
杰卡德系数差分误差跳距修正的DV-hop改进算法
2018-12-04 02:13方旺盛胡中栋
计算机工程与应用 2018年23期
方旺盛,杨 庚,胡中栋
江西理工大学 信息工程学院,江西 赣州 341000
1 引言
无线传感器网络由资源受限的传感器节点组成,这些节点可以相互通信并协作收集环境中的信息,通过无线通信方式形成一个自组织的智能网络系统,能够实时监测、感知和采集所监控区域内的各种环境或监测对象的信息,并对这些信息进行处理,将获取到的信息发送到任务管理节点或者需要这些信息的用户[1]。因为传感器节点是无线传感器网络中的基本组成单位,节点定位又是无线传感器网络系统部署完成后面临的首要问题,是无线传感器网络其他功能的基础,所以节点的位置信息至关重要。
无线传感器网络现有的定位技术通常可以分为两类:基于测距(range-based)的和无需测距(range-free)的定位技术。基于测距的定位方法首先需要精确地测量相关节点之间的距离信息(距离或者角度),然后再使用三边测量、三角测量或最大似然估计定位计算方法来计算节点位置。常见的基于测距的定位算法有RSSI[2],AOA[3],TOA[4],TDOA[5]。基于测距的定位算法有定位精度高的特点,但却有两个主要缺点:首先,距离信息很容易受到多径衰落、噪声和环境变化的影响;其次,通常需要额外的测距装置,这会消耗更多的能量并增加硬件成本。无需测距的定位技术具有硬件成本低、能量消耗少的特点,特别适用于网络规模大和需要耗能小的环境。无需测距的定位算法主要有质心算法、凸近似算法、DV-hop算法、APIT算法、Amorphous定位算法等。
DV-hop定位算法的定位过程利用网络中锚节点的信息广播过程位置信息来进行节点定位,能够有效地节约成本和节省能耗,因此是一种广泛应用的无线传感器网络的定位技术。但是DV-Hop算法却有定位精度较低的缺点,例如网络在平均连通度为10,锚节点比例为10%的各向同性时的定位精度约为33%[6-7]。因此国内外学者都对DV-hop定位算法进行了不断的改进。刘士兴等提出一种使用多个通信半径广播自身分组信息的RWDV-Hop算法,获得了未知节点与锚节点更精确的跳数[8],然而该算法需要锚节点在泛洪阶段向邻居节点广播多次不同通信半径的数据信息,这样增加了网络节点的能耗。党宏社等人提出采用节点接收的RSSI值与理想一跳的RSSI值的比值对经典DV-Hop定位算法的一跳距离进行修正,并且直接对第一跳节点使用RSSI测距技术计算距离[9],但是该算法忽略了在定位过程中直接使用的RSSI值极易受环境的影响而造成较大的误差,而且因其需要锚节点直接从节点寄存器中读取RSSI值,这样明显地加大了泛洪信息的数据量和通信开销。Hou S和Zhou等人提出了一种基于新型差分误差的算法DDV-Hop,在定位计算的过程中,改进每个定位节点的平均跳距大小,然后对从不同锚节点接收到的平均跳距进行加权赋值来估计待定位节点的自身位置[10],该算法有效地降低了经典DV-Hop的误差,但是却存在当所选取的两个锚节点之间的跳数较多时导致估计的跳距仍有较大误差的问题。范时平等是在Hou S等人的算法基础上提出使用跳距误差的加权平均值,修正原始的平均每跳距离,再采用分段的指数、对数递减权重改进粒子群的权重,用改进的粒子群算法求解未知节点坐标[11],从而提高了定位精度。张玲华等引入多通信半径方法细化节点间的跳数,且在计算未知节点平均跳距时,剔除了孤立节点,并利用锚节点得到的平均跳距进行加权归一化处理,使得未知节点定位精度提高[12],但在对所有加权参数值进行归一化处理时计算复杂度较大。这些所改进的定位算法在一定条件下均能有效地降低经典DV-Hop算法的误差,但是在节约节点能耗和减少硬件成本方面效果并不显著,且加大了整个网络的计算复杂度。
本文针对现有的DV-hop改进算法在计算平均每跳距离时和对节点通信半径内的细化跳数估计仍然存在较大误差的问题,提出一种基于杰卡德系数跳距修正的改进算法(简称JDV-Hop),引入杰卡德系数的修正因子对邻居节点间的单跳距离进行修正,并采用DDV-Hop算法中锚节点的实际位置和估计位置的差分误差系数进一步对平均跳距进行校正,最后在选择参与定位计算的锚节点时,引入一种可协作式定位的可信度因子,将定位精度较高的节点升级位锚节点,在不增加硬件成本和节省网络能耗的前提下实现更加准确的定位。
2 DV-hop算法与误差分析
2.1 传统DV-hop算法原理
DV-Hop定位算法的原理与经典的距离矢量路由算法比较相似。在DV-Hop算法中,通过计算未知节点与锚节点的最小跳数,估算平均每跳的距离,并使用跳段距离代替实际距离来计算未知节点的定位坐标。
DV-Hop算法分为以下三个阶段。
(1)计算未知节点与每个锚节点的最小跳数。锚节点向网络广播锚信息,锚信息中包含此锚节点的位置信息和一个初始值为0的跳数参数,例如{ }id,xi,yi,hi的格式。接收节点记录到每个锚节点的最小跳数,忽略来自同一个锚节点的较大跳数的分组,然后将跳数值加1,并转发给邻居节点。通过这个方法,网络中的所有节点能够记录其到每个锚节点的最小跳数。
(2)计算未知节点与锚节点的实际跳段距离。每个锚节点根据第一个阶段中记录的其他锚节点的位置信息和相距跳数,利用式(1)计算平均每跳距离。
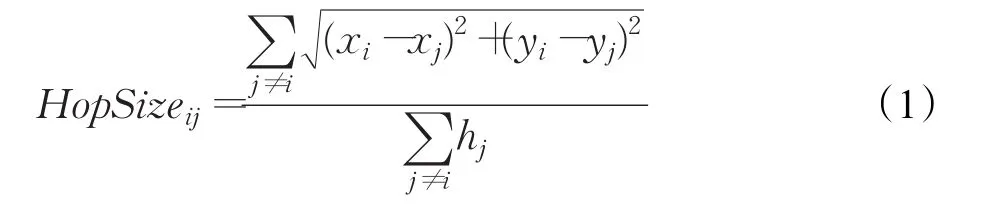
其中,(xi,yi),(xj,yj)为锚节点i,j的坐标,hi为锚节点i和 j(i≠j)之间的跳数。
然后,锚节点将计算的每跳平均距离用带有生存期字段的分组广播至网络中,未知节点仅记录接收到的第一个每跳平均距离,并转发给邻居节点。这个策略确保了绝大多数节点从最近的锚节点接收每跳平均距离值。未知节点接收到平均每跳距离后,根据记录的跳数,计算到每个锚节点的跳段距离。用hi表示某未知节点到第i个锚节点的最小跳数,则其跳段距离di为:

(3)当未知节点获得与3个或更多锚节点的距离时,利用三边测量法或极大似然估计法或最小二乘法计算自身坐标位置。
2.2 DV-Hop算法误差分析
(1)DV-Hop算法是基于网络拓扑的连通度信息,因此在测距时存在误差,而且跳数越多,累积的误差就会越来越大。无线传感器网络节点是随机分布的,而在锚节点的通信半径范围内对所有未知节点或邻居节点的跳数值都计为1跳,如图1所示,节点B,C,D均在锚节点A的通信半径中,所以与锚节点A跳数均只有一跳,但是实际距离却相差较大,如果用平均每跳距离与跳数的乘积去计算A到某未知节点的距离必定产生较大误差。
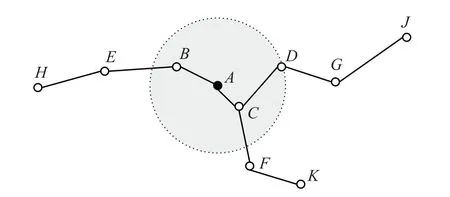
图1 通信半径内的节点跳数示意图
(2)在DV-Hop算法中未知节点用它到达锚节点的最小跳数和离它距离最近的锚节点的平均每跳距离的乘积来作为它和锚节点之间的距离,因此平均跳距的不精确容易对节点距离的计算产生较大的误差。另外,未知节点选择离自己最近的锚节点的平均跳距作为自己的平均每跳距离,而受网络拓扑结构和网络连通度的影响,单个锚节点估计的平均跳距无法准确地反映网络的实际平均跳距。
(3)DV-Hop算法在求未知节点位置时,至少需要知道3个以上锚节点的距离信息,因此锚节点的最优选取对未知节点的坐标确定极为重要。现有的大多改进算法权衡了定位精度和计算复杂度,从锚节点的共线度、未知节点与锚节点间的跳数以及整个网络的锚节点覆盖分布三个方面进行了改进[13-15]。但是在减小网络整体能耗上未能考虑到可以采用具体的阈值机制将已定位的未知节点转换为锚节点,在不降低定位精度的同时又能够节约网络的整体能耗。
3 JDV-Hop算法与改进策略
3.1 杰卡德系数与杰卡德距离
杰卡德系数又称为杰卡德相似系数,用于比较有限样本集之间的相似性与差异性。杰卡德系数值越大,样本相似度越高。定义如下:给定两个集合A,B,杰卡德系数定义为A与B交集的大小与A与B并集的大小的比值
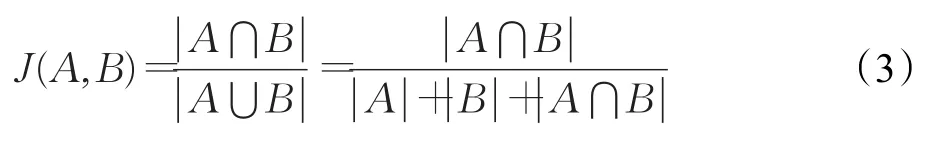
当集合A,B都为空时,J(A,B)的值为1。与杰卡德系数相关的指标叫做杰卡德距离,也用于描述集合之间的差异程度。杰卡德距离越大,样本相似程度越低。公式定义如下:
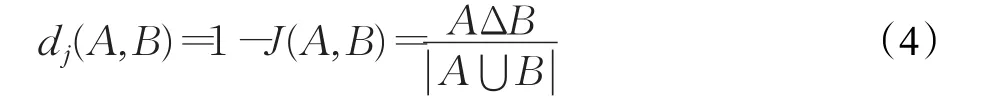
M00:A、B属性值同时为0的属性个数;
M01:A属性值为0且B属性值为1的属性个数;
M10:A属性值为1且B属性值为0的属性个数;
M11:A,B属性值同时为1的属性个数。
显然有:
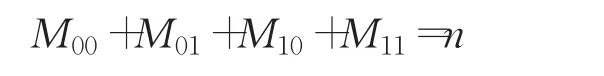
杰卡德系数:
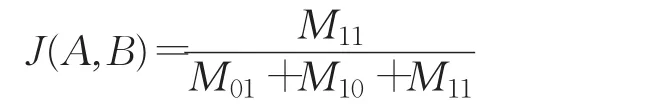
3.2 JDV-Hop的改进方法
杰卡德距离:
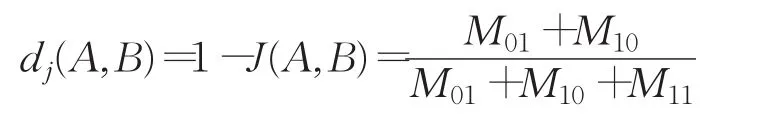
(1)杰卡德系数不仅可以比较两个集合的相似程度,也可以区分集合的差异程度。为了在DV-Hop算法中计算更加精确的平均跳距,本文将杰卡德系数引入到DV-hop算法中,在邻居节点间的通信半径范围内,利用杰卡德系数作为一种修正因子τi,对其相交区域中的节点数量进行赋值,从而进一步细化节点对其邻居节点的估计跳数,并得到更加精确的单跳距离。
在图2中锚节点A的通信半径内有很多未知节点,任取两个未知点B、C,B、C两点也有相同的通信半径,分别将A、B、C通信半径内的节点数看作是一个集合,并将节点个数计为NA、NB、NC。
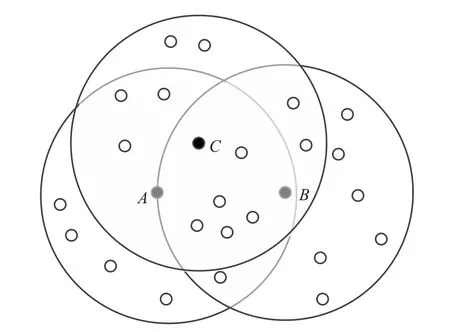
图2 节点通信半径内相交区域示意图
因此可求得节点A、B通信半径内相交区域的杰卡德系数:
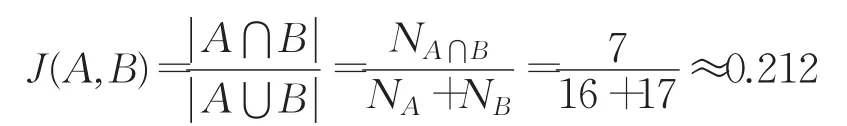
杰卡德距离为:
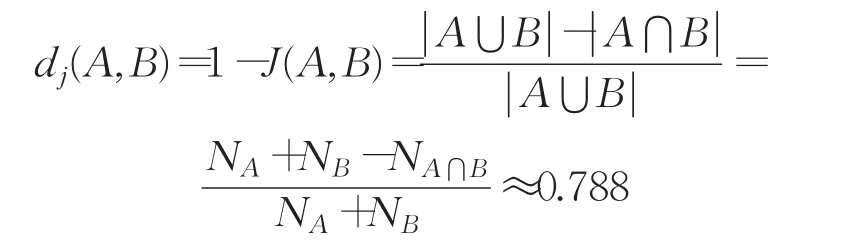
同理可以求得:
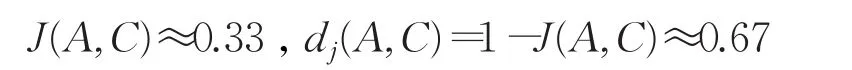
显然dj(A,B)>dj(A,C)。不难发现,在锚节点通信半径范围内任意一个较均匀分布的节点离锚节点距离的远近程度都可以用其通信范围与锚节点通信范围所相交区域节点数的杰卡德距离来表示,离得越远的杰卡德距离越大,如dj(A,B)≈0.788接近跳数1。因此引入一种基于杰卡德系数的修正因子τi,来对节点通信半径范围内的跳数进一步修正,实现更精确的平均跳距的计算。使用此方法修正得到的通信半径内的跳数为1-τi,其中τi=J(a,b),J(a,b)表示为节点a的通信半径范围内的b节点,两节点通信半径范围内相交区域集合的杰卡德系数。
(2)在利用了杰卡德系数因子修正了跳数的基础上,引入DDV-Hop的有限差分误差来改进平均跳距的计算。因为第一阶段锚节点的信息经过泛洪广播之后,所有锚节点也接收到了其他锚节点的具体跳数信息,因此可以得到一个估算的锚节点的距离,例如锚节点i和j之间的距离可以表示为:

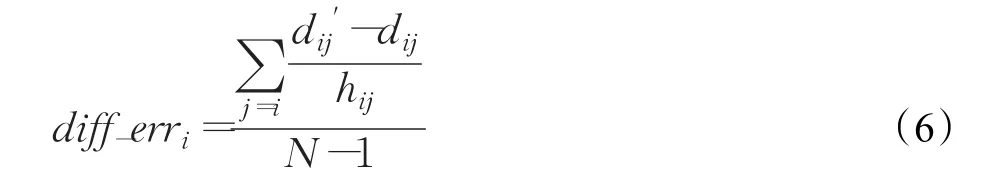
然后把所有锚节点的差分误差在全网进行广播,未知节点接收到跳数信息时,不仅保存接收到的第一个锚节点的跳距和差分误差,而且设定一个阈值Mthh,使得未知节点接收具有差分信息锚节点的数量达到Mthh时,最终可以得到一个修正误差的系数权值为式(7)。
从而得到某一点A修正后的跳距为式(8)。

其中σi是未知节点A从锚节点i获取的平均跳数的加权系数,并且Mthh与无线传感器网络节点最终定位精度的目标相关。所以假设阈值Mthh与最终定位目标成线性相关函数,比例系数为β,所以Mthh的公式为式(9)。

其中Mmax为所选取的最优锚节点集合内的节点个数。
(3)现有的多数DV-hop改进算法都是在第三阶段任取三个或者三个以上的锚节点采用三边测量法、最大似然估计法和一些改进后的最小二乘法计算待定位节点的位置坐标。协作式定位算法的基本思想是将定位后的节点有条件地升级为锚节点,对其他未知节点继续进行定位。而升级为锚节点的未知节点的自身定位精度必须要足够高,否则虽然能减少无线传感器网络整体的能耗,但是用其不准确的位置去再次估计其他未知节点的位置仍然会造成较大的误差。本文提出一种可以进行协作式定位的可信度因子,有效地将定位精度高的未知节点升级为锚节点。
例如在一个无线传感器网络里未知节点A1的位置可以通过其他三个锚节点 A2、A3、A4三边测量法得到。在对节点A1的定位结束后,得到了A1的具体位置信息,此时将A1视为锚节点,而A2、A3、A4中任选取一点(这里选作A2)作为待定位节点,并通过其他两点A3、A4和A1对其进行定位,运用三边测量法得到后的坐标为A2(xest,yest),而A2实际的坐标为(x,y),假设通信半径为R,因此A1的归一化定位误差为:
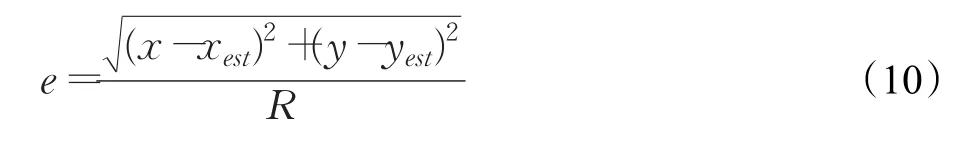
将e视作为节点间可协作式定位的可信度因子。从第二阶段的差分误差改进方法中,可以得到任意节点的可信度因子ei的阈值为式(11)。
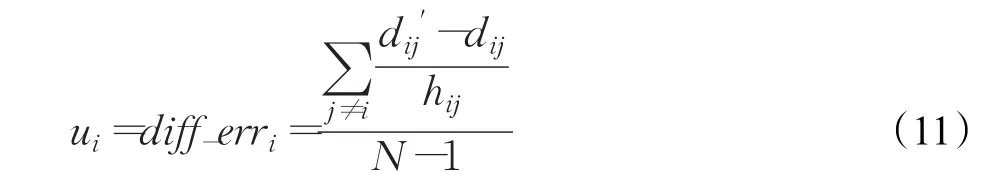
仅当节点的可信度因子满足ei≤ui时,才可以将其升级为锚节点并参与对其他未知节点进行定位计算。
4 JDV-Hop算法
4.1 算法步骤
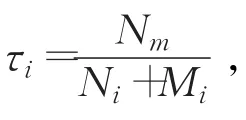
(2)当全网所有节点都接收到锚节点的信息后,可以得到每个锚节点间的欧几里德距离dij,并计算每个锚节点的平均跳距为锚节点i和j之间通过跳数与平均跳距的乘积得到的估计距离,从而得到每个锚节点的差分误差值diff_erri,并把所有锚节点的差分误差在全网进行广播,未知节点接收到跳数信息时,不仅保存接收到的第一个锚节点的跳距和差分误差。而是设定一个阈值Mthh,使得未知节点接收差分信息的锚节点数量达到Mthh,最终可以得到一个修正误差的系数权值σi;并修正未知节点的平均跳距。
(3)通过锚节点的两次泛洪信息,每个未知节点都得到与自己相连通的锚节点的个数和跳距。未知节点选取离自己较近的3个锚节点,并按照式(10)、(11)计算它们的可信度因子ei。当未知节点的可信度因子符合ei≤ui时,将其升级为锚节点并参与其他待定位节点的定位中。新的锚节点集循环以上步骤,直到网络中没有符合定位条件的未知节点为止。
4.2 算法流程图
改进的算法流程图如图3所示。
5 实验结果与分析
为了验证本文对传统DV-Hop算法和DDV-Hop算法的改进方法的可行性,使用MATLAB R2014a对DV-hop算法,DDV-hop等改进算法和本文所提出的改进算法(JDV-hop算法)进行仿真实验,并对实验结果进行对比和分析。仿真环境设定为:100 m×100 m的正方形区域,150个随机分布的节点(包括锚节点和未知节点)。节点通信半径为R。
未知节点的平均定位误差:
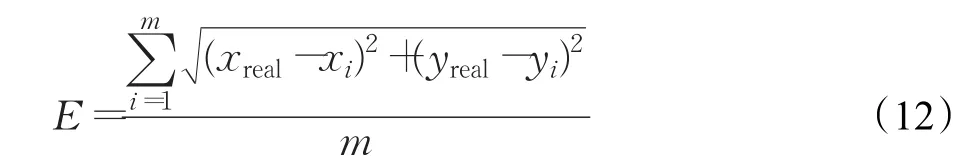
未知节点的相对定位误差:

5.1 不同通信半径下平均定位误差
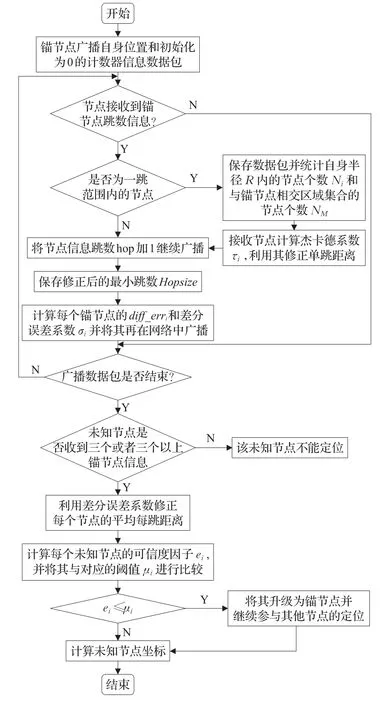
图3 改进算法流程图
在默认设定的仿真环境下,改变节点通信半径R,经典DV-Hop算法、DDV-Hop算法、文献[8]中的改进算法、文献[9]中的改进算法和本文改进算法JDV-Hop在仿真实验中随着节点通信半径从25 m增加到55 m的过程,五种不同算法的平均相对误差变化情况如图4所示。
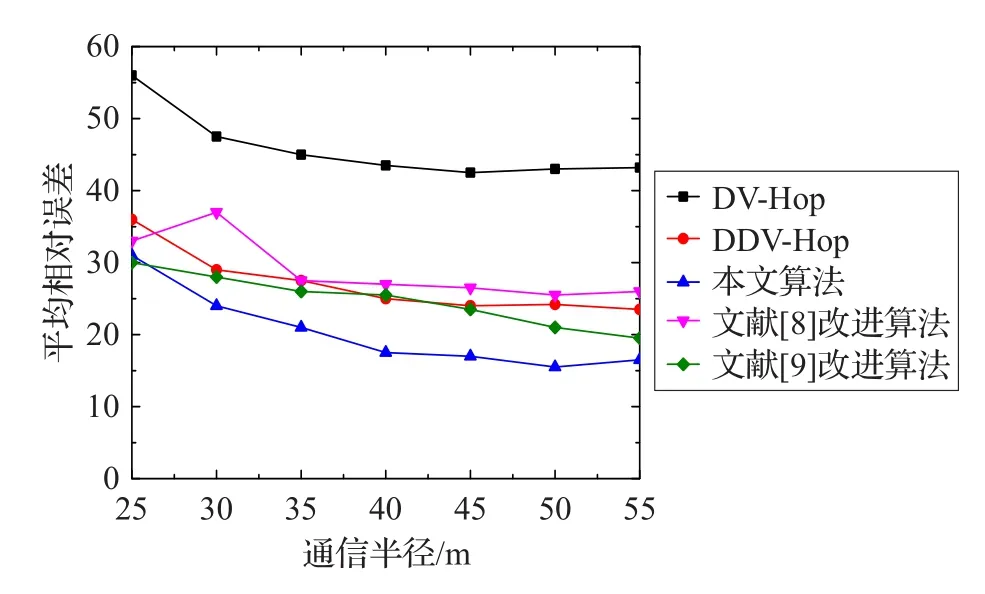
图4 相关改进算法在不同通信半径的定位误差比较图
从图4可以看出随着通信半径R的增加,五种定位算法的平均定位误差都呈下降趋势,当R>40时,DDVHop算法和文献[8]算法及JDV-Hop算法,三种算法的平均相对误差都趋于稳定,其中DDV-hop的平均定位误差比经典DV-hop算法仅下降为18.5%,而JDV-Hop改进算法的平均定位误差值比传统DV-Hop算法的平均误差值低约27%,比文献[8]的算法的误差值下降了10%,比DDV-Hop的平均误差值下降了8%,和文献[9]的改进算法相比,平均误差值也下降了3.5%。由此可知在相同的仿真环境下,当锚节点个数一定时,随着通信半径的增加,相应的网络连通度变大时,本文的改进算法能够实现更加精确的定位。
5.2 不同锚节点密度下的定位误差
在默认设定的仿真环境下,将锚节点个数从10个增加到50个(即锚节点比例从7%增大到33%)。当通信半径为30 m、40 m和50 m时几种算法的相对定位误差值与锚节点比例关系的仿真图分别如图5~图7所示。
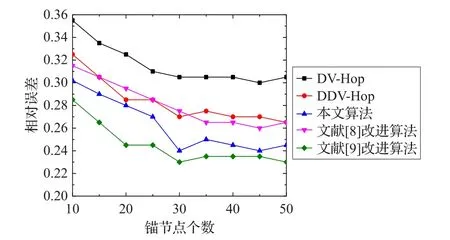
图5 通信半径为30 m时不同锚节点比例下的定位误差
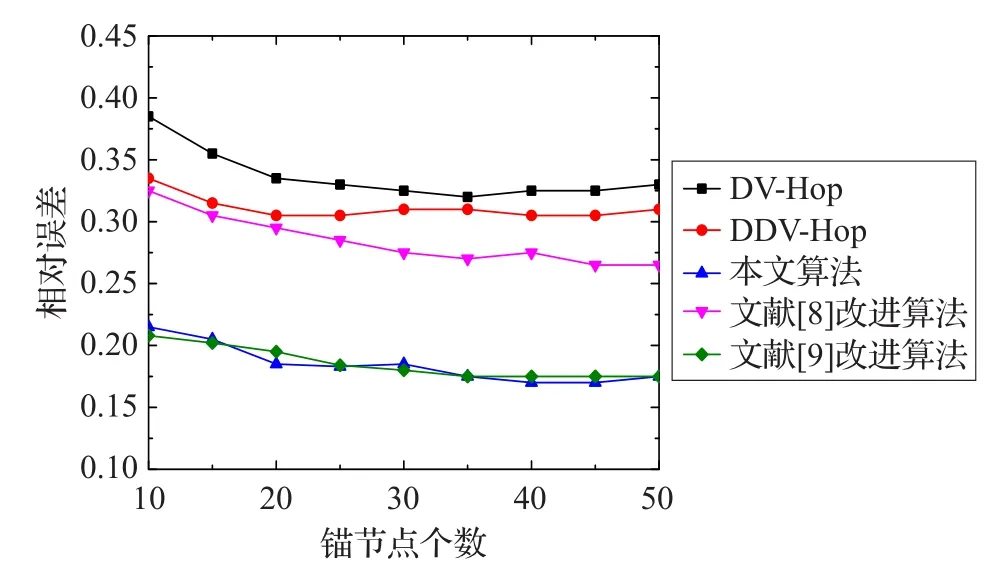
图6 通信半径为40 m时不同锚节点比例下的定位误差
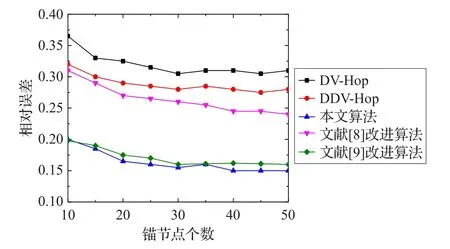
图7 通信半径为50 m时不同锚节点比例下的定位误差
在图5中,将本文改进的算法与经典DV-Hop算法、文献[8]的算法和文献[9]的算法等几种改进算法进行比较发现当锚节点个数大于30时,本文的改进算法比经典DV-Hop算法相比,误差降低了近12%,而DDV-Hop改进算法只降低了近5%。文献[9]算法因为其直接使用RSSI测距技术测量一跳距离,所以此时是平均误差最低的一种算法。
在图6中,当通信半径增加到40 m,且锚节点比例个数大于30时,五种算法的相对误差值趋于平稳,此时本文算法比传统DV-Hop定位算法的相对定位误差下降了近15%,比DDV-hop算法相比下降了近11%,在不用增加额外硬件成本的基础上就达到了和文献[9]算法定位结果较为接近的精度,且相对定位误差基本处于0.2以下,在锚节点数大于30时,达到了0.15(即控制在了15%以内)。
将图6和图7进行比较,可以看出锚节点比例个数大于30时,通信半径固定在40 m或者50 m时,随着锚节点个数的继续增加,本文改进算法比经典DV-Hop算法和DDV-Hop算法的相对误差下降了近16%,这是因为通信半径固定时,随着网络锚节点密度的增加,在节点的通信半径内会出现更多的节点,而本文所提出的JDV-Hop改进算法并没有使用文献[9]中的改进算法采用RSSI测距技术直接测量单跳距离,而是利用杰卡德系数因子细化通信半径内未知节点的跳数,并使用差分误差值进一步修正跳距,使当通信半径内的邻居节点越多,网络拓扑结构越规则时,能够实现更加精确的定位。图7仿真的实验结果显示,本文算法在不增加硬件成本和额外通信开销的基础上已经达到了和文献[9]的改进算法十分接近的定位精度。
5.3 改进算法的计算复杂度
在仿真实验中,定位算法的网络运行时间被用来当作其计算复杂度的度量。在图8中,描述了在150个节点个数,通信半径R=30 m以及不同锚节点比例的环境下,几种算法的网络运行时间的比较。
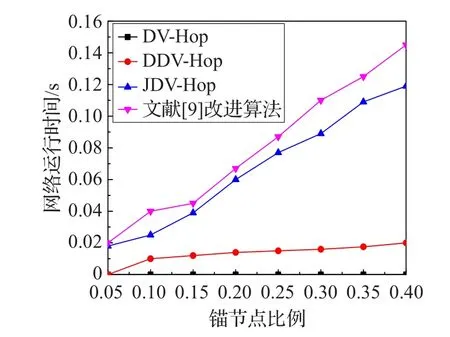
图8 不同算法的网络运行时间图
由图8可知,文献[9]的改进算法和本文所提出的JDV-Hop改进算法所需要的运行时间最多,因此这两类改进算法具有最高的计算复杂度,这也说明了文献[9]改进算法和本文所提出的JDV-Hop算法与经典DV-Hop算法相比,以一定的计算复杂度换取了更高的定位精度。而本文所提出的JDV-Hop改进算法所需要的运行时间比文献[9]的改进算法所需要的网络运行时间更少,所以其计算复杂度比文献[9]改进算法的更低,且其不需要增加硬件成本,就能够有效地减小定位误差,实现更精确的节点定位精度。
6 结束语
本文针对DV-Hop算法中对节点单跳距离内的未知节点跳数的估计所产生的误差,利用杰卡德系数的跳数修正因子细化节点间跳数,并引入DDV-hop算法中的差分误差进一步修正节点间的平均跳距,实现更精确的平均跳距计算。在选择参与定位计算的锚节点时,提出一种可协作式定位的可信度因子,将定位结果精度高的节点升级为新的锚节点,进一步减小节点定位误差和网络能耗。MALTLAB仿真实验结果表明,本文所提出的JDV-Hop改进算法与经典DV-Hop定位算法及相关改进算法相比不仅能够减小能耗,在不增加硬件成本的基础上还能够更有效地减小定位误差。未来将针对节点数目较少,锚节点覆盖率较低等研究的算法问题上作进一步的改进,使其在工程中应用广泛。
猜你喜欢
制造技术与机床(2019年6期)2019-06-25
现代电子技术(2017年7期)2017-04-14
华东师范大学学报(自然科学版)(2017年1期)2017-02-27
电脑知识与技术(2016年7期)2016-05-19
爱你(2016年13期)2016-04-11
故事会(2016年6期)2016-03-23
中外文摘(2015年3期)2015-11-22
中国海上油气(2015年3期)2015-07-01
科技资讯(2014年26期)2014-12-03
传感器与微系统(2014年5期)2014-09-25
