
基于Q-learning机制的攻击图生成技术研究
2018-11-10 01:55张书钦李凯江杨峻峰
电子科技 2018年10期
张书钦,李凯江,张 露,杨峻峰
(中原工学院 计算机学院,河南 郑州 450007)
攻击图是一种脆弱性关联分析技术,主要用于对攻击者的多步攻击进行分析。相对于传统的漏洞扫描,攻击图技术更适合在大规模网络中对网络中的脆弱性、防护目标等整体安全状态进行监控。分布式中间件在大数据领域的大规模使用[1-3],使攻击图技术在整个网络进行安全状态的分析中得到了更广泛的应用[4-5]。
目前,基于操作系统级别的安全防御已经不能满足用户对安全的要求[6]。因此针对漏洞技术的扫描方式得到了大规模的使用,漏洞扫描为网络安全的自动化建模提供了可能。攻击图在不同的网络应用中具有不同的数据结构组织方式和表现形式[7-8]。攻击图的生成方式大多使用传统的图结构的遍历和搜索进行构造。文献[9]通过不确定图模型提出了一种攻击图的生成算法,从攻击者的目标出发,逆向模拟生成攻击图,可以较好的模拟现实攻击情况并找出最可靠攻击路径[9]。文献[10]利用一种逆向深度优先攻击图生成算法和基于区间树的规则匹配算法进行攻击图的生成[10]。传统的攻击图生成方式虽然有效,但随着网络规模的增大,使用传统方法会产生攻击图中节点爆炸的现象。随着分布式计算和大数据研究的发展,国内外研究者也将该技术应用在了攻击图中。如文献[11]构建了基于大数据的Nosql攻击图数据模型[11],文献[12~13]利用了马尔科夫链特性,将其应用在了入侵检系统的分析中,提高了防御的成功率[12-13]。文献[14]通过对数据结构的改进,在使用广度优先搜索算法的基础上使用分布式技术生成了攻击图[14]。随着计算能力和分布式计算的发展,基于无状态的机器学习算法已成为网络攻击图的一个研究热点。
为了改善攻击图生成算法的效率和规模,文本将使用Q-learning机制进行攻击路径的模拟生成,将智能体所处的环境作为攻击图。智能体通过场景对攻击图进行构造,当智能体经历过所有的安全状态空间时,攻击图生成结束。
1 基于Q-learning的攻击图环境模型
Q-learning是一种解决动态规划问题的算法思想。结合攻击图的性质,其系统结构如图1所示。智能体通过漏洞扫描对攻击图环境进行感知,并且通过攻击模板查看当前状态的动作,选择动作后获取攻击图环境的回报,并根据回报更新攻击图中的Q函数表。
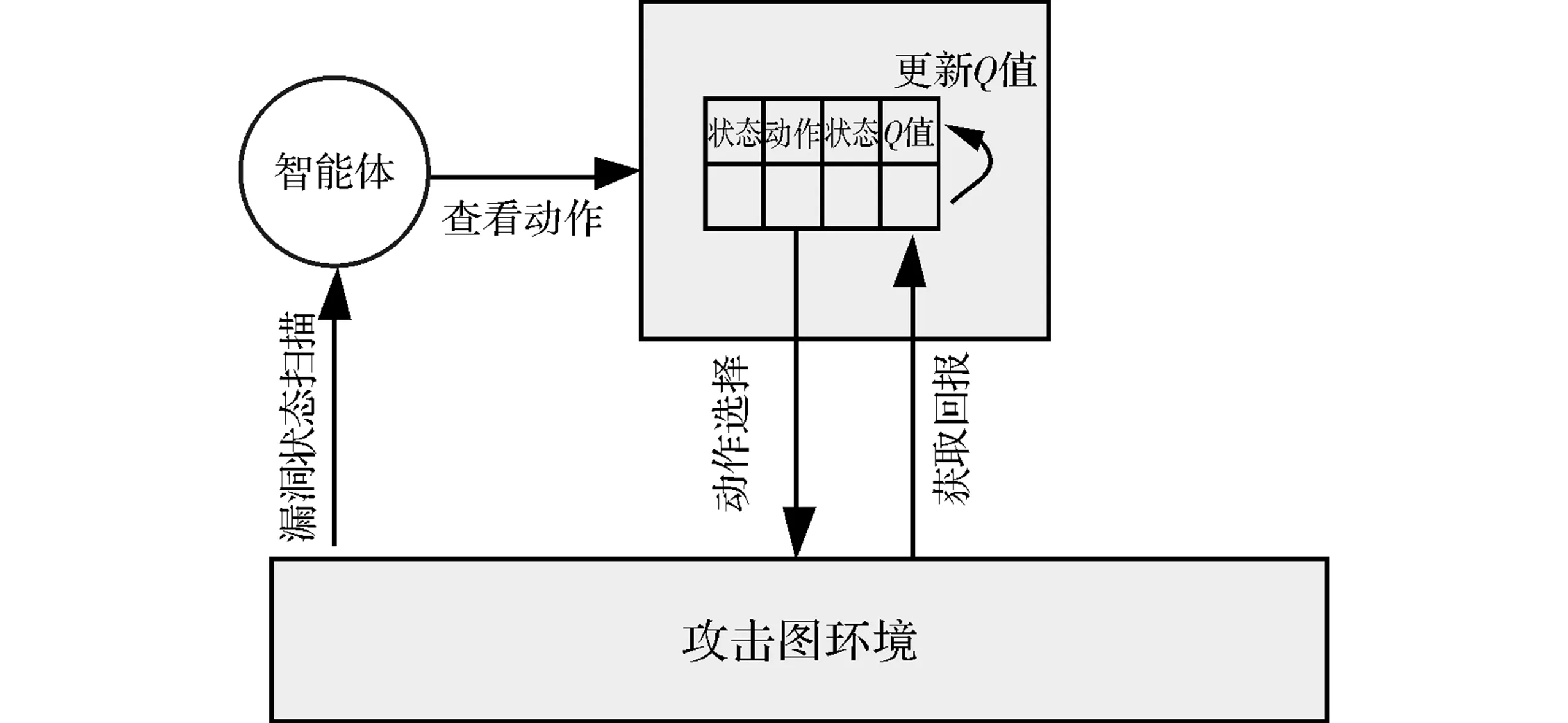
图1 攻击图生成中Q函数积累值的收敛过程
攻击图的拓扑结构是具有若干个初始节点和终端节点的有向图的描述。可以将一个攻击图定义为Q-learning的整个环境。整体定义如下。
定义1攻击图作为Q-learning智能体认知的环境T=(State,Action,Stateinit,Statetarget,γ, refund),其中State代表攻击图中的节点,有漏洞节点和状态节点两种类型。Action代表智能体可以选取的动作类型,具有攻击和防御两种类型。Stateinit代表智能体可以作为攻击初始状态节点的集合。Statetarget代表智能体的收敛状态集合。其中折扣因子和收益两部分是根据Q-learning状态模型而来的辅助结构。
定义2环境空间状态空间State,代表攻击图中智能体可能到达的状态的集合。节点类型有两种,分别为漏洞节点和状态节点两种类型。节点用四元组表示(id,type,State_value)表示,其中id表示状态节点序号,type表示当前节点类型,State_value表示当前节点描述,漏洞节点为漏洞组信息,状态节点表示当前的网络状态或者攻击后状态。
定义3动作Action代表智能体可以进行选择的动作集合,具有攻击和防御两种行为,用(src,dst,cveids,attack_qvalue,defense_qvalue)表示。其中src表示前驱状态节点,dst表示后继状态节点,cveids表示利用或者修复的漏洞组中cveid序号集合,attack_qvalue表示利用脆弱性攻击后的q值,defense_qvalue表示修复脆弱性后的q值。智能体在进行攻击时,主要通过攻击模板进行攻击前提(状态节点)和攻击后果(状态节点)的判断。攻击模板
定义4折扣率γ表示攻击者在进行回报获取时,随着攻击的时序获取回报的比率。
定义5立即奖罚值refund表示智能体进行动作选取后得到的回报值。
2 基于Q-learning的网络攻击图生成算法
2.1 Q-learning机制
Q-learning的数学本质是马尔科夫决策过程。在马尔科夫决策过程(Markov decision process)中0,智能体可通过脆弱性扫描来对当前网络形成感知,通过对当前环境的认知,可以通过攻击模板选择合适的动作(即在当前节点选择攻击的方式以及防护的方式)。智能体通过决策作用于攻击图环境后,该攻击者都可以感知当前的State。网络状态空间都会对该决策进行反映,给出相应的回报rt=r(Statet,actionu),之后进入下一个状态Statet+1=g(Statet,actionu) 。在MDP中,r和g只依赖于当前的Statet状态,并不依赖之前State序列。这充分满足了马尔科夫链的状态性质。
结合攻击图的特点,对于具有特定目标的攻击,智能体可以将该目标中的节点作为收敛状态结束一次场景的学习。使用Q-learning机制最大的特点就是场景的无状态性,每次智能体的学习过程都与其他的学习场景没有必然的依赖,因此可以采用多主机多线程的方式对攻击图进行维护。
2.2 基于Q-learning的攻击图构造过程
为进行攻击图的构造,将整个网络状态空间模拟为一个攻击图,将从当前扫描的初始状态为始发节点到攻击目标的攻击序列模拟为攻击路径。通过Q-learning机制中的智能体可以对整个攻击图进行攻防的模拟,并在模拟中对攻击图进行构造。攻击者对网络的攻击可以看作是对当前网络中的某个状态属性的迁移。对于一次原子攻击,攻击者可以通过攻击模板中的多种攻击方式进行选择,并且在攻击后获得一定的回报。智能体通过采取多步攻击防御,最终到达攻击目标对应的收敛状态。智能体在进行攻击防御过程中经过的节点状态序列形成了攻击图中的攻击路径。最终智能体通过在场景学习中完成对整个攻击图生成的过程。
智能体在进行攻击图的生成过程中不可能进行无休止的场景学习。对于智能体在进行决策过程中是通过贝尔曼方程在Q-learning机制中的Q函数提供依据的。通过对当前环境中Q-learning中的Q函数积累值收敛作为攻击图构建完毕的条件。

(1)
其中,state,action表示当前的状态和行为,α代表当前智能体的学习率。R(state,action)表示智能体在状态state时采取action动作得到的立即奖罚值。
2.3 基于Q-learning的攻击图生成算法
本文利用增强学习中Q-learning对网络扫描状态进行转换分析,并且对当前的节点状态进行决策。通过维护攻击图的Q函数表为智能体的决策提供下一步的行为建议,并通过对学习率α的设置防止在攻击图生成过程中Q函数积累值过早的收敛。Q函数积累值的过早收敛会引起攻击图中的节点丢失。
该算法基本思想为:在进行攻击图生成算法前,需要对网络环境中的Q函数表进行初始化(初始值为0)。算法的输入中需要输入攻击模板、学习率、折扣率、攻击目标和初始节点集合,算法的输出为攻击图。算法中,智能体根据对网络环境的扫描从初始状态节点出发,根据当前状态节点与当前攻击图中的后继漏洞节点根据Q函数表和学习率进行动作的选择。在进行动作选择的过程中,智能体需要对Q函数表按照式(1)进行维护,并且通过攻击模板的匹配结果对后继漏洞节点和攻击后果状态节点进行增量添加。智能体通过动作选择到达下一个攻击后果状态节点。通过一次次的动作选择,智能体把到达攻击目标状态的攻击路径作为一次场景学习。智能体通过场景学习对攻击图进行扩展,直到当前Q函数积累值Qsum收敛,则认为该网络状态的攻击图生成结束。具体算法如下
input:target,attackRules,inits,γ,α
output attackGraph
attackgraph_build(target,attackRules,inits,γ,α){
attackGraph =null
∥Q函数积累值是否收敛
do{
∥判断是否智能体完成该次场景
while(!init∈target){
∥初始状态节点选择
init=initChoose(inits)
attackpath=null;
∥智能体可选动作集合构造
chooseSet=null;
∥根据攻击图中的节点,构建智能体可选动作集合
chooseSet=getchooseSet(attackGraph,init)
foreach(attackRule:attackRules){
∥如果攻击图中没有该后继节点,并且攻击模板中有,将添加到智能体的可选动作集合中
if(init∈attackRule&&! chooseSet.contain(attackRule)){
chooseSet.add(attackRule,0)
}
}
∥根据式(1)进行决策选择和Q函数表更新
state=chooseStateByQ(chooseSet,α,γ)
Attackpath.add(state)
init=state
}
∥将攻击路径添加到当前攻击图中
attackGraph.add(attackpath)
}while(!Qsum.is Convergence)
return attackGraph
}
3 实验仿真及结果分析
3.1 实验环境搭建
为了进行有效性的验证,设置的包含两个主机的仿真平台配置如表1。主机192.168.1.111作为普通PC,主机192.168.1.112搭建MDNS服务,包含一个CVE-2007-2446漏洞。攻击者处于该局域网外,但是可以通过路由器与该局域网通信。

表1 网络实验配置
3.2 实验结果和分析
强化学习的方式本身就适合基于大数据的分布式方式。由于文中采取了基于智能体学习场景构建的攻击图,并且智能体的每次学习过程独立进行。所以实验中采取多线程方式模拟分布式中基于RPC的通信方式进行训练学习。
通过基于Q-learning机制的攻击图构建,最后收敛时攻击图如图2示,共包含22个节点和22条逻辑攻击。
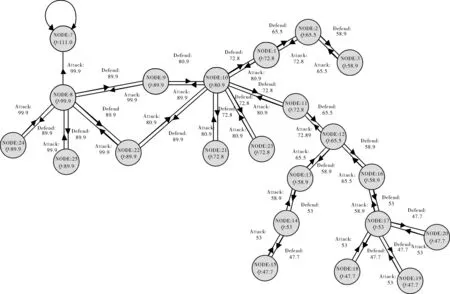
图2 基于Q-learning机制的攻击图
图2中共有22个节点,一个攻击目标节点(节点7),9个初始状态节点共(即初始扫描状态),12个中间状态节点。对于每一个节点都有最后收敛后的值函数的值,以及所对应的状态转换的Q值。由于攻击图中节点和边较多,这里仅给出部分数据(见表2~表3)。

表2 节点属性信息表
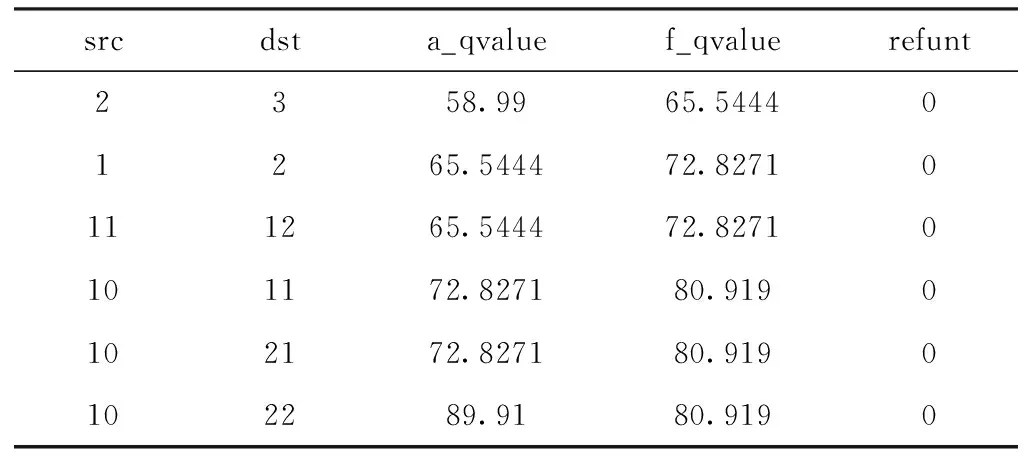
表3 边属性信息表
Q-learning机制中,智能体通过在场景中生成攻击路径与攻击图建立联系。攻击图的生成过程是一个不断迭代更新Q函数的过程,智能体通过学习场景不断地将攻击路径加入到攻击图。Q-learning机制中的一个关键过程是对折扣因子和学习率的选取。实验中,结合攻击路径特征,选取的学习率为0.2。通过对学习率的设置可以实现智能体对网络环境自动探索的过程,防止Q函数积累值Qsum过早收敛。
在攻击图的生成过程中,采用本文算法对该网络环境进行攻击图的生成(设置到吸收态的Q值为99.9,折扣因子取0.9,学习率为0.2),进行了47个攻击场景的学习,共计326次决策训练后数据趋于收敛(收敛过程如图3),Q函数累积值收敛值为1 548.14。

图3 攻击图生成中Q函数积累值的收敛过程
4 结束语
随着网络安全在工业控制网络中的主动防御的重要性的增强[15],攻击图作为一种基础性的安全数据结构,被应用于各种网络安全领域。文中通过Q-learning机制进行了攻击图的生成,实验表明通过基于Q-learning机制可以利用分布式集群对攻击图生成过程进行生成。传统的生成方式一般通过深度逆序的方式对攻击图进行生成,文中通过将智能体模拟攻击者的攻击过程进行攻击路径的生成,并通过Q-learning机制中的Q函数收敛作为攻击图生成结束的标志。此外,文中通过多线程的方式进行了多智能体的攻击路径生成,当运用到分布式集群时仍有许多限制需要进一步突破。
猜你喜欢
今日农业(2022年13期)2022-09-15
自动化学报(2021年8期)2021-09-28
小学生作文(低年级适用)(2019年5期)2019-07-26
爱你(2018年16期)2018-06-21
读友·少年文学(清雅版)(2018年12期)2018-04-04
中国卫生(2016年5期)2016-11-12
儿童时代(2016年6期)2016-09-14
山东青年(2016年3期)2016-02-28
中国卫生(2015年12期)2015-11-10
指挥与控制学报(2015年4期)2015-11-01
