
基于Faster R-CNN的榆紫叶甲虫识别方法研究
2018-12-04 02:13董本志聂丽郦景维鹏
计算机工程与应用 2018年23期
董本志,聂丽郦,景维鹏,崔 航
东北林业大学 信息与计算机工程学院,哈尔滨 150040
1 引言
榆树是东北地区常见树种,也是重要的经济树种和观赏树种,但在其生长过程中经常受到害虫侵扰。准确识别害虫判别灾害情况,对有效治理虫灾有重要意义,利用图像处理方法可有效对其进行识别。
目前利用图像处理对昆虫进行识别的方法为:先使用图像去噪[1]、图像分割等[2]方法对图像进行预处理,然后采用灰度直方图[3-4]、随机森林算法[5]、方向梯度直方图(Histogram of Oriented Gradient,HOG)[6]、词袋算法(Bag of Words,BOW)[7-8]等算法提取图像的特征,最后将提取到的特征送入支持向量机(Support Vector Machine,SVM)[9]、前馈神经网络(Back Propagation,BP)[10]、自组织映射网络(Self Organizing Map,SOM)[11]等分类器中,对提取到的特征信息进行分类表达。但上述识别方法均需人为参与到特征提取模板和特征提取算法的设计中,往往加入了先验知识,具有很强的主观性,影响分类器的判断。同时,针对昆虫这种目标小、纹理特征多样、结构丰富、姿态多样、种间相似度高的目标[12],很难人工设计出有效描述昆虫典型特征的模板与算法。
深度学习模型由数据直接驱动特征的提取,可以利用像素之间的位置特征,自主学习出数据间许多容易被人忽视的潜在特征,有效解决了特征提取模板针对性不强的问题。深度学习模型中卷积神经网络在图像处理方面有较广泛的应用,如汉字识别验证码[13]、道路中车辆识别[14]等。目前最成熟且应用最广泛的深度卷积神经网络模型Faster R-CNN[15]将目标检测的候选区域生成、特征提取、分类、位置精修四个步骤统一到一个深度网络架构之内,形成了统一的体系结构。识别复杂背景中的目标时具有很好的鲁棒性和很强的辨别待识别物体间的细微差别的能力。同时,利用数据自主驱动模型提取特征,有效克服了传统识别分类方法中依赖于人工设计特征提取模板的局限性,可较好地识别出自然环境中复杂背景下的目标,因此本文采用Faster R-CNN网络对榆紫叶甲虫进行框定。但是标准Faster R-CNN网络模型是针对标准数据集VOC2007的20分类任务设计的,生成的初始候选框为固定的三种尺寸、三种比例,用其识别榆紫叶甲虫时,初始候选框的长宽比不符合榆紫叶甲虫的长宽比形态学特征,容易造成候选框冗余过大。加之榆紫叶甲虫的甲壳反光,在框定榆紫叶甲虫目标时会出现误差,在榆紫叶甲虫和榆树叶片豁口或孔洞相邻时或者两只榆紫叶甲相邻时框定误差尤其严重。因此,本文使用Faster R-CNN模型识别榆紫叶甲虫时,对初始候选框生成网络进行改进,使其生成的初始候选框更加贴合榆紫叶甲虫本身的特征,减少周围复杂环境造成的影响,以提高识别精度。
2 基于K-means聚类算法的Faster R-CNN网络模型
为得到符合榆紫叶甲虫长宽比形态学特征的初始候选框,可以用聚类算法对样本的长宽值进行统计,得出最理想的候选框长宽比。目前常用的几种聚类算法有K-means聚类、层次聚类、SOM聚类、FCM聚类。其中K-means聚类算法是基于距离的聚类算法,使聚类后每个子类内的点到当前类中心点的距离之和最小,符合本文的聚类需要。本文以最小化子类内的点到当前类中心点距离之和为目标函数,通过计算评价聚类结果中各子类的类内紧密程度与类间分离程度关系的BWP(Between-Within Proportion)指标来确定最佳聚类中心点个数kopt,对n个榆紫叶甲虫训练样本矩形标签的长宽比值X{x1,x2,…,xn}进行聚类。这里kopt的计算方法见公式(1)。

令聚类中心点个数k在[2,n)内循环,计算各k值对应的所有样本的BWP值的平均值avgBWP(k),kopt的值取令avgBWP(k)最大值时对应的k值,计算方法见公式(2)。
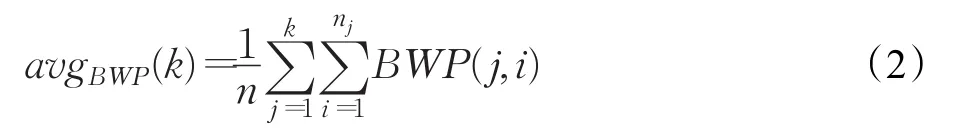
其中BWP(j,i)是最小类间距离和类内距离的衡量指标,其计算方法见公式(3)。

公式(3)中b(j,i)为最小类间距离,是第 j类中第i个样本到其他每个类中样本的平均距离最小值,其计算方法见公式(4);w(j,i)为类内距离,是第 j类中第i个样本到其第 j类中其他所有样本的平均距离,其计算见公式(5)。

其中 j∈[1,ki],i∈[1,nj]。nj为第 j类的样本数;m和j表示类标;表示第 j类的第i个样本;表示第m类的第 p个样本;nm表示第m类的样本数;表示平方欧氏距离。

其中nj表示第 j类的样本数,表示第 j类的第q个样本。
通过计算得到kopt的值后,可同时得到kopt个聚类中心点,可以用集合A={A1,A2,…,Akopt}表示。A中的元素可以用来代替标准网络生成的初始候选框的长宽比值0.5、1、2,生成更加符合榆紫叶甲虫长宽比形态学特征的初始候选框,减少框定误差。
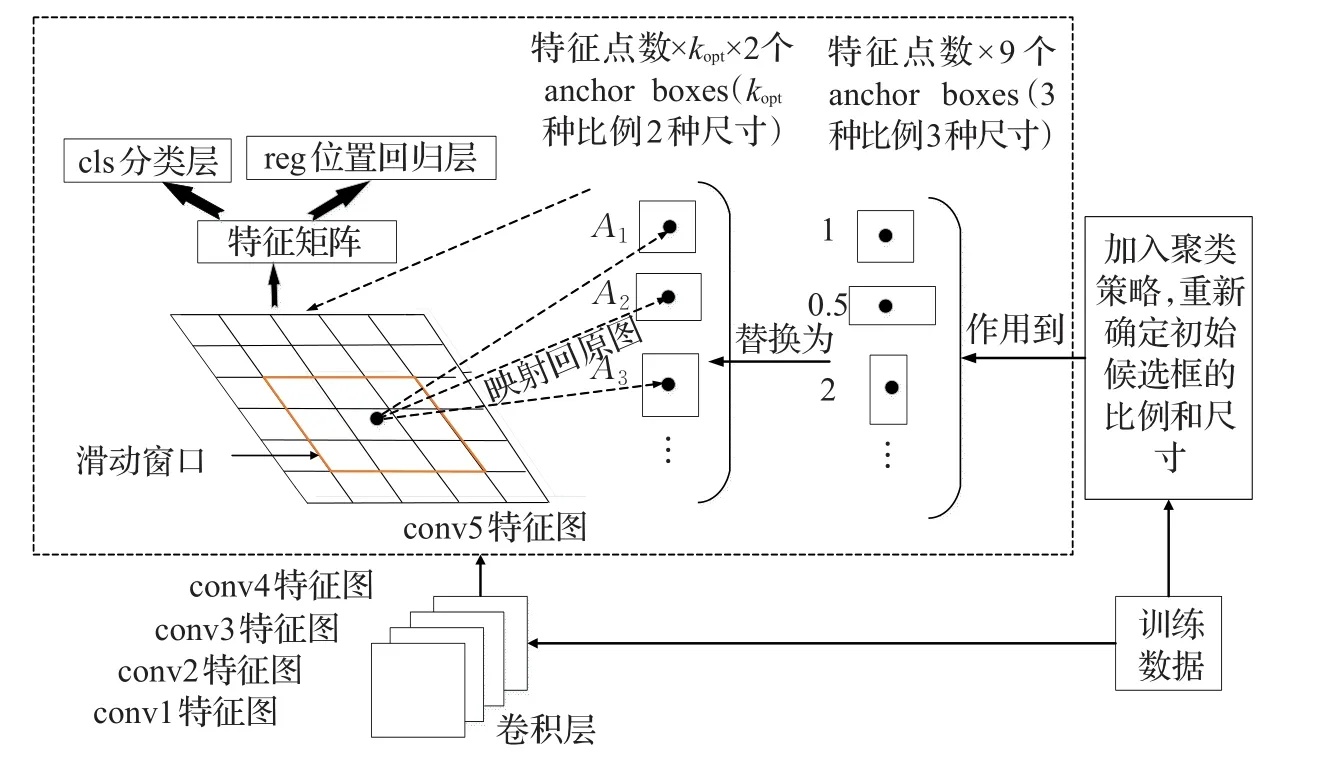
图1 改进的Faster R-CNN网络示意图
调整了初始候选框的生成比例后,进一步对初始候选框的生成尺寸进行调整。标准网络生成的初始候选框的三种尺寸固定为1282,2562,5122,但是由于榆紫叶甲虫的尺寸相对于VOC2007标准数据集中的飞机、汽车、马等目标类别的尺寸来说占据整张图像比例很小,属于小目标。而5122这种尺寸对于榆紫叶甲虫来说冗余过大,导致位置精修时的初始候选框边框平移量过大,容易造成框定不准。因此,本文舍弃这种尺寸的候选框,以提高检测的准确率。
改进的Faster R-CNN网络示意图如图1所示。
改进主要涉及到初始候选框生成文件generate_anchor.py和候选框层文件proposal Layer.py。首先,在proposal Layer.py文件中的类proposal Layer(Caffe.Layer)里根据公式(1)~(5)定义一个用来对训练数据集标签长宽比值进行聚类的函数K_means,返回值为kopt和{A1,A2,…,Akopt}。然后,将两个返回值传给generate_anchor.py文件中的generate_anchors函数,用{A1,A2,…,Akopt}代替标准网络中候选框生成比例0.5、1、2。其中generate_anchors函数根据传入的参数生成生成conv5特征图上的特征点数×kopt×2个初始候选框。在对网络进行训练前,先对训练样本矩形标签的长宽比值进行聚类,并对生成初始候选框的面积加以调整。这样在Faster R-CNN网络后面的全连接层部分,在分类层得分大于0.6的初始候选框会进入后面的位置回归层进行候选框的四个边框的精修。由于改进后的Faster R-CNN网络模型生成的初始候选框更加符合榆紫叶甲虫本身的形态学特征,所以初始候选框四周冗余较标准网络生成的初始候选框少。对初始候选框四边框精修时,四个边框从初始位置平移到标准位置时的平移量较少,使得复杂背景对框定的干扰较少,从而能够更加准确地判定出边框精修的终止位置,达到更为准确的对目标榆紫叶甲虫进行框定的目的。
3 实验
3.1 实验环境
本文实验软件平台采用linux Ubuntu 16.04 LTS系统、label Image 1.3.2、pycharm 2.7.3、openCV 2.4.6,硬件环境是4 GB内存,Intel®Core™i5-5450M CPU@2.50 GHz,主频3.4 GHz的计算机。
3.2 实验数据
实验数据采集地点为东北林业大学帽儿山实验林场,以其30~40年生的大叶榆、大果榆、裂叶榆、春榆等榆树上榆紫叶甲虫为研究对象。拍摄到3 000张像素大小为4 000×6 000的图片数据。对数据集进行筛选以避免错误、重复和模糊的图像并人工标注,同时按照7∶1∶2的比例随机抽取训练数据集、验证数据集、测试数据集。
3.3 实验结果及分析
根据本文样本数据集得出聚类中心数kopt=3,中心点分别为A1=0.64、A2=0.99、A3=1.27。用三个新的生成初始候选框的长宽比值代替标准网络的生成初始候选框的长宽比值0.5、1、2,网络改进前后的初始候选框生成的尺寸和比例框图如图2所示。其中,图2(a)为按照标准初始候选框生成比例和尺寸规则生成的候选框情况,图2(b)为加入聚类策略和调整了初始候选框的尺寸的网络的生成候选框情况。两图均为以O点为中心生成的候选框,图2(a)中的三个蓝色框为最大尺寸的三种比例候选框,三个红色框为中间尺寸的三种比例候选框,三个黄色框为最小尺寸的三种比例的候选框。

图2 网络改进前后的初始候选框生成比例和尺寸框图
从图2中可以看出,蓝色候选框尺寸对于榆紫叶甲虫来说冗余过大,在后面全连接层精修回归过程中易受复杂背景中诸多特征的干扰,造成误圈。红色框和黄色框的长宽比例不符合榆紫叶甲虫本身的长宽比形态学特征,在边框精修时四个边框平移的位移过大,易受复杂背景的干扰。在某一局部区域计算的损失小于规定阈值时就会停止回归,造成边框平移中断或者平移过大,出现框定过大或者过小的情况。图2(b)中去掉了蓝色尺寸的三种比例的候选框。同时,针对红色框和黄色框的情况,在相同尺寸下利用聚类生成新的初始候选框的长宽比,使其更加符合榆紫叶甲虫本身的生物学特性。在后面的回归过程受复杂的背景影响较小,可排除大部分复杂背景干扰圈定更为准确。
榆紫叶甲虫和叶片豁口或孔洞相邻时,标准网络模型与加入聚类策略和调整了生成候选框尺寸Faster RCNN网络输出结果对比图如图3所示。其中,图3(a)~(e)为标准网络的检测效果图,图3(f)~(j)为改进后的网络输出结果图。图3(a)与(f)、(b)与(g)、(c)与(h)、(d)与(i)、(e)与(j)分别为同一张图像的两个模型的输出结果。图中黄色圆圈部分为和榆紫叶甲虫相邻的叶片豁口或孔洞。
从图3(a)~(e)可以看出,由于榆紫叶甲虫的形状、颜色等特征与叶片豁口相似,会出现框定榆紫叶甲虫范围时将临近的叶片豁口也框定进去,造成框定范围冗余的现象。并且由于榆紫叶甲虫的甲壳反光,标准模型会将一部分榆紫叶甲虫识别为背景,出现框定不全的现象。而改进后的网络模型,减少了叶片豁口对榆紫叶甲虫框定结果的影响,框定范围比较准确,如图3(f)~3(j)所示。实验结果证明,经过对生成初始候选框网络的改进,在框定有叶片豁口干扰的榆紫叶甲虫图片时,取得了优于标准候选框的效果。
相邻榆紫叶甲虫框定结果对比,如图4所示。其中,图4(a)~(e)为标准网络的检测效果图,图4(f)~(j)为改进候选框生成网络的输出结果图。图4(a)与(f)、(b)与(g)、(c)与(h)、(d)与(i)、(e)与(j)分别为同一张图像的两个模型的输出结果。
从图4中可以看出,图4(a)将两只榆紫叶甲虫框定到一起;图4(b)中将一只榆紫叶甲虫包含于另一只的范围内;图4(c)中两只榆紫叶甲虫范围均未框定完全;图4(d)中框定的榆紫叶甲虫范围冗余过大;图4(e)中的两只榆紫叶甲虫范围均未圈定完全。这是由于两只榆紫叶甲虫特征相似且位置相临,相似的特征对框定结果造成干扰,而改进候选框生成网络模型有效的解决了标准网络模型出现的问题,如图4(f)~(j)。由此可见,在两只榆紫叶甲虫相邻的情况中,改进后的网络比标准网络框定效果更好。

图3 榆紫叶甲虫和叶片豁口或孔洞相邻时网络模型改进前后输出效果对比图

图4 相邻榆紫叶甲虫框定结果对比图

图5 候选框生成网络改进前后的榆紫叶甲虫和与其特征相似的昆虫识别效果对比
由于榆树花甲虫和盾瘤胸叶甲虫也是榆树常见害虫之一,且和榆紫叶甲虫形态类似,在采集图像时很容易采集到这两种虫,造成错误框定,如图5所示。其中,图5(a)~(e)为标准网络的检测效果图,图5(f)~(j)为改进候选框生成网络输出结果图。图5(a)与(f)、(b)与(g)、(c)与(h)、(d)与(i)、(e)与(j)分别为同一张图像的两个模型的输出结果,图5(a)与(f)、(b)与(g)、(c)与(h)为盾瘤胸叶甲,图5(d)与(i)、(e)与(j)为榆树花甲虫。由实验结果可以看出,标准网络模型存在误将与榆紫叶甲虫形态相似的昆虫框定出来的现象,而改进候选框生成网络后的模型不会输出这样的结果图,只将榆紫叶甲虫框定出来,其余种类的昆虫将不会框定出来。
分类实验中,对于结果的处理,一般仅用一种指标很难得到对算法的正确评估的。所以,一般用精准率(Precision,P),召回率(Recall,R)来共同对算法进行评估。衡量的最终指标是识别的平均精度值AP。一般将以召回率和准确率为横纵轴的PR曲线与两坐标轴围成的面积作为衡量指标。
准确率的计算公式如下:

召回率的计算公式如下:

TP(True Positives)是模型预测为正样本实际为正样本的特征数量,FP(False Positives)是模型预测为正样本但实际是负样本的特征数量。TN(True Nagetives)是模型预测为负样本实际也为负样本的特征数量,FN(False Nagetives)是模型预测为负样本但实际为正样本的特征数。其中,准确率P指检索出的榆紫叶甲虫数量与此次检索得到的检测框的数量的比值,衡量的是查准率。召回率R指检索出的榆紫叶甲虫数量与数据集中所有榆紫叶甲的数量的比值,衡量的是查全率。因为准确率和召回率不可兼得,本文选择AP作为衡量实验效果好坏的指标。将曲线与横纵坐标围成的面积作为AP的值。
改进前后模型的PR(Precision-Recall)曲线如图6所示。

图6 改进候选框生成网络模型和标准网络模型的PR曲线
从图6中可以看出,改进后的网络框架测试结果的AP曲线与横纵坐标轴的面积大于标准框架输出的测试结果与坐标轴的面积,即改进后的网络框架的输出平均精度高于标准网络框架。同时通过图3~图5实验输出效果对比图可以看出,改进后的模型输出的识别效果图圈定的目标范围更加精准,且不会出现误识别其他种类昆虫的情况,识别精度从90.58%提升至94.73%。
4 结束语
本文提出了一种基于聚类算法的自适应Faster R-CNN网络模型用以榆紫叶甲虫的识别:通过利用K-means算法结合BWP指标对训练数据的矩形标签的长宽比值进行聚类,利用聚类中心点代替标准网络中生成初始候选框的长宽比例,使生成的初始候选框更加符合榆紫叶甲虫长宽比形态学特征,减少边框精修时的平移量,提高了识别精度。实验结果表明,本文提出的基于K-means的Faster R-CNN算法有效解决了传统识别算法中特征提取模板的局限性,并针对初始候选框不贴合待识别目标造成的误差加以改进,提高了识别准确率。改进后的网络在框定单只榆紫叶甲虫、榆紫叶甲虫与叶片豁口或孔洞相邻、榆紫叶甲虫相邻时和其他与榆紫叶甲特征类似种类的昆虫的框定效果均优于标准网络。测试相同数据集时的准确率优于标准网络模型,证明了改进后的网络的优越性。
猜你喜欢
光学精密工程(2022年13期)2022-08-02
故事作文·低年级(2022年7期)2022-07-18
计算机工程与应用(2022年1期)2022-01-22
小哥白尼(野生动物)(2021年4期)2021-07-29
小哥白尼(野生动物)(2021年1期)2021-07-16
计算机工程与科学(2021年4期)2021-05-11
火力与指挥控制(2018年3期)2018-04-19
现代园艺(2017年13期)2018-01-19
童话世界(2017年8期)2017-05-04
现代农村科技(2016年19期)2016-11-22
