
一种基于HowNet语义计算的综合特征词权重计算方法
2018-10-17 08:38孙丽莉张小刚
统计与决策 2018年18期
孙丽莉,张小刚
(1.西安交通大学 人文学院,西安 710049;2.塔里木大学a.学报编辑部;b.信息工程学院,新疆 阿拉尔 843300;3.浙江大学 计算机学院,杭州 310027)
0 引言
随着信息时代的发展,产生的文本数据越来越多,文本数据挖掘相关研究变得越来越重要。其中,特征词权重计算方法成为文本数据挖掘领域的一个研究热点。与传统的基于统计信息的特征词权重计算方法相比,基于语义的方法从语义逻辑的角度出发,符合人类感知和认识事物的规律,得到了国内外研究人员的广泛关注。目前基于语义的特征词权重计算方法研究已取得一些成果,例如利用词频或词首现位置进行计算的研究(以英文版和中文版WordNet为基础)[1,2];利用语义扩展度和词汇链进行计算的研究(以《同义词词林》为基础)[3];利用统计信息中的词频(termfrequency,TF)和反文档频率(inversedocumentfrequency,IDF)进行计算的研究(以HowNet为基础)等[4,5]。与国外研究相比,国内研究人员主要以向量空间模型(Vector Space Model,VSM)为基础,利用文本的TF和IDF来计算特征词权重。但传统的TF-IDF方法在计算特征词权重时仅仅考虑到了该词在文本集中的分布数量,并没有考虑到该词在文本中的结构信息(分布位置)和特征词之间的语义联系(与特征词词义相似的词在整个文本集中的分布情况),从而影响了特征词权重计算方法的有效性。
本文提出了一种综合的文本特征词权重计算方法,该方法在计算特征词权重时综合考虑了特征词在文本中的词频、位置和词义信息。
1 基于向量空间模型的TF-IDF特征权重计算方法
目前最常用的特征词权重计算方法是基于统计信息的方法,这种方法根据文本中词语的统计信息(如词频、词之间的同现频率等)来计算特征词的权重。例如传统的TF-IDF方法是利用向量空间模型中的统计信息来计算权重的。
1.1 向量空间模型简介
向量空间模型是由Salton等在20世纪70年代提出的,它把对文本相似性的处理简化为向量空间中向量的相似性计算[6]。其中,特征词的权重计算是直接影响基于VSM的文本相似度计算精度的关键因素[7]。
获得文本特征向量后,文本Di和Dj的相似度就可以通过它们特征向量之间的关系来度量。目前主流的文本相似度值计算方法是计算两个文本特征向量的余弦相似度[8,9]。假定两个文本之间的特征项向量分别可表示为,那么它们之间的相似度度量方法如式(1)所示:

式中Sim值越大表示两文本的相似度越高,文本的特征词权重计算直接关系到文本间相似度值的准确性和文本聚类的效果[10]。
1.2 传统TF-IDF特征权重计算方法
传统的TF-IDF方法是以向量空间模型为基础,利用词频TF和反文档频率IDF来计算特征词权重的[11]。它的理论基于香农信息学的一个假设:一个特征词的权重与它在一个文档中出现的频率TF成正比,与逆文档频率IDF成反比。即如果某个特征项在所有文本中出现的频率高,那么它所包含的信息熵就越少,如果这个特征项在少量文本中出现的频率高,那么它包含的信息熵就多[12]。依据这种假设,传统的TF-IDF权重计算公式如式(2)所示:

其中,tfik表示特征词tk在文档Di中的频数,idfik表示特征词tk在整个文本集中除Di外其他文档中出现的频数。N表示整个文本集的文本数,nk表示整个文本集中出现特征项tk的文本数,α是一个调节系数(常量),通常设为0.01。
1.3 传统TF-IDF特征权重计算方法存在的问题
从上述可知,传统TF-IDF是基于统计学的权重计算方式。该方法优点是简单快速,结果比较符合实际情况。缺点主要有:一是在VSM中,传统TF-IDF算法没有体现特征词在文本中的结构信息。对于文本文档而言,权重的计算方法应该体现出文本的总体信息,包括特征词的词频、词义,位置等。二是特征项被假定为是完全独立的。这样就将特征词之间的词义相似关系,当成完全不相干的两个词来处理,缺失了语义信息。因此本文将综合考虑这些因素,使权重同时兼顾词频、位置和词义信息。
2 一种新的综合TF-IDF特征词权重计算方法
本文提出的综合TF-IDF权重计算方法是在传统TF-IDF方法依赖词频信息的基础上,增加了特征项的结构信息(位置)和特征项之间的语义信息。
2.1 综合TF-IDF方法总体思路
针对原始待测文本Di,依据VSM用特征向量表示如式(3)所示:
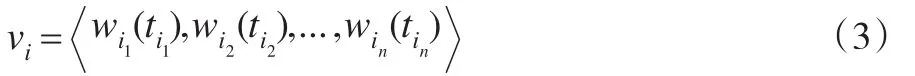
本文提出的综合TF-IDF特征词权重计算方法总体思路如下:对文本Di依据VSM形成的特征向量vi,假设采用传统TF-IDF方法得到其中特征词tij(1≤j≤n)的初始词频权重为wij(1≤j≤n),将wij结合位置系数pij后计算得到综合词频权重wpj,再将wpj结合语义信息系数oij计算得到综合词频-词义权重woj。具体计算过程如式(4)所示:

因此,本文方法弥补了传统TF-IDF方法在特征项权重计算中丢失的部分重要信息,从理论上完善了特征词权重计算方法的完整性。
2.2 词频信息中的位置考量
一些研究也证明,利用与标题相似度较大的语句来提取特征词进行分类时,分类效果较好[13]。就像句子中有关键词一样,通常文本中也有中心语句和普通语句,中心语句中保含的特征词就比普通语句更能反映出文本内容。所以本文对处于不同位置的特征词分别赋予不同的系数,然后加权乘以特征词的词频,以提高文本表示的效果。
在特征提取之前对文本的各个部分的重要程度(在表达文本内容时的贡献大小)加以区分。为了体现特征词对文本内容贡献的差别,给不同位置的特征词赋予对应的“权重系数”。以新闻类文本为例(只有标题和正文),本文将文本位置分成三类。第一类:位于文本的标题位置,赋予权重系数α1;第二类:位于文本正文中的开头语句,赋予权重系数α2;第三类:除开头语句外的正文语句,赋予权重系数α3,且α1>α2>α3。
按照传统TF-IDF方法中对于文本Di中的特征词tij根据频度赋予权重,则结合特征项位置系数pij后的特征向量vp上各维的权重可由式(5)计算获得。

由式(5)获得的文本特征向量vp,每个特征词的权重综合了词频与位置信息两个要素,更能表达特征词的权重。vp特征向量如式(6)表示:

2.3 词义信息中的相似度考量
现有的词语语义相似度主要可以分为基于统计信息的方法和基于本体的方法。其中,基于本体的方法主要依靠语义词典中概念间结构层次关系,相关研究包括基于WordNet的计算方法、基于HowNet的和基于同义词词林的计算方法等。

这里,βi(1≤i≤4)表示第i项义原描述式计算所得相似度占整体相似度的比率。其中,第一独立义原描述式代表了一个概念最主要的特征,其权值所占比例βi最大。依据Sim1到Sim4对于总体相似度所起作用的依次递减,权值所占比例也依次递减,即β1≥β2≥β3≥β4。另外,为了保证权重的完整性,要求β1+β2+β3+β4=1。

式中nk表示包含特征词tij的文本数目;ui表示出现在其他文本中与特征词tij语义相似特征词的文本数目;1+r表示特征词tij及与特征词tij语义相似的词语数量。
本文在参考文献[4]权值计算方法的基础上,结合语义后的综合TF-IDF公式如式(8)所示:
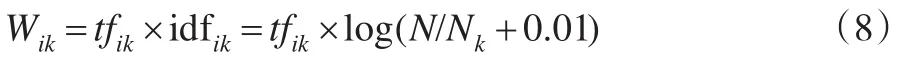
式中对参数tfik加以改进,这里tfik表示在文本Di中出现的特征词tij及与tij语义相似的特征词之和的平均值,改进后的tfik更能显示特征词及其语义相似词的作用;改进后的idfik表示在文本Di以外的其他文本中特征词tij及与tij语义相似的特征词的平均分布情况;这里N表示文本集中文本的总数;Nk表示出现特征词tij及与tij语义相似特征词的文本数目之和的平均值。Nk的计算公式如式(9)所示:
3 实验设计与结果分析
特征词权重计算通常是为文本相似度计算和文本聚类服务的,所以本文利用文本相似度计算及相似度聚类的效果来检验权重计算方法的优劣。对文本相似度的效果检验,本文采用文本区分度指标。对相似度聚类效果的检验,本文采用相似度计算结果聚类的查准率、查全率和F-Score指标。
3.1 实验数据说明
实验数据采用的是哈尔滨工业大学语言技术平台LTP中多文档自动文摘语料库中开放的10%语料[2]。本文实验数据以同类6篇,异类3篇为例进行深入分析(朝鲜核问题6篇,法国油轮爆炸、菲律宾南部城市连环爆炸和航天专家海口被杀主题各1篇)。通过分析语料发现,可以表达文本主要意思的是句子的主干成分,而主干成分主要由名词、动词这类实词构成,所以本文选择名词和动词作为代表文本的特征项,设置关键词表为20维(名词10个,动词10个)。
3.2 实验思路与结果分析
(1)实验思路:首先,对实验数据进行分词,去虚词、停用词后获取关键词表;其次,利用本文提出的综合TF-IDF的权重计算方法和传统的TF-IDF方法分别计算特征词权重;然后,利用余弦相似度计算公式(1)计算文本相似度;最后,对得到的文本相似度结果进行区分度比较和聚类实验。
农业机械的保养要严格按照使用说明书及当地农机管理部门规定的内容进行。机车的高级保养应在机务管理人员指导下在室内进行。燃油动力机械要做到四小漏 (小漏油、小漏水、小漏气、小漏电)、五净(油、水、气、机器、工具)、六封闭(柴油箱口、汽油箱口、机油加注口、机油检视口、汽化器、磁电机)、一完好(技术状态完好);配套农具要实行常年修理,做到三灵活(操作、转动、升降灵活)、五不(不旷、不钝、不变形、不锈蚀、小不件)、一完好(技术状态完好)。
在利用传统TF-IDF方法取得词频相似度后,本文提出的综合TF-IDF(包含词频、位置、词义)相似度计算步骤如下:
步骤1:文本词频相似度计算。将采用传统TF-IDF方法取得的特征词词频分别与其位置权重系数相乘,得到特征词综合词频数据,并采用取余弦值的方法计算文本的词频相似度,相似度取值范围为[0-1]。本文采用的语料为新闻类文本,只包括标题和正文,所以设置位置系数三种,标题、开头句、正文,分别赋予权重系数α1=2,α2=1.5,α3=1。
步骤2:文本词义相似度计算。以步骤1中得到的特征词向量相对应的次序,将10个名词,10个动词依次采用公式(7)求词义的相似度;然后采用取余弦值的方法计算文本的词义相似度,相似度取值范围为[0-1]。这个步骤是对特征词进行语义相似度的合并,本文设置阈值0.6,即与特征词tij语义相似的词语是与tij语义相似度大于0.6的词语;否则认为不相关,取值为0。
步骤3:文本综合相似度计算。将步骤1所得的综合词频相似度结果与步骤2所得的词义相似度结果加权求和求得综合相似度。其中,词频相似度占比0.7,词义相似度占比0.3。
说明:步骤2中词义相似度计算的实验软件采用中国科学院计算技术研究所开发的软件WordSimilarity[2]。本文设置软件WordSimilarity中的各参数取值分别为:β1=0.5(表示第一项义原描述式β1所占比例0.5),β2=0.2,β3=0.17,β4=0.13;α=1.6;γ=0.2;δ=0.2。
(2)实验结果一:文本相似度结果的区分度比较
文本区分度,具体来讲就是同类文本相似度与异类文本相似度之间的差。对本文而言,就是分别对本文中采用的综合TF-IDF权重计算方法和传统TF-IDF方法计算得到的文本相似度进行比较,哪种权重方法的差值越大,则表示该方法的区分性越好。以A1为例,文本区分度比较统计数据如表1所示。

表1 单个文本A1与同类、异类文档区分度统计
由表1计算结果可知本文中改进的方法与传统的TF-IDF权重方法相比,从理论上完善了文本相似度比较的定义,并且显著改善了区分度的区分效果。
(3)实验二:文本相似度结果的聚类比较
因为文本聚类可以发现最近邻文档,所以本文利用文本集中某个文档与同类、异类文档相似度聚类的效果来评价相似度算法,进而反推出特征词权重计算方法的优劣。文档聚类是以文档中频繁出现的术语或词的列表为依据,利用相似度函数将文档集合分成不同组的过程[4]。
为了评价本文提出的权重计算方法的效果,本文利用文本相似度结果进行聚类,考虑了三种不同的评价措施:查准率(Accuracy),查全率(Precision)和综合指标F-Score来衡量算法的性能。
查准率P(i,j)是指属于类别j的所有文本中,与实际相符的文本所占的比例。运算规则如式(10)所示:

式中nj是聚类j的文本数目,nij是聚类j中隶属于类别i的文本数目。
查全率R(i,j)是指专家判定的属于类别j的文本中,正确归类的文本所占的比例。运算规则如式(11)所示:

其中,ni是类别i的文本数目,nij是聚类j中隶属于类别i的文本数目。
F-Score是一种利用查准率和查全率来进行聚类效果评价的综合指标。F-Score运算规则定义如下:

式中P(i,j)代表查准率,R(i,j)代表查全率。利用这三种指标可以判断每一篇文本在聚类后是否被正确划分到了所属类别。
在此实验样本中,以相似度0.45作为文本相似度结果聚类同类的临界值(即大于0.45为同类,否则为异类)。相似度聚类结果如表2所示。

表2 文本A1与同类、异类文档相似度聚类结果统计
如表2所示,本文分别利用传统的TF-IDF方法和增加位置、语义信息后的综合TF-IDF方法,以文本集中文档A1为标准与其余文档进行相似度结果聚类实验。
实验结果在查准率、查全率以及F-Score指标下的对比情况如图1所示。
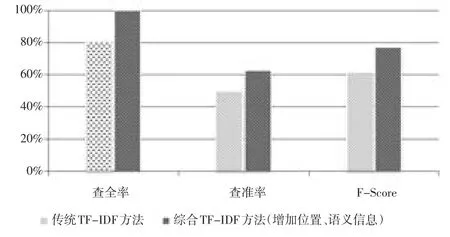
图1 基于查全率、查准率和F-Score系数的文本相似度结果聚类比较
由图1看出,在本样本中,采用本文提出的综合TF-IDF权重计算方法得到的文本相似度聚类结果,其查准率、查全率以及F-Score系数均高出基于传统的TF-IDF方法。
综上显示:在文本特征词权重算法中,计算过程中增加特征词的位置信息和特征词间的语义信息,能够在计算文本相似度时有效地提高文本间的区分度;并且能够明显提高实验文档与同类、异类文档的相似度聚类查准率、查全率和F-Score系数指标。
4 总结
传统的利用向量空间模型的文本特征词提取方法,采用TF-IDF计算文本特征词的权重时只考虑了文本中的词频因素,体现不出特征词的位置信息,而且在计算权重的过程中把每个特征词视为孤立的,忽略了特征词之间的语义相似关系,因此降低了提取特征词的准确性。本文针对上述问题,提出了一种综合的文本特征词权重计算方法。此方法首先利用结构信息(位置)对传统TF-IDF方法得到的特征词权重进行矫正,然后利用基于HowNet的语义相似度算法实现对特征词权重的词义修正。因此,本文的提出的综合TF-IDF权重计算方法兼顾了特征词的词频、位置和词义信息,从理论上完善了特征词权重计算方法的完整性。实验结果也表明,该方法能够在一定程度上提高文本相似度计算的区分度和聚类效果。
