
基于区域划分的轨迹隐私保护方法
2018-12-14 05:26郭良敏王安鑫郑孝遥
计算机应用 2018年11期
郭良敏,王安鑫,郑孝遥
(1.安徽师范大学 计算机与信息学院, 安徽 芜湖 241003; 2.安徽师范大学 网络与信息安全安徽省重点实验室, 安徽 芜湖 241003)(*通信作者电子邮箱lmguo@ustc.edu.cn)
0 引言
随着智能手机的广泛普及,越来越多的用户开始使用位置服务提供者(Location Service Provider, LSP),如高德地图、百度地图、Google地图等提供的基于位置的服务(Location Based Service, LBS),如查参考位置周围的酒店、超市、美食等的相关信息。基于LBS,用户可以获得最短时间或最短距离的轨迹信息来到达目的地, 但由于轨迹信息的时空关联性,攻击者可通过分析用户的轨迹信息,从而获得用户的家庭住址、工作场所等隐私信息; 另外,由于位置服务器的集中性,易受攻击,会导致用户的轨迹隐私信息泄露, 因此,对于用户的轨迹隐私保护问题的研究具有重要意义。
当前主流的轨迹隐私保护方法大致分为以下3类:1)基于假轨迹的方法[1-3], 该类方法通过生成相似的假轨迹混淆攻击者,但由于假轨迹数据存储量大,导致LSP处理复杂,降低了服务质量; 2)基于抑制的方法[4-6], 该类方法通过隐藏敏感信息,让攻击者无法分析出用户信息,但会造成大量的信息损失,影响服务。3) 基于泛化的方法[7-9], 该类方法通过将采样点泛化为相应的匿名区域来达到隐私保护的效果,其中比较主流的是基于k匿名的方法[10],该类方法通过联合其余k-1个用户构成匿名区域,使攻击者无法识别出查询用户。已有的k匿名方法一般利用历史轨迹数据构建k匿名,有如下缺点: 1) 在稀疏地区缺少历史轨迹数据无法构建k匿名; 2)k匿名方法一般只适用于快照查询,若进行连续查询,攻击者可根据匿名区域中始终出现的用户推断出查询用户; 3) 匿名服务器的高集中性[11],使其缺乏安全性。例如,在t1到t4时刻,某用户发送了查询请求,该用户在移动时将自己隐藏在包含其余k-1个用户查询的匿名区域中(假设k=5),使攻击者无法定位真正的查询用户, 但在连续查询时,攻击者很容易通过分析多个连续的匿名区域中始终出现的用户,推断出查询用户,从而重构出该用户的真实轨迹(如图1所示)。
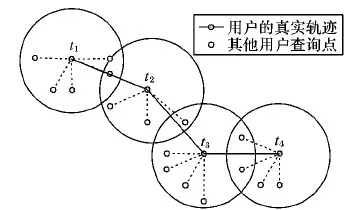
图1 传统k匿名下的用户轨迹
针对上述问题,本文提出一种基于区域划分的轨迹隐私保护方法,主要贡献如下:
1) 用户利用P2P协议共享所需查询的信息,并在找到自身查询结果后,利用其他用户的历史查询点,生成伪查询点迷惑攻击者,以解决在连续查询时的隐私泄露和在数据稀少时无法构建匿名区域问题。
2) 提出覆盖用户真实轨迹的区域划分方法,让子区域面积大于匿名区域面积,使多个查询点隐藏在同一子区域中。如此,攻击者攻击辅助服务器后,无法通过分析用户查询的连续子区域来重构出用户真实的轨迹信息。
3) 通过引入最大缓存时间间隔和最大偏离距离,以提高用户轨迹隐私的安全性,更好地满足用户需求。
1 相关工作
目前,针对k匿名方法无法应对连续查询带来的隐私泄露问题,研究者们提出了相应的解决方案:Peng等[12]提出了一种面向连续查询的协作轨迹隐私保护(Collaborative Trajectory Privacy Preserving, CTPP)方法,用户之间通过WiFi、蓝牙等进行短距离传输,查询用户从多跳邻居用户的缓存中收集有价值信息,然后通过发布假的查询信息来混淆用户的真实轨迹; 胡德敏等[13]通过增加假轨迹和真实轨迹之间的距离约束和相似性约束以满足位置隐私保护的条件; Liao等[14]通过分析用户的历史数据得到每个子区域存在边的可能性,并通过此数据构建滑动窗口,在线性时间内构建伪轨迹,从而提高安全性; Hwang等[15]通过打乱轨迹的时空关联性,在匿名区域随机发送不同的轨迹,使攻击者无法重构用户的真实轨迹来抵御连续查询攻击; Zhang等[16]让用户通过打乱人物身份与轨迹信息的关联性,使用特定算法在移动社交网络找到最佳匹配的用户和其交换查询结果,使攻击者获得匿名服务器的数据后也无法重构出用户轨迹; Zhu等[17]通过分析用户的行为模式,将用户的隐私泄露等级进行分类,并提出了一种基于用户行为倾向的轨迹隐私保护算法,从而增强安全性; 周凯等[18]通过分析LBS中连续查询的轨迹隐私保护的安全需求建立安全模型,再运用双线性映射方法构造用户运动中连续查询的轨迹隐私保护方案,即通过加密的方式保证了安全性。
但上述方法大多运行开销大,查询效率低,或在数据稀少时退化为传统k匿名,因此,本文受到文献[12]的启发,提出一种基于区域划分的轨迹隐私保护方法,以提高轨迹隐私的安全性和提高查询效率。
2 基于区域划分的轨迹隐私保护方法
2.1 相关定义
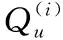
定义2 匿名区域。匿名区域由k个查询点构成,即查询用户的当前查询点和另外k-1个用户对应的k-1个历史查询点的修改版(该修改版是将原历史查询点的post改为当前的查询时间,并清空res,以保证历史查询点和当前查询点的一致性)。k-1个用户的查询点必须在以查询用户的当前查询点或伪查询点为中心的内圆半径为rminASR、外圆半径为rmaxASR的圆环内:大于rminASR是为了保证匿名区域的面积不能过小,以防止攻击者识别出查询用户的兴趣意图;小于rmaxASR是为了保证匿名区域的成员不能过于分散,以免丧失对原查询点的保护作用。
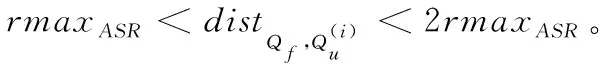
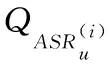
定义5 区域划分。将一块地理区域(如一个城市),放于一个二维平面中,从左到右为x轴正方向,从下到上为y轴正方向,分割成DistrictNum个子区域,Districtx和Districty分别表示x轴和y轴方向上的划分数,有DistrictNum=Districtx*Districty。区域划分时x轴和y轴方向上的划分数由第三方辅助服务器设置,且该信息用户是可获得的。为了保证安全性,子区域面积必须大于ASRi的面积。通过将总区域的面积除以ASRi的最大面积获得一个最小区域数,DistrictNum的设置必须大于该最小区域数。如图2所示,每个子区域按从左到右、从下到上依次从0开始编号。区域划分的作用如下:1) 用户根据辅助服务器在x轴和y轴方向上的划分数计算出当前参考点所在的子区域编号(见2.3节),辅助服务器依据用户发送的子区域编号,快速反馈给用户拥有对应子区域的历史查询点的用户组G,通过与G中的用户共享信息,直接获得兴趣结果,从而可提高查询效率;2)当子区域面积大于匿名区域的面积时,用户的轨迹信息将隐藏在子区域中,使攻击者和辅助服务器无法获得用户真实的轨迹信息。例如,在图2(a)中,用户轨迹中的查询点依次经过了子区域36 → 37 → 27 → 27,攻击者可以从上述连续子区域推断出用户的真实轨迹,无法保证安全性;当子区域扩大后,如图2(b)所示,用户轨迹中所有的查询点都在子区域8内,攻击者和辅助服务器都无法获得用户具体的轨迹信息,保证了安全性。
定义6 查询点之间的距离。查询点Q(i)和查询点Q(j)之间的距离distQ(i),Q(j)是两个参考点之间的欧氏距离。
定义7 最大偏离距离。最大偏离距离distmax是查询用户的当前查询点与其他用户的历史查询点之间所允许的最大距离。
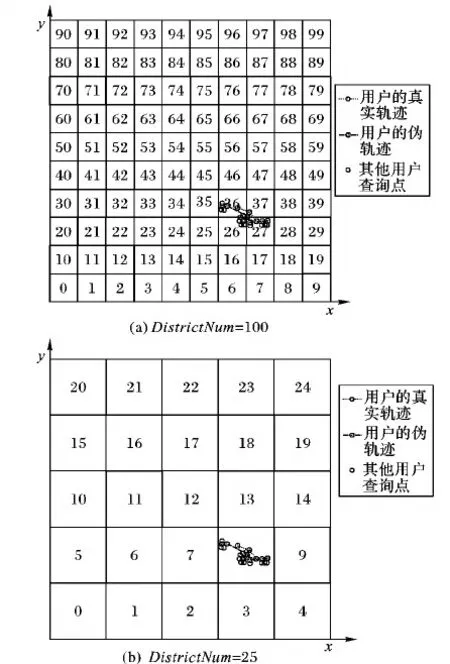
图2 用户轨迹
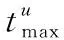
定义9 查询结果。LSP根据用户发送的匿名查询信息返回的k个查询结果,用Result表示。
定义10 缓存信息。用户的缓存信息由多个查询点组成,用cache表示。用户提供给查询用户的缓存信息是经过如下处理的:只含指定子区域下的查询点,且这些查询点的查询时间是经过模糊化处理的。模糊化处理是为了进一步减小查询用户获取其他用户实时轨迹的可能性,由各用户自身设置模糊粒度,该粒度反映了用户对自身轨迹隐私的保护程度。例如,用户可将提供给查询用户的历史查询点中的查询时间只具体到某日。
2.2 系统框架
系统框架如图3所示,由用户、辅助服务器和LSP组成。
首先,查询用户计算当前查询点所在的子区域编号,并将该编号发送给辅助服务器,辅助服务器返回给查询用户拥有对应子区域的历史查询点的用户组信息(即组中各用户的IP信息)。
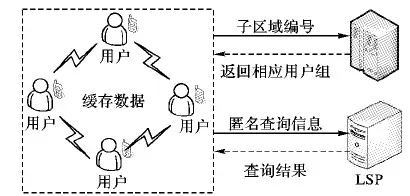
图3 系统框架
然后,通过获得的用户组信息,查询用户利用P2P协议向组中各用户发出请求(即请求所需的对应子区域的历史查询点信息),收到请求的用户将自身缓存中的相关信息经过处理后提供给查询用户下载(详见定义10中的说明),查询用户从中查找与自身当前查询点兴趣相同、距离相近且时间间隔较短的历史查询点。若找到,则将该历史查询点的兴趣结果res值赋予当前查询点的res,然后将当前查询点存入自身缓存中。与此同时,该查询用户会选出伪查询点,以它为中心构建匿名区域,并发送匿名查询信息给LSP以迷惑攻击者,从而更好地解决连续查询时的隐私保护问题;若未找到,则以真实的查询点为中心构建匿名区域,并发送匿名查询信息给LSP。如图4所示,在时刻t1′到t3′时,查询用户从用户组的缓存中获得所需的查询结果,再以伪查询点为中心构成k匿名。在t4′时,查询用户未从其他用户的缓存信息中找到符合条件的历史查询点,因此,以真实查询点为中心构成k匿名。在上述情况下,攻击者即使获得了所有匿名查询信息,在t1′到t3′时刻的伪查询点也使其无法重构出用户的真实轨迹。
最后,LSP根据匿名查询信息中的k个查询点,从数据库中找到每个查询点所需的兴趣信息(即Result)后,返回给匿名区域中的k个用户。查询用户从Result中获得自己所需的查询结果,将其存入当前查询点的res,并将此查询点存入自身缓存中。
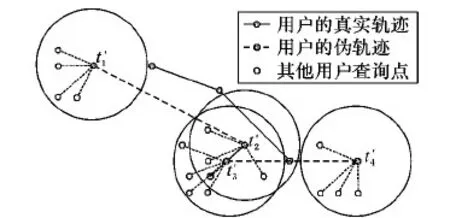
图4 本文方法的用户轨迹
2.3 查询过程
查询用户u在查询所需的兴趣结果时需经历两个阶段:用户组查询和查询处理。
阶段1 用户组查询。
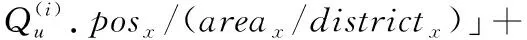
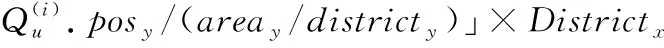
(1)
其中,areax和areay分别是某地理区域在二维平面中x轴和y轴方向上的长度。
阶段2 查询处理。
算法1 查询处理。
1)
2)
flag=0;
3)
for eachuG(uG≠u) inGdo
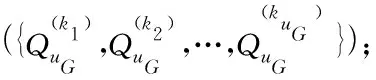
5)
6)
7)
8)
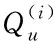
9)
flag=1; break;
10)
end if
11)
end for
12)
ifflag==1 then
13)
break;
14)
end for
15)
ifflag==1 then
16)
利用从∀uG中获得的信息生成Qf;
17)
Anonymity(G,Qf);
//构建匿名区域
18)
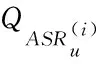
19)
else
20)
21)
22)
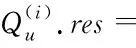
23)
end if
24)
end procedure
算法2 匿名区域的构建。
1)
procedure Anonymity(G,Qx)
2)
ASRi←∅;
3) for eachuG(uG≠u) inGdo
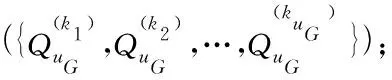
5)
6)
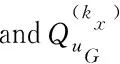
7)
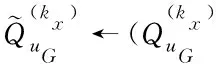
8)
9)
end if
10)
end for
11)
if |ASRi|==kthen
12)
break;
13)
end if
14)
end for
15)
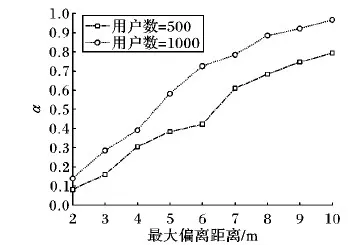
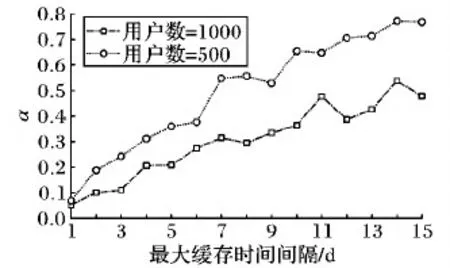
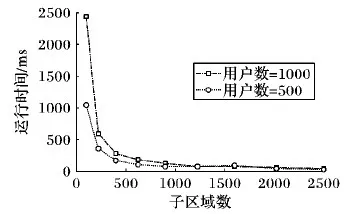
if |ASRi| 16) fori=1 tok-|ASRi| do 17) while 以Qx为中心, 随机生成查询点Qy 18) ifQy∉ASRi-1then 19) break; 20) end if 21) end while 22) ASRi←Qy; 23) end for 24) end if 25) returnASRi; 26) end procedure 实验通过 C++编程实现,编译器是Microsoft Visual Studio 2015,机器的配置是Intel Core i5-3230M CPU 2.60 GHz,8 GB内存和Microsoft Windows 10操作系统。 本文通过编写轨迹生成器来生成用户轨迹,在1 000 m ×1 000 m的地图信息上随机生成多个用户的轨迹信息,具体的参数设置见表1。 表1 参数设置 本文利用发送伪查询点以及将多个查询点隐藏在同一子区域的方法,使攻击者无法重构出用户的真实轨迹,因此,通过伪查询点比例α来评定轨迹隐私的安全性[12],计算如式(2)所示。若一条轨迹中所生成的伪查询点个数越多,则攻击者越难获得有用的信息,安全性也越高。本文通过随机生成50条轨迹,测试用户设定的最大偏离距离和最大缓存时间间隔对安全性的影响。 (2) 4.2.1 偏离距离对安全性的影响 图5显示了在用户数为500和1 000时,最大偏离距离对α的影响。由图5可知,当最大偏离距离越大,α会显著增大,原因是允许的最大偏离距离越大,越容易从用户组中找到符合条件的历史查询点,生成伪查询点的概率高,也就导致安全性提高。例如,当distmax=10时,α=0.97(用户数为1 000时),即一条轨迹中的查询点几乎都是伪查询点;但最大偏离距离的增大,会导致查询精度降低。本文根据用户的隐私需求、地理位置精度需求以及当前子区域缓存数据是否充足来决定最大偏离距离的最佳值。 4.2.2 最大缓存时间间隔对安全性的影响 图6显示了在用户数为500和1 000时,最大缓存时间间隔对α的影响。由图6可知,随着最大缓存时间间隔的增大,α会缓慢地增长。原因与上类似,即允许的最大缓存时间间隔越大,越容易从用户组中找到符合条件的历史查询点,生成伪查询点的概率变高,也就会导致安全性提高。若时间间隔越小,即当前查询点与匹配到的历史查询点的时间越接近,则查询的精度就越高。一般来说,城市的景点、超市、酒店不会在几天之内发生变化,因此,对于用户缓存时间的维护,可以根据城市的变化周期以及缓存能力来设置。 图5 最大偏离距离对α的影响 图6 最大缓存时间间隔对α的影响 4.3.1 子区域数对运行时长的影响 图7显示了子区域数对运行时间的影响。由图7可知,子区域数在100~400内,运行时间急剧减小,在400之后趋于平缓。子区域数增加会使子区域面积减少,若子区域面积小于匿名区域面积,则用户一条轨迹中的多个查询点会在不同子区域中。此时,攻击者若获得辅助服务器中子区域的数据,则可重构出用户的真实轨迹, 因此,子区域数要根据对辅助务器安全性的最低要求以及用户允许的查询时间来进行设置。 图7 子区域数对运行时间的影响 4.3.2k对运行时间的影响 图8显示了匿名程度k对运行时间的影响。由图8可知,本文方法中k对运行时间的影响不大。本文方法利用组内用户的查询点构建匿名区域,运行时间主要取决于组内用户数和缓存的查询点数。在图8中,出现运行时间的偶尔波动(如图8中用户数为500、k=8时的情况)或者是因为当组内符合条件的查询点不满足k时,需随机生成剩余查询点或者是符合条件的历史查询点过少。 图8 k对运行时间的影响 设置CTPP方法中的参数Hmax=5、R=20,用户的当前位置为其历史轨迹中随机的一个位置,其余参数设置与本文相同。 4.4.1 安全性 图9是两种方法下随着用户数增加,安全性的变化情况。由图9可看出,本文方法的安全性高于CTPP方法。即使在用户数相对少的情况下(用户数=500),本文方法的安全性也是CTPP方法安全性的两倍多。原因是CTPP方法取决于查询用户的邻居数,以及邻居用户缓存中是否拥有查询用户想要的查询点。而本文方法直接与拥有对应区域历史查询点的用户共享所需信息,不再受到查询时周围是否有人的限制,且由于用户组的历史缓存中一定拥有用户当前查询点所在区域的历史查询点,所以大幅提升了发送伪查询点的可能性,从而提升了安全性。 图9 两种方法轨迹隐私安全性的对比 4.4.2 查询效率 由图10可看出,对于本文方法,当子区域数为225时,每个子区域面积相对较大,每个子区域的用户相对较多,用户所要查询的历史查询点也随之较多,导致查询时间比子区域数为400时的长。对于CTPP方法,是通过多点跳跃,由多个用户同时进行信息传递,且每次只查询相邻用户的缓存,因此耗时比本文方法在子区域数为225时的少。但是,当本文方法的子区域数(如400)增加时,查询时间比CTPP方法少。原因是:对于CTPP方法,由于一跳的相邻用户未必拥有所需的历史查询点,可能需要对多跳邻居用户进行查询;而本文方法所获得的用户组必定拥有当前区域的历史查询点,避免查询大量无用数据。 图10 两种方法平均运行时长的对比 本文提出了一种基于区域划分的轨迹隐私保护方法,以解决连续查询时轨迹隐私保护性欠缺和用户数少时难以构建匿名区域的问题。该方法通过P2P协作共享历史缓存,并通过构造伪查询点和使多个查询点隐藏在同一子区域的方法,使得攻击者或辅助服务器无法重构出用户的真实轨迹,从而保护用户的轨迹隐私。与CTPP方法相比,本文方法既提高了轨迹的安全性,又在一定程度上改善了查询效率。 下一步将通过打乱用户向辅助服务器查询的时间和顺序,以及考虑在构造伪查询点和生成k匿名时随机生成的查询点真实性,进一步提升用户轨迹隐私的安全性。
3 复杂度分析
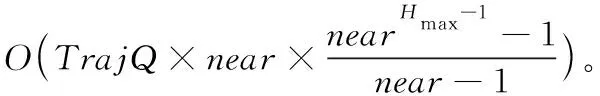
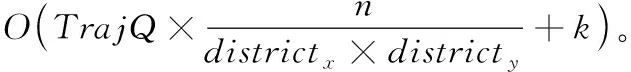
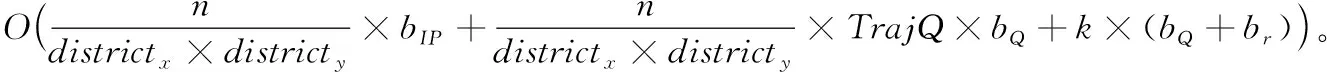
4 实验及分析
4.1 环境设置

4.2 安全性评定
4.3 查询效率的评定
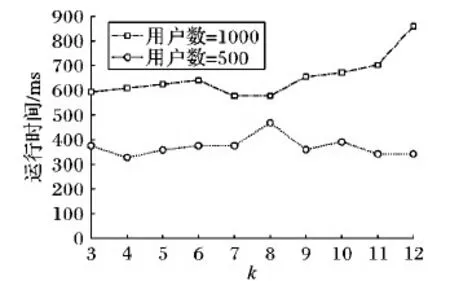
4.4 与CTPP方法的对比
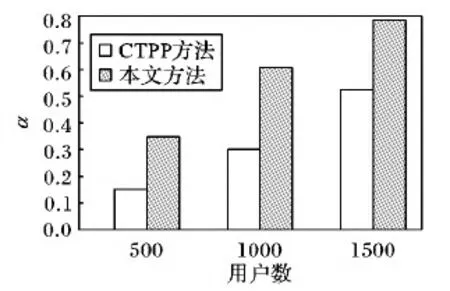
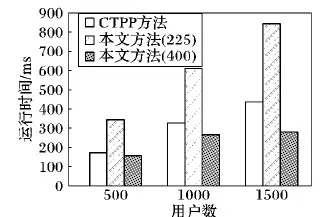
5 结语
猜你喜欢
现代电子技术(2022年11期)2022-06-14
中学生数理化(高中版.高考数学)(2022年4期)2022-05-25
网络安全和信息化(2020年9期)2020-12-31
读友·少年文学(清雅版)(2020年4期)2020-08-24
网络安全和信息化(2020年7期)2020-08-07
读友·少年文学(清雅版)(2020年3期)2020-07-24
网络安全和信息化(2019年8期)2019-08-28
爱你·心灵读本(2018年6期)2018-09-10
爱你(2018年16期)2018-06-21
北京航空航天大学学报(2016年7期)2016-11-16
