
一种基于最优特征选择改进的遗传算法*
2018-12-10 12:13童孟军华宇婷
传感技术学报 2018年11期
辛 宇,童孟军*,华宇婷
(1.浙江农林大学信息工程学院,浙江 临安 311300;2.浙江省林业智能监测与信息技术研究重点实验室,浙江 临安 311300)
1 遗传算法概述
1969年美国大学Michigan的Holland教授提出了遗传算法,其核心理论融合了达尔文进化论和物种选择的思想[9~10]。遗传算法具有坚实的生物学基础,通过选择(Selection)、交叉(Crossover)以及变异(Mutation)等机制模拟了在不同的自然环境、不同的生存条件下某一种群物竞天择的过程,从而将原始问题转变为最优结果的随机搜索问题。算法中适应性函数具有很强的广泛性,根据设计可以表征各类实际问题,再加之算法本身利于并行化、领域无关等特性常用于商业金融[10]、模式识别、计算科学[12-13]等最优解搜索领域。随着人工智能的兴起,机器学习模型中的特征选择便可以借助遗传算法表示为在庞大复杂的特征空间中搜索最优特征子集的过程。
遗传算法作为一种自适应的搜索算法,其核心思想在于将原始问题进行编码以转变为自然种群的基因序列参与进化过程。其中原始问题解的子集可看作种群中的每个个体;定义适应性函数表征种群进化环境的难易程度,同时将原始问题进行编码作为每个个体的基因参与每轮进化的适应性衡量得到适应值;定义选择算子表征种群进化中的优胜劣汰过程,再一次进化中根据个体的适应值选择进入下一轮进化的优良个体;定义交叉算子表征种群在进化中由母本父本交叉形成新个体的过程;定义变异算子表征种群在进化过程中个体基因序列的突变现象。遗传算法的基础框架如图1所示。
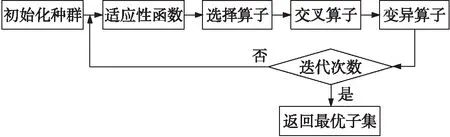
图1 遗传算法的基础框架
2 基于特征选择的遗传算法
2.1 种群个体的编码
遗传算法将原始问题所有可行解模拟为种群中的个体,种群规模表示了算法搜索空间的大小,在初始化种群时,若种群规模过大或过小算法都难以有效的收敛到全局最优。所以种群初始化大小M一般为50~100,并且根据问题的难易、类型不同进行调整。
其中种群个体代表了每一种可能的特征组合,通常对个体基因采用二进制进行编码,使用0,1标记每个特征是否被选中,即进化个体的基因由一个二进制串表示。那么维度为N的特征空间编码后对应长度为N的二进制基因串,其中Ni为1表示该特征被选中,否则Ni为0,例如[1,1,1,0,…,1]。
本文中在对种群个体编码前,引入了一个方差阈值,然后将每个特征的方差值与阈值进行对比,根据是否大于阈值对原始特征空间进行初次过滤,目的在于利用统计学原理剔除那些变化幅度不太,没有区分度的特征。认为这些特征在模型对目标变量的区分上起到了很小的甚至为零的效果。并且经过最大方差的筛选,削减了种群个体基因串的规模,进而减小了遗传算法搜索的范围,提高了算法中的迭代速度。方差筛选算法如下:
N:原始特征空间的维度;
V:预先设置的方差阈值;
SetV
LoopitoN:
If Variance(Ni)<=V:
RemoveNi
2.2 适应性函数
适应性函数是遗传算法中最为关键的部分,它描述了种群在进化过程中的环境难易程度,由于遗传算法不加入先验知识的考虑仅依靠适应性函数对种群质量作出调整,所以优秀的适应性函数能够更好指导算法向全局最优点收敛。针对特征选择问题本文利用预测模型的输出值作为个体的适应值,该值能够直接反映不同特征以及不同特征组合对预测问题的拟合程度和适应性,适应值越高个体越优良对应的特征组合则越有效。同时引入了多折交叉验证以减缓个体对目标的过拟合,保证个体适应性值的鲁棒性;使用线性模型和树模型的结果融合以增强特征组合的鲁棒性。综上每个个体的适应性值F(Xi)可表示为:
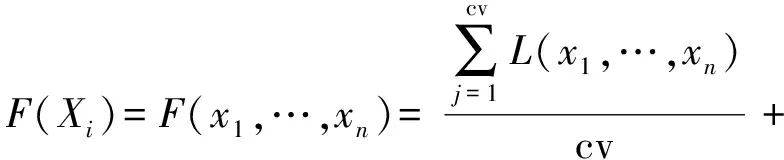
(1)
式中:M代表种群中个体的数量;N代表每个个体的基因长度;cv代表每个模型的交叉验证数;L(x1,…,xn)代表线性模型,本文中其输出值由线性回归导出;G(x1,…,xn)代表树模型,本文中其输出值由梯度迭代树导出;
2.3 遗传算子的设计
2.3.1 选择算子
选择算子模拟了自然生物进化中优胜劣汰的过程,该算子在进化中根据种群内每个个体的适应值进行判断,适应值高即优良的个体有较大概率进入下一轮进化,反之适应值低的个体有较小概率被选中;选择算子保证了优良的基因能够在种群内遗传下去,意味着在预测模型上表现好的特征组合将会被保留。本文中的选择算子采用轮盘赌算法,该算法直接表征了个体被选中的概率与个体适应值的正比关系,公式化如下:
(2)
同时由于本文采用均方误差(MSE)衡量预测结果的准确性,为了保证轮盘赌选择算子在选择最优个体时与评测指标相一致,对个体每一轮进化的适应值做取倒数操作,即:
(3)
2.3.2 交叉算子
交叉算子模拟了自然环境中父本母本通过交叉基因产生新一代的过程,该算子体现了遗传算法启发性搜索的特点,同时它也是每次进化获得优良个体的关键手段。特征选择中的交叉算子极大程度上改变了原始特征的组合方式,使得算法在每一轮进化中考虑了不同交叉特征对预测目标的影响能力。由于父本母本的基因编码代表了特征子集,为了防止特征在交叉过程中被大范围交换丢失了父本母本原有的优良特征,本文设计了定长基因段交叉算法。该算法描述如下:①随机从种群中选择两个个体作为父本和母本;②定义参与交叉的基因段长度L,L为原始基因长度的三分之一并向上取整;③随机选择交叉起始位点A和终点B,使得|A-B|=L;④遍历交换基因段,若基因位点取值相同,则认为父本母本对该特征的意见一致,可保留至下一代,否则直接交换父本母本的基因位点,例如:
父本:[1,1,1,(1,1,0,1),0,0,1]
母本:[1,0,0,(1,0,1,1),0,0,0]
如上长度为10的父本母本基因组,在某轮进化中随机选择了4号至7号基因位点,则除了4号基因位点外,其余位点相互交换,形成新的两个个体基因。
2.3.3 变异算子
变异算子主要体现了种群在进化过程中,基因位点发生突变的现象,随着这种变异的发生个体的特征也会改变,它属于遗传算法中的辅助算子,为遗传算法提供了一定程度的多样性和可能性,大大提高了搜索的随机性。根据自然环境中基因突变发生的低概率性和不确定性,本文中采用的变异算子计算过程描述如下:①定义一个极小的突变阈值;②随机选取若干个基因位点,对于每个基因位点产生一个随机数r;③若随机数大于突变阈值,则对应的基因位点做取反操作。
例如:
M1:[1,1,1,1,1,0,1,0,0,1]
在某轮进化中,M1个体随机选择到4号和8号基因位点,那么对每个位点生成随机数r1、r2后,若r1>,r2<,则变异后的个体基因为:
M1:[1,1,1,0,1,0,1,0,0,1]
3.4 算法流程
基于特征选择的遗传算法是经过特征工程后,在具有一定维度的特征空间上进行搜索的过程。对于原始数据本文采用了独热编码处理类别类型特征,采用交叉组合的方式处理数值类别的特征,通过这种方法在没有引入先验知识的前提下,极大的扩充了原始特征空间。然后对该特征空间进行方差过滤构造特征候选集,同时特征候选集二进制编码初始化种群参与遗传进化,在达到最大迭代次数后返回最优特征子集,最后利用该子集进行预测,并给出评价。其基本流程如图2所示。
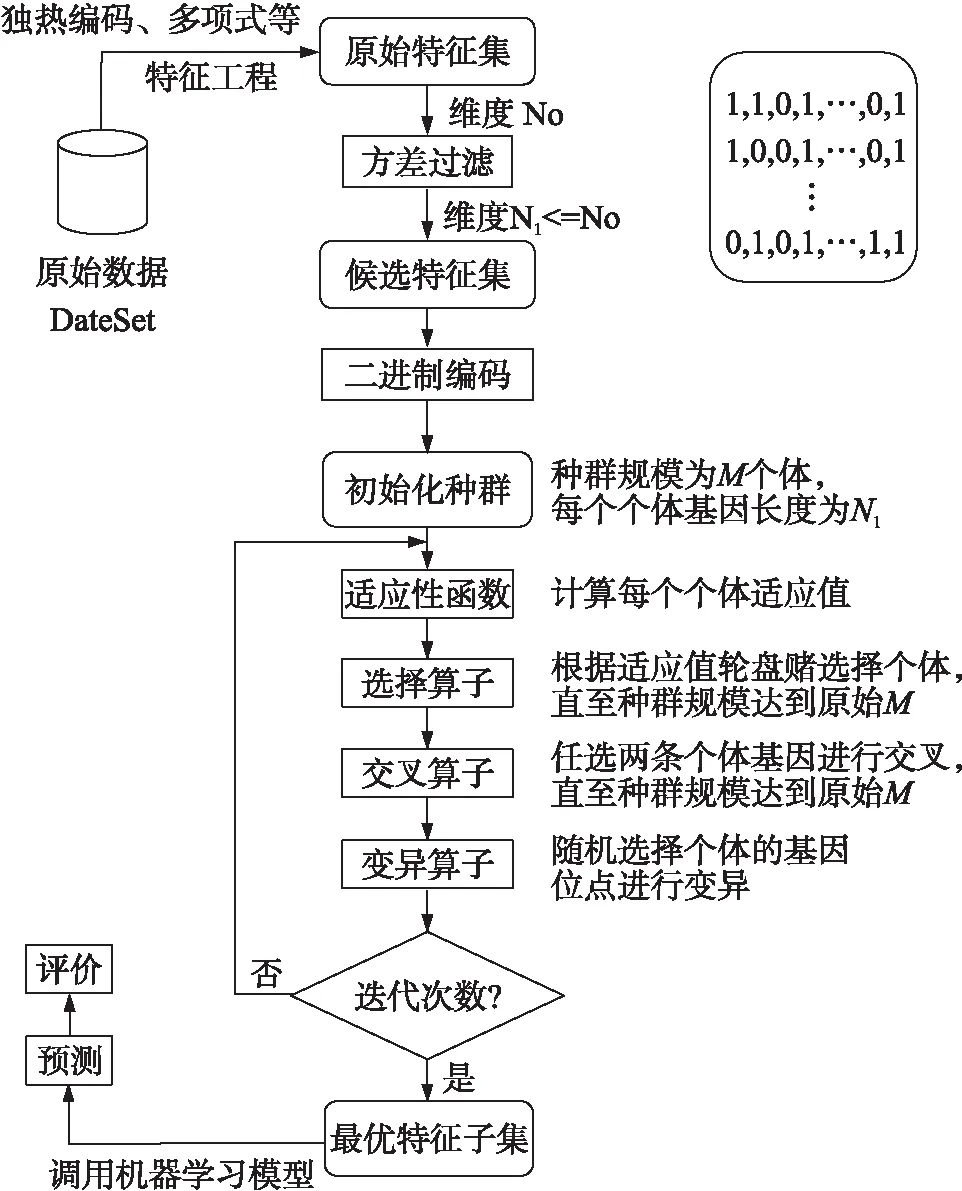
图2 遗传算法流程图
3 实验
3.1 实验环境
本文中的实验环境使用Python3.6.1版本编写遗传算法框架;Sklearn-0.19.1、Pandas-0.22.0、Numpy1.14.2机器学习库处理数据特征和调用预测算法模型;开发编译器使用Ipython-notebook调试算法。实验数据使用5种用以数值型预测的UCI公开标准测试数据集,为方便起见,定义5个数据集分别为D0、D1、D2、D3、D4实验数据集,各个数据集的样本维数、原始特征维数、经过特征工程后的维数如表4.1所示;本文利用以上数据集获得遗传算法的输入特征,并构建线性回归模型进行预测。

表1 数据集特征信息
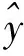
(4)
定义实验中算法模型参数如下:
种群规模为20,每个个体基因长度为经过最大方差筛选后的数量,种群最大遗传次数分别为10、20、30次,用L1~L3表示;最大方差阈值设定为0.1,适应性函数中使用的线性回归与GBDT模型均使用默认参数,交叉验证次数为10次,最后使用线性回归(LR)和进行预测,对比特征筛选前后不同模型的预测情况,取MSE较低为优。
3.2 实验结果
如表2中所示,5个数据集在经过最大方差筛选后有效剔除了区分度较低的特征,其中D0、D1、D3数据集缩减了2~3个维度说明原始特征取值丰富,对目标变量的区分和识别度较高;其他数据集缩减了半数以上的维度,去掉了取值较为单一的数据,很大程度降低了特征空间维度,达到了缩减搜索范围大小的目的。

表2 方差筛选
表3中N表示了5个数据集在L3遗传次数选择后剩下的特征即最优特征子集的规模,与选择前相比选择后明显缩减了特征空间大小,特别的D3数据集缩减率达到了50%;MSE2、MSE1分别表示特征选择前后最终线性回归模型的MSE值,对比二者可见5个数据集使用遗传算法得到的最优特征子集后不同程度上提升了预测的准确率,其中D1数据集准确率上升幅度最大达到90%。表明该算法有效的筛选出了与目标变量相关度最大,最能够区分目标值的特征。
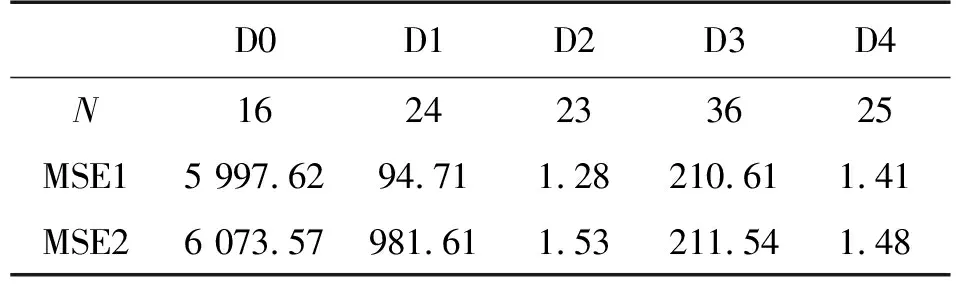
表3 筛选后特征数量与MSE
如图3~图7所示,在不同的遗传次数下,5个数据集经过特征选择后的MSE值均得到了提升,并且随着遗传次数的增加,其最优特征子集特征得到的准确率在不断提升,表明算法具有一定的随机稳定性;主要因为遗传次数的增加,算法包含的随机性随之增大,其考虑的特征组合也越多从而能够产生较为优秀的特征子集。
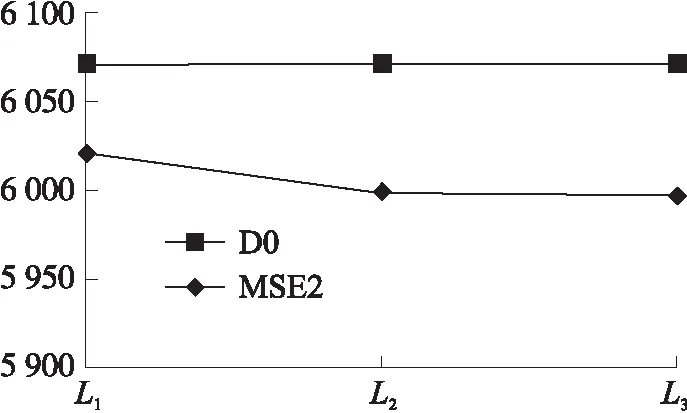
图3 D0数据集MSE变化
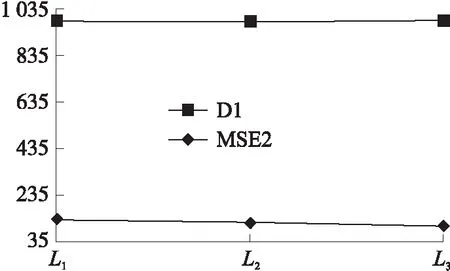
图4 D1数据集MSE变化
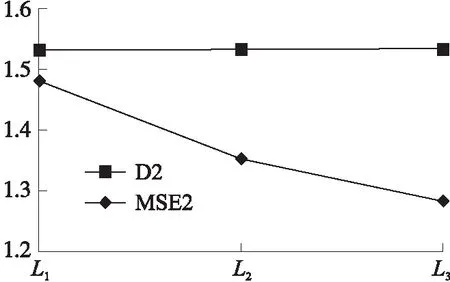
图5 D2数据集MSE变化

图6 D3数据集MSE变化
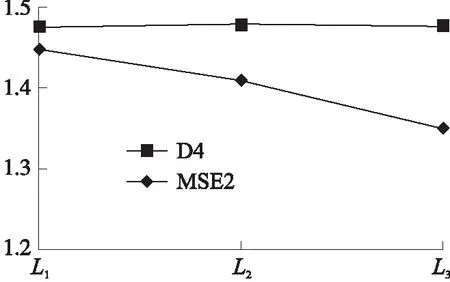
图7 D4数据集MSE变化
另外如图8所示,以D0数据集为例,随着遗传次数的增加遗传算法运行的时间也随之提高,然而得到的特征组合所带来准确率的提升却不足以弥补算法运行效率的降低,所以将遗传次数控制在适合的范围才能够从效率和准确率优化上充分发挥遗传算法的优点。
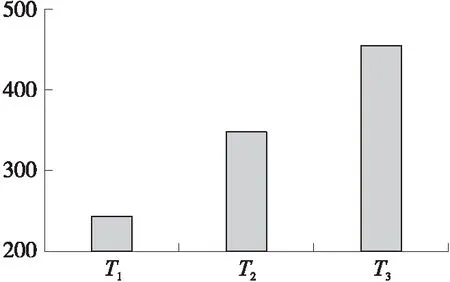
图8 D0数据集遗传算法时间
L3遗传次数选择特征后与选择前的预测模型运行时间如图9所示,其中T1代表特征选择前的模型运行时间,T2代表特征选择后的运行时间。易见特征维数的降低能够减少预测算法的运行时间,主要由于直接降低了模型复杂度,使得模型对每个特征的遍历次数大大降低,表明该遗传算法能够在提高预测准确率的同时优化预测效率。
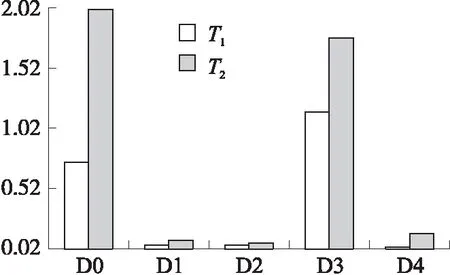
图9 各数据集运行效率

图11 D1数据集MSE对比
如图10~图14所示,MSE3表示单一模型作为适应性函数的遗传算法下最终的预测准确率,可见在不同的遗传次数下,使用适应性函数为单一模型的遗传算法产生的特征,其预测结果的精确度均低于本文使用复合适应性函数的遗传算法,其中D1数据集上预测准确率的差值超过了100,主要原因在于更复杂的适应性函数趋向于选择更为强健的特征,并且交叉算子中产生了更加丰富多样的特征组合,提高了候选特征的质量。
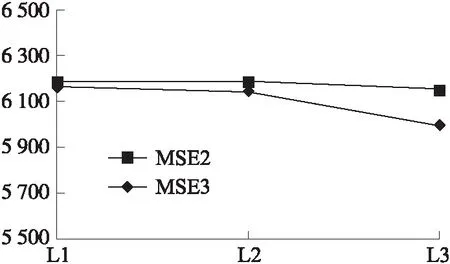
图10 D0数据集MSE对比
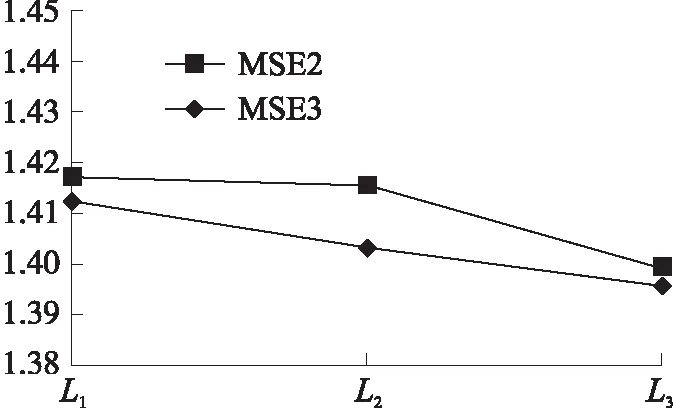
图12 D2数据集MSE对比
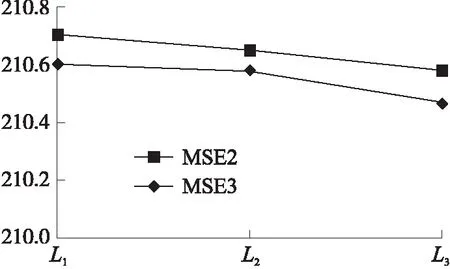
图13 D3数据集MSE对比
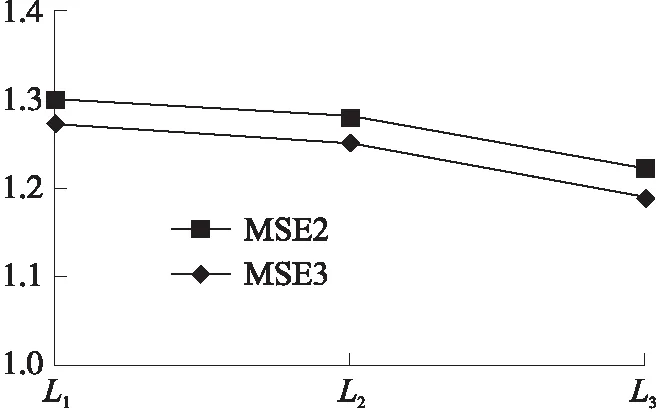
图14 D4数据集MSE对比
5 总结
本文主要研究了机器学习中模型特征筛选的过程。针对原始特征空间维度过大、适应性函数评价方式单一、多特征组合优化搜索问题引入了一种改进的启发式遗传算法,并且利用多个标准测试数据集在该遗传算法上的表现,分析特征筛选后的模型预测准确率和筛选的特征数量,验证了该算法在数值型预测问题上对于原始特征能够在筛选出较优特征组合的同时达到降维的效果,最终提高预测精度。本文对数值型预测中特征选择问题的解决提供了一定的可行性和可靠性。未来将会继续在特征工程优化、遗传算法各算子优化上进一步研究,使算法泛化性、鲁棒性更加强健。
猜你喜欢
数学物理学报(2022年5期)2022-10-09
数学物理学报(2021年2期)2021-06-09
数学物理学报(2021年1期)2021-03-29
应用数学(2020年2期)2020-06-24
中央民族大学学报(自然科学版)(2017年1期)2017-06-11
统计与决策(2017年2期)2017-03-20
电子制作(2017年23期)2017-02-02
现代计算机(2016年34期)2016-02-28
西北工业大学学报(2015年4期)2016-01-19
智能系统学报(2015年4期)2015-12-27
