
基于气体传感器阵列和非线性信号分析技术的龙井茶品质检测方法研究*
2018-10-17 06:37汤旭翔
传感技术学报 2018年9期
汤旭翔,余 智
(1.浙江工商大学实验室与设备管理处,杭州 310018;2.浙江工商大学网络信息中心,杭州 310018)
龙井绿茶,又称龙井茶,是中国传统名茶,著名绿茶之一[1]。产于浙江杭州西湖龙井村一带,已有一千二百余年历史。龙井茶色泽翠绿,香气浓郁,甘醇爽口,形如雀舌,即有“色绿、香郁、味甘、形美”四绝的特点。西湖龙井茶扁平光滑挺直,色泽嫩绿光润,香气鲜嫩清高,滋味鲜爽甘醇,叶底细嫩呈朵[2]。绿茶保留了鲜叶的天然物质,含有的茶多酚,儿茶素,叶绿素,咖啡碱,氨基酸,维生素等营养成分也较多,以其独特的口感和风味而深受中国消费者的喜爱[3]。茶叶的香气对消费者的选购有较大影响,直接影响产品销售情况。因此,绿茶加工过程中风味的品评是不可忽视的重要环节。
传统的茶叶品质分析方法主要包括感官分析法、理化检验方法、仪器分析法等[1]。感官评价依靠具有评审经验的品评员从外观、气味、质地等方面给出综合评价,该方法虽然被普遍使用,但首先需要具有评审经验的人员,并且不同个体对于同样的样品给出的结果往往不一致,相互间评审数据可参考性较差,评审结果也易受个体健康、习惯等因素影响,此外评审人员对于有毒有害的样品也难以开展工作[4-5]。理化检验的方法优点在于有较为全面的标准可以依托,但是一般情况下这一类方法普遍存在耗时长、检验成本高等缺点[6]。仪器分析的方法的优势在于可以高精度定量检测食品中某些物质的含量,也有一系列国家标准作为品质判断依据,但是该类方法一般需要大型昂贵的分析仪器,并且通常需要在实验室环境下工作,无法满足现场快速检测的需求,同时该类方法检测成本高、耗时长、需专业培训的操作人员,这些也都限制了该类方法在现场快速检测的应用。
多传感器分析技术近年来发展迅速,由于该检测方法是吸取被测样品所挥发出来的气体进行分析,因此可以实现无损检测的目标。相对于传统检测技术,该方法具有响应速度快、易于操作和准确性好等优势。可以结合使用的模式识别方法有主成分分析(PCA)、聚类分析(CA)、偏最小二乘回归(PLS)等。Yin等[7]提出了一种基于多传感器阵列优化的食醋区分方法,采用主成分分析法成功区分食醋的种类和风味。Tian等[8]采用PEN2系统进行猪肉掺杂快速实验,结果表明结合线性判别分析方法显示出最优的区分效果。Huo等[9]探索了一种基于电子鼻的中国绿茶种类和分级区分方法,并采用主成分分析方法和等级聚类分析方法对信号进行分析,实现区分目标。Wei等[10]采用电子鼻技术结合物理化学检验方法预测储存花生品质,偏最小二乘回归方法对于去壳和未去壳花生均具有较好的预报精度。然而,以上模式识别模型只是提供了定性区分的方法,无法达成定量检测的目标[11-13]。
基于以上分析,本文研究了多传感器阵列在龙井茶监测上应用的可行性。在测量了传感器阵列的响应数据后,采用载荷分析(Loadings)、归一化处理进行数据的预处理。最后,采用模糊C均值聚类(FCM)、K近邻函数(KNN)和概率神经网络(PNN)分析了多传感器阵列对龙井茶品质的识别效果,为中药材品质的实时监测提供参考。
1 实验方法
1.1 实验材料
龙井茶样品购于杭州某超市,挑选叶片色泽明亮、清洁、无病虫害、无异味的龙井茶作为试验样品。根据试验设计需要,将新鲜龙井茶样品经过干制后形成40个平行样本,每个样品称取15 g置于样品瓶中,并用封口膜密封,在室温和标准大气压的环境条件下进行保藏。通常条件下龙井茶样品的质变过程较为缓慢,在每次实验测量结束后在每个样品中喷雾5 mL超纯水以加速样品的质变。
将龙井茶置于适宜的条件下,利用龙井茶自身带有的真菌进行发霉培养。首先将实验的龙井茶样品进行除杂,测量出龙井茶样品的原始水分,然后将龙井茶样品的水分调节至17%,将调节好水分的龙井茶样品放置在4 ℃的冰箱内48 h,以确保龙井茶样品的水分分布均匀。待样品平衡水分后,称取龙井茶样品,每25 g龙井茶样品放在100 mL的顶空瓶内用封口膜进行封口,将顶空瓶放在恒温培养箱内进行培养,恒温培养箱的温度设置为28 ℃,湿度设置为95%。分别在0 d、1 d、2 d、3 d、4 d和5 d对龙井茶样品进行检测和挥发性物质的收集。

图1 检测系统结构示意图
1.2 仪器和设备
干燥箱;恒温培养箱;高精度电子天平。图1显示了检测系统结构图,主要包括机械控制、传感器气室、数据采集单元等。首先开启清洗泵和气阀2,通入洁净空气清洗各传感器,待各传感器的响应稳定至基线时,关闭清洗泵和气阀2。将样品置入洁净样品瓶中并以封口膜密封,静置30 min后将系统采样探头和气压平衡器同时插进样品瓶的封口膜,启动系统采集样品响应数据,采集时间45 s。气压平衡器采用活性炭去除空气中的干扰气体,将清洁空气导入样品瓶,实现气压平衡。
检测系统采用8个半导体型气敏传感器:x1(TGS-825,含硫类气体敏感),x2(TGS-821,烷烃类气体敏感),x3(TGS-826,氨类气体敏感),x4(TGS-822,乙醇类敏感),x5(TGS-842,碳氢组分类气体敏感),x6(TGS-813,烷烃类气体敏感),x7(TGS-2610,丙烷、丁烷类气体敏感),x8(TGS-2201,氮氧化物类气体敏感)。气室采用耐高温材料,每个传感器都具有独立的气室,以提高检测准确度。
1.3 检测实验
设置检测系统工作参数:清洗时间为600 s,气体流量为320 mL/min,采样时间为40 s。实验具体操作首先取出被测样品,将每一个样品放置在250 mL的样品瓶内,在25 ℃下水浴保温60 min。每个样品重复上述操作5次以保证实验的平行性。
1.4 数据分析
1.4.1 载荷因子分析
载荷是主成分与相应的原始变量之间的相关系数,用于反映因子和变量间的密切程度。因子载荷a(ij)的统计意义就是第i个变量与第j个公共因子的相关系数即表示X(i)依赖F(j)的份量(比重)。统计学术语称作权,心理学家将它叫做载荷,即表示第i个变量在第j个公共因子上的负荷,它反映了第i个变量在第j个公共因子上的相对重要性。位点坐标表示分别在主成分上的比例大小,相关系数越大,位点坐标在主成分上的比例也就越大,位点坐标对应变量的代表意义越明显[14]。
1.4.2 检测数据归一化
在多指标评价体系中,由于各评价指标的性质不同,通常具有不同的量纲和数量级。当各指标间的水平相差很大时,如果直接用原始指标值进行分析,就会突出数值较高的指标在综合分析中的作用,相对削弱数值水平较低指标的作用。因此,为了保证结果的可靠性,需要对原始指标数据进行标准化处理。
数据归一化的目的是使数据集中各数据向量具有相同的长度,一般为单位长度。该方法能够有效地去除噪声干扰导致的传感器阵列获取数据集的方差。实验对传感器优化后的被测样品响应数据进行归一化处理,计算公式为:
(1)
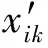
1.4.3 模糊C均值聚类
在众多模糊聚类算法中,模糊C-均值聚类算法FCM(FuzzyC-Means Algorithm)应用最广泛且较成功,它通过优化目标函数得到每个样本点对所有类中心的隶属度,达到自动对样本数据进行分类的目的,其算法主要通过目标函数极小化的必要条件之间的Pickard迭代来实现,根据样本之间的相似度进行自然的分类[15]。
1.4.4 KNN
KNN(k-Nearest Neighbor的缩写)又叫最近邻算法。是1968年由Cover和Hart提出的一种用于分类和回归的无母数统计方法。该方法的特点在于尽量减少或不修改其建立之模型,比较适合处理样本不大的数据[16]。
1.4.5 PNN
概率神经网络由输入层、隐含层、求和层和输出层组成[17]。输入层,作用函数是线性函数,用于接收来自训练样本的赋值,将数据转化为输入信号传递到隐含层,神经元数量与输入长度要等同。隐含层与输入层之间通过权值Wij相连,其传递函数为g(zi)=exp[(zi-1)/σ2],其中zi为该层第i个神经元的输入,σ为均方差。求和层神经元数目与欲分的模式数目相同,具有线性求和功能。输出层有决策能力,其神经元输出值1、0、-1代表输入模式。
1.4.6 茶叶品质计算模型
由非周期输入信号引起的随机共振称为非周期随机共振,该模型通常采用互相关系数指标来表征[18-19]。当输入信号为非周期激励时,此时输入信号具有极大的不确定性,因此首先定义功率范数C0是互相关函数的极大值:
(2)
C0为时间τ的函数,定义为信号幅度放大及相互之间匹配的情况。
归一化功率范数
C1反映了归一化系统输入-输出波形的匹配程度。互相关信息可以定量描述信息关联程度,互信息定义为信息熵H(x)与条件熵H(x|y)之间的差值,可以表示为:
I(x,y)=H(x)-H(x|y)=H(y)-H(y|x)
(3)
互信息也可以解释为在响应y已知的条件下,激励信号x不确定性由H(x)转换为H(x|y),其过程中减少的熵就是互信息I(x,y)。
2 结果与分析
2.1 传感器阵列原始响应
传感器阵列对龙井茶样品的原始响应如图2所示,传感器x4响应最大,而传感器x7和x8的响应较小。随着测量时间的增加,传感器响应均逐渐增加,传感器x4、x6、x5在达到其响应最大值后开始缓慢下降。而传感器x1、x3、x2的响应则持续增加。气体传感器阵列是由具有不同特异敏感性传感器构成的,因此传感器阵列对检测样品的响应则可以表示该样品所挥发出气体的指纹图谱特性,可以用于该样品理化性质的表征。

图2 传感器阵列对样品的原始响应
2.1 传感器阵列的优选
对传感器阵列进行优化选择以减少检测信息中的冗余信息,并且并不是所有的传感器都对被测样品的挥发物敏感,部分传感器在识别目标气体挥发物时发挥作用较小,可优先考虑去除该部分传感器。图3为传感器阵列Loadings优化结果,传感器x1、x2、x3、x4、x5和x6的识别贡献度较大,传感器x7和x8的Loadings分析数据点距离较近,说明这2个传感器在识别时发挥的作用类似。为去除传感器阵列中的冗余信息,我们去掉x8的响应信息以开展进一步的分析工作。
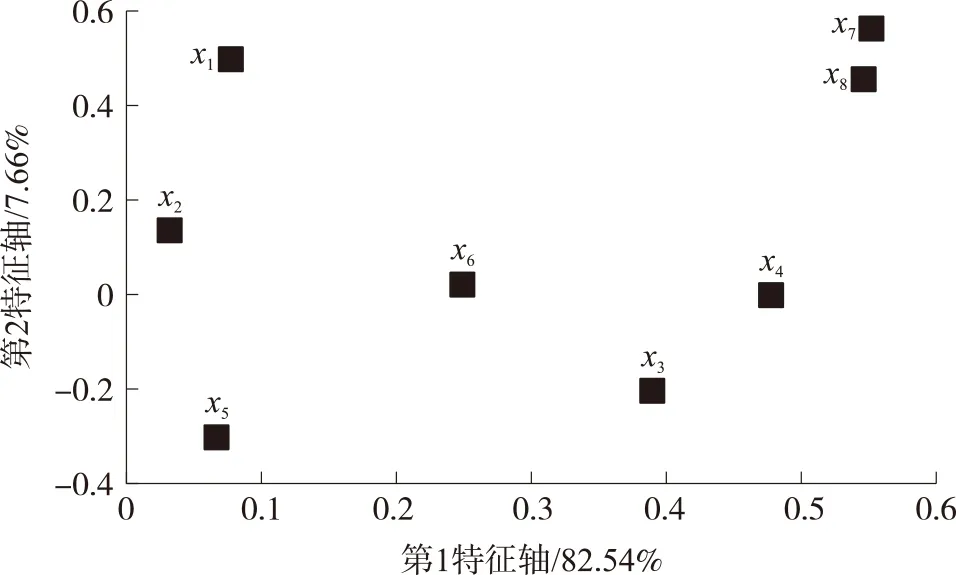
图3 因子载荷分析
2.2 归一化处理
实验对传感器优化后的被测样品检测数据进行归一化处理,计算公式为:
(4)

3 结果与分析
3.1 模糊C均值聚类分析
以FCM探索传感器阵列区分龙井茶样品品质的方法,FCM是一种无监督学习的模式识别方法,进行识别时,加权值m对识别结果影响较大,需要选择最佳m值。经反复训练,加权指数m取5时得到的FCM分类识别效果最佳,分类结果如表1所示。FCM对样品品质的识别正确率为90.83%。其中储存时间1 d与2 d在分类识别过程中区分效果较差,实际应用中易被混淆。FCM分类识别结果初步证明了传感器阵列是可以用于龙井茶品质检测的。

表1 传感器阵列对样品储存时间的FCM识别结果
3.2 k最近邻算法
我们采用KNN对被测样品品质情况进行分类识别。实验包含6类储存时间节点,每类储存时间节点有16个被测样品。从各储存时间节点中随机选择10个样品检测信息作为训练集,其余6个样品作为测试集。因此,实验得到训练集样本数为60个,测试集样本数为36个。在KNN分析中,近邻样本数k的取值对分类识别准确度有较大影响。经过反复训练测试,设置k的个数为5。建立KNN分类识别模型后,模型对训练集样本的回判正确率为100%,对测试集识别的正确率为90%,识别准确度较高。

表2 KNN识别结果
3.3 PNN
在PNN分类识别龙井茶样品品质实验过程中,总共有6个储存时间节点过程,每个节点过程采样16个样本,从其中随机选择10个样品检测信息作为训练集,其余6个样品信息作为测试集。得到训练集样品数量为60个,测试集样品数量为36个。在PNN模型建立过程中,Spread代表PNN的扩散速度,如果其值趋近于0,则网络相当一种最邻分类器,其默认取值是0.1,Spread的取值对模型的判别结果有决定性影响,取值越大就越接近线性函数。为了对PNN模型进行优化,Spread的优化区间取值是[1×10-2、2×10-2、3×10-2、4×10-2、5×10-2、6×10-2、7×10-2、8×10-2、9×10-2、1×10-2]。我们选择训练集识别率和测试集识别率一并为最高时的PNN参数作为最优模型。经过训练测试实验,结果表明Spread=1×10-2时PNN模型为最优配置。在最优模型中,训练集样本分类识别正确率为100%,测试集分类识别正确率为93.3%,具有较好的分类识别效果。
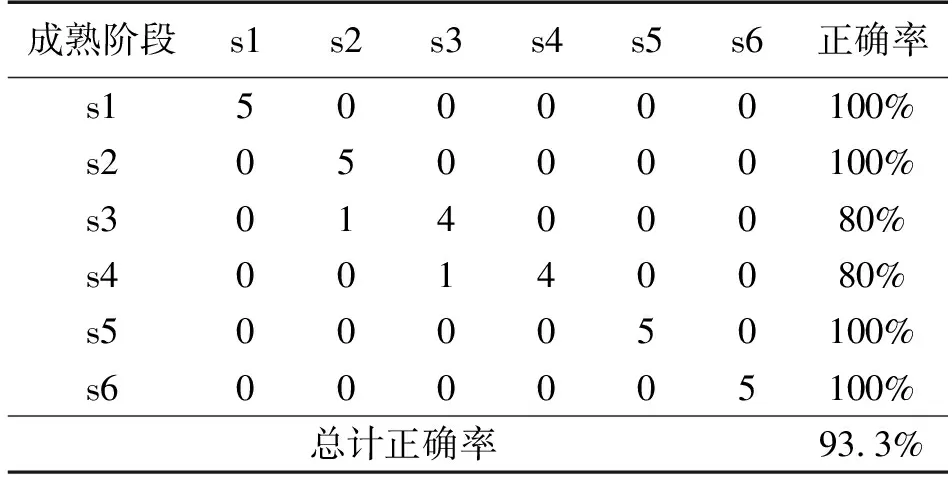
表2 PNN分类识别结果
3.4 测试结果对比
实验采用FCM、KNN和PNN 3种方法对龙井茶传感器阵列检测信息进行了模式识别,识别正确率分别为90.83%,90%和93.3%。FCM仍属于一种线性分类识别方法,并不适用于龙井茶品质分类预测的场合。KNN和PNN都是非线性分类识别模型,在龙井茶样品品质分类识别中均取得了较为准确的结果。因此,KNN和PNN两类非线性模型均呈现了更好的模式识别结果,可以应用到龙井茶品质分类识别场合中去。
图4 非周期随机共振输出结果
3.5 品质预测模型
传感器阵列检测数据的非周期随机共振输出互相关系数曲线如图4所示,随着激励噪声强度数值的增加,各样品的互相关系数首先增加并在噪声强度10左右形成一个特征峰,之后互相关系数逐渐下降,在噪声强度14左右范围内形成谷底。我们选取特征峰作为被测样品的品质表征指标。采用特征峰值线性拟合的方法,构建储存时间对于样品检测数据互相关系数特征峰值的函数,其结果如式(5)所示。
y=0.528+0.013x(R=0.977)
(5)
而在实际检测过程中,我们首先将茶叶样品进行检测,然后得到系统输出互相关系数特征峰值,因此我们将式(5)经过变换,得到茶叶品质对于检测数据互相关系数特征峰值的函数,如式(6)所示。这样,我们直接将样品检测数据互相关系数特征峰值代入式(6),就可以得到品质的预测值。我们另外选取了50个不同储存时间的样品,进行检测,得到输出互相关系数特征峰值后,代入式(6)得到品质预测值,并与这些样品的实际品质进行比较,准确预报的样品数量为48个,预测准确度达到96%,证明该模型确实能够较好的预测样品的品质。
品质=(互相关系数特征峰值-0.528)/0.013
(6)
4 结论
本文研究了一种基于气体传感器阵列和非线性信号分析的龙井茶品质检测技术,采用8个具有不同特异性的气体传感器构建一体化检测实验平台,检测不同品质状况的龙井茶样品。采用Loadings方法优化传感器阵列,去除冗余信息以提高龙井茶品质检测的效率和准确性,得到优化之后的阵列x1、x2、x3、x4、x5、x6、x7。对优化后的传感器阵列检测信息进行归一化处理,并采用FCM、KNN和PNN 3种方法对龙井茶传感器阵列检测信息开展分类识别对比实验研究,分析结果表明上述3种方法的分类识别正确率分别为90.83%,90%和93.3%。结果证明所构建的气体传感器阵列对于龙井茶品质检测呈现了较好的检测精度,非周期随机共振模型输出互相关系数曲线可以区分所有的被测样品,基于该系统和非线性信号分析特征值构建茶叶品质快速模型品质=(互相关系数特征峰值-0.528)/0.013,验证实验结果表明该模型预测准确率达96%。相比较传统检测方法,该方法具有响应快、准确率高、成本低等优势。
猜你喜欢
纺织科学研究(2021年1期)2021-12-03
数学小灵通(1-2年级)(2021年4期)2021-06-09
电子制作(2019年22期)2020-01-14
文化交流(2019年10期)2019-11-22
传媒评论(2019年5期)2019-08-30
中学生数理化·七年级数学人教版(2019年4期)2019-05-20
时代英语·高一(2019年1期)2019-03-13
中学生数理化·七年级数学人教版(2018年6期)2018-06-26
初中生世界·七年级(2017年9期)2017-10-13
茶博览(2015年5期)2015-01-03
