
脉冲星候选样本分类方法综述
2018-11-07 05:37:02王元超郑建华潘之辰李明涛
深空探测学报 2018年3期
王元超,郑建华,潘之辰,李明涛
(1. 中国科学院 国家空间科学中心,北京 100190;2. 中国科学院大学,北京 100049;3. 中国科学院 国家天文台,北京 100012;4. 中国科学院 天文大数据中心,北京 100012;5. 中国科学院FAST重点实验室,北京 100012)
0 引 言
脉冲星是一种有强引力作用、强磁场并快速旋转的中子星,具有稳定的自转周期。脉冲星相关的发现先后两次获得诺贝尔物理学奖(第一颗脉冲星的发现[1]和脉冲星双星系统的首次发现[2])。对脉冲星的观测研究,极大地推动了天文、天体物理、粒子物理、等离子体物理、广义相对论、引力波和导航等众多领域的发展。例如,脉冲星的射电脉冲在经过星际空间到达地球前,会受到星际介质的影响,产生色散等效应,这为星际介质的研究提供了机会[3];作为超新星爆发的产物,脉冲星对于研究超新星爆发理论具有重要价值[4];脉冲双星系统也为广义相对论的检验提供了机会[5];通过分析毫秒脉冲星计时阵列的脉冲到达时间的变化,可以分析引力波信号[6]等。
自第一颗脉冲星被发现后,大量射电望远镜设备被应用到脉冲星搜索中。目前已发现2 700多颗脉冲星,其中大部分是由脉冲星巡天设备发现。例如,Parkes多波束脉冲巡天(Parkes Multi-beam Pulsar Survey,PMPS)[7],高时间分辨率的宇宙脉冲星巡天(High Time Resolution Universe Survey,HTRU)[8],AreciboL波段馈源阵列脉冲星巡天(Pulsar Arecibo L-band Feed Array Survey,PALFA)[9],低频射电(Low Frequency Array,LOFAR)阵列巡天(LOFAR Tied-Array All-sky Survey,LOTAAS)[10],绿岸北半球脉冲星巡天(Greenbank Northern Celestial Cap Survey,GBNCC)[11]等。
随着现代脉冲星搜索设备性能的不断提升,可以接收到更弱的信号,能够探测到更多脉冲星的同时,也产生大量的候选样本,而且大部分样本是射频干扰(Radio Frequency Interferance,RFI)或噪声等。例如,1977年,投入使用的2nd Molonglo survey只接收到约2 500个样本[12],而新一代射电望远镜500 m口径球面射电望远镜(Five Hundred Meter Aperture Spherical Telescope,FAST)[13]预计可以发现5 000颗脉冲星;平方千米阵列(Square Kilometer Array,SKA)[14]预计可以发现2万颗脉冲星。SKA按照保守估计(以HTRU数据的样本比例:脉冲星/非脉冲星为1/10 000[32]为参考计算)需要处理20亿样本。
因而如何有效地从海量数据中筛选出有价值的脉冲星疑似样本,以便进一步观测确认成为需要解决的一个重要问题。本文将阐述脉冲星候选样本分类方法的发展历史、发展现状和技术发展趋势。
1 脉冲星候选样本
目前,脉冲星信号搜索主要借助大型射电望远镜。大部分的脉冲星信号很微弱,且信号在传播中会受到星际介质的影响,因而设备接收到周期性信号后,会借助搜索软件(如PRESTO[15]等)进行一系列的数据处理。例如,通过剪波(clipping)处理,减少脉冲干扰[16];进行消色散(de-dispersion)处理,消除色散延迟[17];再借助傅立叶变换,将数据转换到频域进行分析,从而确定信号周期[18];根据确定的信号周期,将接收到的多个周期的信号进行叠加,放大信号的信噪比,得到平均脉冲轮廓[19]。经过处理后的数据,会转换为图像形式,作为脉冲星候选样本。图1是PRESTO处理后的一个脉冲星候选样本的图像示例(图像来自PMPS[20])。

图1 脉冲星样本图像示例,使用PRESTO软件处理得到Fig. 1 An example figure of a pulsar candidate in PMPS,which was converted by PRESTO
标注的子图(a)~(d)依次为脉冲轮廓曲线图、时间–相位图、频域–相位图和色散曲线图。这些候选样本会被进一步分类筛选,以便选择有价值的脉冲星疑似信号进行观测确认,这个过程被称为脉冲星候选样本的分类。分类的目标是在尽可能不遗漏脉冲星信号的情况下,减少非脉冲星信号的保留(减少进一步观测的工作量)。
天文学家在判断候选样本是否是脉冲星疑似信号时,主要参考以下特征:
1)脉冲轮廓曲线图:通过折叠累加所有频域和时域信号强度得到。由于脉冲星具有稳定的自转周期,理想的脉冲星信号数据在每个周期内会形成一个或多个明显的波峰。
2)时间–相位图:通过累加信号在不同频域的数据得到,反映的是信号在观测时间内的强度。脉冲星信号具有周期性,信号会在整个观测时间内不断重复出现。在时间–相位图上,信号强度越大,颜色越深。从而对理想的脉冲星信号,在整个观测时间内,会形成与脉冲轮廓曲线图波峰位置相对应的竖直线。
3)频域–相位图:通过累计信号在观测时间内的数据得到,反映的是信号在不同频率下的强度。由于脉冲星射电辐射是宽频的,典型的脉冲信号应当出现在观测的大部分频率段上。若为脉冲星信号,对应到频域–相位图上,应当在大部分频率内,有与波峰相对应的竖直线。
4)色散曲线图:脉冲信号在经过星际介质时,会产生色散。色散曲线图反映的是使用不同色散值进行消色散时,脉冲曲线信噪比的变化情况。当使用正确的值消色散时,脉冲信噪比将最大。因而若为脉冲星信号,曲线会在非零位置有一个峰值,曲线呈“钟形”。
在设计算法进行自动分类时,特征的设计一般也是围绕着这几点进行刻画(参见表2、3、5~9)。但对现代设备的候选样本实现脉冲星疑似信号的有效分类,存在以下难点:①候选样本数量大;②脉冲星样本与非脉冲星样本之间、不同类型脉冲星之间的样本不均衡;③干扰信号种类多,部分RFI形似脉冲星信号;④部分脉冲星信号较弱,特征不明显,易遗漏;⑤不同设备、不同区域的RFI环境等不同,使得算法间的可移植性较差。
2 国内外研究进展
关于脉冲星候选样本的有效分类,国内外许多学者进行了大量工作。目前的方法,大致可分为人工识别方法和机器学习方法。其中,人工识别方法可分为基于信噪比信息分类方法、图像软件辅助方法、打分排序方法等;同时,将对应的机器学习方法根据特征类型分为3类:基于经验特征的方法、基于统计特征的方法和基于数据驱动的方法。表1是对这些方法的简单比较。
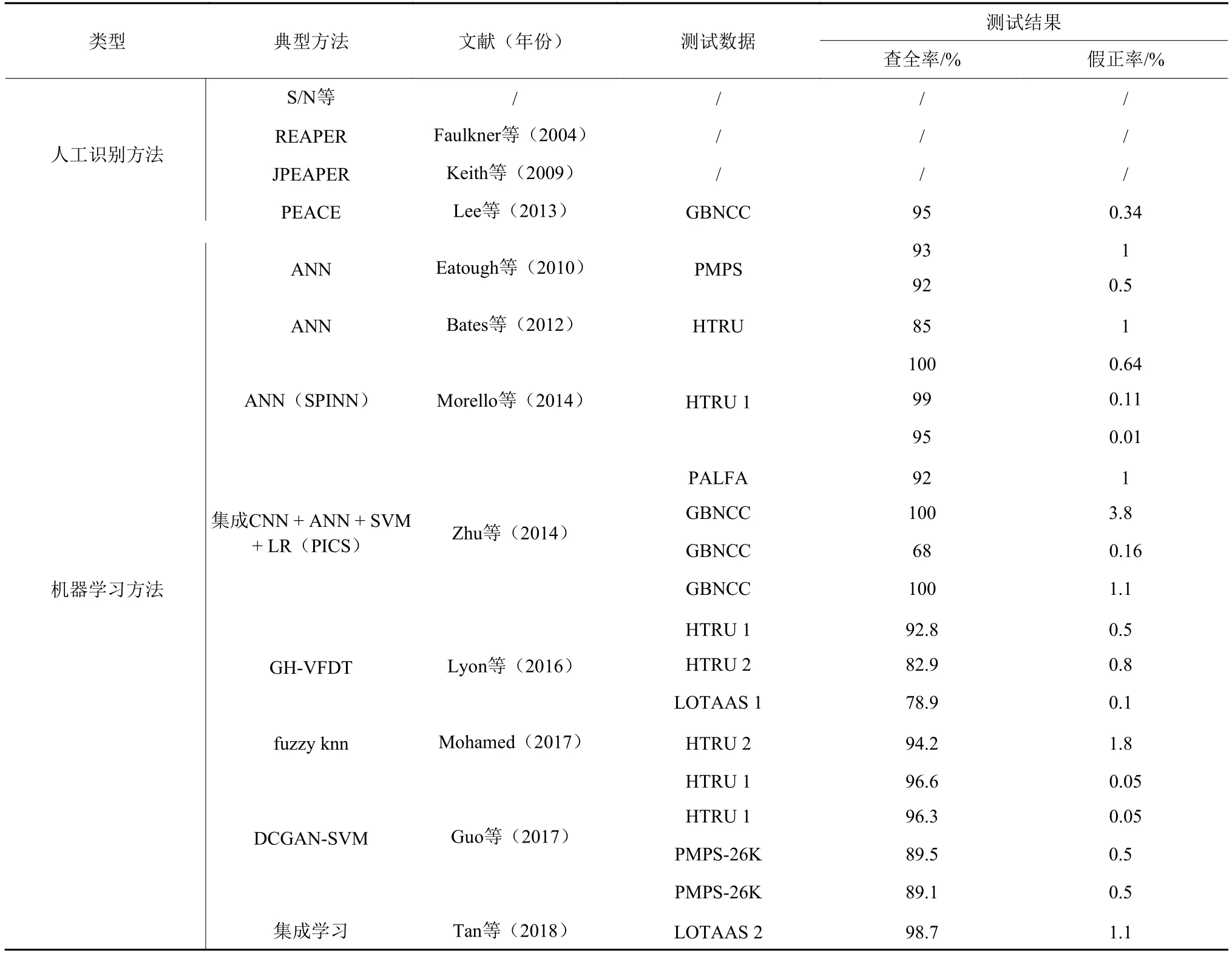
表1 典型脉冲星候选样本分类方法对比Table 1 The comparison of pulsar candidate classification methods
2.1 人工识别方法
脉冲星搜索的前期,由于设备性能等原因,接收到的数据样本有限,研究人员可以借助以往的经验,直接对接收的信号进行人工筛选。
2.1.1 基于信噪比信息分类方法
在早期的识别中信噪比作为重要的判别特征使用。一些简单的筛选软件(例如MSP Find[21])应用到相关的搜索设备上,只接受一定信噪比范围内的信号,辅助减少样本数量。比如,在Arecibo Phase II survey上,Stokes等通过只保留信噪比大于8σ的信号,得到5 000多个候选样本再进行人工进一步识别处理[22]。在Parkes 20 cm survey上,Johnston等使用同样的策略,筛选出约15万个候选样本[23]。人工初步筛选处理速度慢,存在较大的主观性。同时,仅根据信噪比等信息筛选,分类误差较大,会遗漏信号较弱的脉冲星。后续研究人员加入更多信息(比如周期等),在一定程度上提升了准确度,但效果有限。
2.1.2 图像软件辅助方法
利用信噪比、脉冲周期等数据信息进行分类,直观性不强,不利于分析判断,处理速度较慢。因而基于统计特征的图像分类软件被开发用于辅助脉冲星疑似信号的分类操作。例如,2004年,Faulkner等设计了图像分类软件REAPER[24]。它可以根据基本特征(周期、脉冲宽度等),直观地把不同样本展示在二维图像中,将明显的噪声信号与脉冲星疑似信号区分开,减少候选样本的数量。借助REAPER,在对PMPS数据进行再次处理中,新发现了128颗脉冲星。2009年,Keith等对REAPER进行了改进,设计了JREAPER软件[25]。在JPEAPER的帮助下,在PMPS数据中又发现了之前被错分遗漏的28颗脉冲星。
另外,也出现了一些基于网络的图像样本查看评分系统。比如,Pulsar Search Collaboratory[26],通过培训后的高中生,对类似图1所示的样本图像的多个特征进行在线的评分,从而进行样本的分类[27]。该项目开始于2008年,目前已发现了7颗新脉冲星[28]。
基于统计特征的图像分类软件可以有效地筛除一部分明显的干扰信号,减少进一步人工观测的工作量,提升分类速度。但使用基于一定的经验和假设,依赖于研究人员的认知水平与经验模式,手动调整,存在很强的主观性。
2.1.3 打分排序方法
为实现更智能的分类,研究人员尝试对样本进行打分排序。Keith等在JREAPER软件[25]中,设置了经验式的评分标准,对样本进行排序,筛除低分的候选样本(见表2)。2013年,Lee等通过分析大量的脉冲星数据,设计了PEACE系统[29],通过6个特征(见表3)来刻画脉冲星信号,利用函数分别进行评分,并将分数线性组合,根据最终的评分进行排序。在GBNCC数据测试集上,实现了查全率95%时,假正率为0.34%,并从PALFA、GBNCC和HTRU数据集中发现了47颗脉冲星。PEACE提升了分类识别的效率和准确度,但需要人工预先设定评分函数并调节,对人类经验依赖程度很高,只是“半自动化”的分类方法。
随着样本数量的不断增加,人工识别的方法越来越无法满足脉冲星候选样本分类的需求。因而如何在算法中减少主观性,实现自动化,进一步提升准确度和处理速度,成为需解决的一个问题。
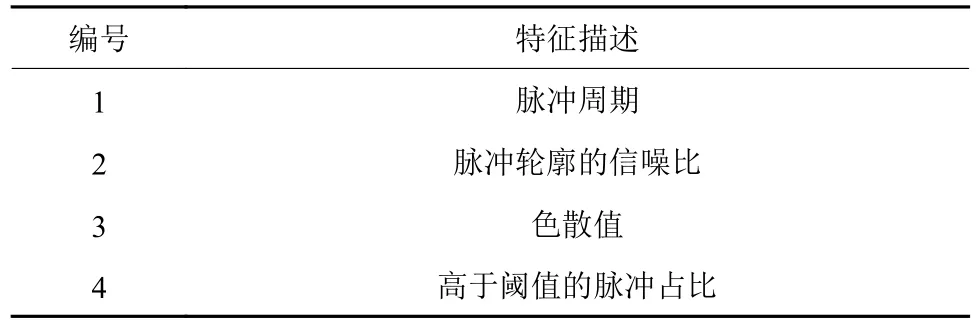
表2 Keith等(2009)使用的特征[28]Table 2 The features used in Keith et al.(2009)[28]

表3 Lee等(2013)使用的特征[29]Table 3 The features used in Lee et al.(2013)[29]
2.2 机器学习方法
为应对数据量不断增大的挑战,随着机器学习的发展,相关的算法也被引入脉冲星候选样本分类任务中。由于样本极度不均衡并且研究人员更关注脉冲星的分类准确度,因而一般使用查全率(Recall)、查准率(Precision)、假正率(False Positive Rate,FPR)来反映算法的性能。其中Recall刻画的是正样本(脉冲星信号)被正确分类的比例;Precision反映的是分类器认定为正类的样本中实际正样本的比例;FPR计算的是负样本(非脉冲星信号)中被分类器错认为正类的比例。Recall越高,脉冲星样本被正确分类的越多;Precision越高或FPR越低,非脉冲星信号被错分的越少。
需要指出的是,由于缺少公共数据集,且大部分算法是针对不同的脉冲星搜索设备的数据进行的设计,因而多数算法是采用各不相同的数据集进行的性能测试。由于样本数量、样本分布、样本比例、样本质量等因素的不同,算法间不能直接定量比较。为方便对照,将部分数据集样本数量信息汇总于表4。
根据分类特征的类型,将目前的关于脉冲星分类的机器学习方法,大致分为:基于经验特征的方法、基于统计特征的方法和基于数据驱动的方法。
2.2.1 基于经验特征的方法
基于经验特征的方法,参照人工分类时的判别方式,引入启发式特征,实现自动评分分类。例如使用信噪比特征、使用sin函数/高斯函数对脉冲曲线进行拟合等。
2010年,Eatough等对启发式评分方法进行了改进,引入机器学习方法,不再进行人工评分[30]。基于射电天文学的专业知识,挑选了信噪比、脉冲宽度等12个特征(见表5)作为三层人工神经网络(Artificial Neural Network,ANN)的输入、输出对应的评分(见表5)。在1.3万个PMPS数据测试集上,实现了93%的查全率,1%的假正率(只使用前8个特征时,查全率为92%,假正率为0.5%)。在对部分PMPS数据进行再处理时,从中发现一颗新的脉冲星。作者对测试数据分析发现:由于毫秒脉冲星与普通脉冲星的不同,以及训练样本的不均衡等原因,使得约50%的脉冲周期小于10 ms的脉冲星被错分;60%的信噪比超过400的脉冲星被错分。
2012年,Bates等[31]将特征增加到22个(表6),借助人工神经网络,在HTRU测试集上实现了85%的查全率、1%的假正率。从部分HTRU Medlat数据中发现了75颗脉冲星。相比于Eatough等[30]的处理结果,在脉冲周期小于10 ms的脉冲星和长周期的脉冲星分类性能上得到了一定的提升,但也增加了模型的复杂度。
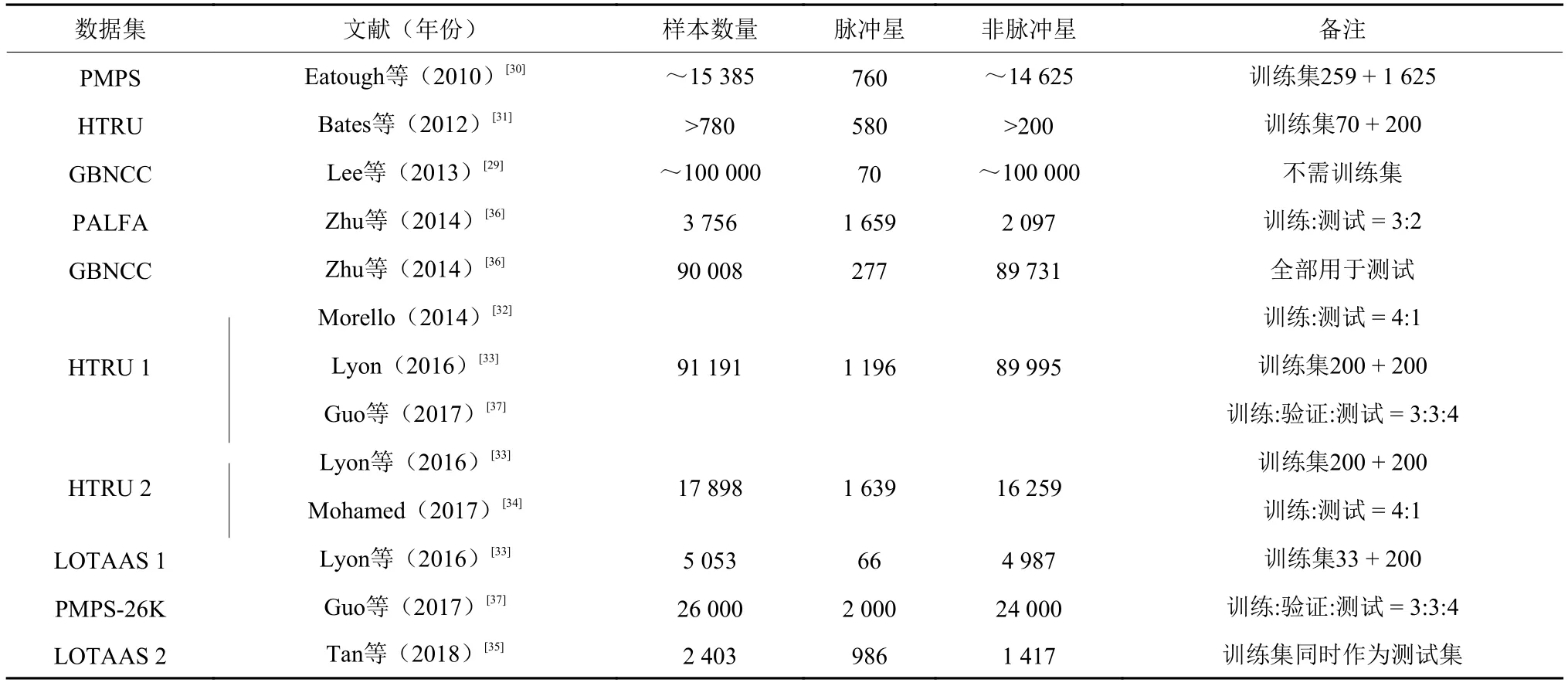
表4 部分数据集样本数量比较Table 4 The comparison of some datasets
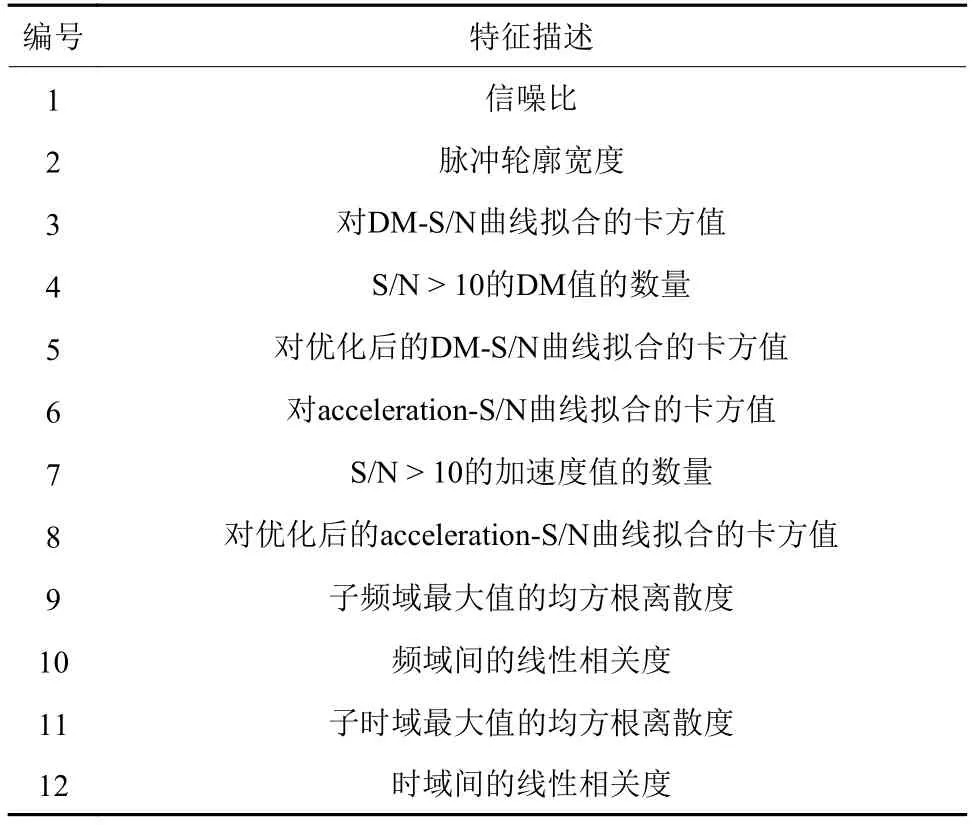
表5 Eatough等(2010)使用的特征[30]Table 5 The features used in Eatough et al.(2010)[30]
2014年,Morello等对人工神经网络方法进行了进一步的优化,设计了SPINN(Straightforward Pulsar Identification using Neutral Networks)分类器[32]。选取了6个特征(表7)作为人工神经网络的输入。在91 192个不均衡样本构成的HTRU Medlat测试集(简称HTRU 1)上,调节阈值参数,可以在达到100%查全率时,假正率为0.64%;99%查全率时,假正率为0.11%;95%查全率时,假正率为0.01%。并对434万个样本再次处理后,筛选出2 400个疑似样本,经过进一步观测确认,发现4颗新的脉冲星。需要指出的是,SPINN“100%查全率时,假正率为0.64%”是根据所有的脉冲星得分中最低分作为分类阈值时,推算得出的。在挑选特征时,考虑了对弱信号的兼顾、对噪声干扰的稳定性以及减少特征间相关度,降低模型的复杂度的同时提升了算法的性能。但对一些形似脉冲星信号的RFI,SPINN并不能很好地分类。因而建议,对RFI的特征进行更好地刻画;同时增加脉冲星数据,降低不均衡度。
基于经验特征的人工神经网络方法的应用极大地提高了脉冲星候选样本分类的准确度和处理速度。对于特征的选取,Eatough等[30]、Bates等[31]、Morello等[32]学者进行了不断的优化。但他们是基于一定的经验和假设,特征对数据集依赖性较强[32],同时,根据人工处理的思路设计的特征有可能使得算法“模仿”人工处理的错误[33]。例如,反复出现的信噪比,会使得算法倾向于信噪比高的“强”信号,而更多的较弱的信号会被忽略。为进一步提高性能,研究人员考虑使用不同的机器学习方法和不同的特征选取策略。

表6 Bates等(2012)使用的特征[31]Table 6 The features used in Bates et al.(2012)[31]

表7 Morell等(2014)使用的特征[32]Table 7 The features used in Morello et al.(2014)[32]
2.2.2 基于统计特征的方法
2016年,Lyon等针对SKA实时处理样本的需求,同时为避免特征对数据集的依赖性和倾向性,设计了新的特征和算法[33]。从脉冲轮廓曲线和DM曲线中提取均值、方差、峰度、偏度共8个无偏向性的统计特征(表8),具有较好的区分度;考虑到实时接收数据时可能存在的数据样本不均衡、不同区域观测可能产生的样本分布漂移等问题,设计了针对不均衡数据流的Gaussian Hellinger快速决策树算法(Gaussian Hellinger Very Fast Decision Tree,GH-VFDT),实现在线处理不均衡的数据。GH-VFDT处理速度快,每秒可以处理7万张样本(单个2.2 GHz,Intel i7-2720QM处理器),但也牺牲了一定的分类准确度。在HTRU1、HTRU2、LOTAAS1数据集上测试时,对应的查全率和假正率依次是:92.8%(0.5%)、82.9%(0.8%)、78.9%(0.1%)。
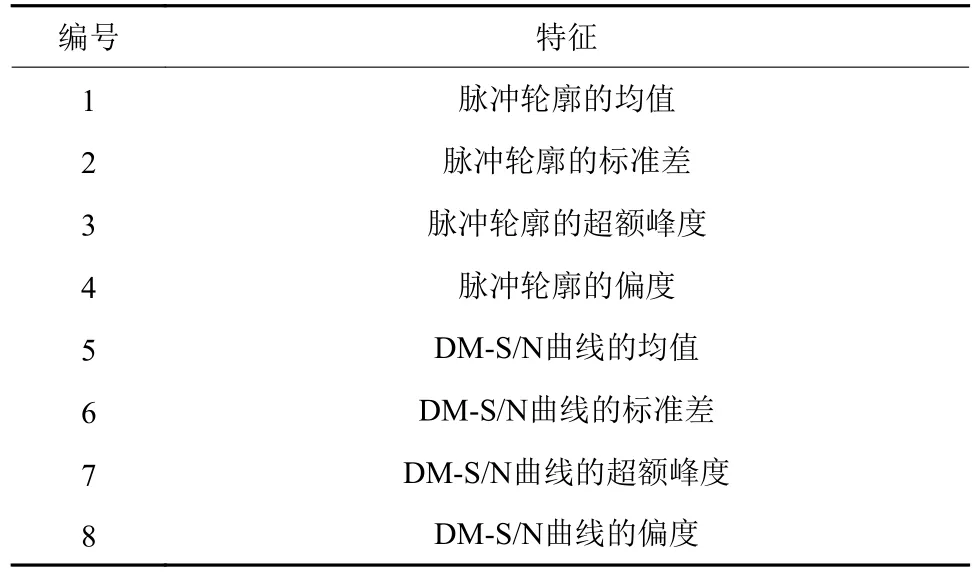
表8 Lyon等(2016)使用的特征[33]Table 8 The features used in Lyon et al.(2016)[33]
另外,Lyon等新设计的8个特征具有较好的区分性,被之后一些研究人员所借鉴使用。2017年,Mohamed将这些特征(表8)应用到模糊k近邻分类器(Fuzzy K Nearest Neighbors,Fuzzy KNN)算法上[34],在HTRU2数据集上测试提升了一定的查全率,实现了94.2%的查全率、1.8%的假正率,进一步证明了统计特征的有效性。
针对Lyon等[33]使用的特征缺少时间–相位图和频域–相位图信息,并在实际分类处理中对宽脉冲脉冲星容易错分的情况,2018年,Tan等[35]进行了改进,通过计算时间–相位图或频域–相位图与脉冲轮廓曲线的相关系数,增加了对应的8个统计特征(表9)。同时将形似脉冲星信号的RFI单独分类,由2分类(脉冲星、非脉冲星)变为3分类(脉冲星、噪声、RFI)。通过利用不同波束探测到的脉冲星信号数据,构造多个决策树,集成提升性能。算法可以较好地识别宽脉冲的脉冲星,在新的LOTAAS数据测试集(为与之前的数据集区别,代称LOTAAS 2)上,相比较于Lyon等[34]算法的结果,查全率提升2.5%,为98.7%;假正率FPR则从2.5%降到了1.1%。该算法被应用于LOTAAS搜索系统中。需要指出的是,由于样本数量有限,在作者的测试实验中测试集包含训练集,因而实际性能可能会稍低一些。

表9 Tan等(2018)新添加的特征[35]Table 9 The features added in Tan et al.(2018)[35]
2.2.3 基于数据驱动特征的方法
卷积神经网络可以实现自动提取特征,避免人工设计特征的缺陷,因而基于卷积神经网络的数据驱动的机器学习方法在脉冲星疑似样本的分类领域具有重要价值。
2014年,Zhu等从图像模式识别的角度分析,设计了PICS(Pulsar Image-based Classification System)系统[36]。PICS将支持向量机(Support Vector Machines,SVM)、ANN、卷积神经网络(Convolutional Neural Networks,CNN)、逻辑回归(Logistic Regression,LR)等集成结合。直接使用PRESTO软件输出的4幅子图(图1已标出)作为SVM、ANN或CNN的输入,并将多个分类器的输出使用LR进行整合,最终输出对应的评分。PICS完全由数据驱动,避免了人工设计特征可能存在的不足(倾向性、数据集的依赖性等),在PALFA数据集上,实现92%的查全率、1%的假正率。并且基于PALFA数据训练的模型,直接在90 008个样本的GBNCC数据上测试,可达到100%的查全率、3.8%的假正率。PICS系统提升了识别的准确度,并具有一定的泛化性能,但模型也相对更复杂。
2017年,Guo等提供了一个新的思路,利用深度卷积对抗生成网络(Deep Convolution Generative Adversarial Network,DCGAN)来进行特征的提取[37]。DCGAN是一种生成模型,将时间–相位图或频率–相位图分别作为输入,利用DCGAN来生成更多的样本;同时DCGAN自动学习对应的特征,作为SVM分类器的输入。该算法在解决样本不均衡问题时,也避免了人工特征的设计提取。在HTRU1 数据集上,使用时间–相位图作为输入时,查全率为96.6%、精度为96.1%,假正率约为0.05%;
使用频率–相位图作为输入时,查全率为96.3%、精度为96.5%、假正率约为0.05%。在PMPS-26K数据集上,使用时间–相位图作为输入效果更好,查全率为89.5%、精度为88.5%、假正率约0.5%。但是DCGAN模型复杂且训练不稳定;仅考虑了二维子图,会缺失部分特征信息,影响算法性能,对复杂情况的分类效果有待进一步提升。表10中对这3类机器学习算法进行了简单的优缺点总结。

表10 3类机器学习算法的优缺点总结Table 10 The advantages and disadvantages of three kinds of machine learning methods
为实现更好的机器学习算法的效果,针对样本不均衡问题,许多学者做了一些有益的尝试。Morello等[32]在对人工神经网络方法进行优化时,使用过采样方法,使得训练集正负样本比例为4:1。Lyon等测试了Hoeffding树分类器处理不平衡数据流的效果[38],并进一步设计了针对不均衡数据流的GH-VFDT算法[39]。2016年,Yao等在目标函数中设置不同的权重,通过集成支持向量机算法提升分类效果[40]。2017年,Ford利用Lyon等提出的特征[33],分别测试了支持向量机、神经网络、决策树、Bagging集成等算法,在上采样、下采样、ROSE采样、SMOTE采样下的性能,实验表明性能均有提升[41]。2017年,Guo等[37]使用DCGAN来进行特征提取的时候,同时生成高质量的新数据,从而缓解样本不均衡对算法的影响。
3 未来的发展趋势
1)在分类器算法设计方面,传统的机器学习算法目前依然占据主流;在特征设计提取上,已经由传统的手工设计特征发展到自动抽取特征。深度学习在特征提取学习方面具有优势,PICS和DCGAN-SVM已经做出了深度学习在脉冲星样本分类上的有益尝试。深度学习、对抗生成网络等技术将会发挥更大的作用。
2)目前,数据多为二分类(脉冲星、非脉冲星),或简单的三分类(脉冲星、RFI、噪声)。而Tan等[35]也提到,不同类型的脉冲星之间、不同类型的RFI之间也会有很多的差异。因而在数据量允许的情况下,结合数据分布的特点,进行更合适的、更细致的样本分类,可以使得特征提取更加有效,进一步提升分类算法的性能。
3)大部分机器学习算法都是作为线下处理使用,针对在线数据处理的较少。Lyon[42]提到,随着设备性能的不断提升,数据量将会持续增加,需要设计更好的数据管理工具、文件格式、数据标准,同时需要更好地实时在线自动处理数据。因而针对数据流设计在线不均衡数据的处理算法,具有重要的价值。
4)目前的算法均为根据已知的脉冲星特征来构建有监督学习,对数据集有很强的依赖性。如果出现未知的新现象、新样本,将会被当成干扰而筛除。因而考虑半监督学习或无监督学习,对离群点进行深入分析,有助于充分利用数据。
5)不同设备间数据分布等存在差异,使得需要分别设计或调整算法。因而提升算法的泛化能力,使之适应不同数据,具有重要的意义。
4 结束语
本文从脉冲星识别的意义、历史发展及现状、未来趋势等角度阐述了脉冲星疑似信号分类识别的问题。基于机器学习算法设计有效的分类器将有助于脉冲星候选样本的准确识别分类,促进脉冲星天文学的发展。
猜你喜欢
中学生数理化·八年级物理人教版(2023年11期)2023-12-26 07:50:10
军事文摘(2023年12期)2023-06-12 07:51:00
科学(2022年4期)2022-10-25 02:43:42
数学物理学报(2022年3期)2022-05-25 13:33:28
现代电子技术(2018年20期)2018-10-24 04:39:04
中成药(2017年12期)2018-01-19 02:06:54
现代情报(2018年11期)2018-01-07 09:41:14
北京航空航天大学学报(2016年6期)2016-11-16 01:50:43
计算机光盘软件与应用(2013年6期)2013-08-08 08:26:50
测绘科学与工程(2013年3期)2013-03-11 15:07:35
