
基于层次化聚类的稀疏谓词语义角色标注方法
2018-11-17 01:25:56杨海彤
计算机工程与设计 2018年11期
杨海彤
(华中师范大学 计算机学院, 湖北 武汉 430079)
0 引 言
语义角色标注是一种自然语言处理领域的浅层语义分析技术。它以句子为单位,分析句子中的谓词与其相关成分之间的语义关系,进而获取句子所表达语义的浅层表示。下面是一个语义角色标注的例子:
[警方]Agent [正在]Time [调查]Pred [事故原因]Patient
其中“调查”是谓词,代表了一个事件,“警方”是施事者,“事故原因”是受事者,“正在”是事件发生的时间。由此可见,语义角色标注能够抽取出一个句子表达的事件的全部重要信息。由于语义角色标注可以提供较为简洁、准确、有益的分析结果,因此近年来受到了学术界的普遍重视,并已经成功地应用到信息抽取[1]、自动问答[2]、机器翻译[3]等任务中。
由于语义角色标注的简洁、有效的语义分析能力,吸引大量的研究人员投入到语义角色标注的研究中。文献[4]细致地分析了哪些特征对中文语义角色标注是有效的,并进行了大量的实验验证。文献[5]提出了一种中文句法分析和语义角色标注联合学习模型。文献[6]融合了4个基本的语义角色标注系统,取得了较好的结果。文献[7]研究了位于同一个句子中的多个谓词的语义角色标注之间是否有联系。
目前,语义角色标注系统大多采用有监督的方法来完成语义标注。然而,在有监督的方法体系下,模型的最终效果和性能受到标注数据的规模和质量的影响。目前中文语义角色标注最大的公开语料是中文命题库(Chinese PropBank,CPB)。它是在中文树库的基础上增加了语义角色标注相应的人工标注。尽管中文命题库的标注过程耗费了大量的人力、物力,促进了语义角色标注理论方法的进步[8-11],然而语料的标注过程忽视了一个重要的隐含问题即谓词标注不均匀。谓词标注统计分布整体上表现出明显的长尾现象,一些谓词在中文命题库中被标注了许多次,而大多数谓词仅仅被标注了一次或两次,比如谓词“是”被标注了超过1000次,而80%的谓词仅仅被标注了一次或两次。因此,这些标注次数较少的稀疏谓词由于缺乏足够的训练实例,导致模型很难学习到有效的模型参数,进而语义分析效果要远远地低于其它谓词。而一个实用的语义角色标注系统经常需要处理各种稀疏谓词,因此,研究稀疏谓词的语义分析方法具有理论和现实的意义。
为解决稀疏谓词的语义分析问题,本文提出了一种基于聚合层次化聚类的方法。该方法通过聚合层次化聚类建立起稀疏谓词与常见谓词的联系,把稀疏谓词可以泛化为与之语义相近的常用谓词,进而缓和语义角色标注系统中的谓词稀疏问题。实验结果表明,该方法可以显著地提升稀疏谓词的语义分析性能。
本文的创新点在于:
(1)语义角色标注中稀疏谓词的问题一直以来都被忽视,本文是第一个提出该问题,并进行细致地分析研究的工作。
(2)对于稀疏谓词问题,本文提出了一种基于聚合层次化聚类的方法,可以显著地提升稀疏谓词的语义分析性能,提升了语义角色标注在实际语义分析系统的可用性。
1 中文语义角色标注系统
1.1 数据资源
本文采用中文命题库作为实验的语料。中文命题库(Chinese PropBank,CPB)是宾州大学建设的中文语义角色标注语料库。它是在中文树库(Chinese TreeBank,CTB)的基础上添加了一个语义角色标注层。具体地,该语料通过在句法树中找到与待分析的谓词语义密切相关的成分,并给不同的语义成分赋予不同的语义角色,来实现对句子语义的形式化表示。下面以一个具体例子进行说明。在图1,待分析的句子是“警方已到现场,正在详细调查事故原因”。从图中可以看到在文字部分的上方是该句的句法分析结果,在文字部分的下方是该句的语义角色标注结果。从结果可以看出,“调查”是谓词,被标注为“Pred”,代表了发生的一个事件;“警方”被标注为“ARG0”,是事件的施事者;“事故原因”被标注为“ARG1”,是事件的受事者;而“正在”和“详细”分别被标注为“AM-TMP”和“AM-MNR”代表了事件发生的时间和方式。
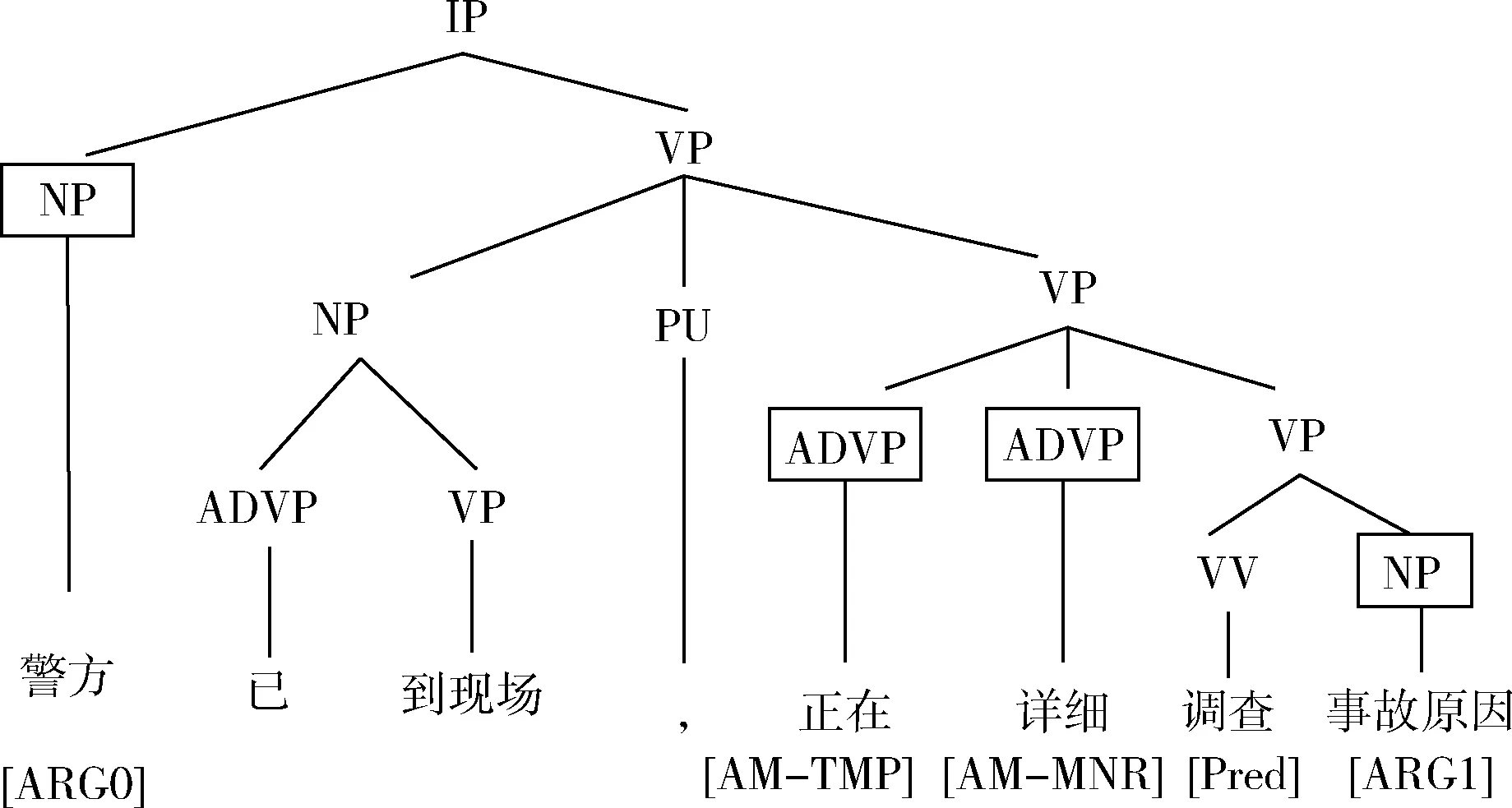
图1 中文命题库中的一个具体实例
1.2 系统框架
本文所采用的标注系统的基本框架如图2所示。句子经过句法分析后,需要先后经过如下的4个模块。
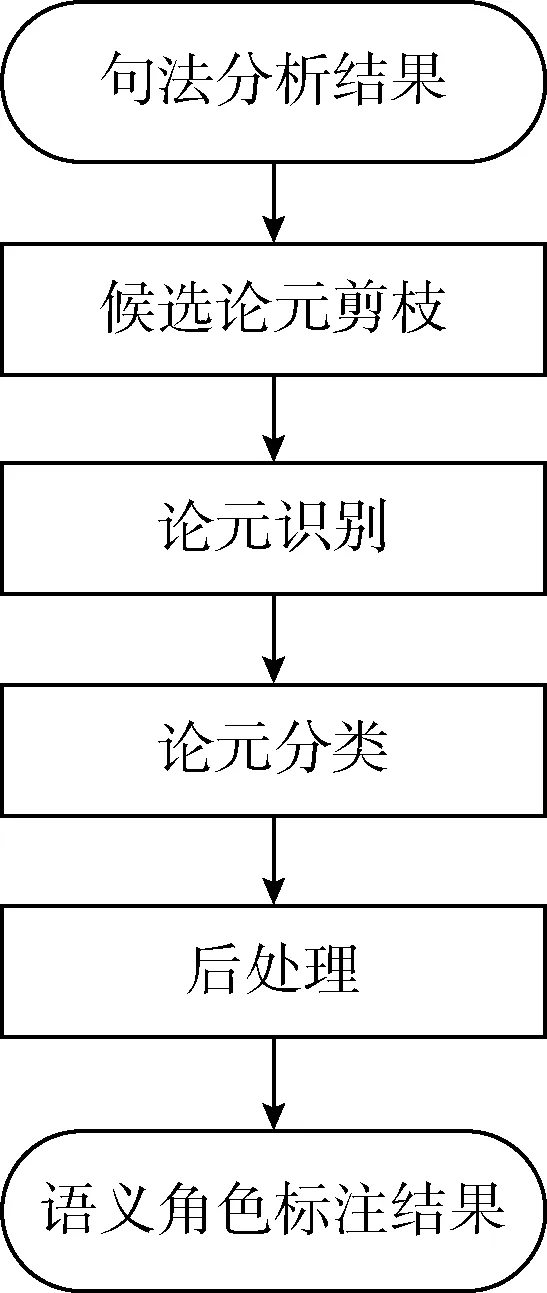
图2 标注系统的系统框架
(1)候选论元剪枝。该模块的作用是从大量候选论元中剪掉不可能是论元的那些候选,从而减少候选论元数目。本文采用文献[4]提出的启发式方法进行论元剪枝。
(2)论元识别。该阶段的目标是从候选论元集合中识别出哪些是真正的论元。一般地,论元识别被当作一个二元分类问题来解决。
本文采用最大熵模型(maximum entropy,ME)完成此二元分类。模型如下式所示
其中,x是输入样例,y是输出结果,即1(是候选论元)或0(非候选论元),fi(x,y)是人工定义的特征函数,θi是特征fi(x,y)相应的参数,Z(x)是一个归一化项,计算方式如下式所示
(3)论元分类。该阶段就要为论元识别阶段识别出的论元赋予一个语义角色。一般地,论元分类会被作为一个多元分类问题来解决。本文依然采用最大熵模型完成此多元分类。
(4)后处理。该阶段的作用是对前面得到的语义角色标注结果进行后处理。
1.3 特征选择
特征选择的好坏直接影响了标注系统的性能。在特征选择方面已有许多相关工作。其中,文献[4]通过实验从大量特征中仔细挑选了一组性能较好的特征。因此,本文系统采用他们使用的特征,详细的特征列表如下:
(1)谓词
(2)候选论元到谓词的句法路径
(3)候选论元的头节点
(4)候选论元头节点的词性
(5)谓词类别
(6)谓词和候选论元头节点的组合
(7)谓词和候选论元句法标签的组合
(8)谓词类别和候选论元头节点的组合
(9)谓词类别和候选论元句法标签的组合
(10)候选论元与谓词的相对位置
(11)谓词父节点的句法生成规则
(12)候选论元的首词和尾词
(13)候选论元的句法标签
(14)句子中名词性短语生成框架
2 谓词的层次化聚类方法
在有监督的方法体系下,如果固定下分类器,那么论元的类别标签是由论元的特征决定的。对于语义角色标注来讲,从1.3节所选的特征可以看出,谓词相关的特征占据了重要的地位,直接影响了标注系统的性能,对系统标注性能起了关键的作用。然而,稀疏谓词由于在训练集中仅仅拥有极少的标注训练样例,因此导致分类器很难学习到一组较优的模型。其中,一种极端情况是从未在训练集中出现过的谓词,这种情况会更加严重,因为重要的谓词特征均成为了词典外特征(out-of-dictionary,OOV),对角色判别不能发挥任何作用。
对于稀疏谓词问题,本文提出了一种基于层次化聚类方法。本文的动机是通过层次化聚类方法为稀疏谓词找到与之语义相近的常用谓词,然后再在特征提取过程中的用找到的常用谓词替代该稀疏谓词。下面举例说明,在中文命题库中,‘操控’仅仅出现了一次,而与之语义相近的谓词‘控制’出现了28次。显然,对于统计分类器而言,较容易学习到‘控制’的概率分布情况。但由于‘操控’和‘控制’具有相近的语义,因此它们应具有相近的概率分布。这启发本文当需要处理稀疏谓词‘操控’时,可以使用常用谓词‘控制’进行替换。具体地,本文使用层次化聚类的方法实现该目标。
2.1 层次化聚类
层次化聚类算法是机器学习和自然语言处理领域被广泛采用的聚类算法。在理论上,层次化聚类算法的目标是通过构建一棵层次化的树结构,从而找出数据集内部各个元素的聚类关联。在具体的实现中,一般有两种层次化聚类策略:
(1)聚合策略
聚合是一种从底向上的方法策略。该策略每次迭代时首先计算各个类别核心的距离,之后将最近邻距离的两个类别合并,形成一个新的聚类,直至所有数据形成一个聚类结束。
(2)分裂策略
分裂是一种从顶向下的方法策略。该策略在算法运行伊始,将所有数据看作一个聚类,之后每次迭代将一个聚类分类为两个聚类,直至每个原始数据都成为一个独立聚类为止。
综合考虑,本文采用了聚合层次化聚类算法对所有的谓词进行聚类。一般地,聚合层次化聚类算法在算法伊始时,把所有的数据点均看作一个独立结点,之后每次迭代过程中,计算出距离最近的两个结点,直至形成一个最终的结点。相比分类策略,聚合策略在运行效率上具有较大优势。
2.2 聚合层次化聚类算法描述
本节对算法实现细节进行详细阐述。本文采用了分布式词向量技术表示每个谓词。分布式词向量技术是近年来自然语言处理领域对词进行表示的主流方法,它的每一维可以看作包含了原始词的句法或语义信息。所有的谓词集合记为P,谓词数目为n,集合P又被划分为两个集合:常用谓词集合Pr和稀疏谓词集合Pc。在聚类过程中,所有聚类结点的集合记为S,结点数目记为Sl,S内部各结点之间的聚类矩阵记为M,其中Mij表示结点Pi和Pj之间的距离。
算法1给出了聚合层次化聚类算法的详细描述。在算法初始化阶段,该算法将每个谓词都作为一个独立的结点看待。在每次迭代时,计算各个结点之间的距离,从而得到距离矩阵M。根据距离矩阵M,找出距离最近的两个结点,并将其合并,形成一个新的结点,该结点的向量表示为上述最近邻结点对的平均。经过n-1次迭代后,所有的结点最终合并为一个统一的结点。在算法1第4行,需要计算两个结点的距离,本文采用了如下的余弦距离公式
算法1:聚合层次化聚类算法
输入:所有的谓词集合P
输出:关于所有谓词的一棵层次化聚类树
初始化所有的谓词为聚类结点集合S中的元素
(1) fork= 1 ton- 1 do
(2) fori= 1 toSldo
(3) forj= 1 toido
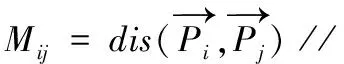
(5) end for
(6) end for
(7)i′,j′←argmini,jMij//从当前聚类结点集合S中找出最近邻的两个结点i′,j′
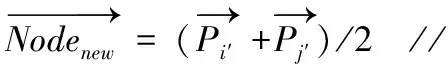
(9) end
2.3 嵌入中文语义角色标注系统
经过算法1,可以得到关于所有谓词聚类关系的一棵层次化树结构。该层次化的树结构反映了所有谓词间的关联信息,语义相近的谓词对将会在树的底层某结点合并,而语义差异较大的谓词对只能在树的高层某结点合并。当一个谓词进入到标注系统时,系统首先判断该谓词是否是稀疏谓词,如果该谓词是常用谓词,则不进行任何处理,直接进行语义分析;如果该谓词是稀疏谓词,则系统首先在上述层次化的树结构中定位到该谓词,之后从底向上搜索,如果遇到的聚类结点中包含常用谓词,则标注系统在抽取特征时自动地用找到的常用谓词替换稀疏谓词。
3 实 验
3.1 实验设置
本文使用中文命题库1.0作为实验数据集。与文献[4-6]相同,所有的数据被划分为3部分:648个文件(chtb_081.fid到chtb_899.fid)作为训练集、40个文件(chtb_041.fid到chtb_080.fid)作为开发集、72文件(chtb_001.fid到chtb_040.fid和chtb_900.fid到chtb_931.fid)作为测试集。本章采用Berkeley parser自动地生成短语结构树,同时句法模型也是在训练语料上重新训练得到的。基线系统中最大熵模型均借助张乐的最大熵工具包进行具体实现。本文将训练集中标记次数少于10次的谓词看作稀疏谓词,重点对这部分谓词进行了研究。
为构建所有谓词的词向量表示,本文采用了开源软件word2vec,在语料Chinese Gigaword corpus上运行CBow模型,窗口设置为10,向量维数设置为200。
3.2 评价指标
语义角色标注领域普遍采用准确率(precision)、召回率(recall)和F1来评价系统的性能。Numright表示正确标注为语义角色的个数,Numtest表示系统预测为语义角色的总数,Numgold表示测试数据中语义角色的总数。那么,它们的定义分别为
3.3 实验结果对比
图3给出了原中文语义角色标注系统的性能,以F1值作为评价指标。本文把所有的谓词按照在训练集中出现次数对测试集数据进行了分组,其中‘0’组表示该谓词从未在训练集中出现,‘1’组表示该谓词在训练集中出现了1次,以此类推。
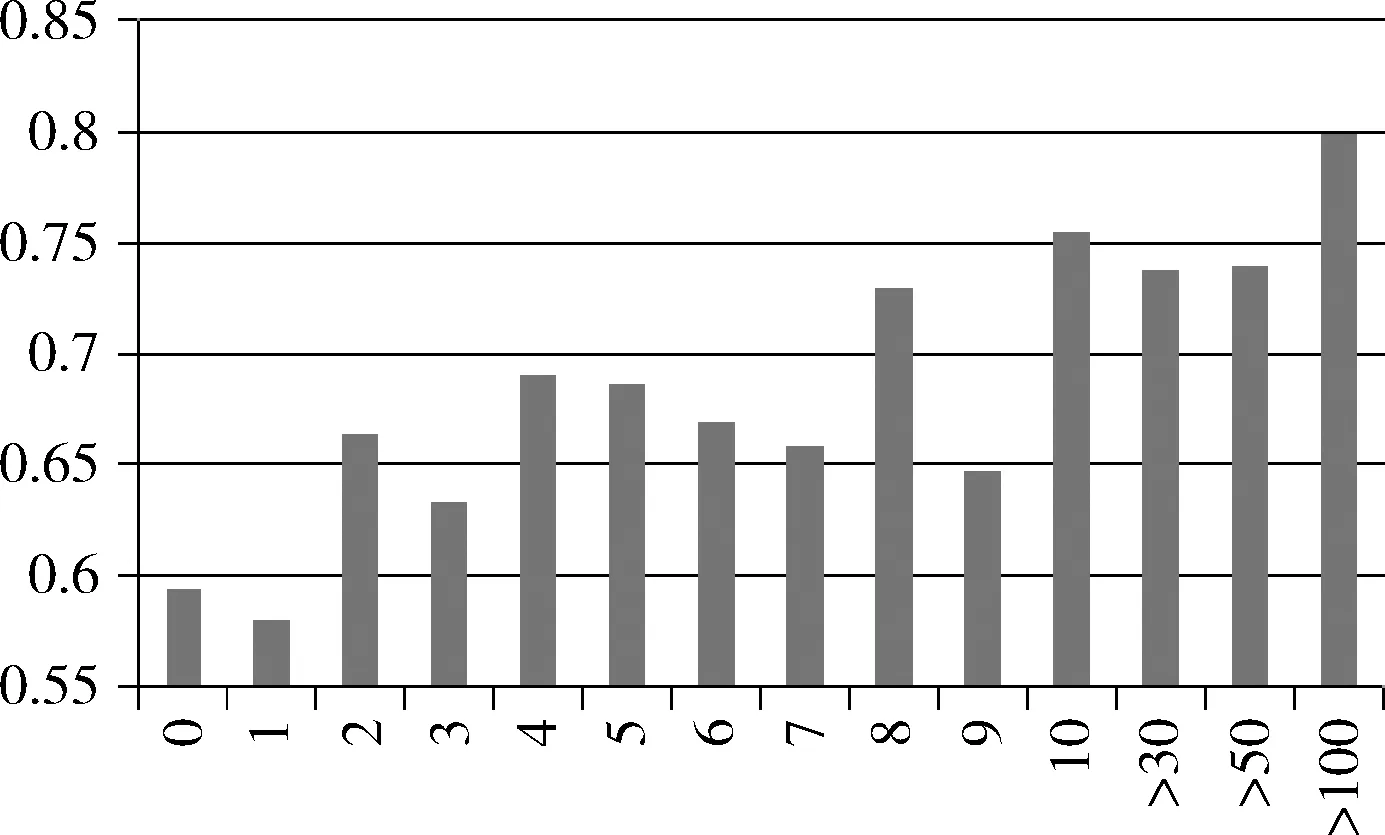
图3 中文语义角色标注系统对于不同谓词的性能对比
从图中首先可以看到一个整体趋势是谓词被标注的次数越多,标注系统对该谓词的语义分析越准确,该现象是符合预期的,因为有监督学习的系统要达到比较好的性能需要一定数量的训练数据。而对于稀疏谓词而言,正是因为不能提供足够的训练数据导致性能远远低于常用谓词。性能最低的谓词组‘0’比性能最高的谓词组‘≥100’低了将近20个百分点F1,这突出反映了稀疏谓词问题的严重性。需要注意的一点是,‘0’组谓词即从未在训练集中出现的谓词,在测试集中占比达到20%,但是该组谓词的语义分析性能最低。在实际应用中,如果一个标注系统一旦遇到未出现过的谓词,经常会输出错误的分析结果,显然该标注系统是不能满足实际需求的。因此,一个实用的语义角色标注系统应能处理各种谓词。研究稀疏谓词的语义分析方法也具有较大的现实意义。
表1给出了本文提出的方法的性能。从表中可以看到本文提出的方法可以显著地提升稀疏谓词的语义分析性能。‘0’组谓词的性能提升幅度最大,F1值由59.32%提升到61.05%,约1.7%的提升幅度,其它组稀疏谓词也均具有较大幅度提升。所有稀疏谓词的F1值由68.70%提升至69.75%,平均约有1%的提升幅度。为检验本文提出的方法的结果是否是统计显著的,本文采用了重采样的方法对结果进行显著性检验。检验结果表明在p<0.05的设置下,本文提出的方法的结果显著优于原中文语义标注系统的结果。
下面通过一个具体实例进行进一步的分析。下面是原中文语义角色标注系统的一个分析结果,[各项存款]Arg0[比七五]ArgM-TMP净增五十亿元[Arg2],然而,上述结果对于论元‘五十亿元’的标注结果是错误的,它的正确标记应为Arg1。该句中的谓词是‘净增’,但该谓词在训练集中从未出现过,所以导致谓词相关的分类特征的缺少,进而使得分类器出现分类错误。本文通过构建的层次化树结构找到与‘净增’语义最相近的常用谓词是‘增长’,该谓词在训练集中出现了237次,拥有足够的训练数据,因此分类器可以学习到较好的模型参数。最终,本文提出的方法正确的修正了上述例句中的错误结果。
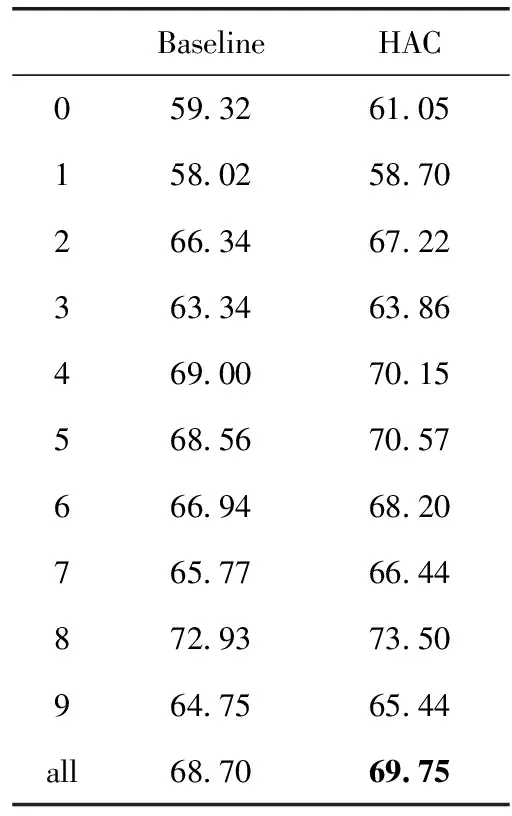
表1 实验结果对比
本文还测试了提出的方法在跨领域数据上的性能。领域适应问题是语义角色标注的亟待解决的问题之一。导致领域适应问题的主要原因是领域外与领域内之间的数据分布差异,而其中谓词的差异也较为突出。由于中文缺乏跨领域的语义角色标注数据,本文在英文的布朗数据集(brown corpus)进行了测试,实验数据选择了英文命题库(English PropBank,EPB)作为训练集。表2给出了详细的实验结果对比。从表中首先可以看到,在领域外数据集上语义角色标注系统也表现出了谓词被标注的次数越多,标注系统对该谓词的语义分析越准确的趋势,反之,谓词被标注次数较少的话,语义分析性能较差。同样地,‘0’组谓词的语义分析性能最差,比最高得分的谓词组低了20%。可见,在领域外数据集上,稀疏谓词的情况也非常严重。从表中可以看到本文提出的方法可以显著地提升稀疏谓词的语义分析性能。‘0’组谓词的分析性能提升幅度最大,由44.64%提升到46.22%,约1.6%的提升幅度,其它组稀疏谓词也均具有较大幅度提升。所有稀疏谓词的F1值,由60.15%提升至61.40%,平均约有1.3%的提升幅度。在p<0.05的设置下,本文提出的方法的结果显著优于原语义标注系统的结果。
4 结束语
在有监督的方法体系下,语义角色标注系统最终效果和性能受到标注数据的规模和质量的影响。然而,当前公开的标注语料对于不同谓词的标注是不平衡的,有些谓词被多次标注,而有些稀疏谓词仅仅被标注一次或两次,甚至还有大量谓词未被标注。所以,稀疏谓词问题严重限制了语义角色标注在实际中的应用。而目前,语义角色标注领域尚未有稀疏谓词的研究工作。本文对语义角色标注任务中的稀疏谓词问题进行了细致地分析,并对该问题提出了一种基于聚合层次化聚类的方法。实验结果表明本文提出的方法可以显著提升稀疏谓词的标注性能。
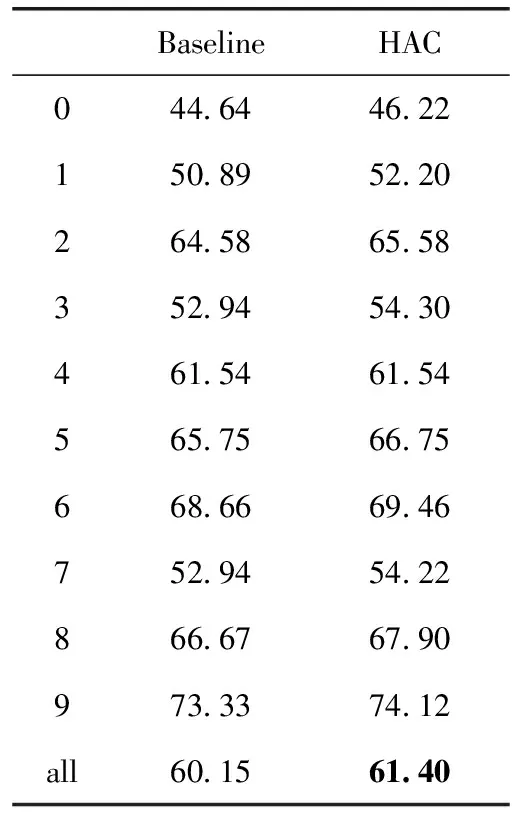
表2 领域外实验结果对比
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31 08:57:30
——论胡好对逻辑谓词的误读
现代哲学(2020年5期)2020-11-30 17:00:36
西夏研究(2020年2期)2020-06-01 05:19:12
韶关学院学报(2017年4期)2017-04-13 20:25:22
海外华文教育(2016年3期)2017-01-20 08:22:14
铁道通信信号(2016年1期)2016-06-01 12:10:17
外语学刊(2016年4期)2016-01-23 02:33:55
中国舰船研究(2015年2期)2015-02-10 06:45:44
江西师范大学学报(哲学社会科学版)(2014年1期)2014-09-05 07:44:12
航天返回与遥感(2014年5期)2014-07-31 17:57:09
