
基于LSTM网络模型的菜品销量预测
2018-10-13 07:58马超群王晓峰
现代计算机 2018年23期
马超群,王晓峰
(上海海事大学信息工程学院,上海 201306)
0 引言
近年来,由于大数据的兴起,使得我们的生活得到了很大的改善,大数据已经开始渗透到各行各业,传统企业也想搭乘大数据的顺风车,来为公司和企业带来科学的分析和指导。目前大多数餐饮企业还仅局限于传统的分析方法,有的企业则完全取决于管理人员的个人经验来进行决策。本文应某全国连锁火锅企业的要求,对近2年来的餐饮消费数据进行分析,以金针菇菜品为例,分析其潜在的数据价值,并对其销量进行预测。
目前对于餐饮领域还未对菜品的销量进行预测,本文通过阅读国内外文献,总结出在时间序列领域内预测模型的种类。所用的方法主要有自回归移动平均(ARIMA)、支持向量回归(SVR)、随机森林(XGBoot)等。时间序列是从数量上揭示某一现象的客观规律,分为围观层面和宏观层面,从一定角度揭示变化和时间之间的关系,从本质上发现其中的规律,挖掘其内在的信息。严宇宙使用ARIMA模型预测深圳市PM2.5浓度[1],Salim Lahmiri提出了使用SSA(奇异谱分析)和支持向量回归(SVR)以及粒子群优化(PSO)的股价预测模型[2]。得到了比单一模型更好的实验结果。然而,由于混合模型过于复杂、需要人为不断的调节,不利于在推广和使用。随着神经网络模型的发展,一些时序数据[3]也开始采用深度学习的技术来处理。循环神经网络(Recurrent Neural Network,RNN)[4]不同于 BP 和ANN,它在时序数据上表现较好,其他人工神经网络在进行学习时,假设输入输出之间相互独立,并没有考虑到序列中上下文之间的关系,这一点对时序数据来说,尤为重要。然而,这些复杂的神经网络设计又带来了自己的挑战。当监督学习被考虑并且实施反向传播以更新神经网络的连接的权重时,梯度消失和爆炸是成功训练循环神经网络的非常严重的障碍。为了弥补了RNN缺点,Sepp Hochreiter和 Jurgen Schmidhuber在1997年提出了长短期记忆模型(Long Short-Term Mem⁃ory,LSTM)[5]。LSTM是一种基于RNN神经网络的模型,用于处理长时间序列数据。相对于其他序列模型,LSTM能够解决长期依赖问题,其单元使用输入门、忘记门和输出门,采用门控系统来调整输出值,同时存储节点状态信息,并且可以通过每个门来添加和删除信息,也就是遗忘一部分状态信息。另外,由于每个门的操作由附加到单元状态的加法操作,所以避免了梯度消失的问题。由于近年来LSTM[6]在自然语言处理,语言翻译,生物基因和视频等领域取得显著的效果。在对餐饮数据分析后,决定采用LSTM模型对菜品销量这一时间序列进行预测研究。
1 相关理论和技术
1.1 RNN网络模型
循环神经网络(Recurrent Neural Networks,RNN)是机器学习中常用的非线性动态模型。在传统的神经网络模型中,往往假设其输入和输出是相互独立的。但是现实环境中往往二者之间却存在某种关系。假如你想预测句子中的下一个单词,应当知道哪些单词出现在它之前。RNN之所以被称之为循环是在于其对隐藏层之间进行了连接。图1表示了比较常见的RNN网络的架构图。

图1 RNN节点间关联

图2 RNN节点展开
RNN通常是全连通网络,其中连接权值为训练参数。一个简单的深层循环神经网络体系结构将隐藏状态向量排列在二维网格中,其中t=1,…,T是网络学习的总时间,l=1,…,L是网络的深度。图2为深度为2的简单RNN展开结构。对于原始nx维向量Xt输入,其ny维输出向量Yt则由下式子给出。


其中Wl是 nh×nh权重矩阵,Ul是 nh×nx权重矩阵,函数f(.)是隐藏层的激活函数,神经网络体系结构的核心组件之一。权重矩阵W模拟各种隐藏状态之间的基础动态连接。因此,潜在的非线性交互可以通过w隐藏状态在这个框架内建模,并从数据中提供值得注意的隐藏动态特性,并允许V参数适当地加权这些模式。使得递归神经网络在建模和预测变量之间的顺序关系时表现出很好的效果。
但是,RNN在实施反向传播以更新神经网络的连接的权重时,如果当前的输出与距离较远的时间序列有关,RNN将无法更新远距离数据对权值的影响。所以为解决此问题,就需要引入LSTM。
1.2 LSTM对RNN的改进
LSTM使用称为存储器单元的结构而不是RNN神经元。它结合了快速训练和高效学习任务,在试验期间需要连续短时记忆存储许多时间步骤[7]。其最大的改进就是添加了记忆单元(Memory Cell),它通过门控结构来控制历史信息更新和使用,分别是输入门(Input Gate)、遗忘门(Forget Gate)和输出门(Output Gate)。LSTM单元的基本结构如图3所示:

图3 LSTM单元结构
图3 中ht表示t时刻存储的信息,xt为t时刻的输入信息,tanh和R分别表示双曲正切函数和sigmoid函数。ct表示t时刻记忆细胞的计算方法,ctw为当前t时刻候选单元的状态信息。下面将分步介绍LSTM每个时间点的更新流程。
ft为遗忘门的输出值,其决定从存储单元中删除或遗忘一部分信息,中ht-1为上一时刻的输出值,xt为当前的输入值,W和b分别是系数组成的矩阵和偏置的向量,σ是激活函数sigmoid。
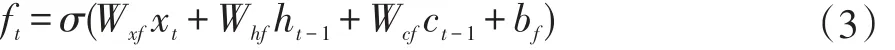
计算输入门的it值,用来决定更新多少信息,输出为0-1之间的某个值。

更新细胞状态,旧的细胞状态ct-1与遗忘门输出值ft相乘,输出更新的后选值表达式与输入门it相乘,二者相加得到新的细胞状态ct。
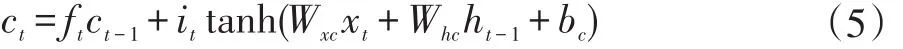
计算输出门output gate的值ot,它决定多大比例的记忆用于输出。

最后一步则是使用双曲正切函数更新Ct值,使其处于-1-1之间,最后将输出门值ot与其相乘,则得到t时刻的最终输出值ht:

2 实验分析
本节结合实际,通过对连锁火锅企业的消费数据进行清洗,处理成模型需要的数据格式,并通过Hyper⁃opt进行模型参数的选取,并指定相应的指标来对模型进行评测。实验软件环境为Windows,CPU:Intel Core i5 2.5GHz,8GB RAM,GPU:Intel HD Graphics 6100 1696M。
2.1 数据的选择
根据每天订单数据里的菜品销量,剔除退菜和异常数据值,将半份和份统一成以份为单位的数据。选取近两年来的金针菇销量数据,以日期为时间轴的时间序列作为输入。转化观察值使其处在特定区间。具体来说,就是将数据缩放带-1至1的区间内,以满足LSTM模型默认的双曲正切激活函数。

式中xmax和xmin分别为菜品销量的极大值和极小值。预测模型得到的预测数据为归一化数据,需要进行反归一化使其具有实际意义,反归一化计算公式为:

2.2 模型评价指标的选择
用来比较的两种模型都分别选取了表现最好的一组。为了衡量模型预测的准确率,使用平均绝对误差(MAE)和均方根误差(RMSE)来作为衡量模型效果好坏的指标。

其中,yi和 fi分别为销量时间序列在第i天的销量值和模型预测值,N为天数。
2.3 LSTM预测模型
基于TensorFlow和Keras深度学习框架来搭建本实验所需模型。由于本实验数据采用单一变量,数据为两年半菜品的销量数据,所以可以使用经典的三层网络模型结构。模型的第一层为输入层,输入单元为单个日期的菜品销量值,输入层的单元数由Hyperopt自动调参优化模型选取,依照经验,一般对于三层的网络模型,隐含层的单元数为输入层单元数的两倍,即输入单元为50,隐含层单元为100。最后一层为输出层。
为了防止模型出现过拟合,增强模型的拟合能力,对输入层和隐含层添加dropout,当数据量较少时,drop⁃out的系数值可以相应的减少,过大则使得节点向量过于稀疏,不利于获取数据的特征。在该模型中设置dropout为0.1。为了防止梯度爆炸等问题,在隐含层添加激活函数,激活函数的选取需要根据模型的收敛速度和预测效果的好坏来选取,LSTM处理时序问题时,一般采用MSE均方误差来作为其损失函数。优化方法采用随机梯度下降法(SGD)的改进方法RMSprop。学习率设置为0.002,过大则会出现loss值一直震荡,且不会收敛。模型训练batch size的选取则采用自动调参工具Hyperopt中的模拟退火算法(Simulated An⁃nealing)得出。将数据归一化为-1到1区间内的数,每5条数据分为一组训练数据,后一条数据为预测数据。模型训练100次,得以下结果(图4)。
由图4可以看出,LSTM模型很好地拟合了销量数据的周期性,且经过归一化数据还原后,能够清楚的看到预测结果与原始值之间的差异,该模型能够很好地判断数据地起伏趋势,为了突出该模型的优点,将该模型与RNN和ARIMA模型进行对比,RNN模型采用三层网络架构,部分参数和LSTM模型相同,ARIMA模型采用自适应参数调节。表1显示了模型预测误差值,图5和图6为模型预测图。从上图可以看出RNN模型能够体现出数据的周期性,但是由于RNN存在结点记忆快速衰减的特点,使得其精度有所降低。ARIMA预测模型则只能大致的拟合出周期趋势,预测结果劣于前两个模型。
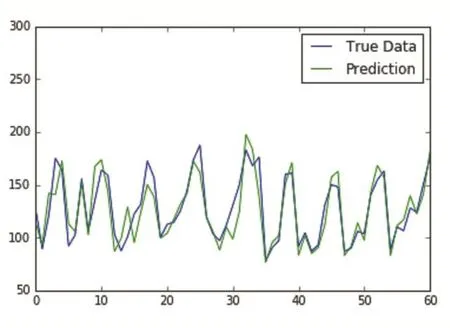
图4 LSTM模型预测结果
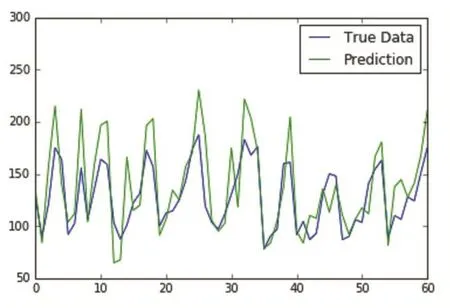
图5 RNN模型预测结果

图6 ARIMA模型预测结果

表1 模型预测统计分析结果
3 结语
本文通过对餐饮数据的处理和分析,针对菜品销量非线性、变化波动等特点,采取了适用于此类问题的LSTM模型;相对于RNN和传统的时间序列分析模型ARIMA取得了很好的预测效果。现阶段采用的仅是单一变量预测菜品销量,后期可以加入季节、温度、节假日等多因素预测销量,进一步提高该模型的预测精度,这也将成为我们下一步的研究目标。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
食品安全导刊(2021年30期)2021-11-28
当代水产(2021年7期)2021-11-04
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
意林·少年版(2020年20期)2020-11-06
汽车观察(2019年2期)2019-03-15
烹调知识(2017年6期)2017-06-16
汽车与驾驶维修(汽车版)(2017年2期)2017-03-18
高中生学习·高三版(2016年9期)2016-05-14
家用汽车(2016年4期)2016-02-28
