
粮食作物巨灾保险的纯费率厘定
2018-12-03 11:39梁来存皮友静
统计与决策 2018年21期
梁来存,皮友静
(广西财经学院a.信息与统计学院;b.图书馆,南宁 530003)
0 引言
为积极开展粮食作物的巨灾保险业务,使政府的保费补贴额度与各地区的风险水平、费率水平相适应,有必要厘定出各地区粮食作物的巨灾保险费率,为我国政策性粮食作物巨灾保险的健康发展提供技术支持。以往研究探讨的是农作物保险费率的厘定方法,并未涉及农作物巨灾保险的费率厘定问题。粮食作物巨灾事件属于极值事件,可以基于极值理论进行研究。根据PBDH定理,灾损数据极端值的分布可以选择广义帕累托分布(GPD)。即,粮食作物巨灾保险的费率厘定可参照参数法思路,以GPD作为灾损数据的尾部分布,基于极值理论界定巨灾,估计并检验GPD参数,进而厘定粮食作物巨灾保险的纯费率。
1 研究方法
1.1 灾损数据的推算
设农民以粮食作物的单产投保。i地区第t年的实际单产为yit,根据趋势方程可求得趋势单产为it。可以这样获取灾损数据:将实际单产yit与趋势单产it比较,如果yit≥it,则认为i地区第t年的粮食作物生产没有遭受自然灾害,该地区该年的灾损数据为0;反之,如果yit<it,则认为i地区第t年的粮食作物遭受了自然灾害,该地区该年的灾损数据为it-yit。所以,i地区第t年的灾损数据xit为:

1.2 巨灾界定值的初步估计
1.2.1 巨灾界定的理论依据
Balkema&Dehann(1974),Pickands(1975)证明了超额灾损数据的分布函数在MDA条件下收敛于GPD。 即 当μ→x0时-μ}→0。这就是PBDH定理。该定理的统计意义在于,可以用GPD来拟合高出门限值的那一部分数据。
可见,只有估计了门限值μ,才能依据前述的灾损数据和门限值μ,确定巨灾年份,并得到超额灾损数据z。依据PBDH定理,超额灾损数据z趋于GPD,据此计算z的期望值E(z),则E(z)+μ为巨灾数据的期望值。所以,要计算巨灾年份巨灾数据的期望值,要厘定巨灾保险的费率,估计门限值μ是必要的。
1.2.2 巨灾界定值的初步估计法
如果某地某年粮食作物的单产灾损超过了门限值μ,则认为粮食作物遭受了巨灾;如果单产灾损在μ或μ以下时,则认为没有遭受巨灾。初步估计门限值μ的方法,一是样本平均超出函数法,根据en(μ)关于μ的分布图来选择确定一个适当的门限值:如果en(μ)在超过某一门限值μ后呈现明显的正斜率的线性变化,说明数据服从GPD;如果en(μ)在超过某一门限值μ后呈现明显的负斜率的线性变化,说明数据呈薄尾分布;如果呈一条水平线,则是指数分布。二是正态近似法。McNeil和Frey提出,当假定灾损数据随机变量x的分布函数左边和中间都是正态分布、右尾是GPD时,根据F(x)的右连续性可知,可以取满足的最大的x作为门限值。这里Φ(x)是具有和历史数据相同均值和方差的正态分布的分布函数,n是样本容量,Nu为大于门限值μ的数据的个数。三是峰度法。该方法是由Pieere Patie(2000)提出来的,其依据是,正态分布的峰度系数等于3,厚尾分布的峰度系数大于3。因此,可以这样来估计门限值:每次将灾损数据中使得| |xi-xˉ值最大的xi从数据中删除,一直到删除后的剩余数据的峰度系数近似地等于3。此时,这些剩余数据组成的样本呈正态分布,该样本中的最大值即可作为巨灾的门限值。
1.3 巨灾界定值的确定
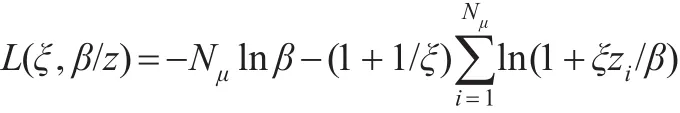
当ξ≠0时 ,对L(ξ,β/z)求极值,令偏导数等于0,可以解得使函数值L(ξ,β/z)最大的参数(ξ、β)的最佳估计量ξ是分布的形状参数,β是分布的尺度参数。
建立的GPD模型还需要进行检验。根据V.Choulakian和M.S.Stephens(2001)的研究,检验GPD模型可使用假设检验法。原假设H0:样本来自于GPD。并计算统计量:
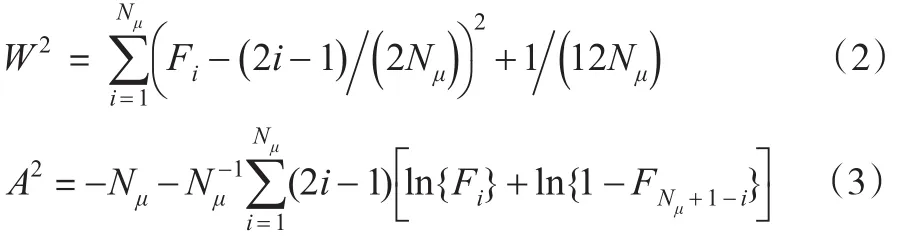
在上一步中,已经得到了巨灾界定值的初步估计值。对该值及其附近可能的门限值,逐一进行上述检验,直到检验通过为止,这时的巨灾界定估计值即为最终确定的巨灾界定值。
1.4 计算纯费率
当农民以单产投保时,设保障程度为λ,投保年份的趋势单产为it。由于粮食作物保险的纯费率为粮食作物的平均损失率,那么,粮食作物巨灾保险的纯费率等于所有年份巨灾损失的期望值与保障水平之比。而所有年份巨灾损失的期望值可以通过巨灾年份巨灾损失的期望值与巨灾发生的概率之积来计算。因此,粮食作物巨灾保险的纯费率为:
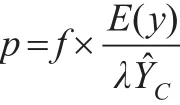
其中,y-μ=x,x为单产巨灾损失超出额。根据PBDH定理,x服从GPD分布,因此有:
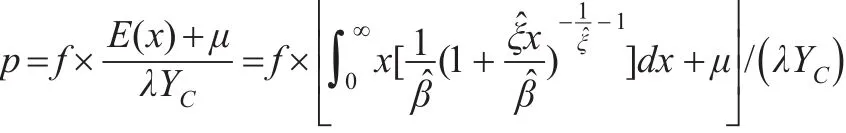
式中,f为巨灾发生的频率,、分别为GPD分布的形状参数、尺寸参数的估计值。
2 实证
假定农民以单产投保,单产的变化幅度反映了所有自然风险对稻谷作物的影响程度,这里以我国稻谷为例,厘定我国稻谷作物巨灾保险的纯费率。
2.1 数据搜集与灾损数据推算
2.1.1 数据搜集
根据相关年份的《中国农村统计年鉴》,可以搜集到我国各省(市、区)稻谷作物1979—2015年分省、分年的实际单产数据yit(公斤/公顷)。由于青海省的相关数据不全,且不含港澳台地区,所以,这里只包含30个省(市、区)。
以省(市、区)为单位,为了得到各省(市、区)各年的单产趋势值,采用趋势方程拟合法。取1979—2015年各年的t为1~37(其中,广东、海南只有1988—2015年的单产数据,故t取1~28;四川、重庆只有1997—2015年的单产数据,故t取1~19),根据各省(市、区)的实际单产数据,对各省(市、区)所拟合的单产趋势方程见表1。
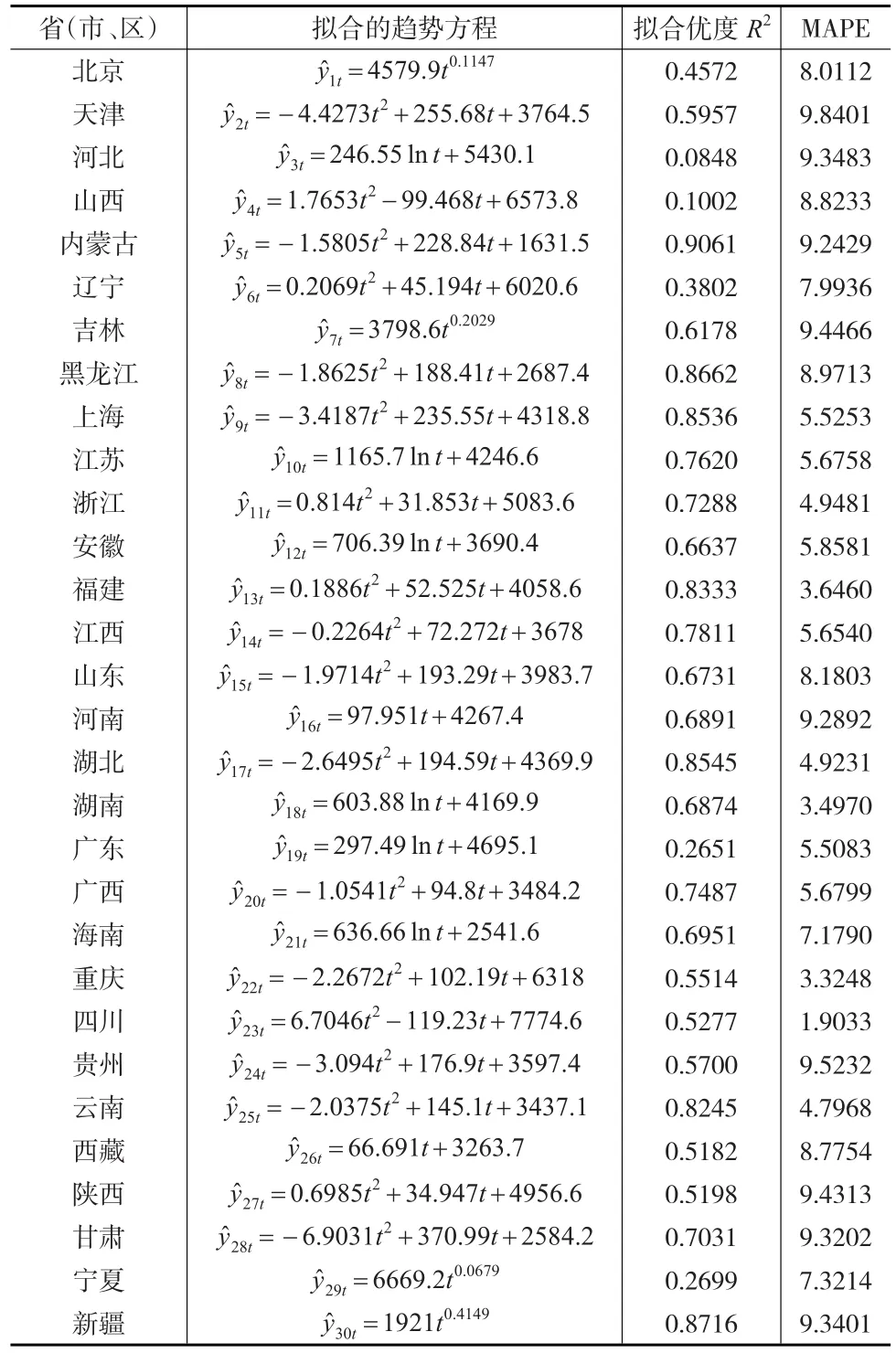
表1 各省(市、区)的单产趋势方程表
从表1看,拟合精度指标MAPE值都小于10,符合精度要求,可以接受上述所建立的趋势方程。
2.1.3 灾损数据的推算。
将各年的对应t值代入表1的趋势方程中,即可得到各省(市、区)各年的趋势单产值。把各省(市、区)每年的实际单产与相应的趋势单产代入式(1),便得到灾损数据。对于这些灾损数据,如果分省份分析,样本容量为37,广东、海南的样本容量只有28,四川、重庆还只有19,样本太小,无法对灾损数据的分布形式进行较准确的判断。
假定农民以单产投保,在巨灾的影响下,单产的变化在各省(市、区)之间仍然具有可比性。以高单产地区为例,与低单产地区相比,一方面,由于单产相对较高,在同样灾害的影响下,单产的下降幅度会比较大;但另一方面,高单产地区的基础设施往往相对完善,抵御自然灾害的能力相对较强,单产的下降幅度会比较小。综合这两个方面,可以认为各地区间的单产变化具有可比性。因此,把各省(市、区)的灾损数据作为一个整体进行分析,这是合理的。
2.2 巨灾界定值的估计与确定
对于灾损数据,是否存在巨灾的界定值,还需要进行诊断,也就是厚尾性诊断。现对上述灾损数据进行初步分析,分析结果表2所示。

表2 我国稻谷灾损数据的统计分析指标
表2表明,灾损数据总共有443个,最小值为0.58公斤/公顷,即平均亩产减少了0.58公斤/公顷,显然这不是巨灾。最大值为4010.02公斤/公顷,即平均亩产减少了4010.02公斤/公顷,无疑这属于遭受巨灾导致的减产。
峰度系数为9.95,远远大于正态分布的峰度系数3,不能用常用的正态分布作为灾损数据的分布形式。偏度系数为2.25>0,呈右偏分布。这就是说,我国稻谷的灾损数据序列有极端值存在,即序列存在巨灾数据。
对于上述的灾损数据,样本平均超出函数法、正态近似法都很难精确估计门限值。采用峰度法,利用MATLAB R2017a软件,可以得到门限值为793.91公斤/公顷,大于该门限值的灾损数据有91个。除去这91个巨灾数据,余留下来的灾损数据的峰度系数为2.99,相当于正态分布的峰度系数3。据此,可以估计,我国稻谷巨灾的界定值,即门限值,在793.91公斤/公顷附近,巨灾数据大概91个左右。
再利用V.Choulakian和M.S.Stephens(2001)提出的假设检验法来确定最终的门限值。对于初选的门限值793.91公斤/公顷及其附近的可能的门限值,采用极大似然法ML得到GPD的参数估计值和。利用式(2)计算W2,利用式(3)计算出A2。结果见表3所示。
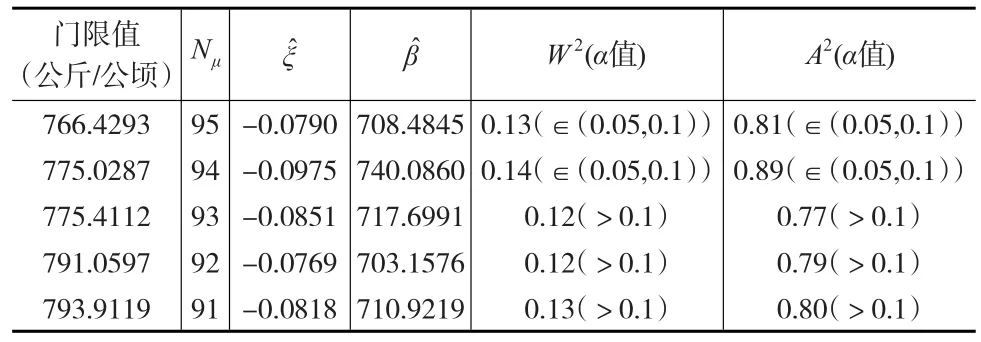
表3 门限值及其参数估计与检验表
在表3中,α值就是假设检验中的P值,当α值很小时,就有理由拒绝原假设H0。当门限值μ=766.42公斤/公顷,或者μ=775.02公斤/公顷时,在10%的显著性水平上拒绝原假设H0,即相应的超额灾损数据不服从GPD。当μ≥775.41公斤/公顷时,在10%的显著性水平上接受原假设H0,即相应的超额灾损数据服从GPD。为了尽可能扩大服从GPD的样本的容量,则确定门限值μ=775.4112公斤/公顷,这就是稻谷单产巨灾的界定值。超过该单产巨灾界定值的灾损数据,均为巨灾数据。
从表3可以看出,门限值μ=775.4112公斤/公顷时,以最大似然法估计巨灾损失的超出损失z的GPD的分布参数=-0.0851,=717.6991。据此可进一步厘定巨灾保险的费率。
2.3 巨灾保险的纯费率厘定
根据上述估计得到的超出损失的GPD分布参数,计算单产巨灾损失超出额的数学期望E(x)=661.4129。由于E(y)=E(x)+μ,则单产巨灾损失的数学期望E(y)=661.4129+775.4112=1436.8241。
各地风险水平不一,要计算各省(市、区)的单产巨灾损失的数学期望,还需要对E(y)进行调整,调整的依据为各省(市、区)的风险水平(表4)及政策取向。

表4 各省(市、区)粮食作物自然灾害影响的分区结果
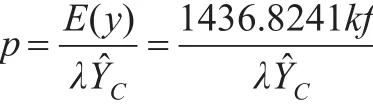
以风险系数k进行调整,各省(市、区)风险系数值与该地区的风险等级、政府的政策取向等因素有关,这里假设低风险区的风险系数为1.0,较高风险区为1.2,高风险区为1.4,如下页表5第(1)列。巨灾发生的频率用f表示。各省(市、区)粮食巨灾保险的纯费率为:
3 讨论
3.1 我国稻谷发生巨灾的概率较高,巨灾保险纯费率较低
上述的实证研究选取了1979—2015年中国内地青海省以外的30个省(市、区)37年的数据。其中,广东、海南只有1988—2015年28年的数据,四川、重庆只有1997—2015年19年的数据。这样,样本容量为1056。根据计算的巨灾界定值,巨灾数据共有93个。这样,各省(市、区)平均发生巨灾的概率达到8.81%。在巨灾保险的纯费率方面,计算各省(市、区)纯费率的简单算术平均数可知,如果保障程度为90%,纯费率的平均值为2.33%;如果保障程度为100%,纯费率的平均值为2.09%。
3.2 粮食主产区的巨灾保险纯费率偏高
我国有13个粮食主产区,保障程度90%时计算它们巨灾保险纯费率的平均值为2.17%。相应地,保障程度90%时全国的平均水平为2.33%。两者相比,粮食主产区的纯费率略低且相当接近全国平均水平。这说明,国家支持粮食主产区发展的相关政策,已经产生了积极的效果,基础设施建设得到了加强,增强了抵御自然灾害的能力。但是,主产区的粮食产量占全国粮食总产量的比重达到了70%左右,与主产区粮食生产的重要地位相比,其抵御自然灾害能力仍然有待加强。
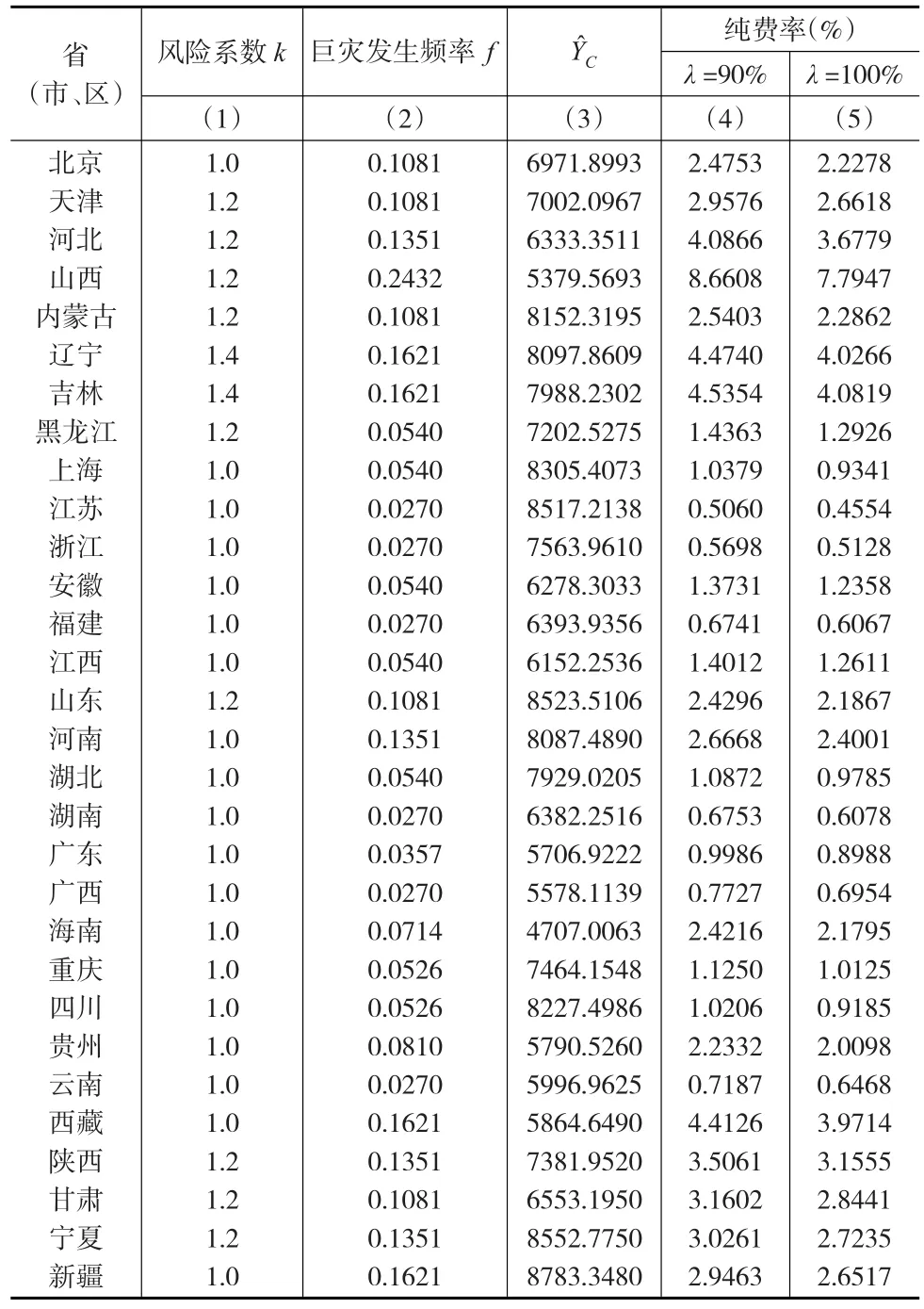
表5 各省(市、区)粮食巨灾保险的纯费率
3.3 稻谷巨灾保险的纯费率在全国呈北方高、南方低的区域分布特征
现以长江流域作为分界线,当保障程度为90%时,北方各省(市、区)巨灾保险纯费率的平均值为3.27%,而南方平均值为1.09%。如果将全国各省(市、区)的纯费率按从大到小作降序排列,排前十位分别是:山西(8.66%)、吉林(4.53%)、辽宁(4.47%)、西藏(4.41%)、河北(4.08%)、陕西(3.50%)、甘肃(3.16%)、宁夏(3.02%)、天津(2.95%)、新疆(2.94%)。可见,这些纯费率较高的前十位省(市、区),无一例外全部位于长江流域以北的地区。究其原因,一方面,反映北方地区粮食生产基础设施建设的相对落后;另一方面,北方地区水资源的严重不足,已经成为制约其粮食生产的重要因素。
3.4 中、西部地区的纯费率明显高于东部地区
当保障程度为90%时,计算中、西部地区巨灾保险纯费率的简单算术平均数为2.48%,而东部地区只有1.81%。根据上述全国各省(市、区)的纯费率按从大到小作降序排列的情况看,排前十位的除辽宁、河北、天津外,其他七个都属于中、西部地区。这主要因为东部地区经济较发达,农业基础设施建设相对健全、完善,抵御自然灾害的能力相对较强,单产相对稳定,所以巨灾保险的纯费率较低。如果是同等程度的自然灾害,对东部地区的粮食作物不会形成巨灾,但对于中、西部地区来说,由于基础设施建设不完善,则可能形成粮食作物的巨灾。另外,东部地区水资源的相对充足也是原因之一。
4 结论
费率厘定主要有参数法和非参数法。本文按照参数法思路,即基于极值理论以GPD作为粮食灾损数据的尾部分布,以门限值作为粮食作物巨灾的界定值,采用费率即平均损失率的方法,探讨了粮食作物巨灾保险的费率厘定方法。并以稻谷为例进行了实证研究。结果表明,我国稻谷发生巨灾的概率较大,达到8.81%,保障程度为90%时,巨灾保险纯费率的平均值为2.33%;保障程度为100%,平均值为2.09%;粮食主产区的平均纯费率稍微低于全国平均水平,相对其粮食生产的重要地位来说显得偏高;在区域分布方面,北方的平均水平明显高于南方,中西部地区明显高于东部地区。
猜你喜欢
中国临床医学影像杂志(2022年5期)2022-07-26
昆明医科大学学报(2021年4期)2021-07-23
中国交通信息化(2020年10期)2021-01-14
东坡赤壁诗词(2019年3期)2019-07-05
劳动保护(2019年3期)2019-05-16
金融经济(2018年14期)2018-08-16
雷达学报(2018年3期)2018-07-18
时代金融(2016年24期)2016-09-10
中国交通信息化(2015年9期)2015-06-06
