
核磁共振氢谱结合化学计量学快速检测掺假茶油
2018-11-28 06:52闫小丽朱梦婷谢明勇
食品科学 2018年22期
石 婷,陈 倩,闫小丽,朱梦婷,陈 奕*,谢明勇
(南昌大学 食品科学与技术国家重点实验室,江西 南昌 330047)
茶油是油茶种子中经过压榨、浸出等方法提取得到的木本植物油,又名油茶籽油、茶树油、茶籽油,主要分布在湖南、江西、广西、浙江等中国南部省市,是我国特产的一种绿色、生态和高营养的保健食用油,为食用油中的珍品,被称为世界四大木本油料植物之一[1]。由于茶油的脂肪酸组成和橄榄油的脂肪酸组成非常相似,因此被誉为“东方橄榄油”[2]。研究表明茶油除含有较高含量的油酸,少量亚油酸、亚麻酸外,还含有多种生理活性物质如角鲨烯、甾醇、生育酚、茶多酚等[3],对多种疾病有较好的预防作用[4]。其中富含的α-生育酚可促进细胞新陈代谢,具有增加肌肉细胞的营养、防止动脉硬化、预防心脏和肺梗塞、改善血液循环、防止关节炎等功能,而茶多酚在降低胆固醇含量和抗癌疗效方面效果较佳[5-6]。我国茶油资源丰富,但由于茶油的生产周期长、产出率低等原因导致茶油产量比其他植物油较低,且因脂肪酸组成、产量及营养价值等因素的影响,茶油的市场价格大约是普通食用油的3~6 倍[7],一些不良商贩为了牟取暴利,在茶油中掺入廉价的植物油,如大豆油、玉米油,冒充茶油出售,导致目前市场上茶油质量参差不齐。因此,建立掺假茶油检测技术对于茶油质量监督以及品质控制十分重要。
目前,常用于茶油掺假的检测主要有传统检测方法(如感官评价、物理化学指标的评价等)[8]和仪器检测方法(如色谱[9]、质谱[10]、差示扫描量热法[11]等),但传统检测方法时间长、化学试剂耗费大,而以上这些仪器检测方法大多需要进行繁琐的样品前处理,对样品破坏性较大。与上述方法相比,核磁共振具有快速、高效、无污染、无需繁琐的前处理、重复性高等优点,在植物油掺假领域,如橄榄油[12]、花生油[13]、核桃油[14]、菜籽油[15]中得到广泛的应用。
通过核磁共振波谱可以获得样品中多种化学成分的信息,但是各种成分信号的重叠也使得图谱变得十分复杂,尤其当谱峰严重重叠,信号所包含的化学成分未知时,数据分析的难度大大增加。面对信息量大、复杂的核磁数据,如何提高其处理效率变得至关重要。
所研究样品的信息,有些可以通过数据直观地反映出来,但很多重要的信息却并不能直接从数据中得到,往往需要结合正确的数学模型和有效的计算方法对数据进行分析[16]。化学计量学是将化学体系的测量值与体系的状态建立联系的学科,本质是化学测量的基础理论与方法学。结合化学计量学方法可以全面地分析谱图数据,从复杂的核磁数据中最大限度地提取有关研究对象成分、结构等重要信息,获得有效的特征数据,建立数学模型,有助于对测量数据的解释、判别和预测,具有计算速度快和识别功能佳等优点[14]。常用的化学计量学方法一般包括两类:无监督模式识别和有监督模式识别。主成分分析(principal component analysis,PCA)法是常用的无监督模式识别方法之一,在保持数据信息损失最少的原则下,对高维变量空间进行降维处理,直观反映样品间的差异[17]。常用的有监督模式识别包括偏最小二乘判别分析(partial least squares-discriminant analysis,PLSDA)法、PLS等[18-19]。PLS-DA作为一种可靠、稳健的多元统计分析方法,多适用于复杂样品的质量控制以及类别预测。PLS是一种描述矩阵X和响应矩阵Y相关性的多元校正分析方法,多用于定量分析。
但是,很少有研究报道应用核磁共振结合化学计量学方法PCA、PLS-DA以及PLS对茶油掺假进行检测。本实验利用核磁共振氢谱(1H nuclear magnetic resonance,1H NMR),以纯茶油及掺入大豆油、玉米油的掺假茶油为研究对象,结合PLS-DA建立掺假油种类的预测模型,通过PLS模型进一步预测掺假比例,对茶油品质进行评价,为核磁共振结合化学计量学方法在茶油品质评价和控制中的应用提供实验依据。
1 材料与方法
1.1 材料与试剂
茶油样品30 个(江西省不同地区)、大豆油样品3 个(江西省南昌市)、玉米油样品3 个(江西省南昌市、江西省九江市、浙江省杭州市),以上均由江西省南昌市质检局提供; 氘代氯仿(CDCl3,99.8%+0.03%四甲基硅烷(tetramethylsilane,TMS)) 上海阿拉丁公司。
1.2 仪器与设备
AV 600 MHz核磁共振波谱仪 瑞士布鲁克公司;5 mm核磁共振样品管 美国Wilmad公司;QL-861型涡旋仪 海门市其林贝尔仪器制造有限公司;DragonLab移液器 北京大龙实验室仪器有限公司。
1.3 样品的1H NMR测定
从上述30 种茶油样品中随机挑选3 种茶油,向所选茶油(n=3)中分别掺入不同体积分数(5%、10%、20%、30%、40%、50%、60%、70%、80%、100%)的大豆油(n=3)或玉米油(n=3),当茶油中掺入大豆油或玉米油的比例达到100%,则为纯的大豆油或玉米油。上述混合油样涡旋30 s,取200 μL油样与800 μL CDCl3混合,涡旋30 s,室温静至5 min,取600 μL转移至5 mm核磁管中进行核磁实验,总计90 个样品,其中茶油样品30 个,掺有不同比例的大豆油样品30 个,掺有不同比例的玉米油样品30 个。
质子共振频率为600 MHz,时域为32 K,90°脉冲的宽度为11 μs,恢复时间为2 s,信号检测时间为2.73 s,信号累加次数为32,空扫次数为4。以TMS(δ 0.00)为内标。
1.4 数据处理
将测得的1H NMR信号导入MestRenova软件进行傅立叶转换,自动调整相位和基线,以内标峰TMS(δ 0.00)为基准校正化学位移,化学位移在δ 7.0~7.5归属于溶剂峰(CDCl3)信号。1H NMR图谱手动积分,将酰基链上α-亚甲基氢(—OCO—CH2—,信号9,δ 2.40~2.20)的积分面积标准化为1 000,其他信号峰面积以此为参考标准[20],最终得到16 个积分片段。
将15 个积分片段(除了作为参考标准的信号9,δ 2.40~2.20)作为变量导入Simca-P+12.0软件(Umetrics,Sweden),结合PCA、PLS-DA以及PLS建立掺杂油种类及其掺杂量的预测模型。PCA通过几个独立的变量线性表示原始变量,综合指标通常用方差来表达,方差越大,包含的信息越多[21]。PLS多用于定量分析,当用于定性分析时,则以PLS-DA形式出现[22-23]。PLS-DA是一种用于判别分析的多变量统计分析方法,根据观察或测量到的若干变量值判断研究对象如何分类。PLS-DA是PCA的回归拓展,其原理是对不同处理样本(如观测样本、对照样本)的特性分别进行训练,产生训练集,并检验训练集的可信度,通过分类信息将不同组别样本的分离最大化,而将同类中的方差及协方差最小化[24-25]。
2 结果与分析
2.1 1H NMR指纹图谱

图1 茶油、玉米油和大豆油的1H NMR谱Fig. 1 1H NMR spectra of camellia oil, corn oil and soybean oil
图1为纯茶油、玉米油以及大豆油的1H NMR 指纹图谱,表1是相应化学位移对应的官能团[26-29]。可以看出3 种植物油主要成分为甘油三酯,含有少量的甘油二酯,角鲨烯和甾醇。由于脂肪酸的化学相似性,大部分信号存在重叠,没有完全区分开来。其中信号最强的是δ 1.40~1.14(信号12)和δ 0.92~0.80(信号14),其次为信号1(δ 5.42~5.29)和信号10(δ 2.08~1.94)。信号12包括所有的不饱和脂肪酸以及软脂酸和硬脂酸上的亚甲基氢,信号14是来自于除了亚麻酸以外的其他脂肪酸末端的甲基氢。对比3 种植物油的特征指纹图谱,可以看出玉米油中有最高强度的β-甾醇和甘油二酯共振峰,大豆油中亚麻酸共振峰强度最高,而茶油中亚油酸以及甾醇共振峰强度均明显低于玉米油和大豆油。通过1H NMR图谱可以看出纯茶油与纯大豆油及玉米油之间存在差异谱峰,为进一步通过化学计量学方法,从中找出纯茶油和掺假茶油之间的生物标志物提供依据。

表1 茶油1H NMR信号Table 1 Assignment of the 1H NMR spectral signals of camellia oil
2.2 掺假油样的PCA
在进行PCA之前,可以通过Hotelling’s T2Range算法判断异常样本。当T2超过临界值时(0.05作为置信区间),说明该样本与其他样本间存在较大差异,应作为异常点剔除。如图2所示,在95% Hotelling’s T2的置信区间之内,茶油样品中无异常值,而大豆油掺假样品中剔除2 个异常值,玉米油掺假样品中剔除2 个异常值,剩余86 个样品用于下一步的模型建立。

图2 茶油(a)、大豆油(b)和玉米油(c)掺假样品的Hotelling’s T2 Range图Fig. 2 Hotelling’s T2 Range plots of pure camellia oil (a) and adulterated camellia oil with soybean oil (b) or corn oil (c)
根据模型得分图(图3)可知,不同组的样本分类情况,从得分图3a上可以看出,PC1解释了45.77%的总方差,纯茶油和大部分掺假茶油在主成分1上有较好的区分。所有纯茶油均分布在PC1左侧,大部分掺假油分布在PC1右侧,由于化学组成上的相似性,少部分低浓度的掺假油与纯茶油重叠,随着掺假油比例的增加,样品的分布在PC1轴上呈从左到右分布。进一步采用载荷图来筛选区分真假茶油潜在的生物标记物,对不同组的样本分类贡献较大的代谢物质通常是在载荷图中远离中心原点的物质,即离中心的距离越远,对分类的影响越大[30]。从图3b可以看出,信号4(δ 4.20~4.05),10(δ 2.08~1.94),12(δ 1.40~1.14)以及14(δ 0.92~0.80)在PC1上有较大的负载荷值,而所有的不饱和脂肪酸(信号1,δ 5.42~5.29)、亚油酸(信号8,δ 2.84~2.79)以及亚麻酸(信号7和信号13)在PC1上有较大的正载荷值,甘油三酯(信号2、信号3)在PC2上有较大的负载荷值,甘油二酯(信号6)在PC2上有较大的正载荷值。

图3 剔除奇异点后的茶油(CAO)、大豆油掺假样品(CAOSO)、玉米油掺假样品(CAOCO)的PCA得分图(a)和载荷图(b)Fig. 3 PCA score plot (a) and loading plot (b) of PC1 versus PC2 for pure camellia oil and adulterated camellia oil with soybean oil and corn oil
结合图3分析可以看出,不饱和脂肪酸(信号1)、亚油酸(信号8)以及亚麻酸(信号7和信号13)是掺假茶油的主要特征信号峰,而油酸(信号10)、甘油三酯(信号4)以及三萜醇(信号16)是纯茶油的特征信号峰。进一步对掺假茶油1H NMR谱中以上特征信号峰进行积分,并获得其信号强度与掺假量之间的关系,结果如图4所示。随着大豆油掺入量的增加,信号1和信号8、信号7和信号13的共振峰逐渐增强。掺有玉米油的样品信号峰强度呈现出类似的趋势。由此证实了PCA在筛选掺假茶油特征变量上的有效性。

表2 PLS-DA模型判别准确率Table 2 Discrimination accuracy of the PLS-DA model

图4 不同掺假比例的茶油样品1H NMR信号积分面积Fig. 4 Integral area of 1H NMR signals for camellia oil samples with different adulteration ratios
2.3 掺假油样的PLS-DA
无监督模式识别的PCA无法判断未知样品,且存在与研究目的无关的组内误差以及随机误差,不利于分组信息的准确性。为了确定分组样品的差异,进一步采用有监督模式识别的PLS-DA。按照建模的一般要求,在所采集的86 个样本(30 种茶油+28 种掺入大豆油的茶油+28 种掺入玉米油的茶油)中,从每一类油样随机取2/3的样品划分为训练集,用于建立模型,剩余1/3的样品作为预测集,用于检验模型。
为了准确识别掺假茶油,首先将56 种掺假茶油归为一类,纯茶油作为另一类,建立PLS-DA1模型,图5判别结果表明,相比PCA,纯茶油和掺假茶油在PLS-DA1中得到了更好地分离。随着掺假比例的增加,茶油样本区域和掺假茶油样本区域间的距离逐渐增加。当掺假比例≤10%时,掺假茶油和纯茶油有部分交叉,而当掺假比例≥20%时,掺假茶油和纯茶油得到较好地区分,尤其当掺假比例达到40%以上时,两类样品能完全分开。为避免模型分类的偶然性,采用200 次置换检验验证上述模型(图5e)的可信度,结果见图6a。如图6a所示,PLS-DA1模型的R2和Q2分别为0.078和-0.37,且所有位于左边的Q2值(Y轴数据)均低于最右边的Q2值,说明模型没有过拟合,具有较好的稳定性和预测性。进一步采用预测集检测模型的判别准确率,验证模型的有效性。在判别分析中,将茶油数值设定为1,掺假茶油数值设定为0,阈值设为0.5,并规定预测值中≥0.5判定为1,<0.5判定为0。预测结果如表2所示,当掺假比例由5%增加至40%时,模型预测集的总判别准确率由88.00%提高至100%。当掺假量≥40%时,训练集和预测集判别准确率达到100%,模型检测效果较好。


图5 茶油及掺假茶油PLS-DA1得分图Fig. 5 Score plot of PLS-DA1 for pure camellia oil and adulterated camellia oil with an adulteration ratio higher than 5%, 10%, 20%,30%, and 40%

图6 排列实验对PLS-DA模型的可靠性验证Fig. 6 Validation of PLS-DA model by permutation test
为了进一步判别茶油中掺假油的种类,对纯茶油、掺入大豆油的茶油、掺入玉米油的茶油建立PLSDA2模型,结果见图7。随着掺假比例的增加,纯茶油的样本区域和掺入大豆油以及掺入玉米油的茶油样本区域间的距离逐渐增加。从表2判别结果可以看出,除了部分掺假茶油被误判为纯茶油外,其他所有样本都能被准确识别,训练集总判别准确率高于89.66%。与PLS-DA1模型类似,采用200次置换检验对图7e中对应的PLS-DA2模型进行验证,结果如图6b所示。该模型的R2和Q2分别为0.022 5和-0.34,模型稳健,可靠性强。进一步采用预测集验证模型的有效性。在判别分析中,设定茶油为(1, 0, 0),掺入大豆油的茶油为(0, 1, 0),掺入玉米油的茶油为(0, 0, 1),并规定预测值≥0.5,判定为1;预测值<0.5,判定为0。预测结果如表2所示,当掺假量≥30%时,掺入玉米油的茶油样品判别准确率达到100%,此时纯茶油的样本区域和掺入玉米油的茶油样本区域分布较远,区分很明显,表明掺少量玉米油的茶油与纯茶油样品间即存在明显的品质差异。当掺假量≥40%时,掺入大豆油的茶油样品判别准确率达到100%。而当掺假量≥30%时,大豆油掺假样品训练集和预测集的判别准确率分别为85.71%和83.33%,仍有部分低浓度的大豆油掺假样品被误判为纯茶油。原因可能是一些微量化学成分在茶油和大豆油中差异较大,如大豆油中甾醇含量达到2226.13 mg/kg,而茶油中甾醇含量低于535.99 mg/kg[31]。当大豆油掺假比例较低时,掺假样品中甾醇含量较低,与茶油中甾醇含量类似,因此导致大豆油掺假样品被误判为纯茶油;而随着掺假比例的增加,掺假样品中甾醇含量升高,与茶油甾醇含量差异较大,二者能较好地区分。由表2可知,大豆油掺假样品的判别准确率低于玉米油掺假样品,表明在同样掺假比例下,掺有大豆油的茶油样品更不易检出,因此大豆油更容易成为茶油的掺假对象。结合PLS-DA2得分图(图7e)和载荷图(图7f)可以看出,不饱和脂肪酸(信号1)、亚油酸(信号8)以及亚麻酸(信号7和信号13)是掺假茶油的主要特征信号峰,随着掺假比例的增加,上述信号峰积分值在茶油和掺假茶油之间的差异越明显。由此可见,1H NMR结合PLS-DA 方法不仅可有效辨识纯茶油和不同掺假形式的掺假茶油,而且还可以表征掺假物质(大豆油、玉米油)添加量对茶油品质特性变化的影响。


图7 茶油(CAO)、大豆油掺假样品(CAOSO)、玉米油掺假样品(CAOCO)PLS-DA2得分图(a~e)以及载荷图(f)Fig. 7 Score plots (a-e) and loadings plot (f) of PLS-DA2 for pure camellia oil and adulterated camellia oil with higher than 5%, 10%, 20%,30% and 40% soybean oil or corn oil
2.4 掺假油样的定量分析
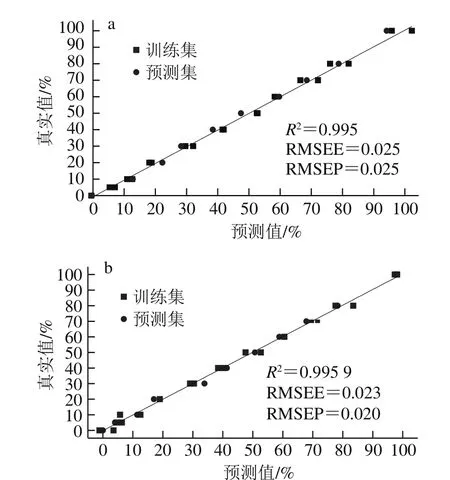
图8 掺假茶油含量真实值和预测值相关关系散点图Fig. 8 Plot of predicted against actual concentration of soybean oil and corn oil in aduterated camellia oil
由于PLS-DA模型只能判断掺假油的种类,因此将检测所得1H NMR数据及实际掺假值结合PLS法,建立掺假量预测模型。将2/3的样品划分为训练集,1/3的样品作为预测集。通常采用训练集均方根误差(root mean square error of estimation,RMSEE)、预测集均方根误差(root mean square error of prediction,RMSEP)以及训练集相关系数(R2)评价PLS模型,R2越大,RMSEE和RMSEP越小,说明模型准确性和精确度越高,模型越理想[32]。PLS利用1H NMR数据作为自变量,茶油掺假比例作为因变量,线性拟合1H NMR峰的积分值和掺假比例之间的关系,在一定程度上可以克服传统单变量模型的缺陷,解决以往用普通多元线性回归难以解决的问题。但是,PLS方法有其局限性。当被测组分浓度范围很大时,化学值和样品1H NMR积分值之间非线性因素就会变强,影响测试结果。图8为大豆油掺假样品和玉米油掺假样品的PLS模型,两个模型中R2依次为0.995 0和0.995 9,均大于0.99,RMSEE依次为0.025和0.023,然后采用预测集样品检验此模型,RMSEP依次为0.025和0.020,RMSEE和RMSEP接近于0,检测效果良好,说明PLS模型可用来准确预测掺假茶油中的掺假量。
3 结 论
通过1H NMR指纹图谱可以看出纯茶油、玉米油以及大豆油的主要成分为甘油三酯,含有少量的甘油二酯,角鲨烯和甾醇,且3 种植物油之间存在差异特征峰。随着掺假比例的增加,纯茶油、大豆油掺假样品以及玉米油掺假样品在PCA得分图上呈规律性分布,结合载荷图分析可知甘油三酯、不饱和脂肪酸、亚油酸、亚麻酸以及甘油二酯在区分纯茶油及掺假茶油中起着重要的作用。通过PCA方法可以直观反映茶油及掺假茶油的差异,但是无法判断未知样品。而采用PLS-DA模型则可以有效地区分纯茶油和掺假茶油,其中茶油的判别准确率为100%,当掺假比例大于40%时,玉米油掺假样品和大豆油掺假样品的判别准确率均达到100%。进一步通过PLS模型可准确预测掺假茶油中大豆油和玉米油的掺假量。以上结果说明1H NMR结合PCA、PLS-DA以及PLS等化学计量学方法可简单、快速地对未知茶油进行掺假鉴别。无监督模式识别的PCA能够客观反映原始数据的分类信息,但无法判断未知样品,缺乏确切的数据指标来判别模型的好坏。而PLS-DA作为一种可靠、稳健的有监督模式识别方法,通过分类信息将不同组别样本的分离最大化,而将同类中的方差及协方差最小化,能较好地预测掺假茶油种类。但PLS-DA模型只能判断掺假油的种类,无法判断掺假量。而PLS提供了一种多因变量对自变量的线性回归建模方法,适合掺假体系的定量预测。但是,PLS方法有其局限性。当被测组分浓度范围很大时,化学值和样品1H NMR积分值之间非线性因素就会变强,影响测试结果。在预测茶油掺假量模型中,R2大于0.99,RMSEE和RMSEP接近于0,表明PLS模型可准确预测茶油掺假量。1H NMR结合PLS-DA和PLS可以预测茶油掺假种类和掺假量,具有分析时间短、可控性强、准确性高等优点,可以弥补目前茶油掺假鉴别方法存在的缺陷,为现代油品企业及有关监管部门监测、评价和控制油制品的品质提供了新的研究思路和有效手段,对推动行业科技进步、规范茶油市场、保障消费者合法权益以及促进我国茶油产品事业的健康发展具有重要意义。
猜你喜欢
中国食品(2021年11期)2021-06-23
海峡姐妹(2020年9期)2021-01-04
海峡姐妹(2019年2期)2019-03-23
石油沥青(2018年6期)2018-12-29
现代食品(2016年14期)2016-04-28
广西林业科学(2016年4期)2016-03-16
中国粮油学报(2016年1期)2016-02-06
中国粮油学报(2016年5期)2016-01-23
中国粮油学报(2016年5期)2016-01-23
中国粮油学报(2014年6期)2014-12-27
