
基于旅客出行意图的航线潜在价值计算模型
2018-10-29 05:05徐召朋
交通运输系统工程与信息 2018年5期
徐 涛,徐召朋,卢 敏
(1.中国民航大学a.信息技术科研基地,b.计算机科学与技术学院,天津300300;2.中山大学机器智能与先进计算教育部重点实验室,广州510275)
0 引 言
面对日益激烈的市场竞争,航空公司通过开辟新航线或加大热门航线的运力争相发展和扩大航线网络以提升市场竞争力.开辟新航线或加大热门航线的运力首要解决航线价值或航线收益的计算问题.现阶段,航线价值通常是以航线客流量的统计为基础,并结合票价信息来计算.但是,仅利用航线的客流量和票价信息难以评估旅客带给航线的潜在价值.发现具有高潜在价值的航线能够帮助航空公司解决后期因客源不足引起的营运效益降低问题.因此,航线价值计算问题的解决,对航空公司的发展具有重要的意义.
为了能够发现具有高潜在价值的航线,本文提出了一种基于旅客出行意图的航线潜在价值计算模型来计算航线的潜在价值.提出了航线潜在价值的概念,将难以直观描述的旅客出行行为及旅客偏好融入到航线价值计算中,达到航线潜在价值计算的目的;提出出行意图的概念,将旅客的出行行为按照出行意图进行划分并量化,在计算航线潜在价值的同时将航线按照出行意图进行了分类.
1 基于旅客出行意图的航线潜在价值计算模型
本文主要通过中国民航旅客订票数据集来研究航线的价值,而该数据集中并不包含有关航线价值的信息.但可以通过统计航线上的客流量来定义航线的价值,将其定义为

在基于旅客出行意图的航线潜在价值计算模型中引入出行意图的概念,将旅客的出行行为进行细分.出行意图由主题模型[1-4]中文本主题的概念引申而来.文本主题表示一种隐含的概念,具体表示为一系列相关的单词,以及它们在该概念下出现的概率.因此,出行意图可以表示为一系列相关的航线,以及航线出现在该出行意图下的概率.
借鉴主题模型中文本的生成过程来模拟旅客出行记录的生成.旅客出行时先确定出行意图,然后在该意图下选择航线.因此,在获得旅客隐含的出行意图分布及每个意图中航线的分布后,结合旅客对舱位的偏好来计算出的航线价值便是航线的潜在价值.
记U为旅客组成的集合,U中所有旅客出行时乘坐的航线组成航线集合R.借助贝叶斯公式将基于旅客出行意图的航线潜在价值计算模型定义为
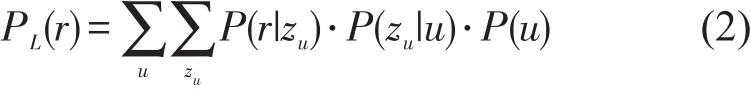
式中:P(r)表示航线r的价值,r∈R;P(u)表示旅客u对舱位偏好所产生的价值,u∈U;P(zu|u)表示旅客u拥有出行意图zu的概率;P(r|zu)表示确定出行意图zu后选择航线r的概率.
1.1 旅客出行意图分布及出行意图下航线分布的定义及求解
(1)旅客出行意图分布及出行意图下航线分布的定义.
记每位旅客u包含自身出行意图的向量为θu,θu中的元素是旅客u选择不同意图的概率值,则所有旅客的出行意图构成“旅客—意图”矩阵Θ.此外,假设共有K种出行意图,每种出行意图z由不同航线在该出行意图中出现的概率组成,记为向量φz,针对所有出行意图形成“意图—航线”矩阵Φ.为方便起见,将每条航线r进行编号.旅客u在出行中选择航线r的概率可表述为

式中:z表示某次出行旅客的意图.
由于旅客u选择航线r的过程中加入了旅客出行意图的潜在信息,因此,式(3)表示旅客u在出行中选择航线r的概率值也代表着该旅客u所赋予航线r的价值.最终,我们可以将旅客出行记录的生成用图1所示的流程来表示.其中α与β都表示Dirichlet分布的参数先验参数.
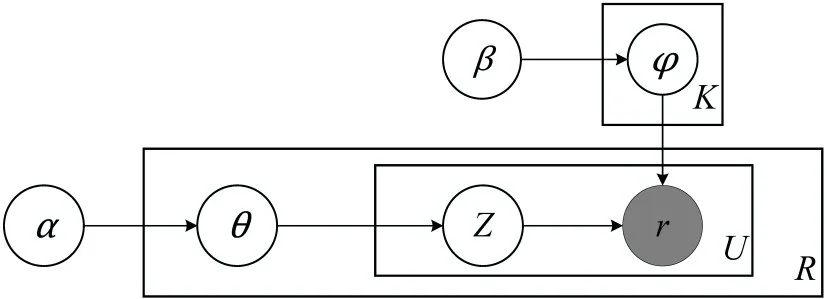
图1 旅客出行记录生成图Fig.1 The generation chart of passenger travel records
(2)旅客出行意图分布及出行意图下航线分布的求解.
由于向量θ是旅客选择出行意图的分布,假设共有K种出行意图,则θ符合K维多项式分布.同理,向量φ符合|R|维多项式分布.由统计学知识可知,θ和φ会具有先验分布,此处选择Dirichlet分布作为θ和φ的先验分布形成共轭结构以提高参数估计的精度[7],并简化估计的过程.
所有旅客的出行意图分布P(z|U)加入先验分布可表示为

同理,各出行意图下航线的分布P(r|z)可表示为
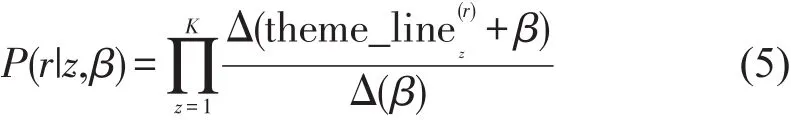
综合式(4)和式(5),可得所有旅客出行意图及出行时所乘航线的联合分布为
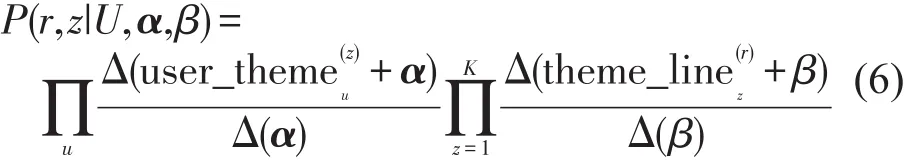
利用Gibbs Sampling方法对式(6)进行采样.由于航线r是观测到的已知数据,出行意图是隐含变量,所以真正需要采样的分布是P(z|r).其公式推导为
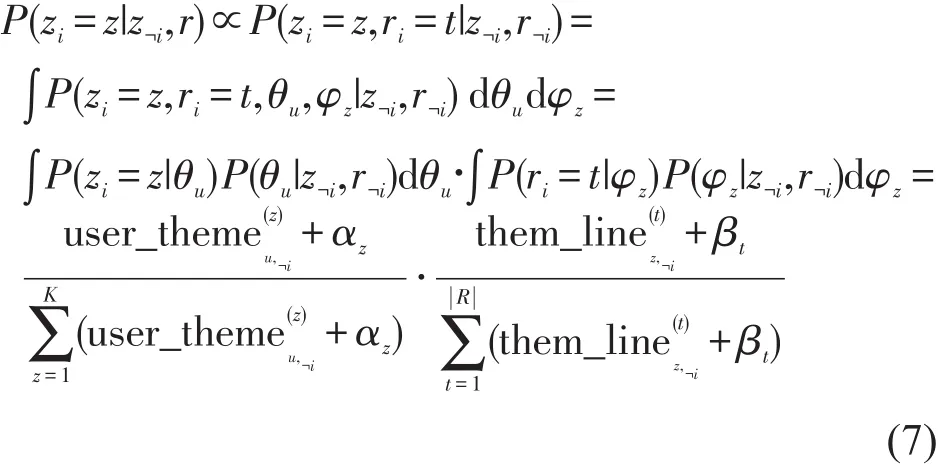
式中:zi表示第i条航线对应的出行意图变量;下标¬i表示变量不包含第i条航线的情况.
式(7)最后一步的推导应用了Dirichlet分布的期望公式,因此,只要获得每条航线r的意图z的标号,便可通过简单的计数方式获得“旅客—意图”矩阵Θ和“意图—航线”矩阵Φ.主要过程是遍历旅客出行时的航线集合,按照式(9)进行不断的迭代,从而更改不同航线分配到不同的出行意图下的概率.

式中:θuz表示旅客u选择出行意图z产生的价值;φzr表示出行意图z下确定航线r产生的价值.
1.2 旅客舱位偏好的计算
旅客对舱位偏好所产生的价值由其历次出行累积得来.设旅客的每次出行及旅客间的出行相互独立,且对不同的舱位赋予不同的舱位系数,则所有旅客组成的集合U因舱位偏好所具有的价值为
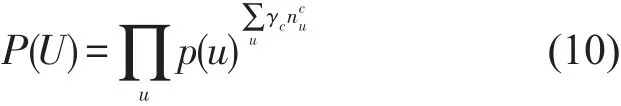
对式(10)使用最大似然估计法,可得
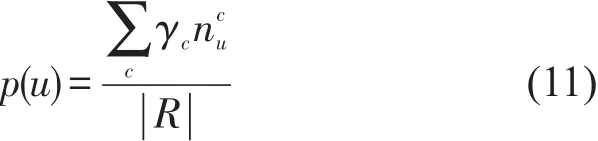
通常,航空公司通过里程累积计划吸引和奖励旅客,在里程累积计划中,旅客出行时不同的舱位选择会被赋予不同的里程累积系数,不同舱位的里程累积系数事实上反映了不同舱位在航空公司收益中的重要性,因此,式(11)中舱位系数γc的选择用航空公司对不同舱位的里程累积系数替代.式(11)中得到旅客u出行时的概率可用来评估旅客因其对舱位偏好所产生的价值.
截止调查前,安徽省普通高等学校大学生总人数约为万.为了保证问卷的可靠性,取问卷调查置信水平为95%(相应的),误差值,概率值,此时样本方差最大.计算得到.考虑到信息覆盖度不足,假设问卷有效回收率为,因此,此时的样本量为.最终发放600份问卷,实际回收有效样本509份,回收率,其中,订购过外卖的样本有480份.
最终可得基于旅客出行意图的航线潜在价值计算模型为

2 实验与分析
2.1 实验数据及预处理
实验数据集选取中国民航旅客订座系统中2010年1月1日~2011年12月31日2年的旅客订票数据,其数据量是48.9 G.包含订票记录数102 305 312条,旅客96 298 451人,航线1 634条.数据内容包含身份证号,性别,所选航空公司,航班号,舱位,起飞机场,到达机场等17个属性.
旅客的偏好需要通过出行次数的累积来体现.旅客出行次数偏少,则其对舱位的偏好模糊,出行意图也会过于单一,不仅不会提高计算的准确性,还会导致出行意图中航线分布不均匀.为更好地获得旅客偏好及出行意图,选择年出行次数5次及以上的旅客作为基准实验数据,筛选后的数据如表1所示.
实验中,对缺失舱位信息的旅客订票数据以经济舱信息补全.航线信息则利用订票数据中“起飞机场”“到达机场”两个属性来唯一标识,这两个属性在旅客订票数据中都由国际航空运输协会(International Air Transport Association,IATA)规定的机场“三字码”来表示,于是,将旅客订票数据所表示的出行记录预处理为如图1所示的短文本格式作为基于旅客偏好的航线潜在价值计算模型的输入.该文本数据以行为单位,每行代表1名旅客的出行记录.各行的第1列表示加密后的旅客身份证信息,具有唯一性,其余各列由旅客出行时选择的起飞机场和到达机场的两个“三字码”拼接而成的航线组成.

表1 年出行次数5次及以上的数据集Table 15 times and above data sets for annual trips
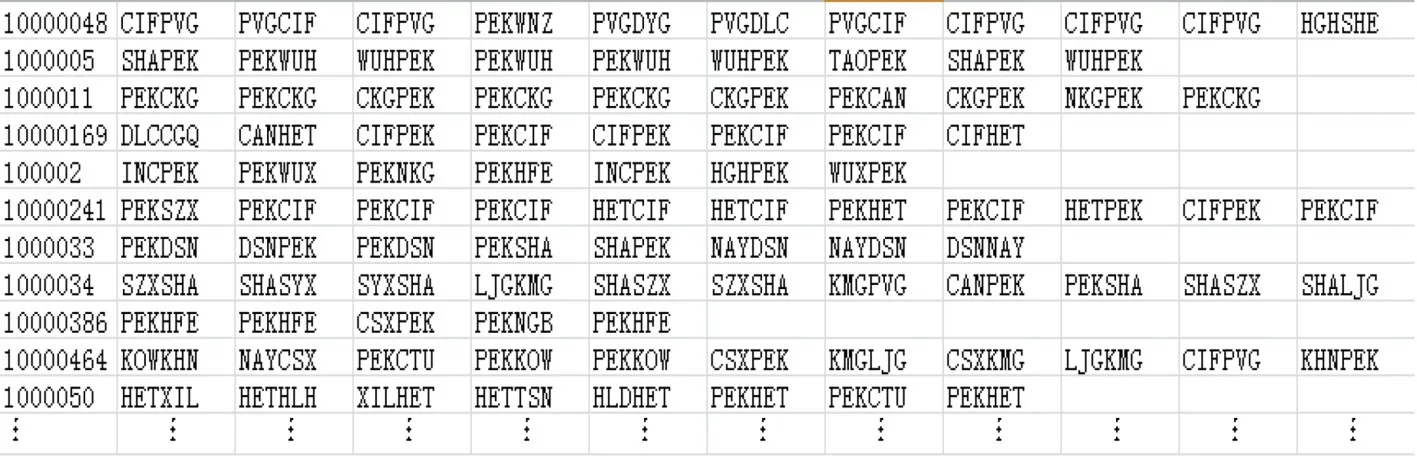
图2 基于旅客偏好的航线潜在价值计算模型的输入样例Fig.2 Input sample of route potential value calculation model based on passenger preference
由于旅客订票数据量庞大,使用传统数据库进行操作经常会出现内存溢出的情况,且航线价值的计算也涉及大矩阵运算.为加快对旅客订票数据的处理采用Hadoop并行平台中的MapReduce技术[5-7]及Fast LDA[8]技术进行数据的预处理及大矩阵的运算.
2.2 模型的评估方法
虽然航线潜在价值的计算属于回归预测的范畴,但由于对航线价值定义并没有一种统一的标准,所以不能单纯的用均方误差来评估模型的性能.因此,通过衡量航线价值排名的相似性来验证基于旅客出行意图的航线价值计算方法的有效性.而肯德尔相关系数(Kendall Rank Correlation Coefficient,KRCC)[9-10]与斯皮尔曼相关系数(Spermans Rank Correlation Coefficient,SRCC)[11-12]常用于评价两个有序序列的相似性,所以将这两个系数作为模型的评价指标.实验的具体过程如下:
(1)利用2010年与2011年的数据分别计算出不同出行意图数目下的PL2010(r)与PL2011(r)并对其降序排列.
(2)利用2010年与2011年的数据分别计算出P2010(r)与P2011(r)并对其降序排列.
(3)计算步骤(1)与步骤(2)中各自前N项(Top-N)的肯德尔相关系数与斯皮尔曼相关系数.
2.3 实验结果分析
模型中设置出行意图的先验分布参数α值为50/K,出行意图中航线先验分布参数β值为0.01,出行意图的数目分别设置为10,30,50和100.
航线潜在价值的计算引入了出行意图的概念,即假设旅客出行时会先确定出行意图,并在确定出行意图后选择航线.因此,在某种层面来讲也假设了不同航线会属于不同的出行意图.图2给出了某些出行意图下排名前10的航线序列(以2010年数据所得).
图2由“意图—航线”矩阵Φ转置并滤除掉概率值后生成,并已按概率值的大小进行了排序.以列为单位,每列表示某种出行意图下包含的航线.从聚类角度来看,如果不考虑各航线出现在意图中的概率,基于旅客偏好的航线潜在价值计算模型中用Gibbs Sampling方法获得的“意图—航线”矩阵Φ将航线按照出行意图进行了聚类.
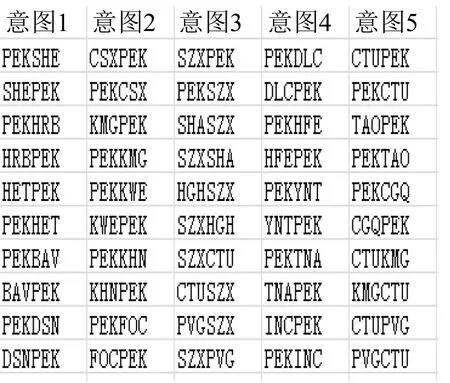
图3 某些出行意图下前10的航线Fig.3 The first ten air-routes of some travel intentions
表2给出了P2010(r)与P2011(r)在不同Top-N中的相关系数τ与rs.表3则给出了不同出行意图数目下PL2010(r)与PL2011(r)在不同Top-N中的相关系数τ与rs.

表2 P2010(r)与P2011(r)在不同Top-N中的相关系数τ与rsTable 2 Correlation coefficientτandrsofP2010(r)andP2011(r)in different Top-N
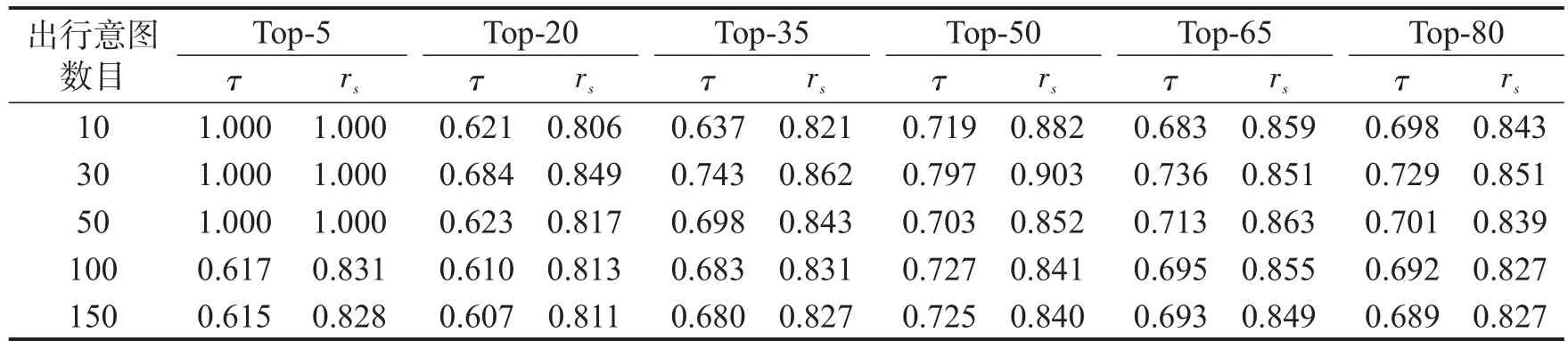
表3 不同出行意图数目PL2010(r)与PL2011(r)在不同Top-N中相关系数τ与rsTable 3 The correlation coefficients of different travel intention numbersPL2010(r)andPL2011(r)in differentTop-Nareτandrs
从表2与表3的对比中可以看出,当出行意图数目一定时,基于旅客偏好的航线潜在价值计算模型得到的PL2010(r)与PL2011(r)的相关系数τ和rs大多高于P2010(r)与P2011(r)之间的相关系数.其原因在于计算P(r)时仅仅考虑旅客的出行次数,而基于旅客偏好的航线潜在价值计算模型将旅客对舱位的偏好及旅客的出行行为进行了量化,并融入到航线的价值计算中,不仅考虑了出行次数,还考虑了每名旅客的出行特征.所以基于旅客偏好的航线潜在价值计算模型具有比基准方法更好的性能.
从表3中可见,当出行意图数目分别选取10,30,50时,PL2010(r)与PL2011(r)在Top-5中的相关系数τ及rs均为1.000,即基于旅客出行意图的航线潜在价值计算方法在选取出行意图数目分别为10,30,50时对排名前5的航线价值的挖掘准确率达到100%.其原因是基于旅客偏好的航线潜在价值计算模型将航线按照旅客的出行意图进行了分类,而同一航线可能被赋予不同的出行意图,在计算中被多次带入公式运算,使得拥有多种出行意图的航线具有较高的价值,从而验证了该模型在挖掘高价值航线方面具有很大的优势.此外,当Top-N中N≥35时,相关系数τ和rs分别在0.700与0.850上下波动,这是因为N值的变动,会使2010年与2011年2年的航线价值序列中排序不一致的对数所占的比例有所变化,但会稳定在一定范围内,说明了本文方法性能的稳定性.
从表3中还可见,当Top-N一定时,PL2010(r)与PL2011(r)的相关系数τ和rs在出行意图数目为30时均取值最大,之后随着出行意图数目的增加会随之下降,并趋于平稳.这是因为当出行意图数目过大时,旅客对某些出行意图的选择会变成小概率事件,在该意图下选择航线时会出现概率趋近于0的情况,从而弱化了旅客能够赋予航线的价值,从而表明旅客出行意图数目的确定并不是越大越好.
3 结论
针对民航航线网络中航线价值计算问题提出了基于旅客出行偏好的航线潜在价值计算模型.该模型引入出行意图的概念,将旅客的出行行为划分为出行意图的确定及意图下航线的确定两个阶段,并结合旅客对舱位的偏好,从而达到计算航线潜在价值的目的.此外,出行意图的引入,在计算航线潜在价值的同时,还可以将航线按照出行意图进行聚类.
然而,基于旅客偏好的航线潜在价值计算模型在考虑旅客出行时,将其看作是相互独立的,未考虑不同出行之间的相互联系和依赖关系.然而旅客的实际出行中存在如购买往返机票或因无直达航线而需要转机等多种相互关联或依赖情形,这些情形中航线的关联及依赖关系对旅客意图的分布和意图下航线的分布都会产生影响,从而影响到航线潜在价值的计算.今后的工作将会考虑对旅客出行时所选航线的关联及依赖关系进行建模来计算航线的潜在价值,使航线潜在价值的计算更符合旅客的出行行为.
猜你喜欢
法律方法(2022年2期)2022-10-20
福建基础教育研究(2022年4期)2022-05-16
法律方法(2021年3期)2021-03-16
现代计算机(2019年15期)2019-07-15
物流科技(2018年10期)2018-10-17
商界(2017年3期)2017-03-14
铁道学报(2016年2期)2016-05-07
延河(下半月)(2014年3期)2014-02-28
青年文摘·上半月(1996年4期)1996-12-31
