
对共享单车资源配置与调度的建议—以北京市为例
2018-12-03 03:17张若菡
物流技术 2018年11期
张若菡,何 颖
(1.湖南师范大学 数学与统计学院,湖南 长沙 410006;2.徐州工程学院 经济学院,江苏 徐州 221008)
1 引言
发端于传统社会的共享经济作为一个新鲜事物在我们生活中的作用正日益凸显。而享誉“中国新四大发明”之一的共享经济代表—共享单车,因其方便快捷、低碳环保的使用特质,得到人们的广泛认可,俨然已成为人们短途出行的重要交通工具之一,随着在我国的迅速发展,现已推广到国外。
毋庸置疑,共享单车以分时租赁的经营模式、便捷环保的使用方式,备受人们推崇,使其呈爆发式迅速增长,迅速普及,在某种程度上减缓了城市的拥堵状况,减少了空气污染,方便短途出行,但正是其使用时的“方便”,反而给共享单车在资源配置、管理调度上增加了困难,甚至有时反倒加剧了交通的拥堵[1]。随着市场上共享单车保有量的迅速增大,使得车辆在资源配置、运营和管理中存在的问题日渐显露。除了由于单车使用者个人素质差异造成的不按规定地点停放、乱停乱放、损坏车辆等不道德行为外,更大的问题是因行业竞争激烈,管理粗放,调度滞后,不能科学合理地配置资源、管理资源,不能科学预判投放数量,造成车辆投放地区不平衡[2]。经常出现有的地方车辆积压阻碍交通,而有的地方又“一车难求”的局面,且共享单车运营公司“各自为政”,单车投放数量盲目,比例失衡,使得某些城市的单车数量超过城市容纳量,造成极大的资源浪费。尽管很多共享单车公司为单车安装了GPS定位系统,能够实现动态化地监测车辆数据、骑行分布数据,但是如何充分利用智能化手段对共享单车科学调度、科学预测,提高车辆使用效率,减少拥堵发生,使共享单车这一新生事物健康有序的发展,是摆在我们面前亟待思考与解决的问题。
本文通过对北京市2017年一段时间内的共享单车使用情况的数据进行分析、挖掘,在数据预处理的基础上,通过建立相应的数学模型,预测北京不同区域的共享单车静态需求量以及居住区、教学区、商业区等不同区域共享单车静态需求数量的分配权重,考虑动态时间因素和单车转运的运输成本、建筑分布以及总体均衡等因素,求出北京共享单车动态需求下的合理调度方案,最后给出共享单车的经济效益分析,为共享单车在合理配置资源、科学调度、运营管理、收益分析等方面给出优化建议,以期为共享单车这一“中国式创新”事物的健康发展,为城市管理者、共享单车运营者提供参考建议[3]。
2 共享单车资源分配问题的定量分析—以北京市为例
2.1 数据预处理
由于采集得到的共享单车原始数据往往存在冗余、错误等问题,为了让进一步的数据挖掘及统计性研究有效可行,首先对采集到的数据进行预处理。
搜集到的共享单车骑乘记录数据共计20 000条。通过绘制数据散点图,发现数据中有部分离群的异常点,于是运用LOF算法(局部异常因子算法)剥除了6个数据点,得到了19 994条可用数据。
2.2 共享单车的静态需求量模型
2.2.1 空间特征分析。要想使资源分配趋于合理,需要分析不同时空下的共享单车的需求量。若仅对空间而言,共享单车的空间分布往往成集群分布,这体现了空间分布的不均衡性,而这种不均衡往往是不同空间所具有的固定属性决定的。在分析空间分布与需求量的关系时,考虑了空间固有的四个不同的固定属性,分别是:骑乘者基数、骑乘者密度、附近交通设施数与附近骑乘目的地密集度。
骑乘者基数可由常住人口密度决定,搜集的数据是2017年一段时间内北京市的骑乘数据,因此查找了北京市不同区域常住人口密度。对于空间中给定的坐标点,选定与其最近的区域中心人口密度近似替代该点的常住人口密度。根据调查,对于市区而言,共享单车往往会与其他公共交通工具起到竞争的关系,因此采集了北京市地铁口的坐标,计算出这些坐标与骑车出发点的最短距离,作为第二项指标。
为了得到与骑乘者密度以及骑乘目的地相关的数据,通过K-means聚类算法,对骑行出发点与骑行目的地这两项数据进行了聚类分析[4]。由于北京市面积较大,选择使用30个质心进行聚类分析。经过多次迭代,得到聚类效果图如图1、图2所示。
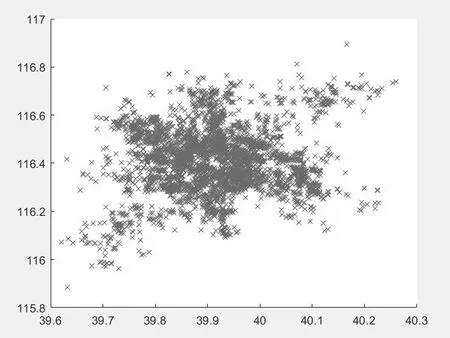
图1 乘车起点聚类分析效果图
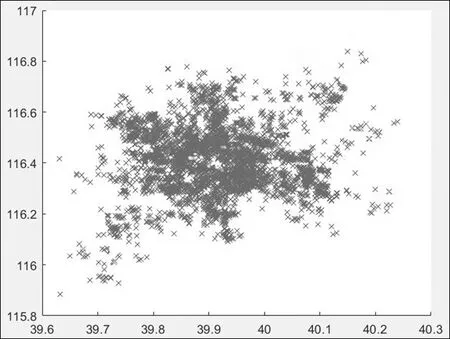
图2 乘车终点聚类分析效果图
聚类分析得到的质心,虽然并不一定恰好与骑乘者最密集的中心,即骑乘者最常去的目的地相吻合,但相差不大,可忽略不计。通过Google地图对聚类分析得到的质心进行了考察,发现质心基本都落在密集的居民区或商业区,这也证明了前面的猜想。为了得到具体指标,参考LOF算法中的核心思想,将某一给定坐标点到骑乘出发点聚类质心的第k距离作为体现骑乘者密度的指标,将某一给定坐标点到骑乘目的地聚类质心的第k距离作为体现附近骑乘目的地密集度的指标。其中,第k距离即对于A3、A4指标,将乘车起点对于聚类质心的第k距离作为指标d(p,o)(两点p和o之间的距离)。
对于点p的第k距离dk(p)定义如下:dk(p)=d(p,o),并且满足在集合中至少有不包括p在内的k个点o'∈C{x≠p} ,满足d(p,o')≤d(p,o);在集合中最多有不包括p在内的k-1个点满足d(p,o')≤d(p,o);p的第k距离,也就是距离p第k远的点的距离,不包括p,如图3所示:
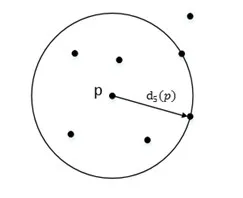
图3 p的第k距离定义示意图
这里选择k=1,得到相应的指标后,在MATLAB上使用libsvm3.2通过支持向量机回归建立空间特征与需求量的关系模型[5]。随机选择了1 000个数据作为训练集,同时用100个数据作为测试。在进行支持向量机训练时,使用差分进化算法,对支持向量机的两个参数c、g进行优化寻参数,其迭代过程如图4所示。

图4 差分进化算法迭代次数
最终构建了支持向量机回归模型,其数据回测图和残差图如图5、图6所示。
此处得到的预测值再乘以19 994,即为预测的单位空间内一天的共享单车需求数量。其中预测数据的均方误差(MSE)为2.770 5×10-4。
2.2.2 时间特征分析。通过前面的分析,得到了支持向量机回归模型,输入四个指标即可得到某一空间一天的需求总量。下面,为了能得到某一空间在不同时间段中的需求量,对19 994条数据样本进行了统计性分析,条形统计图如图7所示。
为了使需求量的预测结果尽量精确,将原本以分钟为精确度的数据转换为以小时为精确度的数据,由此可得到每小时不同时间段乘车数量的占比。故只需将支持向量机回归预测得到的需求量与规定的时间段乘车数量的占比相乘即可获得特定时空下的需求量。由此完整分析了不同时空下的需求量[6]。
2.2.3 各地区共享单车数量的分配权重。为了得到每个子空间内部的共享单车分配方案,选取了四个典型的地区,以及五个主要因素建立需求最高地区的层次分析模型。如图8所示。
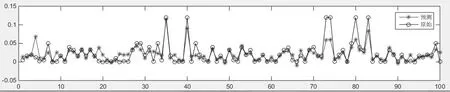
图5 SVR数据回测图

图6 残差图

图7 时间分布条形统计图

图8 层次分析模型
根据共享单车的情况,结合层次分析结构中的各种因素,构造判断矩阵如下:


通过求解得权重向量如下:
wA=(0.428 2,0.230 2,0.168 7,0.105 7,0.067 2),一致性比率为CRA=0.038 4;
wB1=(0.255 3,0.148 6,0.550 7,0.045 5),一致性比率为CRB1=0.049 0;
wB2=(0.255 3,0.148 6,0.550 7,0.045 5),一致性比率为CRB2=0.048 6;
wB3=(0.310 6,0.149 0,0.490 6,0.049 8),一致性比率为CRB3=0.071 8;
wB4=(0.295 4,0.137 9,0.490 4,0.076 3),一致性比率为CRB4=0.098 8;
wB5=(0.155 1,0.283 7,0.085 4,0.479 8),一致性比率为CRB5=0.043 2。
最后求得各地区对目标层的权重,即各地区共享单车数量的分配权重,见表1。

表1 各地区共享单车数量的分配权重
2.3 共享单车的动态需求量调度模型
2.3.1 车辆流动模型。上一部分为了建立可以适用于整个大范围区域,可以准确预测其每个各异的子空间共享单车需求量的回归模型,更多地关注于不同区域不同地区固有的空间特征,选择性地忽略了一些时间特征,因此建立的模型属于静态的需求量模型,可以反映某一区域某个特定时段对共享单车的需求量,却无法反映某时段、某区域共享单车使用数量的变化,从而无法反映供求关系是否失衡。而解决共享单车调度问题,还需建立动态的车辆流动模型,在上一部分基础上对该地区的共享单车动态变化进行进一步的分析。
实际生活中,共享单车的调度能力是有限的,考虑到调度中心人力资源有限这一影响因素,规定共享单车调度中心一天只进行两次调度,分别对应于使用早高峰与晚高峰时段。定义时间t内单位子空间的需求变化量为Pt。通过计算早高峰时间段(07:00—09:00)和晚高峰时段(16:00—19:00)以及一整天的Pt,绘制出热力图,如图9—图11所示。

图9 单日需求变化热力图
由热力图可以看出,无论是在早高峰还是晚高峰,需求量增加最多的地区基本处在北京市中心地带。
2.3.2 共享单车动态需求量调度的双目标规划模型。为了能更好地分析整个北京城中的局部动态变化,将数据中所覆盖的北京城区,均匀地分为100个子空间,如图12所示。由左上角第一个子区域开始向右分别标号为(1,2,…,100)。进而将问题转化为研究每一块子空间之间共享单车数量的变化量以及共享单车调度方法。通过MATLAB中的numel函数得到了将北京市划分为100个均匀子区间后的需求矩阵,并分别计算了早高峰以及晚高峰的需求变化量矩阵。

图10 早高峰需求变化热力图

图11 晚高峰需求变化热力图

图12 北京市空间分区图
为了建立共享单车的调度方案,依据计算得到的早、晚高峰期需求变化矩阵,将这些子空间划分为供不应求、供给过剩、供求均衡三种类型。这里选择Pt<0为供不应求,Pt>0为供给过剩,Pt=0为供求均衡。在调度方案中,由供给过剩的子空间向供不应求的子空间调度共享单车,而供求均衡的子空间则可以根据子空间中实际的建筑分布情况,派遣人员对子空间中的共享单车按照静态的需求量模型中的权重比例进行调度。对于供给过剩与供不应求的子空间,定义了全局共享单车分布不均衡度K。
为了让整个市区在全局上拥有良好的共享单车分布状态,需要让子空间互相调度单车,从而令目标K最小化。而对于每个子空间自身的内部调度,则需要考察子空间内的建筑分布,按照静态的需求量模型中的结论进行调度[7]。在保证全局均衡度尽可能达到目标的前提下,考虑到北京市区空间跨度大,单车的转运需要耗费较多的财力、人力,建立双目标规划模型如下。
目标函数为:
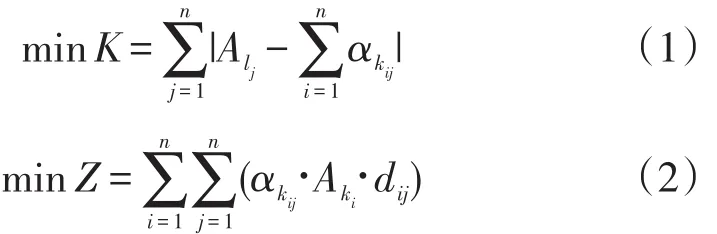
约束条件为:

在目标规划中,单车空间分布的不合理将会造成乘客使用率减少,交通阻塞等现象。这些现象均会直接或间接地对经济造成一定的影响,故可以对两个目标进行加权,此处对运输成本加权d0,从而将双目标规划问题转换为单目标规划。

使用模拟退火算法对上述模型进行求解,求解步骤如下:
(1)求解货车行驶距离。A、B两点的地理坐标分别为(x1,y1),(x2,y2),由于地球表面不是平面而是球面,故两点的实际距离为A、B两点的劣弧长。地球半径为R=6 370km,则A、B两点坐标可表示为:

A、B两点实际距离为:

由式(5)可以得到两个子空间的实际距离,用以近视替代货车行驶的路程。
(2)产生初始解。通过rand函数随机获得一个匹配矩阵与匹配权重矩阵,通过多次循环选择其中目标值D最小的两个矩阵作为初始解。
(3)产生新解。通过rand函数获得随机的nk与两个随机的nl的新匹配方式,以及随机分配的新权重。
(4)计算适应性,重复直到退火过程结束。如果新的匹配方式与权重得到的目标值更小,则将匹配方式与权重替换掉原本的匹配矩阵与匹配参数。
此处由于篇幅问题,仅给出求解得出的早高峰过后的调度方案,见表2。
3 共享单车经济效益分析与建议
目前,共享单车企业资金来源为融资和投资,主要收入来源为单车租金。在共享单车的运营过程中,大多数都出现了亏损的现象。由于共享单车押金、融资方面的内容缺少数据支撑,暂不对这些方面进行分析,沿用前面的结论,仅就收取骑乘费这一方面,提出新的经营模式并进行论证。传统的骑乘费用都以骑乘时长为主要参考度,对于使用过程中出现的特殊情况,如恶意毁坏单车时会加收骑乘费等不做考虑。利用共享单车的时间分布具有双峰性,而空间上具有集群性这些特点,可以考虑在骑乘高峰期加收费用,即于早07:00—09:00,晚16:00—19:00这两个时间段进行骑乘费用的加收。同时可以在节假日提供免费骑乘的活动作为加收骑乘费用的补偿。

表2 早高峰过后的调度方案
根据上面的运营方案,使用计算机进行模拟,在周一至周六的骑乘高峰期进行50%的费用加收,而周日全天免费使用。根据模拟得到这样的结果:传统收费方式一周仅获利139 958元,采用高峰时段加收费,周末回馈的方式,一周可以获利146 013元。提高使用高峰期收费所得利润如图13所示。
据此,又对10%—100%的提价区间进行了进一步分析,发现若乘客的骑乘数量不减少,仅需要提高40%的骑乘费即可达到传统收益的水平[8]。但由于市场经济规律的影响,骑乘费的提高往往会带来骑乘数量的下降,所以要想对这个问题进行精确的研究,还需要再对不同品牌的共享单车之间的竞争因素做进一步调查,从而得到更多的数据再做进一步分析。
4 结语
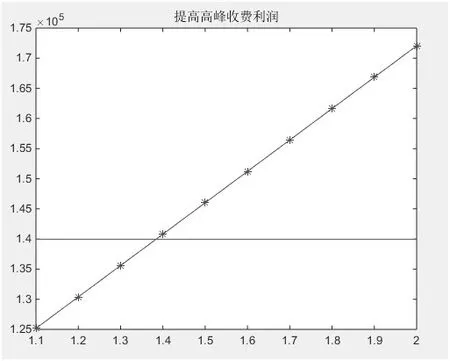
图13 提高高峰期收费利润
本文对北京市2017年一段时间内的共享单车使用情况进行了数据分析和挖掘,通过建立数学模型,预测了北京不同区域的共享单车静态需求量以及居住区、教学区、商业区等不同区域共享单车静态需求数量的分配权重,考虑动态时间因素和单车转运的运输成本、建筑分布以及总体均衡等因素,求出了北京共享单车动态需求下的合理调度方案,最后,给出了共享单车的经济效益分析。该研究结果符合北京市共享单车的实际情况,为解决共享单车的需求、调度、管理等提供了一定的决策参考。同时,该研究方法也为其他城市解决共享单车问题提供了参考建议。
猜你喜欢
意林彩版(2022年1期)2022-05-03
数学大王·中高年级(2021年6期)2021-09-27
现代畜牧科技(2021年5期)2021-07-20
读友·少年文学(清雅版)(2020年1期)2020-05-20
科学导报·学术(2020年12期)2020-04-14
当代水产(2020年2期)2020-03-17
玩具世界(2019年5期)2019-11-25
中国自行车(2017年5期)2017-06-24
领导决策信息(2017年9期)2017-05-04
岷峨诗稿(2017年4期)2017-04-20
