
具有短密文的多身份全同态加密构造框架
2018-10-16 12:15王学庆
信息安全学报 2018年5期
王学庆, 王 彪, 薛 锐
1中国科学院信息工程研究所信息安全国家重点实验室 北京 中国 100093
2中国科学院大学网络空间安全学院 北京 中国 100049
1 引言
全同态加密 (Fully Homomorphic Encryption,FHE) 是一个密码学原语, 它的功能是允许任何人对密文进行任意计算, 满足这样的实际需求: 拥有较少资源的用户, 既能保护持有数据的隐私性, 又能利用拥有较多资源服务器的强大计算能力, 适用于安全计算、隐私数据检索等应用场景。同态加密(Homomorphic Encryption, HE)的思想最早由Rivest,Adleman和Dertouzos在1978年提出[1], 虽然出现了很多HE方案, 如早于同态思想提出的RSA加密方案[2]、El Gamal加密方案[3]、BGN加密方案[4], 但是这些方案只满足乘法同态、加法同态或较低次数多项式同态, 直到2009年, Gentry才构造出第一个FHE方案[5]。接下来, 基于不同假设、具有更多功能、更高效或构造思想更自然的 FHE方案[6-14]如雨后春笋般涌现出来。
在 FHE的发展过程中, 借鉴在传统公钥加密基础上发展出的密钥生成与管理更方便的身份加密(Identity-based Encryption, IBE)[15], 2010年, Naccache将如何构造身份全同态加密 (Identity-based Fully Homomorphic Encryption, IBFHE) 方案作为一个公开问题提出[16]; 2013年, Gentry, Sahai和Waters首次对这一公开问题作出了正面回答[13], 利用他们基于近似特征向量方法构造的、无需计算密钥的层次型全同态加密 (Leveled Fully Homomorphic Encryption,LFHE) 方案(以下简称 GSW), 给出了一个可将已有基于DLWE假设的IBE方案, 转换为身份层次型全同态加密 (Identity-based Leveled Fully Homomorphic Encryption, IBLFHE) 方案的框架; 2014年, Clear和McGoldrick利用不可区分混淆(Indistinguishability Obfuscation, iO) 方案和可穿孔的伪随机函数(Puncturable Pseudorandom Function, PPRF)[17], 构造了一个可将 FHE方案转换为 IBFHE方案的框架;2015年, Clear和McGoldrick在GSW的基础上, 给出了可将满足特殊条件的 IBE方案, 转换为多身份层次型全同态加密 (Multi-id Identity-based Leveled Fully Homomorphic Encryption, MIBLFHE) 方案[18](以下简称 CM15), 其构造方法也可将 GSW 这一LFHE方案转换为多密钥的层次型全同态加密(Multi-key Leveled Fully Homomorphic Encryption,MLFHE) 方案, 从而继López-Alt等人的第一个基于非标准假设的 MLFHE方案[19]之后, 得到了第一个基于DLWE这一标准假设的方案。虽然CM15利用Gentry, Peikert和Vaikuntannathan的IBE方案[20](以下简称GPV) 构造了第一个单跳①的MIBLFHE方案,但是其安全性只能在随机谕言机 (Random Oracle,RO) 模型下得到证明, 且其构造方法晦涩复杂。
在CM15的基础上, MFHE的研究取得了较大的进展, 2016年, Mukherjee和Wichs简化了CM15的构造方法, 得到了一个简洁自然的、单跳的MLFHE方案 (以下简称MW16)[21]; 同年, Brakerski和Perlman将 MW16中的简洁方法用于多密钥的同态解密, 得到了一个短密文的、全动态的 MFHE方案 (以下简称BP方案)[22]; 几乎同时, Peikert和Shiehian灵活化了 MW16的构造方法, 得到了两个多跳的 MLFHE方案[23]。
关于MIBFHE的发展, 2017年, Canetti等人借鉴Brakerski等人构造多属性全同态加密的方法[24], 给出了一个构造框架[25], 他们利用IBE方案和MFHE方案这两种构件。另外, 为了得到同时实现全动态和全同态的 MIBFHE方案, 我们可以用满足这两个性质的BP方案和基于DLWE假设的IBE方案去实例化,得到的方案密文规模为 O (n5lo g5q),这里n,q是DLWE假设的参数。因密文规模是影响通信效率的关键因素, 故考虑如何构造密文规模更小的 MIBFHE方案, 是一个具有重要理论意义和实际价值的问题。
1 我们的工作
首先, 我们在第3节构造了一个可将MFHE方案转换成 MIBFHE方案的框架。经过观察, 我们发现Canetti等人的框架有两点不足: (i) 密文规模较大;(ii) 即使 MFHE的同态结果密文规模不依赖于输入密文数, MIBFHE的同态结果密文规模也与输入密文数成正比, 即 MIBFHE的紧致性比 MFHE的变弱,而导致这两点不足的原因是: 密文不仅包括用MFHE的公钥pk对消息的加密, 还包括pk和IBE的用户公钥 (mpk,id) 对MFHE的私钥sk的加密。因密文规模是影响通信效率的关键因素, 从实际应用出发, 我们应考虑如何减小密文规模。为了消除这两点不足, 我们考虑只在密文中保留对消息的加密这一部分, 那么就需要用于加密消息的MFHE的pk与id有关, 为了能够解密, 用MFHE的sk作为skid, 从而需要将id嵌入 (pk,sk) 的生成过程, 一般的方法是将id与生成 (pk,sk) 所用的随机串进行关联, 可用PRF实现与id相关的随机性, 而为了在证明中划分挑战身份id*和解密密钥查询的身份集合{idi}, 我们采用PPRF实现, 这样我们把PPRF的密钥作为方案的主私钥, 为了公布与skid配对的pkid, 可用iO实现, 从而得到了只用MFHE构造MIBFHE的框架。
① 同态计算的结果密文不能继续参加有新用户参与的同态计算。虽然我们用到了iO这一复杂度较高的工具, 但因只影响到主公钥mpk的规模, 且主公钥是公共的, 相比于密文规模, 对通信效率影响较小。
然后, 我们在第4节用BP方案[22]对第3节中构造的框架进行实例化, 得到了同时满足全动态和全同态性质的、密文规模为O ( nlogq)的MIBFHE方案,且该方案的紧致性比Canneti等人方案的紧致性强。
2 基本概念
在这一章我们将给出本文将要用到的相关符号和概念的定义。
本文约定用a←RA表示从集合A中均匀随机选取元素 a, 用←(除映射外)表示概率性得出, 用:=表示其左边的结果由其右边确定性计算得出, 用 PPT(Probabilistic Polynomial Time) 表示概率多项式时间,用 [n] 表示集合
2.1 带错学习问题(Learning with Errors,LWE)
LWE问题是带噪声校验位学习 (Learning Parity with Noise, LPN) 问题的一个扩展, 最初由Regev提出[26], 有搜索性和判定性两种形式, 通过设置合适的参数, 搜索性 LWE与判定性 LWE (Decisional LWE, DLWE) 问题的困难性等价, 下面只给出判定性LWE问题的定义:
定义1. 对于任意安全参数λ,设两个整数n= n (λ),q = q (λ)≥ 2 ,一 个 支 撑 集 为 ℤ 的 分 布χ=χ( λ),用DLWEn,q,χ表示的 DLWE问题是指区这两个分布。DLWEn,q,χ假设是指不存在求解 D LWEn,q,χ问题的PPT算法。
目前已知 Regev在2005年[26]、Peikert在 2009年[27]分别给出了从格上的近似最短向量问题到DLWEn,q,χ问题的量子归约和经典归约, 由于目前尚无求解格上近似最短向量问题的多项式时间量子算法, 因此也没有求解 D LWEn,q,χ问题的多项式时间量子算法, 进而公认基于 D LWEn,q,χ问题的密码学方案是抗量子攻击的。另外, 这些归约中用到的χ都是高斯分布, 而高斯分布与取值恰当的Bχ有界分布统计不可区分[11], 因此为了简便, 本文方案中的噪声分布都用Bχ有界分布。
下面给出Bχ有界分布的定义[11,13]。
定义 2. 设整数集ℤ上的一个概率分布总体{χn}n∈ℕ, 对 于 任 意 常 数 Bχ> 0 ,若成立, 则称该概率分布总体是Bχ有界的。
2.2 多身份全同态加密(Multi-id Identitybased Fully Homomorphic Encryption,MIBFHE)
若一个IBFHE方案能同态计算用不同身份加密得到的密文, 则称它是多身份的。基于安全性考虑,MIBFHE要求只有联合参与同态计算的所有用户,才能对结果密文进行正确解密。
一个MIBFHE方案由以下五个多项式时间算法构成:
-Setup(1λ)→ ( m pk , m sk):概率性的系统参数生成算法 Setup以安全参数1λ为输入, 生成公共参数mpk和主私钥 m sk.
-KeyGen(ms k , i d )→skid:概率性或确定性的解密密钥生成算法KeyGen以主私钥msk和身份标识id为输入, 生成id对应的解密密钥 s kid.
-Enc(mp k , i d ,μ )→cid:概率性的加密算法Enc以公共参数 m pk , 身份标识id和消息μ为输入, 生成只能用 s kid解密的密文 cid.
-Eval(mpk, f ,( c1,… ,ct))→ˆ:概率性或确定性的同态计算算法 Eval以公共参数 m pk,电路f和与其输入数相同个数的一组密文 c1,… ,ct为输入, 这些密文可能对应不同的身份标识 i d , 生成结果密文
-Dec((skid1,… ,s kidN),ˆ )→ μ:确 定 性的 解 密算 法Dec以密文cˆ和与其对应所有身份标识的解密密钥(skid1,… ,s kidN)为输入, 联合解密得出消息μ。
一个MIBFHE方案的一些性质定义如下:-全动态性。设 N = N(λ),t = t (λ),对任一可同态计算的电路 f ,任意 (id1, … ,i dN)和 (cˆ1,… ,c ˆt),满足(m pk, m sk)←Setup(1λ),对于所有的i∈[N],
skidi←KeyGen(msk,idi),若Pr[D ec ( (sk1, … ,skN),E val(mpk,f, (cˆ1, … ,cˆt)))≠f(μ1, … ,μt) ] = negl(λ)成立, 则称MIBFHE方案具有全动态性; 否则, Setup算法以N作为输入, 即预先给定可参与同态计算的最大用户数。注意, 这里隐含了方案正确性的定义。
-紧致性。对于任意的同态计算结果密文cˆ ← Eval(mpk,f,{ci}),存在一个多项式poly(.),使得 |c ˆ|≤ poly(λ),其中poly(.)独立于电路f的规模、深度、输入密文数或不同用户数①因本文用于实例化的BP方案只关于电路的规模和输入数具有紧致性, 故我们得到的MIBFHE方案也只关于电路的规模和输入数具有紧致性, 即这里的poly只独立于电路规模和输入数, 是关于安全参数、电路深度和不同用户数的函数。。
-全同态性。若f是任意多项式深度的电路, 即方案可用于同态计算任意多项式深度的电路, 则该方案被称为全同态加密方案; 否则, 若Setup算法以L作为输入, 即预先给定可同态计算电路的最大深度,则称该方案是层次型全同态加密方案 (Leveled Fully Homomorphic Encryption, LFHE).
-安全性。 MIBFHE方案的安全性定义与 IBE的相同, 一般考虑 IND-aID-CPA (又称适应安全性) 和IND-sID-CPA (又称选择安全性) 这两种安全性, 下面给出IND-sID-CPA安全性的形式化定义。
IND-sID-CPA安全性实验由挑战者C与敌手A交互执行:
初始化阶段: A向C提交将要挑战的身份标识id*;
参数生成阶段: C根据方案生成mpk和msk, 并将mpk发送给A;
解密密钥查询阶段(挑战前): A选择除 id*以外的任意身份标识id对解密密钥oracle进行多项式次询问,C充当解密密钥oracle, 回答与id对应的解密密钥;挑战阶段: A向C提交 (μ0, μ1), 要求μ0与μ1等长,C随机选择b∈{0,1}, 调用加密算法生成μb的密文cid*发送给A;
解密密钥查询阶段(挑战后): A可以继续选择除id*以外的任意身份标识id对解密密钥oracle进行多项式次询问, C按照挑战前的方式进行回答;
猜测阶段: A向C提交对b的猜测b′, 若b′=b, 则输出1, 否则输出0.
IND-aID-CPA安全性定义与IND-sID-CPA安全性定义的区别是: 敌手 A在挑战阶段与消息一起选择并提交挑战身份id*.
注: 因MIBFHE方案是对IBE, FHE, MFHE方案的扩展, 由 MIBFHE的定义易得出后三种方案的定义, 故在此只给出MIBFHE的定义。
2.3 不可区分混淆 (Indistinguishability Obfuscation, iO)
iO作为对虚拟黑盒 (Virtual Black Box, VBB)混淆的一种弱化方案, 最初由 Barak等人[28]在 2001年提出, 它用来保证任意两个功能相同的电路混淆后计算不可区分。
定义 3. 设iO为一致的 PPT算法, 若对于一个电路分布簇{Cλ}, 若iO满足以下两个条件:
-正确性。对于任一安全参数λ∈N, 任一电路C∈Cλ,任一输入x, 都有

-不可区分性。对任意 PPT 敌手(S amp, D ) ,(C0,C1, τ) ← S amp(1λ), 都存在一个关于λ的可忽略函数 εiO, 使得如果Pr[C0(x) =C1(x) for ∀x] >1 - εiO,≤ εiO.则称iO为不可区分混淆方案。
2.4 可穿孔的伪随机函数(Puncturable Pseudorandom Function, PPRF)
PPRF作为一类简单的受限 PRF, 最初由 Sahai和Waters在2014年提出[29], 它允许PPT敌手首先给定一个多项式规模的输入集合, 即使给敌手一个计算密钥, 该密钥可用来计算除此集合之外所有输入的函数值, 它也难以区分一个值是此集合中输入的函数值还是一个等长的随机元素。
定义 4. 一个可穿孔的伪随机函数F:K × { 0,1}k→{0,1}m有两个算法(Key, Puncture),满足以下两个条件:
-穿孔外的功能不变性。对于任意 PPT敌手 A,{0,1}k(λ)⊇S←A ( 1λ),对 于 所 有 不 在S中 的x ∈ { 0,1}k(λ),Pr[F ( K, x) = F ( K( S ) ,x) :K ← Key (1λ),K(S) ← Puncture(K,S)]=1成立。
-穿孔处的伪随机性。对于任意PPT敌手 ( A1, A2),有
2.5 Brakerski和Perlman的全动态多密钥全同态加密方案
Brakerski和Perlman在CRYPTO 2016给出的方案[22]是目前已知的唯一一个全动态→ M FHE方案, 其中用到一个特殊矩阵G: =I⊗gT,这里 I 表示
n+1n+1
-BP. S etup ( 1λ) :生成 D LWE假设成立的参数n,q,χq, n, m,χ,Bχ,其 中q是 模 数, n是 维 数,m = ( n + 1 )ℓq, Bχ-有界的分布 χ是噪声分布,

令 B it(s k)表示sk的比特分解→
对于i∈ [m] ,Ri←R{0,1}m×m[ i] := ARi+ B it(s k )[ i].G
对于

输出

-BP. E nc( p k,μ ∈ { 0,1}):随 机 选 取
2.6 Canetti等人的多身份全同态加密构造框架
设(M FHE.Setup, M FHE.KeyGen, M FHE.Enc,Eval, MFHE.Dec)是一个 MFHE方案, (IBE.Setup, IBE.KeyGen, I BE.Enc, IBE.Dec)是一个IBE方案, Canetti等人[24]利用这两类方案构造了多身份的身份全同态加密方案, 其主要思想是将身份标识到加密密钥的映射与密文计算分开, 即利用 IBE方案的从身份标识到加密密钥的映射, 和 MFHE方案的同态计算能力, 既避免了仅利用 IBE存在密文扩展问题所导致的无法利用已有的适应性安全方案问题, 又解决了仅利用 MFHE方案存在的身份标识到加密密钥的映射问题。该思想与Brakerski等人[25]利用属性加密和多密钥全同态加密构造多属性全同态加密的思想相同。
-Setup ( 1λ) :PPMFHE←MFHE. S etup (1λ),(mpkIBE,mskIBE) ← IBE. S etup (1λ)
输出 m pk : =(P PMFHE, m pkIBE) , msk : = mskIBE.-KeyGen(m sk, i d ):
输出 s kid←IBE. K eyGen(m skIBE,i d ).-Enc ( m pk, i d ,μ):将mpk分解为
(PPMFHE,mpkIBE),
(pkMFHE,skMFHE) ← MFHE. K eyGen(PPMFHE),
c1←MFHE. E nc(pk,μ),
idMFHE
c2←IBE. E nc (mpk,id,sk),
idIBEMFHE
-Eval(f, (c1, … ,ct)):
假设 c1,…,ct对应不同的身份下标集合I1,… ,It,
且满足 {idi}i∈I1∪… ∪ {idi}i∈It={id1,… ,idN}
对于所有的i∈[t],将ci分解为

首先将c{idi}i∈[N]分解为
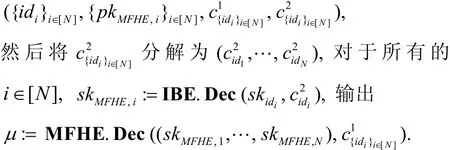
观察以上构造, 我们发现其新鲜密文不仅包括对消息的加密, 还包括MFHE的公钥pk和IBE对MFHE的私钥sk的加密, 另外, 其同态计算中的结果密文不得不包括所有输入密文中 MFHE私钥sk的密文的级联, 因此即使 MFHE紧致性较强 (如同态结果密文规模仅与不同id数有关, 而与输入密文数无关), MIBFHE的同态结果密文规模也与输入密文数成正比。
为了从以上构造中得到全动态的多身份全同态加密方案, 目前我们可以用基于 D LWEn,q,χ假设的IBE方案和 BP方案去实例化, 因已有的基于DLWEn,q,χ假设的 IBE方案[20,31-32]的密文空间最小为 ℤm,根据2.5节, 我们知道BP方案的公钥空间为q故实例化得到的多身份全同态加密方案的密文规模为 O (n5lo g5q).
3 具有较短密文和较强紧致性的多身份全同态加密构造框架
如前所述, 我们仅利用 MFHE这一个构件去构造MIBFHE, 具体地, 将id与生成MFHE的 (pk, sk)的随机串关联, 嵌入到其生成算法KeyGen中, 因已有MFHE方案KeyGen算法中的随机元素是从ℤq或ℤ中, 根据均匀分布或高斯分布选取出的向量或矩阵, 我们不是简单地利用一个 PPRF, 而是针对每一类随机元素, 增加概率抽样算法, 作为PPRF生成的随机串与 KeyGen算法所用随机元素之间的桥梁,也就是将 PPRF生成的随机串作为概率抽样算法的随机串, 概率抽样算法的输出作为 KeyGen算法的随机元素, 从而使得PPRF的输入id决定KeyGen算法的输出(pkid,skid),
设(M FHE.Setup, M FHE.KeyGen, MFHE.Enc, MFHE.Eval, MFHE.Dec)是一个MFHE方案,构造的MIBFHE方案的身份标识空间为{0,1}k,噪声分布为Bχ-有界分布χ,iO是一个不可区分混淆方其 中 ℜSampleU, ℜSampleE分 别 是 概 率 算 法SampleU, SampleE的随机数空间, 这里SampleU(A1,U)是指从集合 A1中按照均匀分布U随机抽取出一个元素, S ampleE( A2,χ)是指从集合 A2中按照噪声分布χ随机抽取出一个元素。
-MIBFHE. S etup ( 1λ):P P←MFHE. S etup (1λ),K←F. K ey (1λ),令H为程序 FMapPK(见图 1)的一个混 淆 iO(1λ,FMapPK), 输 出mpk: = (PP,H),msk: =(PP,K).
(pkid,skid):= MFHE. K eyGen (PP; (Rid,Eid)),输出skid.注意, 这里的集合 A1, A2由 M FHE. KeyGen算法决定。
-MIBFHE. E nc (mpk,id∈{0,1}k,μ):pk:= H(id),
id输出 cid←MFHE. E nc(p kid,μ).
-MIBFHE. E val (mpk,f, (c1, … ,ct)):假 设c1,…,ct对应于不同的身份下标集合为 I1,… ,It,且满足I1∪…∪It={id1,… ,idN},对 于 任 意i∈[N],pkidN),f,(c1,… ,ct)).
-MIBFHE. D ec ( (skid1,… ,skidN),:输出 μ:= MFHE.

图1 程序 F MapPKFigure 1 ProgramFMapPK
定理1. 若方案MFHE是IND-CPA安全的, iO是一个计算不可区分混淆方案和F是一个可穿孔的伪随机函数, 则方案MIBFHE是IND-sID-CPA安全的。
证明. 假设存在一个 PPT的敌手A,攻击MIBFHE方案 IND-sID-CPA安全性的优势为εMIBFHE(λ) , 我们将采用实验序列的方式证明εMIBFHE(λ)可忽略, 其中每个实验都由挑战者C与敌手A交互执行:
Game 0. 这是定义IND-sID-CPA安全性的原始实验,首先敌手A向挑战者提交将要挑战的身份标识id*,然后在参数生成阶段, C调用(mpk,msk)←MIBFHE. S etup ( 1λ),并将mpk发送给 A .在解密查询阶段, 当A对idi进行查询时, C检查idi是否等于id*,若是, 则拒绝回答, 否则调用skidi←MIBFHE. K eyGen (msk,idi),将skidi发送给A,这样的查询可执行关于λ的任意多项式次。在挑战阶段, 当收到A发送的一对等长消息(μ0, μ1)时,C从{0,1}中 随机 选 择 b, 调 用c←MIBFHE. E nc (mpk,id*,μ ),将c发送给
id*bid*A.在挑战后的解密查询阶段, 对于A的询问, C像挑战前一样处理。在猜测阶段, A发送b′给C,若b′=b,C输出1, 否则输出0.
Game 1. 在参数生成阶段, C生成 K ←F. K ey (1λ)后, 调用 K ( {i d*} ) ← F. P uncture(K , {i d*}),在挑战前后的解密密钥查询阶段, C利用K( {id*})而不是K回答A的解密查询, 其他与Game 0中相同。
Game 2. C不在挑战阶段利用H生成 p kid*,而是在参数生成阶段如下生成: 生成 K ←F. K ey (1λ)后,

图 2 程序MapPKFigure 2 ProgramMapPK
Game 5. C不先选取 Rid*和 Eid*,而是直接调用MFHE. K eyGen(P P)生成 (pkid*,ski*d),其他与Game 4中相同。
接下来对以上实验进行分析, 令Si表示敌手 A在Gamei(0 ≤i≤5)中取得成功这一事件。
因Game 0是IND-sID-CPA安全性的原始实验, 故

Game 1与Game 0的唯一不同是在解密密钥查询阶段, Game 0中C用K回答A对 idi的查询, 而Game 1中用的是 K ( {i d*}),根据PPRF穿孔外的功能不变性, 可得对于任意idi≠id*, F(K,idi)=即这两个实验中的从而分别用作为随机串选取的 Ridi和 Eidi相等, 用 Ridi和 Eidi作为 M FHE. KeyGen的随机串生成的skidi相等, 故

Game 2与Game 1的不同有: (i)pkid*的生成位置和生成方式不同; (ii) 用来生成混淆方案H的程序不同。(i) Game 1中C在挑战阶段利用H生成pkid*,而Game 2中C在参数生成阶段直接利用 K , 因Game 1中生成H的程序 FMapPK是直接用K生成任意id对应的 p kid,根据不可区分混淆方案iO的正确性, 得对于 PPT敌手A,这两个实验中生成的pkid*相同, 且pkid*的生成位置不同对 A的猜测不会有任何影响;(ii) 根据PPRF穿孔外的功能不变性, 可得对于任意输入 id , FMapPK与MapPK的输出相同, 从而根据不可区分混淆方案iO的不可区分性, 得 A成功区分H ← iO ( 1λ,F )与H ← iO ( 1λ,)的概率可MapPK MapPK忽略, 设其概率为 εiO(λ),故

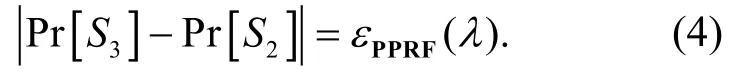

引理 1. 假设方案MFHE是 IND-CPA安全的,则敌手A在Game 5中的成功优势可忽略。
证明. 利用A构造攻击MFHE方案IND-CPA安全性的敌手 B : B收到自己的挑战者所发送的(PP, pk)和A提交的 i d*,令pkid*:=pk,调用利用PP,pkid*和K( {id*})作为参数构造程序FMapPK,将 m pk:= H 发送给 A .在解密查询阶段, B利用 K ( {i d*})生成解密密钥对A进行回答。在挑战阶段, 收到A发送的一对等长消息(μ0, μ1),B将其转发给自己的挑战者, 得到密文作为cid*发送给 A .在猜测阶段, 收到A发送的猜测b′,B将其作为自己的猜测发送给挑战者。

由MFHE方案的IND-CPA安全性, 得 εMFHE(λ)可忽略, 故A在Game 5中的成功优势可忽略。
综合式(1)-(7), 可得

4 全动态的多身份全同态加密方案
目前只有Brakerski和Perlman给出了全动态的MF HE方案[22], 现用该方案对第3节中的MIBFHE框架进行实例化, 因在此实例化中, 只有MIBFHE. Setup和 M IBFHE. KeyGen与框架中的相应算法不同, 故下面只给出这两个算法的描述。
设(B P.Setup, B P.KeyGen, B P.Enc, B P.Eval,BP.Dec)是Brakerski和Perlman的全动态MFHE方案, F :K × { 0,1}k→ℜ ×ℜ,
11SampleU1SampleE
F:K × { 0,1}k× [ (n + 1 )ℓ] → ℜ,
22qSampleU2
F:K ×{0,1}k×[m2(n+1)ℓ ]→ ℜ 是三个PPRF,
33qSampleU3
ℜSampleU1,ℜSampleE, ℜSampleU2,ℜSampleU3分别是概率算法SampleU1, S ampleE, S ampleU2, SampleU3的随机数空间。
-MIBFHE. S etup(1λ):
(q,n,m, χ,Bχ,B) ← BP. S etup(1λ),
K←F. K ey ( 1λ), K ←F. K ey(1λ),
1 1 2 2
K←F. K ey (1λ),令H为程序 F (见图3)的一个混
33PK
淆 iO (1λ,FPK),输出mpk:=H,
msk : =(A, K1,K2, K3),其中 m pk, msk中都隐含参数q, n, m,χ,Bχ.
-MIBFHE. K eyGen (msk,id∈{0,1}k):
(r1,1,r1,2):= F(K,id),
idid1 1
对于任意i∈ [ (n+ 1 )ℓ ],r2,i:= F(K,id,i),
qid22对于任意
j∈ [m2(n+ 1 )ℓ ],r3,j:= F(K,id,j),
qid3 3
:=SampleU1( ℤn,U;r1),e→ : = SampleE(ℤm,χ;r2),
qidid对任意
i∈[(n+1)ℓ ],R:= SampleU2( {0,1}m×m,U;r2,i),对
q1,iid任意
j∈ [m2],R:= SampleU3( {0,1}m×m, U ; r3,(i-1)m2+j),
2,i,jid
(p kid,s kid):=

输出 s kid.
因该方案的密文空间就是 BP方案的密文空间ℤn+1,故本方案的密文规模 O (nl o gq)远远小于 Canneti等人实例化方案的密文规模 O (n5lo g5q).
定理2. 若方案BP是IND-CPA安全的, iO是一个计算不可区分混淆方案, F是一个可穿孔的伪随机函数, 则方案MIBFHE是IND-sID-CPA安全的。
证明. 根据文献[22]中Lemma 4.1的证明和定理1的证明, 可得出该定理的证明。

图3 程序 F P K#Figure 3 Program FPK
5 总结
观察到Canetti等人的MIBFHE构造框架的不足:密文规模大和紧致性弱, 本文构造了密文规模较小和紧致性较强的 MIBFHE框架, 相比于前者用到MFHE和 IBE两种构件, 本文中的构造仅需 MFHE一个构件。若用Brakerski和Perlman的MFHE方案去实例化这两个框架 (Canetti等人的框架还需用基于DLWE假设的IBE方案), 可得Canetti等人实例化方案的密文规模为 O (n5log5q),而实例化我们框架所得方案的密文规模为 O ( n l ogq). 然而, 我们的方案只能实现选择安全性, 且用到了iO这一目前复杂性较高的工具, 故如何构造更高效的、密文规模较小的、适应性安全的 MIBFHE方案, 是我们将来要研究的问题。
猜你喜欢
黑龙江大学自然科学学报(2022年1期)2022-03-29
政工学刊(2021年2期)2021-11-26
计算机仿真(2021年10期)2021-11-19
吉首大学学报(自然科学版)(2020年2期)2020-09-14
五邑大学学报(自然科学版)(2020年1期)2020-06-17
佳木斯大学学报(自然科学版)(2020年2期)2020-05-18
沈阳工业大学学报(2020年2期)2020-04-11
佳木斯大学学报(自然科学版)(2020年1期)2020-02-28
阅读与作文(小学高年级版)(2019年2期)2019-03-27
通信技术(2016年10期)2016-11-12
