
傅里叶变换红外光谱鉴别芝麻酱中掺杂花生酱
2018-10-22 12:06周密宋哲龚蕾付文雯罗彤文红
中国调味品 2018年10期
周密,宋哲,龚蕾,付文雯,罗彤,文红*
(1.湖北省食品质量安全监督检验研究院,武汉 430075;2.湖北省食品质量安全检测工程技术研究中心,武汉 430075)
芝麻酱(sesame paste),又称麻酱,由芝麻籽烘炒碾磨制成,作为一种佐餐辅料,其口感细腻,营养丰富,深受消费者喜爱。现市场上大多数芝麻酱生产企业技术水平较低[1],导致芝麻酱产品良莠不齐,部分不法商贩为了降低成本,向芝麻酱中掺杂劣质花生原料,损害消费者利益的同时,劣质花生原料中的生物毒素对食用者的身体健康也构成了极大威胁[2]。目前,常用感官分析如产品的分层情况、颜色识别、气味及口感等来判断芝麻酱中是否添加其他成分,但主观性强且辨别难度大,给芝麻酱的质量安全问题带来一定的隐患。
有研究表明,通过分析芝麻酱的特征风味物质、荧光定量PCR等方法可对芝麻酱品质进行识别及鉴伪研究[3],但上述检测方法对人员要求高,样品分析时间较长,因此,亟需寻找一种快速便捷的分析方法规范市场秩序。
本研究通过傅里叶变换红外光谱仪收集纯芝麻酱的光谱信息,有效地建立了FTIR鉴别纯芝麻酱中掺杂花生酱的判别模型,为纯芝麻酱的质量控制提供了有益思路。
1 材料与方法
1.1 样品的收集及制备
根据湖北省内调味品企业生产状况,共收集纯芝麻酱样品30例;掺杂芝麻酱样品则是将纯花生酱(生产企业提供)按10%,20%,30%,40%,50%,60%,70%(质量比例)添加至9例不同的纯芝麻酱中,共计63例。所有样品放置于2~6 ℃避光保存,测试前混匀并恢复至室温,待测。
1.2 光谱信息的采集及样品划分
采用傅里叶变换红外光谱仪(北京西派特科技有限公司)测定纯芝麻酱样品及掺杂花生酱样品的光谱信息,仪器配备DTGS检测器,样品扫描前以空气作为背景,光谱信息采集范围为4000~650 cm-1,分辨率为4 cm-1,扫描次数为32次,最后取3次光谱的平均值作为该样品的光谱信息。
将纯芝麻酱样品及掺杂样品随机分为训练集(纯芝麻酱样品20例,掺杂样品42例)和验证集(纯芝麻酱样品10例,掺杂样品21例),将训练集建立定性判别模型,验证集作为未知样品检验模型,样品信息见表1。
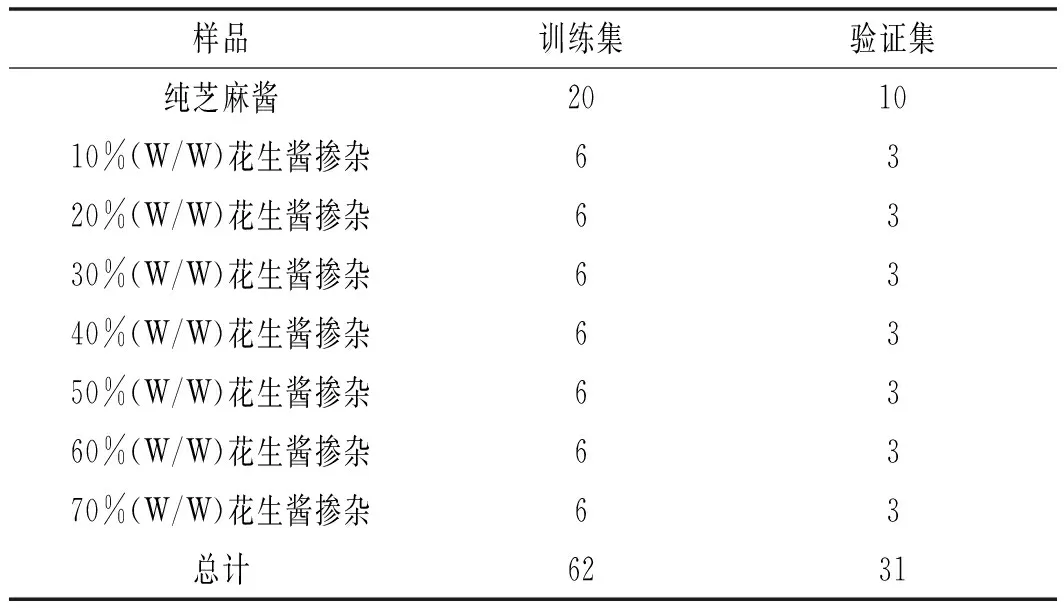
表1 训练集和验证集样品Table 1 Samples of train set and validation set
1.3 光谱信息预处理
光谱信息采集过程中,除含有目标物自身的化学信息外,还包含随机噪声[4]。利用傅里叶变换红外光谱结合化学计量学建立识别模型时,常对光谱信息进行适当的处理或变换以达到降低噪声的目的,从而提高模型的判别正确率。光谱预处理方法主要有标准化(auto scaling)、多元散射校正(multiplicative scatter correction,MSC)、标准正态变量变换(standard normal variate transformation,SNV)、Savitzky-Golay卷积平滑法(S-G smoothing)等。
本研究通过多元数据分析软件(The Unscrambler X 10.4,CAMO)对原始光谱进行预处理,比较上述方法处理后的模型判别结果,优化光谱预处理条件。经过分析比较,发现使用SNV对光谱进行预处理后的建模判别效果最佳。
1.4 判别模型的建立
对纯芝麻酱及掺杂样品进行线性判别分析(liner discriminant analysis,LDA)和支持向量机(support vector machine,SVM)判别分析,比较2种模型定性分析的综合判别正确率。其中,LDA按照类内方差尽量小、类间方差尽量大的准则求得判别函数,然后利用建立的判别函数对待测样本进行分类[5];SVM是专门针对小样本建立的统计学习方法,能够较好地解决小样本、非线性、高维数等问题[6]。
2 结果与讨论
2.1 样品的红外光谱图
采用1.2所述方法分别采集纯芝麻酱和纯花生酱的傅里叶红外光谱图,见图1。
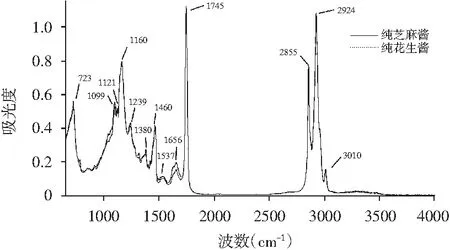
图1 纯芝麻酱与纯花生酱的红外光谱图Fig.1 FTIR spectra of pure sesame paste and pure peanut butter

向纯芝麻酱中不同比例地添加纯花生酱,制得掺杂样品,同样按照1.2所述方法收集样品的傅里叶红外光谱图。
由图2可知,随着花生酱掺杂比例的增加,样品图谱也产生规律性变化,在指纹区1000~1100 cm-1范围内(糖类C—OH的伸缩振动、酯键中C—O的伸缩振动)及官能团区1500~1700 cm-1范围内(酰胺Ⅰ带、酰胺Ⅱ带)样品的吸光度逐渐降低,可能是由于随着花生酱的逐量添加,掺杂样品中主要营养成分如脂肪、蛋白质及糖类等物质的变化引起光谱吸光度的变化。
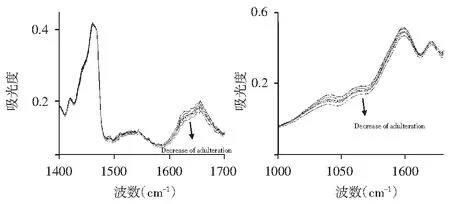
图2 纯芝麻酱中不同质量比掺杂花生酱的红外光谱图Fig.2 FTIR spectra of pure sesame paste with different weight ratios of peanut butter
2.2 线性判别分析与支持向量机判别模型结果
通过SNV对原始光谱进行降噪处理后,建立SVM、LDA的定性分析模型判别,结果见表2。

表2 SNV预处理下SVM、LDA模型的判别结果Table 2 Discrimination results of SVM and LDA based on SNV
其中SVM类型为Nu-SVC,核函数类型Linear,Nu值设置为0.5;LDA主成分个数为5。由表2可知,利用SVM所建立的定性判别模型效果优于LDA模型,综合判别正确率较LDA高9.67%。本研究中,由于纯芝麻酱的样品量相对较少,且各生产厂家之间由于原料来源、生产工艺不同等因素,LDA在模型建立过程中类内差异过大对模型的判别函数造成一定影响,从而模型判别正确率较低,相比而言,SVM能够较好解决小样品、非线性等问题。
2.3 模型输入变量的选择
通常情况下,光谱中除噪声外还含有大量无用信息,在建模时可对光谱数据进行筛选,提高分析效率。30份纯芝麻酱光谱信息见图3。
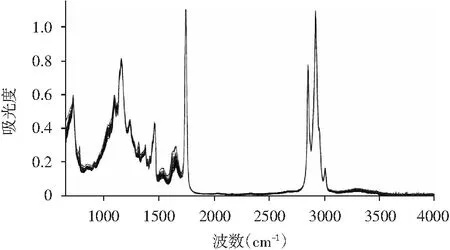
图3 30例纯芝麻酱光谱图Fig.3 FTIR spectra of 30 pure sesame pastes
其中3071~2792 cm-1,1786~667cm-1范围内含有丰富的光谱信息,吸光度值较高;其他范围内光谱吸光度值接近于零。选择吸光度值较高范围内的光谱信息作为有效波长,各有效波长的吸光度值作为输入变量重新建立SVM判别模型,结果见表3。
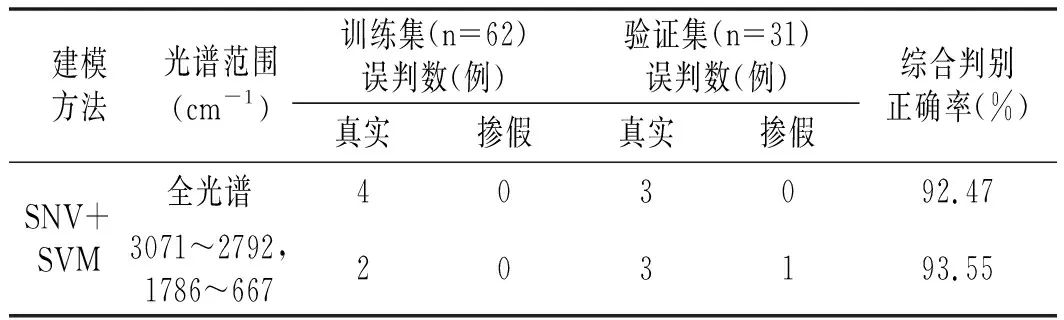
表3 有效波长与全波长的SVM模型判别结果Table 3 Discrimination results of SVM based on effective and full wavelengths
以3071~2792 cm-1,1786~667 cm-1作为输入变量的SVM判别模型与全波段相比,模型综合判别正确率为93.55%,上升了1.08%,且输入变量减少了58.20%,保证样品判别正确率的同时,剔除了光谱中的无用信息。
3 结论
FTIR结合SVM能有效地建立纯芝麻酱掺杂花生酱的判别模型。使用SNV对光谱进行预处理的条件下,对比了线性判别分析和支持向量机2种定性判别模型对分析结果的影响,进一步挑选3071~2792 cm-1,1786~667 cm-1范围内光谱信息作为有效波长,并与全波段模型做比较。结果表明,基于有效波长的SVM模型综合判别正确率达93.55%,判别正确率最高。利用FTIR结合SVM对纯芝麻酱掺杂花生酱的鉴别研究中,样品无需前处理,检测时间短,精度较高,有望作为一种有效手段实现对芝麻酱的鉴伪检测。
猜你喜欢
少儿科技(2021年12期)2021-01-20
文萃报·周二版(2020年31期)2020-09-02
文萃报·周二版(2020年13期)2020-04-14
作文评点报·小学五、六年级(2020年8期)2020-02-14
北京航空航天大学学报(2018年1期)2018-04-20
北京广播电视报(2017年31期)2018-02-26
浙江大学学报(工学版)(2016年11期)2016-06-05
中国农业文摘-农业工程(2016年5期)2016-04-12
舰船科学技术(2016年1期)2016-02-27
环球时报(2010-01-12)2010-01-12
