
我国区域经济结构的计量分型及差异进化度量
2018-12-03 11:39周晓宇
统计与决策 2018年21期
周晓宇
(1.厦门大学 管理学院,福建 厦门 361005;2.重庆大学 经济与工商管理学院,重庆 400044)
0 引言
随着中国经济经过刘易斯拐点,供给侧因素导致经济增长放缓[1]。目前,我国面临经济转型发展的紧迫任务,为了成功实现经济的顺利转型就需要对经济结构的内生环境有所了解,尤其是对不同地区经济间的差异性和相似性进行分析和度量并在此基础上探索转型的可能方向和评估转型的难易程度,本文就这些方面进行了探索。
近年来,经济发达地区的转型速度明显快于欠发达地区,这些可以从资本形成和结构性指标的定量分析中反映出来[2]。我国东部地区的全要素生产率上升,中西部地区略有下降[3,4]。在统计分析上如果选择的地理单元过大,可能导致忽略了区域单元内部的相关性[5],本文建立了相关评估模型对区域经济发展趋势在实证分析的基础上进行考证分析,有利于从微观上把握经济的变化和整体走向。
1 数据处理及量化分型规则提取
传统上对地区经济进行计量统计分析时缺乏一种从不同数据粒度层次上对区域经济进行分型研究的计量方法,难以探索经济分型中的共性规律。本文根据经济发展的统计指标数据,通过横向的比较进行分类并结合地区或区块的年度纵向变化进行定量分析,同时获得横向对比和纵向变化两个维度上的经济变动趋势。
选取了十类有代表性的经济统计指标作为经济内涵分析的依据(见表1),地区名称与序号的对应见表2,采用模糊集的分类方法按指标进行量化,产生的各区块为某种指标下的量化分型,为研究不同经济类型间的进化和转型提供了客观依据。
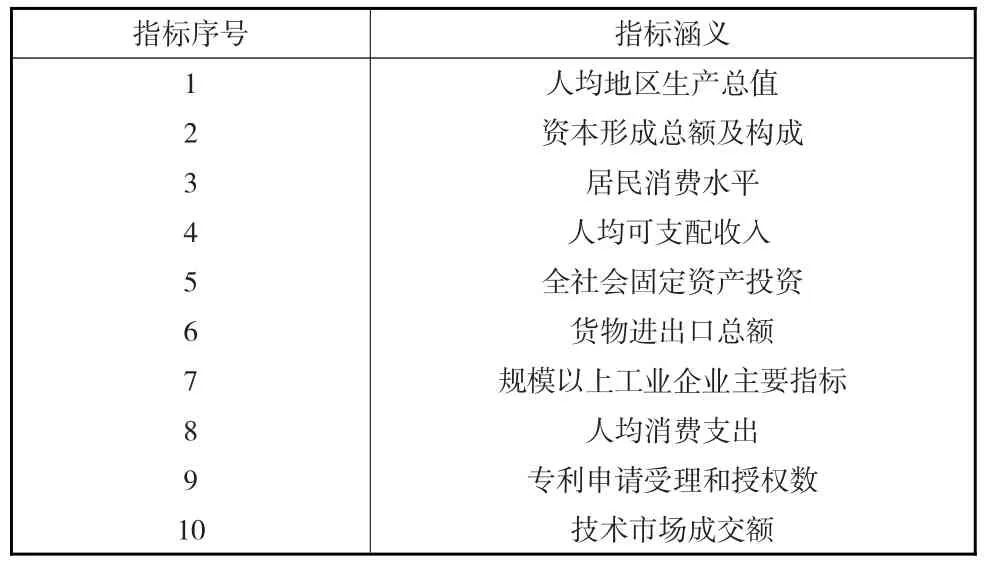
表1 指标序号与涵义
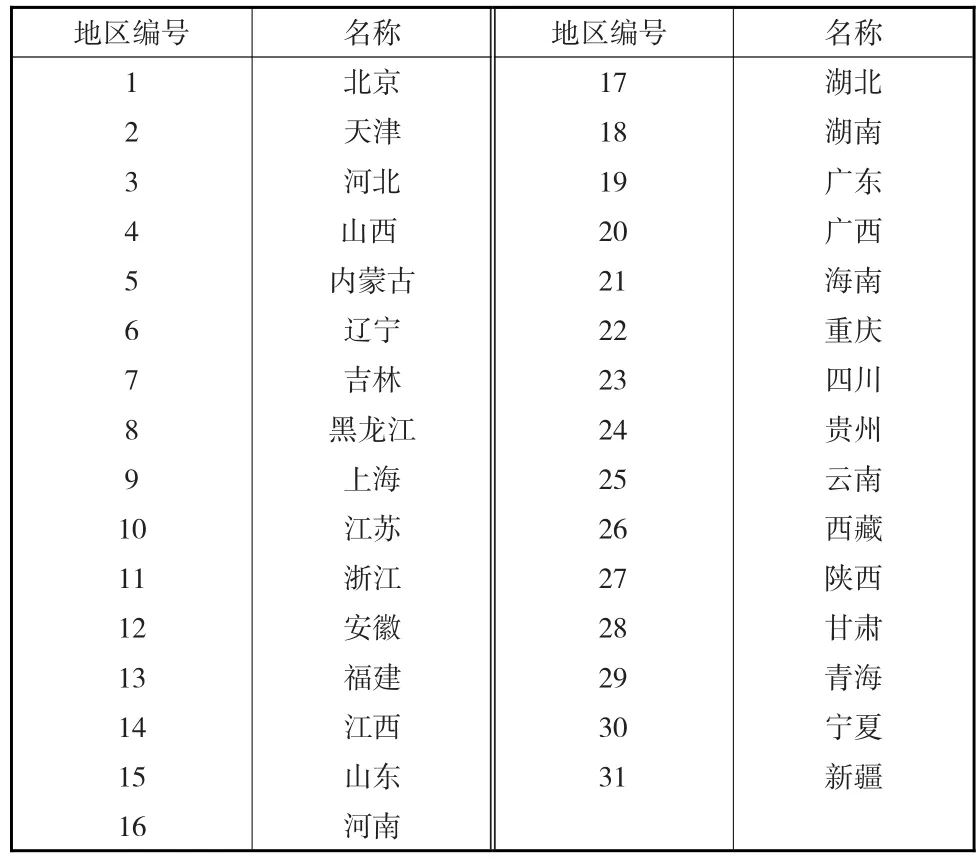
表2 地区序号与名称
1.1 分类模糊隶属度函数定义
为了客观地体现统计指标的等级变化情况,分别定义了三种隶属度函数:μ_lοw,μ_med,μ_high,,以对应“低”、“中”、“高”三种模糊判定观点。
(1)计算统计指标数据F的分段均值:
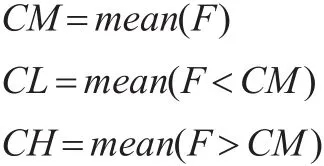
其中,CM为F全部数据的均值,CL为F中低于CM的那些数据的分段均值,CH为F中高于CM的那些数据的分段均值。
(2)定义模糊隶属度函数
设指标数据集为F,F的最小值minF=min{fi|fi∈F},F的最大值maxF=max{fi|fi∈F}。
“低”、“中”、“高”三种模糊隶属度函数定义为:

1.2 分类规则的确定
(1)对三种隶属度函数值进行离散化:
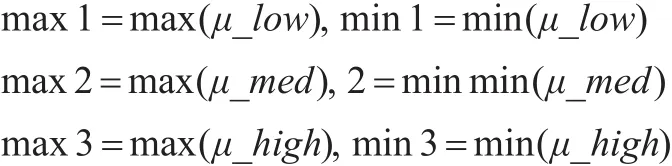
将每个区间 [mini,maxi] (i=1,2, 3)的隶属函数μ_lοw,μ_med,μ_high,值均匀离散化为 0,1,2三个等级。
(2)根据三种隶属度的等级值通过计算机算法挖掘抽取出典型的10种分类规则并给出相应的等级分值m(见表 3)。
根据国家统计局发布的2010—2014统计年鉴数据对各地区的指标数据进行模糊分类,得到当年不同统计指标下的分类区块,其中等级分值相同的地区被归入到同一区块中,有利于实现计量的客观性和可比性。表4给出了2012—2014年三个年度关于“人均地区生产总值”、“资本形成总额及构成”、“居民消费水平”三个指标(分别对应“指标1,2,3”)下的原始分类区块及其等级分值(例如,[20 24 25 26 28]表示由地区[广西、贵州、云南、西藏、甘肃]组成的区块)。
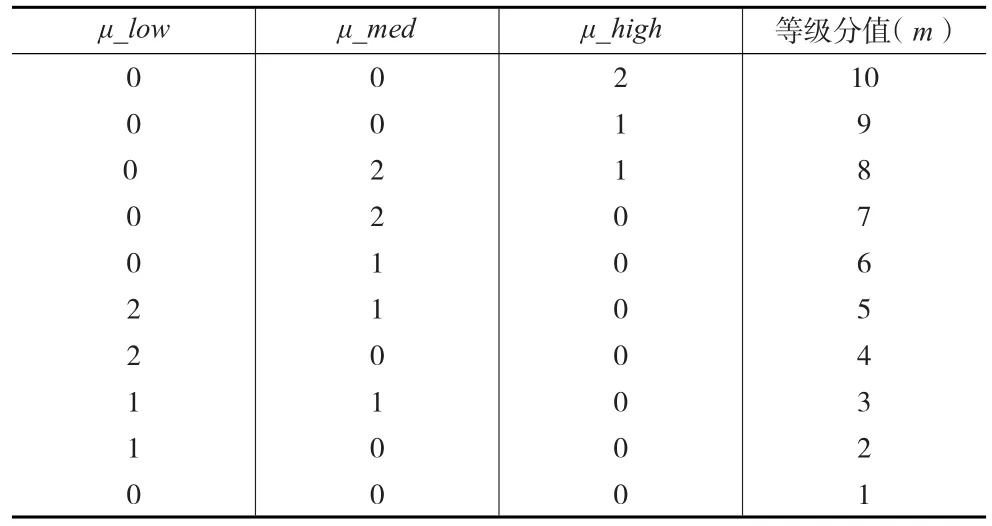
表3 分类决策规则及等级分值
2 经济内涵评估模型
在确定了数据的分类规则的基础上,为了按经济指标分区块进行定量分析,建立了评价体系从而实现经济内涵的挖掘,以发现数据背后隐藏的规律性内容。经济活动的聚集被经济学家视为现代经济增长的一个典型事实[6],考虑到一种经济指标代表着该指标涵义下的某种经济表现,为了对一个地区的经济表现进行评价并与其他地区进行对比,在所选的十类经济指标的基础上通过定义并计算相关指数来进行分析衡量。
①分地区的指标聚集度(Area_IA):
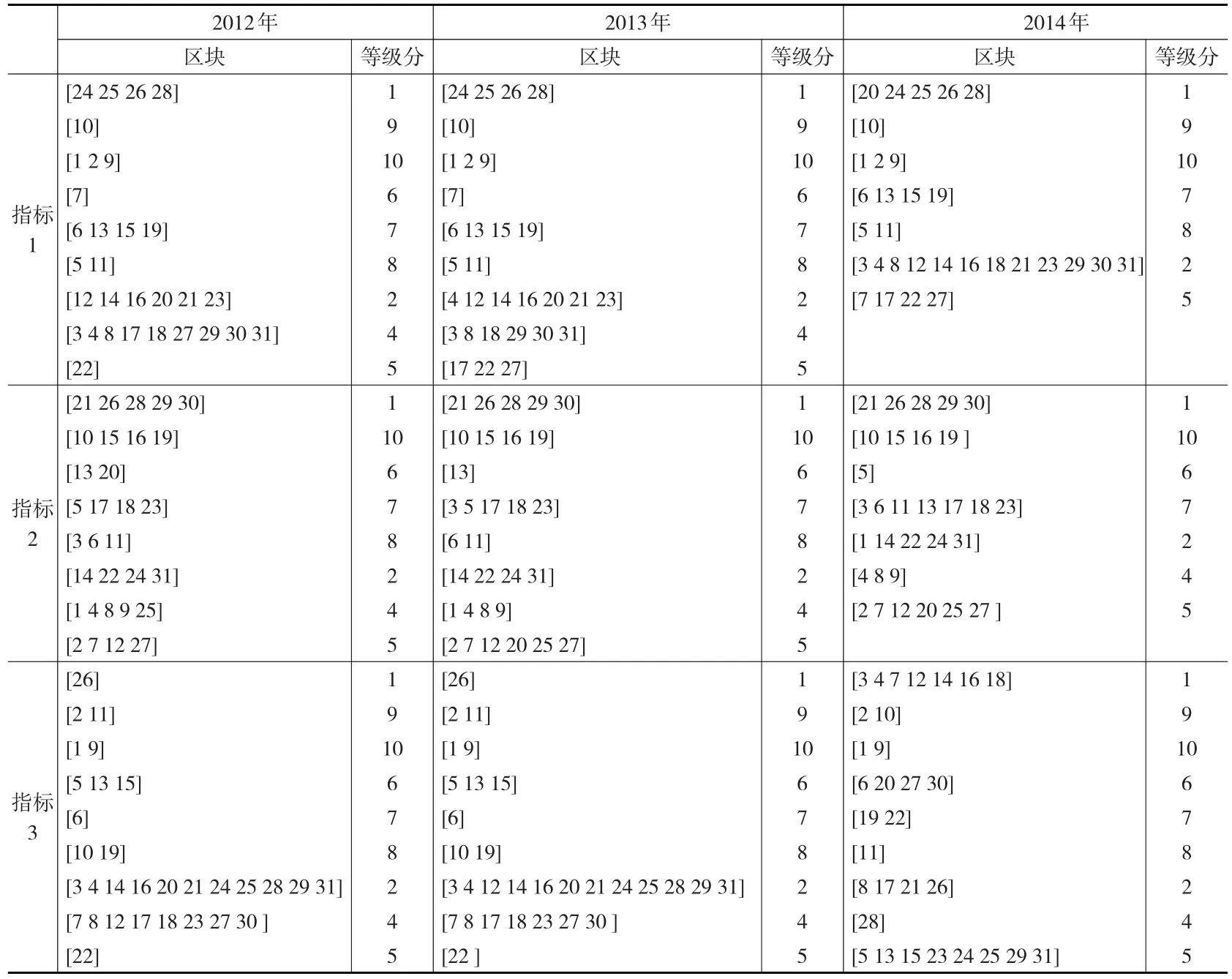
表4 2012—2014年指标1,2,3数据的原始分类区块及其等级分值
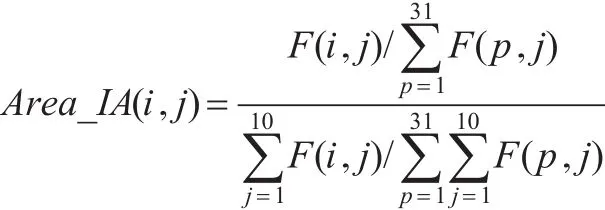
其中,F(i,j)是“地区i”在“指标j”下的数据,F(p,j)是“地区p”在“指标j”下的数据(地区总数为31个省区或直辖市,指标共10类,详见表1)。
②经济区块的当量聚集度(CLS_IA):在计算了分地区的指标聚集度后,根据区块中包含的地区可以计算该区块相对于其他指标涵义下的当量聚集度情况,其意义在于衡量由某个经济指标涵义下产生的经济区块在另一个指标涵义下的经济表现,以便建立起跨指标间的当量对比关系,从而反映出某个指标区块在其他指标涵义下的经济特征,体现的是经济分型的宏观统计意义。
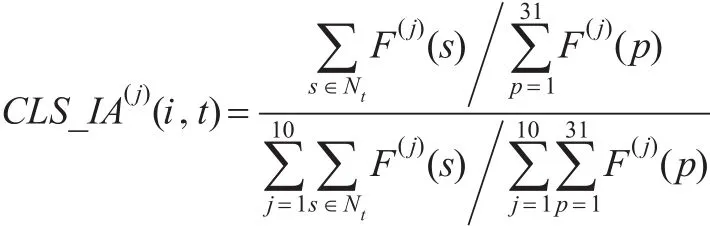
其中,CLS_IA(j)(i,t)是指标i的区块t相对于指标j
的数据之和(Nt是区块t所包含的地区序号的集合),是指标j的全部31个地区的数据之和,是区块t包含的地区在全部10个指标下的数据之和,是全部10个指标下全部31个地区的指标数据之和。
③指标区块的当量转移概率矩阵(P):为了对某个经济指标i下的某个区块t与其他经济指标k(k≠i)建立当量对比关系,便于在跨指标的经济因素间进行横向转移当量对比,通过建立如下的当量转移概率矩阵来衡量。
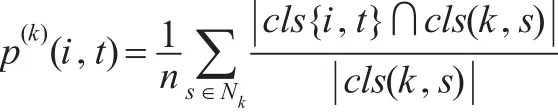
其中,p(k)(i,t)表示指标i下的某个区块t转移到指标k(k≠i)下的当量转移概率;Nk为指标k下分类出的全部区块;cls{i,t}为指标i下的区块t中的地区序号集,cls(k,s)为指标k的区块s中的地区序号集为两个不同区块交集中相同的地区序号总数;n是地区序号总数。
④指标区块的等级分值转移当量指数(SHR):等级分值转移当量表征某个指标区块中的地区转移到其他指标区块中的当量难度系数,该值越小则转移的难度越小,反之则越大。该指数度量了不同经济分型间转型的难易程度。
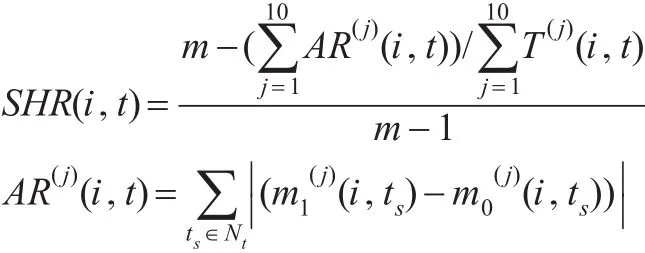
其中,SHR(i,t)表示指标i的区块t(其所包含的全部地区序号集为Nt)的转移当量指数,m1(j)(i,ts)是指标i的区块t中包含的地区ts在指标j下当年的等级分值,为其上一年的等级分值,AR(j)(i,t)为区块t在相邻两个年度的等级分差,T(j)(i,t)为该区块包含的地区在指标j下等级分差不为零的地区数。
模糊分类规则挖掘形成的区块从“等级意义”上讲表征了一定的经济分型,涵盖了“发达”、“中等发达”和“不发达”等情况。区块的等级分值从最高分值m(本文m=10)到最低分1共跨越了m-1个等级梯度。通过计算不同分型之间的等级转移当量,可确定不同分型转换的当量难易程度,为经济的转型比较提供客观依据。
⑤分地区的经济丰度指数(ER):为表征不同地区在各指标所代表的经济发展方面的均衡性,从经济生态学的角度定义了地区经济丰度指数。该指数综合考察地区间的横向对比、不同经济指标下地区的分类等级以及聚集度下的量化度量。
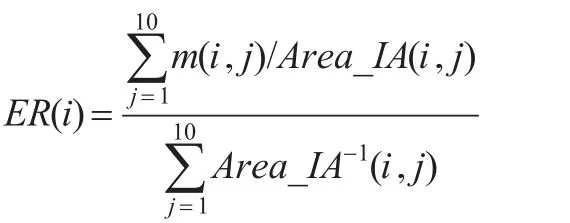
其中,ER(i)是地区i的经济丰度指数,m(i,j)是地区i关于指标j的分类等级分值,Area_IA(i,j)是地区i在指标j下的指标聚集度。该指数越大则地区的经济均衡性越好,反之均衡性越差。
⑥指标区块的经济丰度系数(CLS_ER):
为了对经济指标涵义下不同等级分值区块所代表的经济生态进行评估,通过建立指标区块的经济丰度系数来衡量其代表的经济生态环境的变动情况,它反映出各类指标下的经济类型在某年度经济结构的相对变化以及与不同年度同等分值区块的纵向对比关系,从而发现不同年度不同等级的经济结构的变动规律,为宏观经济的整体走向变化提供量化依据。
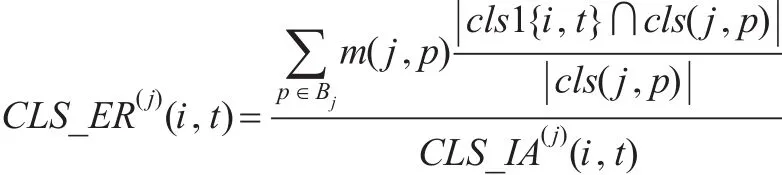
其中,CLS_ER(j)(i,t)为指标i的区块t关于指标j的丰度系数,m(j,p)是指标j的区块p的等级分值,Bj是指标j下的所有区块集合。
⑦指标区块的进化质量(Q):不同的经济分型的经济进化体现的是分型区块间的横向对比关系,并且考虑了发展趋势的强弱变化。这些因素的综合能够客观地度量经济分型的进化发展潜力,是对进化质量的定量描述。
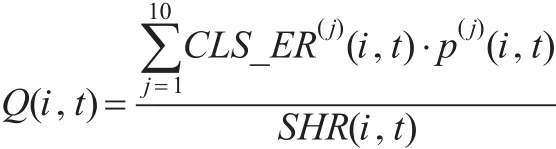
其中,Q(i,t)是指标i的区块t的进化质量,p(j)(i,t)是指标i的区块t转移到指标j下的当量转移概率,SHR(i,t)是区块t的等级分值转移当量指数。区块的进化质量衡量了某个指标区块所代表的经济类型朝结构优化方向改变的能力或趋势的强弱。
⑧分地区的经济差异进化指数(EDI):该指数衡量指标聚集度的整体变化与地区经济进化的关系。

其中,F(1)(i,j)为地区i关于指标j的本年度的值,F(0)(i,j)为其上一年度的值,m(1)(i,j)为地区i关于指标j在本年度的等级分值,m(0)(i,j)为其上一年度的等级分值,Area_IA(1)(i,j)为地区i在指标j下本年度的指标聚集度,Area_IA(0)(i,j)为其上一年度的指标聚集度。经济差异进化指数衡量了地区经济在纵向和横向两个方向上的综合进化情况。
3 实证分析
我国自经济改革以来,区域间的经济差距扩大,探究经济发展轨迹需从地域角度在统计数据的基础进行分析研究。研究问题包括:(1)经济活动的聚集度在不同地区的表现;(2)经济活动的聚集度与经济进化的关联;(3)经济发达地区与欠发达地区的经济结构的差异和特点等。
统计数据表明,我国发达地区的经济发展更加均衡,表现在指标的聚集度上,该类地区的年度指标聚集度变化不明显。表5给出了地区经济丰度指数的各年度值。模糊分类得出江苏、广东为一类,该类地区的丰度指数最高且保持了一定的稳定性,说明该类地区的经济结构较为均衡,北京、上海、浙江、山东等地区为一类,其丰度指数也较高,它们是我国经济和技术实力较雄厚的沿海地区和一线直辖市;天津、辽宁、福建、重庆、陕西同属一类,其丰度指数适中,它们是近几年经济增长较快的地区,经济结构的客观表现与经济丰度指数较为吻合,这一点可从地区差异进化指数上反映出来(见表6);其余地区的丰度指数较低,其经济结构还有一定的优化空间,但这类地区中某些省份的发展潜力还是明显的,例如,结合地区差异进化指数可以发现,广西和贵州两省2014年的差异进化指数都达到2.0以上,具有一定的进化潜力,这种结果与其他文献的分析结果是吻合的[7]。
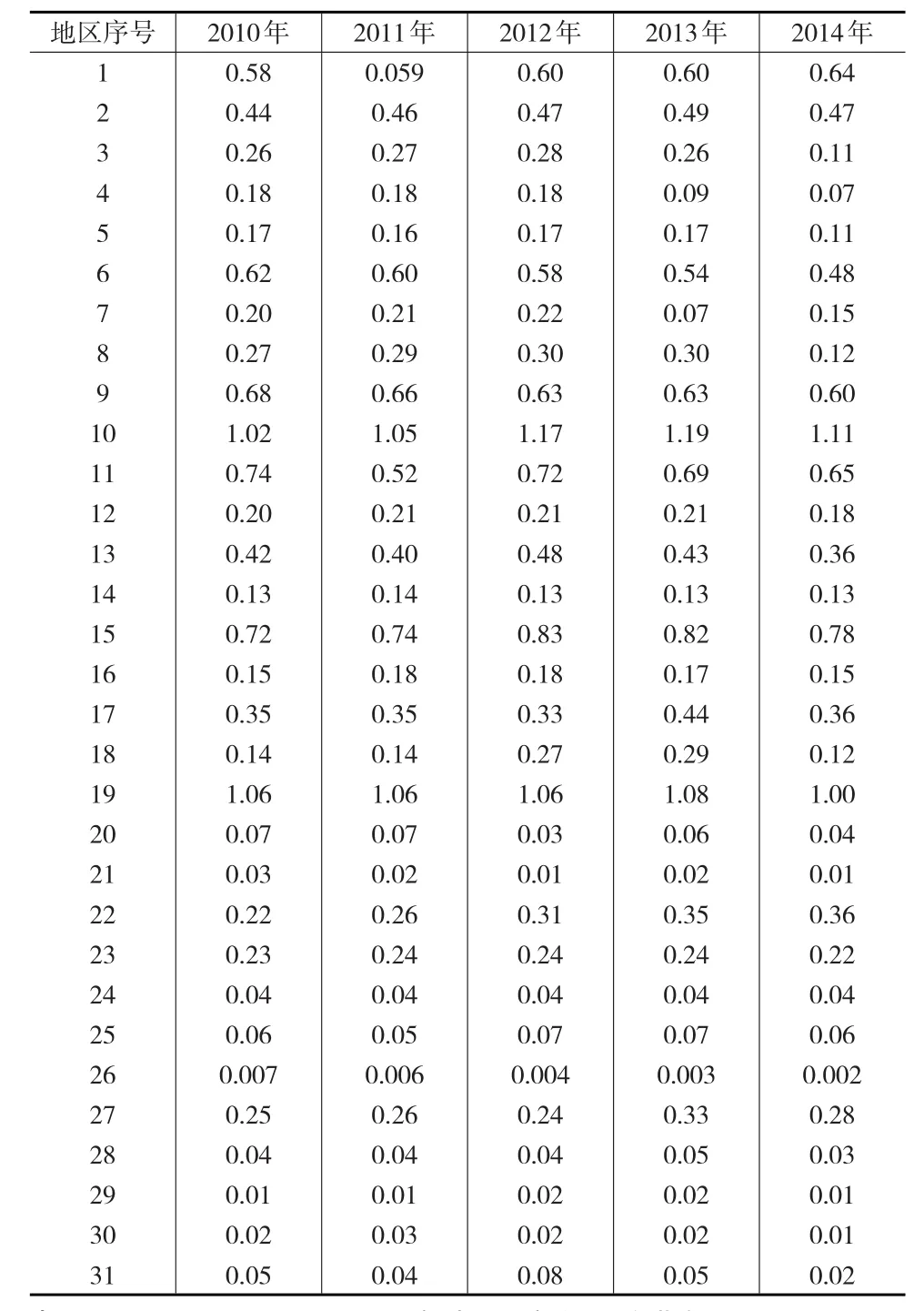
表5 2010—2014年地区经济丰度指数
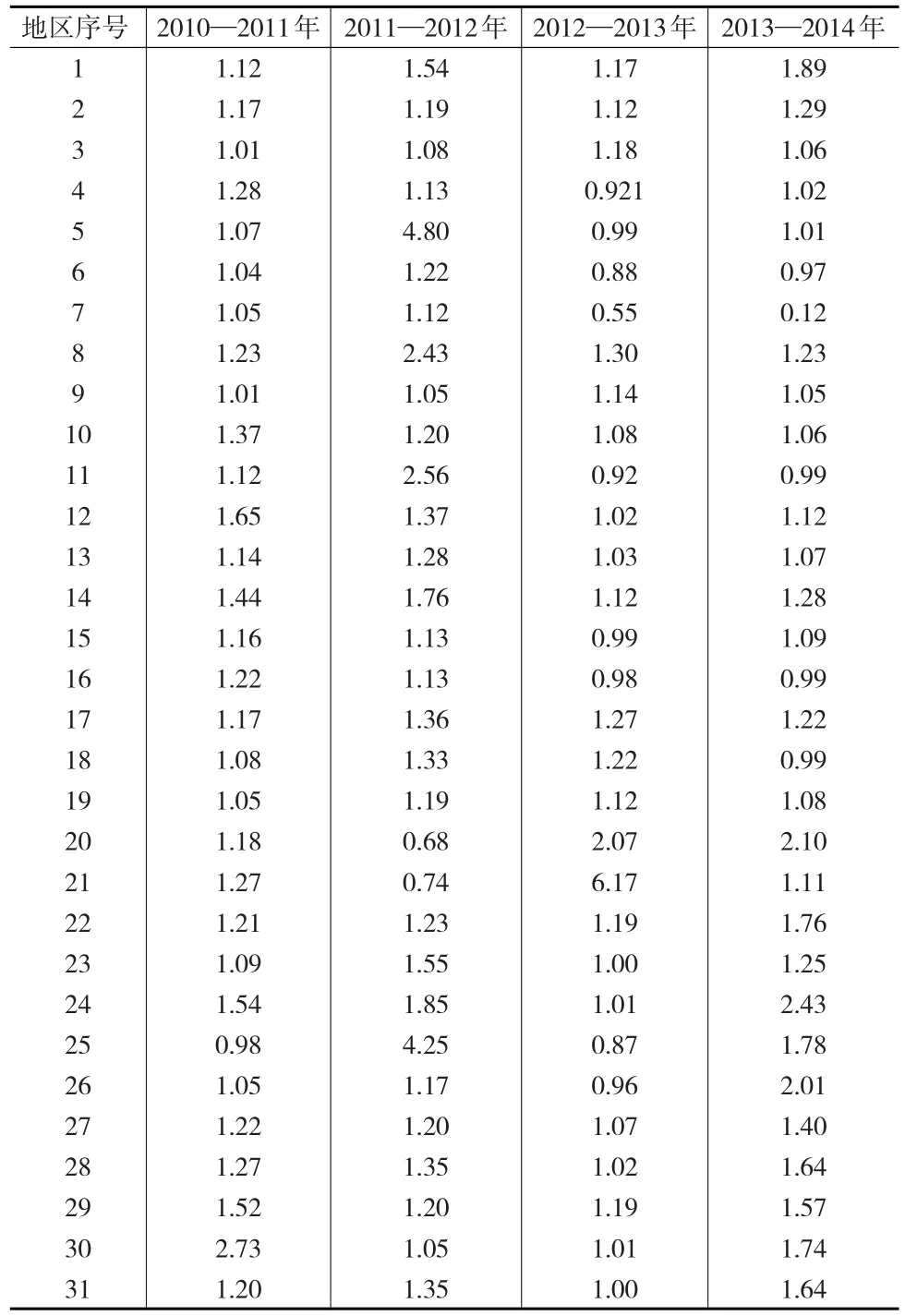
表6 2010—2014年地区经济差异进化指数
在考证不同分型区块的经济进化质量的规律方面,图1给出了2011—2014年人均地区生产总值(指标1)、资本形成总额及构成(指标2)和居民消费水平(指标3)在各年度进化质量的趋势。选取5种有代表性的区块,分别对应了“较低层次”(m=1和m=2)的两种类型;“中等层次”(m=5和m=6)以及“较高层次”(m=10)的情况。从图1可以看出,在指标1的变动趋势中,“高层次区块”总体保持了稳定的增长态势,说明具有较强的经济增长实力;中等层次和低层次的区块则在较低的进化质量水平上徘徊,说明进化质量不高;在指标2的变化趋势中,两类较低层次的分型区块呈现波动上升态势,说明这类欠发达地区仍然保持了一定的资本拉动经济的态势;与此相反,“高层次区块”却总体上保持了稳步下降的态势,说明经济较发达的地区的经济增长已开始从单纯的资本拉动向其他增长因素拉动的方向转变,率先开始转型;在指标3中,不同区块总体上均保持了增长态势,但是中低层次区块增长态势波动较大,而较高层次的区块却保持了较稳定的增长态势,与其他实证分析结果吻合[8,9]。
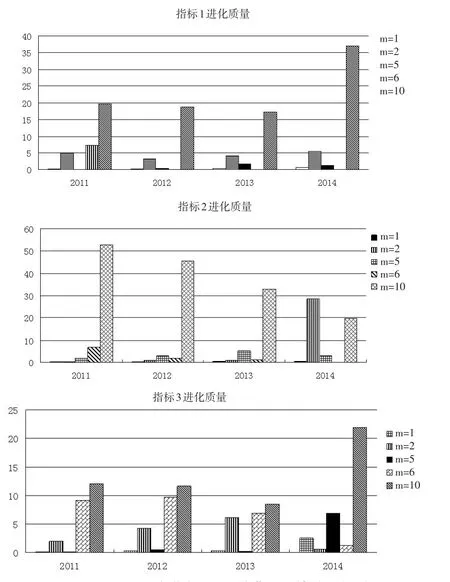
图1 2011—2014年指标1,2,3的典型区块的进化质量
表7给出上述区块的当量聚集度和经济丰度系数的对比情况。在指标1下,m=10对应的区块中当量聚集度一般均小于1,该区块所对应的经济丰度系数也相对较高,此区块对应的地区分别为北京、天津和上海,说明上述地区是经济发展较为均衡且聚集度较为合理的地区;与此接近的是m=7的区块,该区块的聚集度也大多位于1附近且其对应的经济丰度系数也较高,此类地区为辽宁、福建、山东和广东。在m=1和m=2两个区块中,其当量聚集度大都大于3,而其经济丰度系数普遍较低,这些区块所代表的地区主要是一些中西部地区,其经济发展的均衡性相对低一些。
在指标3下,经济丰度系数较高的区块是m=10的区块,该区块的当量聚集度均小于1,它包含的地区恰好为北京和上海两个直辖市,其经济也是我国最发达的地区之一;m=7和m=9两个区块的情况较为接近,其对应的经济丰度系数较为适中,其对应的地区为天津、江苏、广东和重庆,这些都是近几年我国经济发展较快的地区;在m=1和m=4两个区块中,经济丰度系数相对较低,该区块为河北、山西、吉林、安徽、江西、河南、湖南。上述实证结果与其他定量研究的结果也较为吻合[10]。
指标2情况比较复杂。在丰度系数较高的区块中,既有一些通过资本形成等因素拉动经济发展的发达地区(例如江苏、山东、广东),也有已经通过经济转型降低了资本形成因素拉动作用的地区(例如m=2类别中的北京),它们多已转变为依靠技术进步来拉动经济增长[11,12]。
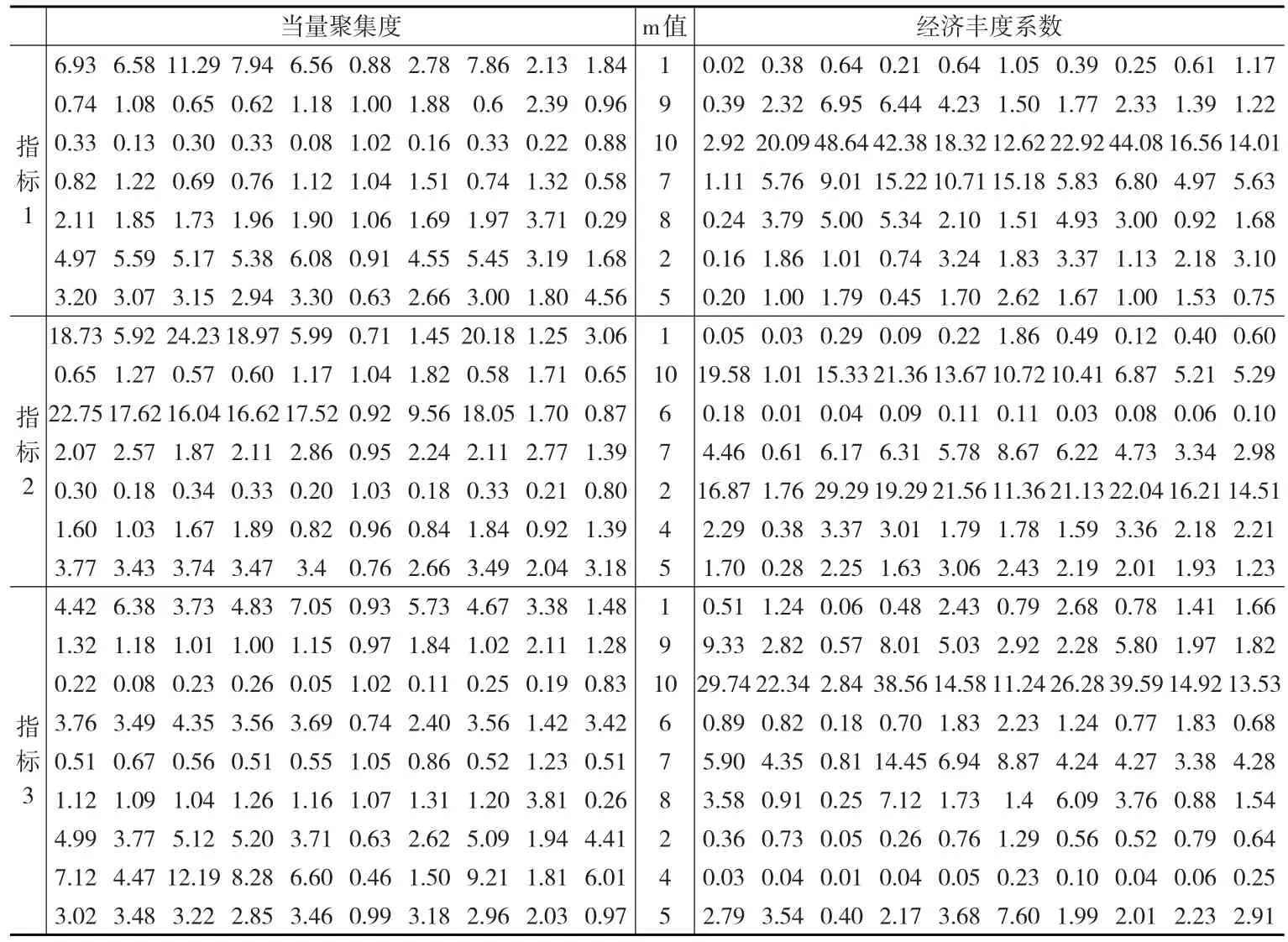
表7 2014年指标1,2,3各区块的当量聚集度与经济丰度系数对照
4 结论与启示
本文对2010—2014年的经济统计数据在经济内涵挖掘模型的基础上进行了定量分析。结果表明,我国地区间的经济结构和发展层次存在着多种分型特点,其经济进化能力、经济发展水平与层次、经济结构的均衡性等方面均存在明显的梯次差异。发达地区与欠发达地区之间、不同的发达地区之间也存在着经济增长拉动因素的差异,这些结果对于探索地区经济发展模式及不同经济类型的结构转型方面都能提供数量参考。因而启示我们,不同地区应该根据实际情况进行有序的结构转型升级并充分利用区域经济的差异度来开展定向的互补合作以促进更多地区的共同繁荣。此外,还应该重视经济进化过程中质量内涵的提高,对于率先转型的地区应加强技术创新的引领作用,对于仍然依靠劳动力增长和资本拉动的地区应将发达省区的剩余产能及时转移过去。同时,还应该探索不同地区多元化多层次的转型发展规律,引导我国不同地区按层次的规模升级和增长因素的转换,避免一刀切的转型模式,为我国经济的可持续发展创造条件。
猜你喜欢
医学美学美容(2021年18期)2021-10-21
石油化工应用(2021年12期)2021-01-15
中国人民公安大学学报(自然科学版)(2020年2期)2020-07-04
制造技术与机床(2019年11期)2019-12-04
初中生世界·九年级(2019年6期)2019-08-15
中国中医急症(2019年10期)2019-05-21
北京航空航天大学学报(2017年5期)2017-11-23
中华骨与关节外科杂志(2017年1期)2017-05-17
智能制造(2015年4期)2015-05-12
火炸药学报(2014年3期)2014-03-20
