
基于分段式序列图片集的运动恢复结构
2018-11-17 02:50倪颖婷
计算机工程与应用 2018年22期
罗 米,赵 霞,陈 萌,郭 松,倪颖婷
1.同济大学 电子与信息工程学院(控制科学与工程系),上海 201804
2.上海宇航系统工程研究所,上海 201100
3.上海航天技术研究院,上海 201109
1 引言
运动恢复结构(SFM)是三维重建流程的第一步,也是最重要的一步。它计算每张图片所对应的相机的位置与朝向,在后续步骤中使用该参数计算三维点云的坐标,而相机参数直接决定了三维重建的精度。SFM过程分为四部分:特征提取,特征匹配,姿态估计,参数优化,这四部分共同决定SFM的重建速度与精度。
在通常的三维重建流程中,SFM使用一种增量式的方法[1-2],逐个初始化相机姿态,每个新的相机姿态要根据之前已初始化的相机姿态进行恢复,导致花费的时间会随着输入图片的数量增多而大幅增加。如表1所示,用Visual SFM[3]软件对不同图片集进行稀疏重建所花费的时间。可以看出,随着图片集数目的增大,重建时间增长很快。同时,由于建筑物的正面视图与背面视图几乎不同,它们之间的计算不但耗费计算时间,还可能因为噪声而降低重建精度,这些图片之间的计算是完全没有必要的。

表1 重建时间与图片集数量
为了加快SFM的重建速度,Schonberger等[4]提出了一种基于学习的图片配对方法,通过训练分类器将图片配对编码,实现成对图片的快速重建,但需要进行额外的训练步骤。Ni等[5]使用二分结构将SFM视图转化为相机超图,然后根据递归分割得到子图并形成树状结构,最后采用自底而上的优化方法,减轻了相机的初始化计算,但是由于额外添加了子图,仍需要大量的BA优化。
另外,在增量式SFM中,首先基于两张或三张图片计算初始的相机姿态,使用五点法或六点法[6-7],根据图片间的特征点计算相应的相机外参数矩阵,然后以一张图片的相机坐标系或自定义坐标系作为世界坐标系,随后将新的图片添加到世界坐标系中表示。该方法若不添加局部BA优化过程,会导致重建精度低下。图1为使用增量SFM对喷泉图片集进行重建的结果,(a)为喷泉图片集中的四张图片,(b)为经过BA优化的相机姿态图片,(c)为不使用BA优化的相机姿态图片,可以看出不使用BA优化会使重建结果远离真实值。因此,为了确保能够成功重建,需要在每次添加新图片时使用局部BA进行优化,但是由于添加了大量的局部BA,又会导致效率低下。

图1 增量SFM的喷泉图片集重建示意图
随着后续图片的加入,相机参数误差的漂移越来越大,对于闭合循环的图片集,经常会导致最后的闭合失败,添加了BA优化步骤也不一定能够解决这一问题。因为BA优化通常使用LM(Levenberg Marquard)方法最小化总重投影误差,优化结果很大程度上取决于初始图片对的选择和后续图片的添加顺序,容易收敛到局部最优值。
图2为闭合图片集正常闭合和闭合失败的例子,(a)为由于误差积累,相机姿态右上角部分闭合失败,(b)为闭合的相机姿态。

图2 闭合图片集重建示意图
为了解决增量式方法中的漂移误差,并提高效率,Sinha等[8]提出基于点和消失点对图片进行匹配,最后进行全局相机姿态优化,不需要局部BA优化,但这种方法需要额外的消失点检测算法。Cui等[9-12]提出了一种全局式的SFM。与增量式的方法相比,它同时恢复所有相机的位置与方向信息,考虑了全局误差的均匀分布,不会产生误差漂移,同时效率较高。但是这种方法的图片集需要由三个相机得到,在图片集中构成一定的约束关系,而且全局式的方法对抗噪声的能力较差,容易因为图像噪声而产生错误的重建点,影响到全局相机位置恢复。
本文提出了一种分段式的SFM方法,介绍了该方法的组成与实现,并通过实验分析了该方法在精度和速度方面与普通方法的优劣性,最后说明了该方法的不足之处与未来展望。
2 分段式运动恢复结构
考虑一个有序的图片集,此处有序指图片由相机环绕场景逐帧得到,相邻图片间存在一定的顺序对应关系。策略是把相机姿态朝向接近的图片划分到一个图片集,将总图片集分为多个互有交集的子图片集,对子图片集分别进行独立的重建(易于实现并行化),最后再将各模型之间共有的部分完成融合,进行全局优化。方法分为四个步骤:初始集合划分,连接集合确定,稀疏重建合并,全局参数优化。

图3 初始集合划分示意图
2.1 初始集合划分
根据图片集的数量和硬件的计算能力确定划分的集合数。确定中心图片:由于图片集有序,随机选取一张图片作为中心图片,根据集合数,其他集合的中心图片也随之确定,即初始图片集划分完毕。
为保证局部重建效果与全局合并效果,每个子图片集需要有一定数量的图片(最少图片数),经实验,本文将这个数量设置为8。可以根据CPU核数与线程数确定集合数,简单地可以一核一线程划分为一个集合,当划分后的子图片集中图片数量大于8时,称为大图片集,反之称为小图片集。小图片集可以根据图片总数及每个集合8张图片确定集合数。
设每个子图片集基本图片数量为n,中心图片为Imid(mid∈[1,S],S为集合数),M 为图片集总数量,构成图片集合Ni,在大图片集中,有:

而在小图片集中,需要首先确定集合数,有:

然后计算剩余图片数,最后将剩余图片从最后一个集合往前逐集合加入:
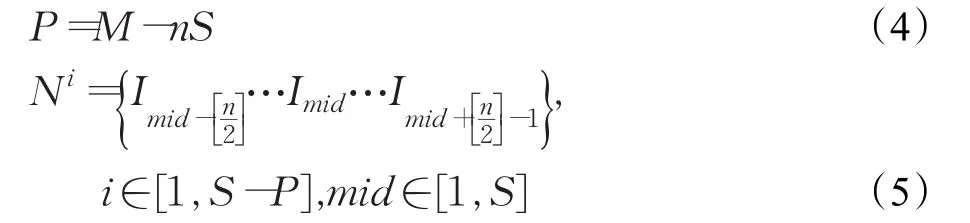
初始集合划分示意图如图3所示:

2.2 连接集合确定
当划分好初始集合后,需要确定相邻图片集之间的连接关系,为独立重建后的合并过程做准备。
连接图片的确定:本文使用SIFT(Scale Invariant Feature Transform)[13]算法提取并匹配中心图片和连接图片的特征点,再将经过随机采样一致性算法过滤后剩余的匹配点对数目作为相似度的量度,相似度高表明两图片对应的相机姿态较为接近,在独立重建时匹配点对较多,重建精度也较高。首先计算相邻图片集连接处图片与图片集中心图片的相似度,然后使用与中心图片的相对相似度作为约束条件,满足条件的定为连接图片,最后将连接图片集添加到各图片集之中。
(1)针对相邻图片集,设第i个和i+1个图片集的图片数量都为n,将第i个图片集的最后一张图片Nni和第i+1个图片集的第一张图片加入连接图片集,即:

(2)先计算第i+1个图片集第一张图片与第i个图片集中心图片的相似度,然后依次用第2张至第张图片,计算其与第i个图片集中心图片的相似度。若当前图片的相似度大于前一图片相似度,则将此图片加入中,继续比较;若当前图片的相似度小于上一图片的相似度,则说明相似度呈下降趋势,结束该步骤(例如先计算第一张图片的相似度,再计算第二张图片的相似度,若第二张图片的相似度大于第一张,则将第二张图片加入到连接图片集中,然后计算第三张相对第二张的相似度,当相似度小于第二张时,退出当前步骤,反之继续将第三张图片加入连接图片集)。
再计算第i个图片集最后一张图片与第i+1个图片集中心图片的相似度,然后依次用第n-1至n/2张图片,计算其与第i+1个图片集中心图片的相似度。若当前图片的相似度大于前一图片相似度,则将此图片加入中,继续比较;若当前图片的相似度小于上一图片相似度,则结束该步骤。
上述原理的伪代码实现如下所示:


连接集合确定示意图如图4所示。
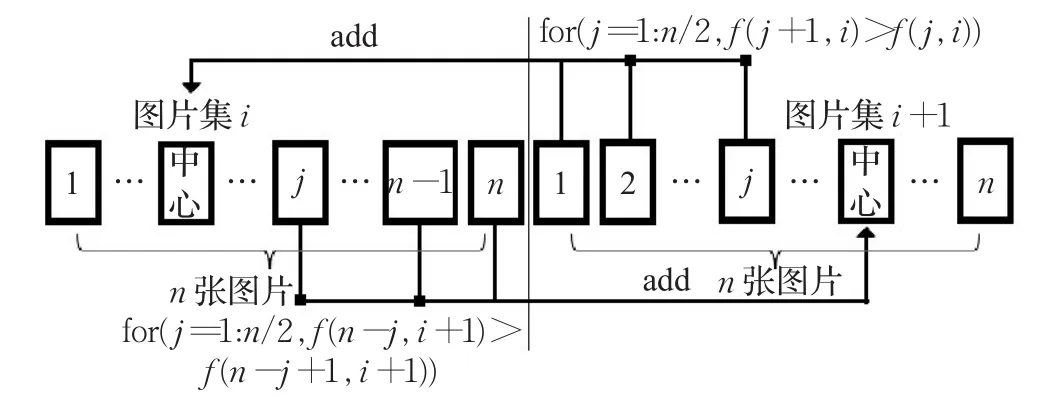
图4 连接集合确定示意图
2.3 稀疏重建合并
在连接集合确定之后,可以对每个集合进行独立SFM重建,得到每个集合的相机姿态。由于集合与相邻集合之间存在相同图片的相机姿态信息,可以根据此对所有图片集进行拼接。计算相邻集合中相同图片之间的相对旋转矩阵,取均值后得到图片集之间的旋转矩阵,最后再经过旋转平移尺度变换等将所有图片集转换到同一坐标系。
伪代码实现如下:

end
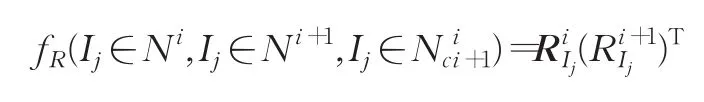
备注:
(2)将图片集Ni+1所有相机姿态使用旋转到与Ni同一个坐标系,最后所有图片集与N1处于同一个坐标系。

(3)经过尺度变换、平移变换等,将所有子图片集变换到同一尺度空间中,如图5所示。
2.4 全局参数优化
经过稀疏重建合并后的模型只使用了简单的拼接,精度会比较低,需要用全局BA[14]进行优化。即将合并后的稀疏点云经投影矩阵重投影回图片中,计算投影位置与实际位置的误差和,再使用非线性最小二乘算法最小化这个误差和。公式为:

其中,Pi为第i张图片的投影矩阵;Mj为第 j个重建3D点;n为重建的3D点个数;m为图片数,mij为点Mj在图i中对应的二维点坐标;ψ(PiMj)表示点Mj在图片i中的投影。
本文提出的方法将集合分为多个子集合,子集合可以进行SFM并行处理,充分利用已有硬件条件,以提升重建速度。这种方法的重建精度不局限于最初的图片对,每个子图片集中,都是不同的初始化图片,在最后全局BA优化中,更可能收敛到全局的最优值。
3 实验结果与分析
本文使用两类图片数据集[15-16]进行实验:第一类包括QingHua.D(33张)、Teaching.B(78张)、Science.B(102张)、ZhanTan.T(158张)4个数据集,由于这类数据集图片数量比较多,用其进行了普通SFM和分段式SFM的时间效率比较实验。第二类数据集包含Fountain(11张)、Herz-Jesu(25张)、Castle-L(30张)3个数据集,这类集合中包含每张图片的真实相机姿态,可以用来评估普通SFM与分段式SFM的精度。
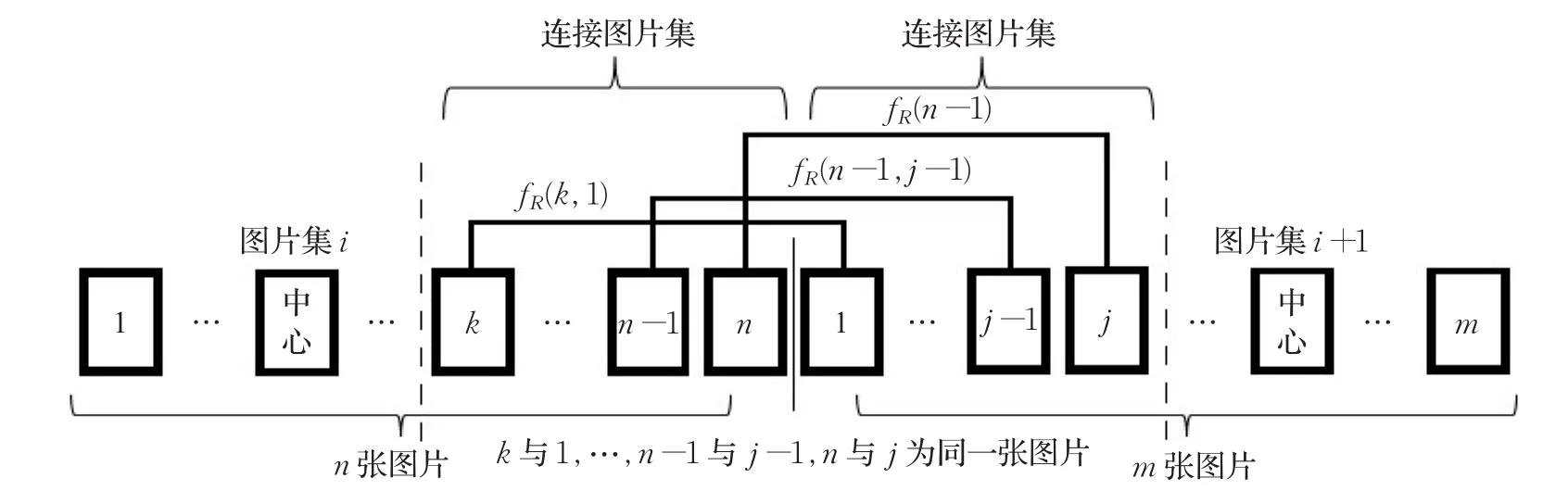
图5 旋转矩阵计算示意图
3.1 分段重建
以QingHua.D数据集为例,它包括33张图片。选取第二张图片作为中心图片,先划分初始集合得到基本集合为[31 32 33 1 2 3 4 5]、[6 7 8 9 10 11 12 13]、[14 15 16 17 18 19 20 21]、[22 23 24 25 26 27 28 29 30]。相似度的计算使用了开源计算机视觉库OpenCV的GPU_SURF模块,添加连接集合后分为4个集合[30 31 32 33 1 2 3 4 5 6]、[5 6 7 8 9 10 11 12 13 14 15]、[13 14 15 16 17 18 19 20 21 22 23]、[21 22 23 24 25 26 27 28 29 30 31 32],集合中的数字代表数据集中的图片序号。添加连接集合后的第4个子图片集如图6所示。

图6 QingHua.D数据集中第4个子图片集
添加各子集的连接集合后,使用SFM同时进行重建,得到各集合的相机姿态信息,计算集合之间的相对旋转变换矩阵R,将所有相机姿态使用R进行变换,再经过尺度、平移变换之后,并将所有的输出转化为CMVS(Clustering Views for Multi-view Stereo)[17]的要求输入格式,最后进行PMVS(Patch-based Multi-view Stereo Software)[18]密集重建。图7为相机姿态合并示意图,图8为合并后的重建模型示意图。
该方法能在全局优化后获得所有的姿态信息和相对位置关系,能成功完成闭合相机姿态的重建。而传统SFM软件可能会因为漂移误差而不能判断相对位置关系,特别是正面背面较为相似的物体重建时,错误更加明显。图9显示了一种错误的相机姿态,导致密集重建时背面部分不能正确重建。
3.2 定量对比

图7 相机姿态合并示意图

图8 合并后的重建模型示意图

图9 错误的相机姿态重建
本文使用的CPU为I5-6400核心,共4核4线程,显卡为GTX1060,将集合数定为4。在第一类数据集中评估了普通SFM和分段式SFM的时间效率,如表2所示;在第二个数据集中包含了具体每张图片的真实相机姿态,故使用第二个数据集评估了普通SFM和分段式SFM的精度,如表3所示。
3.3 实验分析
实验结果表明,分段式SFM在时间效率上有较大提升。相较于普通SFM需要对整个图片集进行匹配重建,分段式SFM只需要对子图片集内的图片进行匹配重建,TMatch时间大大减少。TLBA所花费的时间也随着图片集的增大,有着比较明显的减少。因为在全局BA优化中使用的方法为多核集束调整,所以花费时间也较少。相比普通SFM,分段式SFM在大数据集上所花费的时间大大减少,适合应用于需要快速建模的大型场景中。
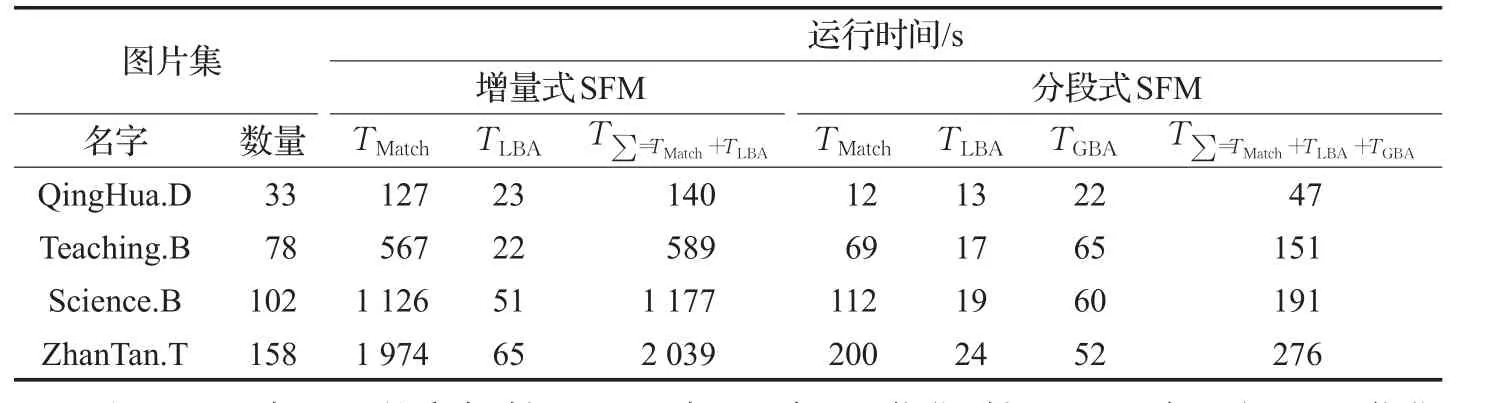
表2 增量式SFM与分段式SFM的运行时间比较
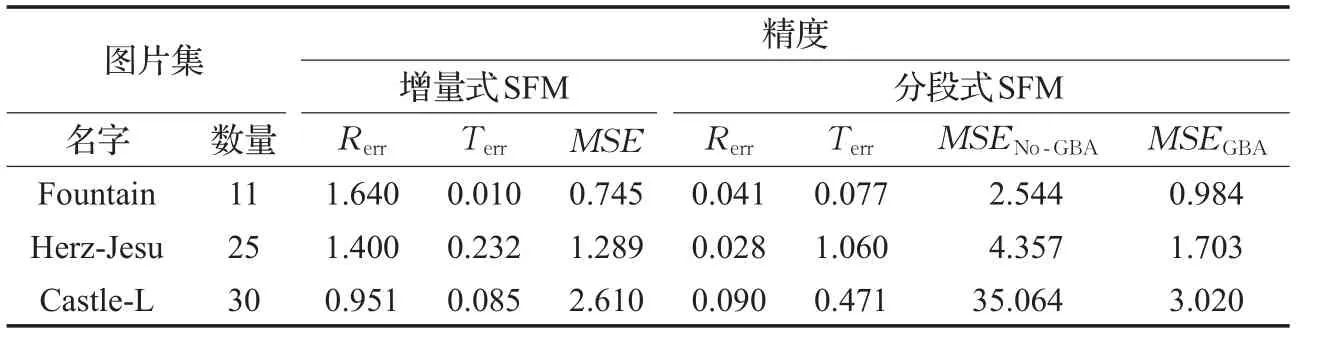
表3 增量式SFM与分段式SFM的精度比较
在精度方面,由于是子图片集独立重建,漂移误差较小,同时旋转矩阵误差与尺度、平移变换无关,Rerr误差较普通方法有所减少。Terr误差由于相邻图片集之间的连接图片对应的相机位置有一定误差,在经过尺度、平移变换后进行合并拼接时,需要对相机位置进行一定程度的近似处理,因此Terr误差有所增加。而三维点经过变换后,同样由于尺度、平移变换误差等,导致MSEGBA有所增加。虽然部分误差有所增加,但是仍然能够完成密集重建,满足大部分建模应用需求。
4 结束语
本文提出的方法适用于有序的闭合图片集,重建速度较普通SFM有较大提升,同时重建精度与普通方法接近,适用于重建精度要求不是特别高的大型数据集的三维重建。接下来需要将整个方法拆分并进行模块化,添加到三维重建流程中,同时可以考虑改进子图片集的合并方法,结合点云匹配使用G-ICP(Generalized-Iterative Closest Point)算法,将文章中计算得到的旋转矩阵与平移矩阵作为G-ICP算法的迭代初值,利用子模型间共有的部分进行点云融合,可以进一步提高重建结果的精度。
猜你喜欢
数学物理学报(2022年4期)2022-08-22
数学物理学报(2022年2期)2022-04-26
数学物理学报(2021年4期)2021-08-30
数学小灵通(1-2年级)(2020年9期)2020-10-27
当代贵州(2019年41期)2019-12-13
小学生学习指导(低年级)(2018年11期)2018-12-03
金桥(2018年4期)2018-09-26
太空探索(2016年9期)2016-07-12
中国共青团(2015年7期)2015-12-17
中国卫生(2014年5期)2014-11-10
