
论OT语法的初始状态
2018-10-12 03:45:52秦川
外语学刊 2018年2期
秦 川
(香港浸会大学,香港999077)
提 要:优选论研究界对一语习得的初始语法有3种观点:(1)初始排序为M>>F;(2)初始排序为F>>M;(3)初始阶段制约条件无排序,其中以前两种观点间的交锋最为激烈。本文分别从理论可学性和实证性的角度回顾和剖析各家观点,确认M>>F的主张,并指出对M>>F排序最有力的证明来自于实证观测到的儿童语言。为了从超音段习得的角度检验M>>F的假说,基于前人研究,本文探讨儿童对汉语普通话声调的习得,结果同样印证M>>F的观点。最后,本文进一步讨论关于M>>F排序本身的相关问题,并指出未来研究的方向。
1 引言
优选论(Optimality Theory,简称 OT)(Prince,Smolensky 1993/2004)已被广泛应用于语言习得研究。一方面,OT被用来解释儿童语言习得的各类现象;另一方面,各种验证OT语法可学性的习得推演算法(learning algorithms)也相继问世。无论研究的侧重点是什么,OT中习得的实质始终是个体语法系统的演变。既然是演变,自然会有如下问题:一语习得中语法演变的起点是什么?本文将围绕这一问题展开。
2 习得中的初始排序
OT语法包含一系列制约条件,制约条件来源于普遍语法,不同语言间的区别在于制约条件的不同排序,因此学习者的一大任务就是构建起符合目标语的制约条件排序。具体而言,当学习者接触到的显性形式(即实际观察到的成人语言形式)与自身语法生成的形式不符时,制约条件会被重新排序,这就是OT的错误驱动(error⁃driven)学习。
对于重新排序的形式,影响力较大的是Tesar和 Smolensky(2000)制约条件降级的主张,Boers⁃ma和Hayes(2001)则认为升级与降级同样重要。升级也好,降级也罢,我们都要明确重新排序的起点和终点。在一语习得中,终点通常是成人语法排序,可作为起点的儿童语法初始排序就没那么明确。但出于3方面的原因,我们有必要弄清初始排序:
第一,从语法设计来看,合理的语法体系必须是可学的。OT要成为可学的语法①,必须让儿童仅靠显性形式就能在有限时间内从初始状态达到目标排序。若假定了一个错误的初始状态,目标排序可能永远也无法达到。因此,初始排序是OT理论体系里的重要一环。
第二,OT根植于普遍语法,初始排序对不同语言背景的儿童都是一样的。在Chomsky(1986:3)看来,普遍语法正是语言机制(language faculty)的初始状态。换言之,儿童的初始语法最接近普遍语法的预设值。若能弄清OT语法的初始排序,我们对普遍语法本质的认识将更进一步。
第三,就习得研究而言,只有弄清儿童的初始语法,才能完整地把握儿童语言发展的轨迹。
由于OT语法表现为标记性制约条件(简称M制约条件)和忠实性制约条件(简称F制约条件)的相对排列,因此学界对初始排序有过3种主张:(1)两类制约条件无排序(unranked);(2)M 制约条件高于F制约条件(M >>F);(3)F制约条件高于M制约条件(F>>M)。本文将回顾和剖析这些主张,并指出M>>F的初始排序最能准确反映儿童语言发展的规律。
3 早期的可学性模型:M与F无排序
针对OT语法的可学性问题,Tesar和Smolen⁃sky(1993)提出制约降级算法(Constraint Demotion Algorithm)。根据他们的观点,在初始阶段所有制约条件都位于同一层级(stratum),随着儿童开始接触目标语的显性形式,显性形式所违反的制约条件会被逐步降级,直至达到目标语的排序为止。其降级过程可演示如下②:
第一阶段:{C1, C2, C3}
第二阶段:{C1} >> {C2, C3}
第三阶段:{C1} >> {C2} >> {C3}
在以上过程中,被降级的制约条件会形成新的层级,其结果是符合语法的形式在总体上逐渐减少:第一阶段的语法会因所有制约条件位于同一层级而接受多个互为平手的表层形式;在第二阶段,语法只青睐不违反C1的表层形式;制约条件在第三阶段达到完全排序,这时只有一个候选项能胜出。针对无排序的初始阶段,Tesar和Smolensky(1993)认为,语言习得应遵循母集原则(Superset Principle):初期语法是后期语法的母集,即初期涵盖后期的可接受形式。但Tesar和Smolensky并未明确说明习得为何要遵循母集原则,母集原则也仅能视为对所提出算法的一种描述。另外,若初始语法是完全无排序的,各种表层形式应有均等的机会出现在儿童语言中,儿童语言应是随机的,无规律的。但恰恰相反,儿童语言及其发展路径呈现显著的规律性(详见4.2节),这显然是无排序初始阶段无法解释的。
4 支持M>>F的观点
4.1 M >>F:可学性角度
Tesar和Smolensy(2000)对之前提出的制约降级算法进行修正,认为习得应始于M>>F的排序③。该排序可接受的表层形式最少,是局限性最强的子集(subset)语法。促使Tesar和Smolen⁃sky做出这一修正的是语言学习中的子集问题(subset problem):当学习者处于母集语法时,仅靠显性形式无法学到子集语法。这是因为母集包含子集语法可接受的所有形式,符合子集语法的显性形式同样也符合母集语法,因此不会产生可驱动学习的错误,学习者自然不会改变当前的母集语法(Kager et al.2004:42)。
但根据OT的基础丰富性原则(Richness of the Base),子集语法又是必须要掌握的。OT可以允许数量无限的输入项,但这些输入项往往只有一小部分能在表层形式中被忠实体现,这就需要子集语法对可能出现的输出项加以限制。事实上,子集语法也确实存在于人们的语法知识中,McCarthy(2002:205)就给出一个例子。尽管英语中并没有显性形式能直接表明由“塞音+鼻音”组成的词首辅音丛(如[kn])是不可接受的,但英语母语者通常知道这类辅音丛是不合语法的。另一些语言却可以接受“塞音+鼻音”辅音丛,如德语中就存在[kni]“膝盖”。在此英语显然需要一个M>>F的子集语法,德语则是F>>M的母集语法,见表1④。
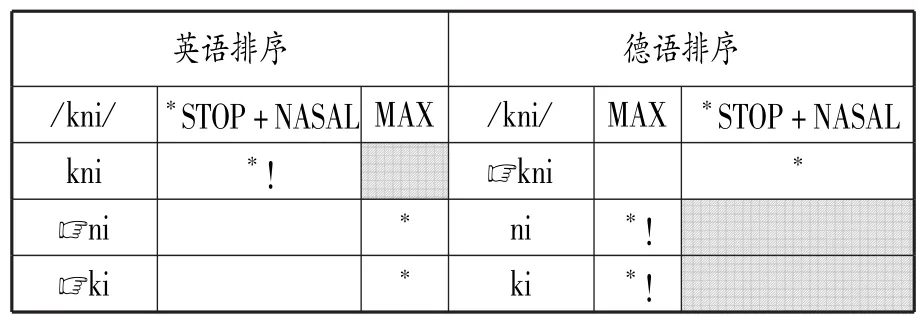
表1 底层形式/kni/在英语及德语中的OT评估表
一方面,儿童须要习得子集语法;另一方面,仅靠显性形式无法从母集语法达到子集语法,而在自然的习得环境中,儿童很难通过大量的反面证据来获知怎样的形式不被允许。要解决这一难题,Smo⁃lensky(1996b),Tesar和 Smolensy(2000)提出的方案是预设一个M>>F的初始状态,使习得始于子集语法。在M>>F的排序下,语法仅能接受非标记的形式,当学习者接触到标记的显性形式时,M制约条件会被降级,直至达到目标语的F>>M状态;若学习者接触的都是非标记的显性形式,制约条件排序会维持在最初的M>>F状态。这样一来,无论是子集语法还是母集语法都将是可学的。
M >>F的初始排序正与 Berwick(1985:37)提出的子集原则(Subset Principle)相一致:当学习者接触到的语料同时符合母集和子集语法时,要尽量选择子集语法。Prince和 Tesar(2004:263)指出,M>>F不仅出现在初始语法中,还是贯穿于习得全过程的一种倾向,是学习者遵循子集原则的结果。无论在哪一习得阶段学习者都应把F制约条件尽量维持在排序底端,初始阶段自然也不例外。
须要指出的是,基于可学性的M>>F主张实质上是一种虚拟假设,目的是为了方便语法运算。该假设正确与否,还有赖于实证的检验。
4.2 M >>F:实证性角度
通过实证研究,学者发现儿童语言中M>>F的例证。 Levelt和 van de Vijver(2004:209)观测不同音节类型在荷兰儿童语言中的出现顺序,总结如下:
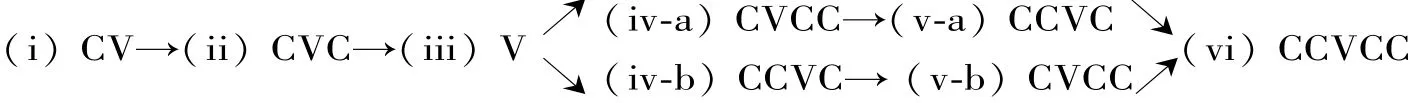
图1 荷兰儿童的音节习得顺序⑤
Levelt和 van de Vijver(同上)认为,这一习得顺序可用以下制约条件解释:
ONSET:音节必须有首音。
NOCODA:音节不能有尾音。
∗COMPLEXONSET:音节不能有复杂首音。
∗COMPLEXCODA:音节不能有复杂尾音。
FAITH:输出项与输入项一致⑥。
在图1中,阶段(i)的CV标记性最低,当上述M 制约条件(即 ONSET,NOCODA,∗COMPLEXON⁃SET,∗COMPLEXCODA)都位于 FAITH 之上时,CV是唯一被允许的音节。随后的习得可用M制约条件的降级来解释,每当有新的音节类型出现,一个M制约条件就会被降级。当儿童达到阶段(vi)时,荷兰语中所有的音节类型都已出现,儿童也达到荷兰语的目标排序:{FAITH >>ONSET,NOCODA,∗COMPLEXONSET,∗COMPLEXCODA}。 这一由非标记到标记的音节出现顺序也验证M>>F的初始排序。儿童对复杂音节结构的简化在Fik⁃kert(1994)和 Gnanadesikan(2004)的研究中均有记录,这些研究都表明NOCODA,∗COMPLEXON⁃SET和∗COMPLEXCODA等M制约条件在儿童语法中的高排序。
M>>F排序在儿童对语音配列的习得中也有体现。 根据 Fikkert(1994:57 -59),习得早期的儿童倾向于用塞音作为音节首音。Kager等(2004:37)认为,这种倾向可用首音响度制约条件(Gna⁃nadesikan 2004:81)来解释,如下所示:
μ/a >> μ/e,o >> μ/i,u >> μ/r,l >> μ/m,n >> μ/v,z >> μ/f,s >> μ/b,d >> μ/p,t
上述的“μ/a”表示音段 a应为莫拉(Mora),而以上的排序可理解为响度最高的a最应该为莫拉,而响度最低的p和t最不适合成为莫拉。换言之,当非莫拉位置(如首音)需要某个音段来填充时,塞音p和t将是标记性最低的选择。儿童用塞音来取代其他的发音方式,表明首音响度制约条件的排序高于要求底层特征不变的F制约条件IDENT.
Davidson等(2004)通过儿童对语言的感知实证为M>>F提供依据。Davidson等的感知实验采用转头范式(Headturn Preference Procedure)⑦,其理论假设为:婴儿会听到由3个刺激(stimulus)组成的一组录音{X,Y,XY},其中 XY可被认为是由底层形式X和Y组成的表层形式;若XY越符合婴儿当前的语法,他们对XY的注意时间会越长。Davidson等对比4、5个月大的婴儿对以下两组不同刺激的反应:
组别 1:{on...pa...ompa}
组别 2:{on...pa...onpa}
组别1的ompa产生发音部位同化;而组别2中onpa忠实保留on和pa的发音部位。ompa中的同化现象可归结于M制约条件MNASALPL:鼻音应与随后相邻的辅音发音部位相同。当MNASALPL排序高于F制约条件时,ompa和谐度更高;反之,onpa更合语法。结果显示大多数婴儿对组别1的注意时间更长,这也支持M>>F的初始排序。由于实验中的婴儿尚未具备语言产出能力,这一阶段的儿童语法也许更能揭示语法的最初状态。
4.3 M>>F:产出与感知的不对称性
儿童语言的一大特点是其在产出(produc⁃tion)与感知(perception)上的不对称性——儿童无法精确地产出目标语言形式,却可以精确地感知语言(Menn, Matthei 1992)。 Smolensky(1996a)指出,只需将初始排序设定为M>>F便可解释这一不对称性。
Smolensky(1996a)认为,精确的感知和不精确的产出都源于同一套语法,他们之间的区别在于语法评估中竞争候选项的不同。在产出语法中,已知某一输入项,评估装置会选出最和谐的候选输出项;在感知语法中,已知某一输出项,评估装置需要从众多候选输入项中选出最合语法的一个⑧。当处于M>>F排序时,在产出语法中胜出的是标记性最低的候选输出项。在感知语法中,由于M制约条件只负责评估输出项,而输出项已经给出,无论候选输入项是什么,M制约条件早已被已知的输出项违反。因此,筛选最优输入项的任务就落在F制约条件上,最忠实于输出项的候选输入项将会胜出。
以表2为例,尽管在M>>F排序的作用下,儿童产出的表层形式[ta]偏离目标语形式[tat],但当儿童听到目标形式[tat]时,感知语法总能忠实地将[tat]理解为正确的底层形式/tat/。
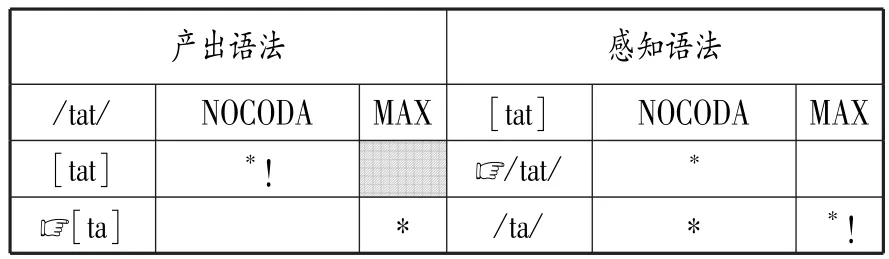
表2 儿童对/tat/及[tat]的产出和感知
5 支持F>>M的观点
5.1 F>>M:从底层形式习得出发
Hale 和 Reiss(1998)质疑 Smolensky(1996a)的算法(见4.3),并提出 F>>M 的初始排序。 Hale和Reiss指出,当语言中存在中和(neutralization)时,Smolensky的算法无法将表层形式引导向正确的底层形式。在中和现象中,存在于底层的音位对立会在表层消失,如德语的尾音清化现象:/rat/→[rat]“建议”;/rad/→[rat]“车轮”。 由于“建议”和“车轮”两词在表层均为[rat],根据Smolensky的观点,听者会将两词同时理解为/rat/,而无法将“车轮”一词理解为其底层形式/rad/。
Hale和Reiss认为,Smolensky仅能为表层形式匹配一个底层形式,假若听者能将表层形式与一组底层形式集合相匹配(如将[rat]同时匹配/rat/和/rad/),中和问题将迎刃而解。 为此,Hale和Reiss为语言感知提出以下算法:
(1)当听到某一表层形式Φ,听者会为Φ设立一组底层形式集合Ψ,首先确定的集合成员为Φ本身,即Ψ={Φ}。
(2)根据制约条件排序由高到低逐条进行计算;
(3)当遇到关于某一特征G的F制约条件时,集合Ψ会被“锁定”:不许再有就G而言与现有成员不同的新成员加入。
(4)当遇到某一M制约条件MX时,集合Ψ会被“扩大”:若现有集合成员没有违反MX,在Ψ中加入一个新成员,新成员与现有成员的唯一不同是违反Mx.
(5)当余下的M制约条件不高于任何F制约条件时,计算完成。现有集合Ψ即为Φ的所有可能底层形式。
当F>>M时,底层形式集合会在扩大前被F制约条件锁定;当M>>F时,集合会在锁定前被M制约条件扩大。在德语中,要求阻塞尾音清化的M制约条件NOVOICEDOBSCODA排序高于IDENT,当听到[rat]时,除/rat/本身,集合中还会加入违反NOVOICEDOBSCODA的底层形式/rad/;英语的排序是IDENT>>NOVOICEDOBSCODA,底层形式集合在被NOVOICEDOBSCODA扩大前就已被IDENT锁定,听者自然不会把[rat]理解为/rad/。
Hale和Reiss进一步指出,若以上算法是解决中和问题的最佳途径,初始排序必须为F>>M.在M>>F的初始语法下,此算法将无法为学习者构建起正确的底层词库,表3以德语为例对此进行说明。
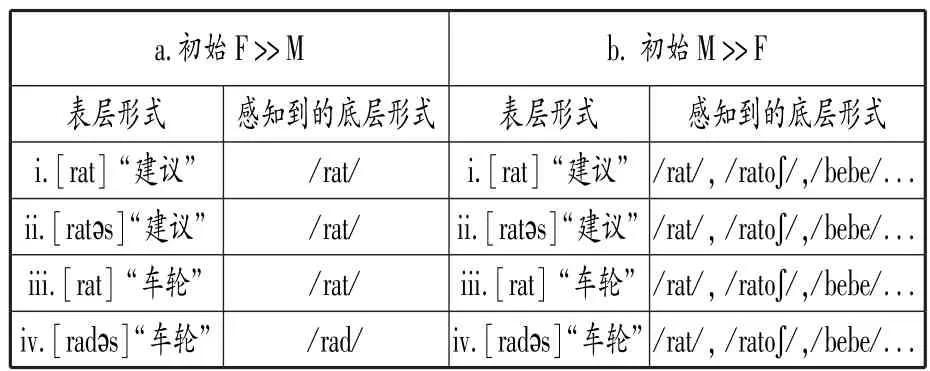
表3 两种不同语法下学习者对德语的感知
[⁃əs]为单数属格后缀,当其出现时,原本中和的/rad/在[radəs]中忠实呈现(见表3⁃a⁃iv)。 如表3⁃b所示,当M>>F时,在感知语法中首先起效的是M制约条件,所有违反M制约条件的输入项都将被加入底层形式集合,处于排序底端的F制约条件再也无法锁定已被无限扩大的底层形式集合。因此,听者会把一个表层形式与众多不相关的底层形式(如/rat/,/ratoʃ/,/bebe/)相匹配,而这显然与事实不符,在此情况下底层词库也无法被习得。当初始排序为 F >> M 时,除了表3⁃a⁃iii中的[rat]无法被正确理解为/rad/外,其余的表层形式均被正确感知。Hale 和 Reiss 认 为, 解 决 表3⁃a⁃iii的 关 键 在 于 后 缀[⁃əs],通过[radəs]与[rat]之间的交替,学习者最终确定表3⁃a⁃iii与表3⁃a⁃iv共享同一底层词干 /rad /。
事实上,表3的例子并未显示出Hale和Reiss的算法有什么高明之处。在F>>M的初始排序下,该算法只能将表示“车轮”的[rat]理解为/rat/本身而不是由/rat/和/rad/组成的集合。 要依靠交替现象,学习者才能把[rat]和/rad/联系起来。根据 Smolensky (1996a)的算法,除[radəs]会被理解为/rad/外,表3⁃a中其余的表层形式均会被感知为/rat/,这实际上与Hale和Reiss的算法无异。通过替换现象,Smolensky同样能为“车轮”一词构建起底层形式/rad/。
即便在德语的NOVOICEDOBSCODA>>IDENT排序下,Hale和Reiss的算法也存在问题。诚然,表示“车轮”的[rat]会与正确的底层形式/rad/联系起来,但听者是否同样会将原本就应为/rat/的[rat](表“建议”)误解为/rad/呢? 若如此,Hale和Reiss无非是在解决旧问题的同时又带来新问题。这一误解问题在其他场合会被放大,如依照表1中的英文排序∗STOP+NASAL>>MAX,当英语母语者听到表层形式[ni]时,根据Hale和Reiss的算法,[ni]将会被理解为底层形式/kni/,但在现实中这几乎不可能发生。此外,在F>>M的初始排序下,Hale和Reiss(1998)将儿童产出的非标记语言完全归结于语言运用(perfor⁃mance)(Chomsky 1965:4),这样的处理多少有些绝对化,弱化语法的解释作用。Fikkert和de Hoop(2009:319)也指出,基于语言运用的解释既不适用于句法领域,也无法说明儿童语言的系统性。
5.2 F >>M:从儿童语言出发
Fikkert和Levelt(2008)在荷兰儿童的语言习得中发现“忠实→非忠实→忠实”的U形发展过程,认为M>>F初始排序无法解释U形发展。
在儿童早期产出的语言中,同一单词内的辅音往往发音部位相同,如成人形式[bed]在儿童形式中变为[dət],其中[d]和[t]皆为舌尖音。在Fikkert和Levelt看来,该阶段的儿童尚未对辅音的发音部位特征进行赋值,整个单词中唯一赋值的是元音的发音部位⑨,儿童会将元音的赋值应用于整个词,因而产生诸如[dɛt]的形式([e],[ɛ],[d],[t]皆为舌尖音)。 因此[bed]变为[dɛt]的过程可理解为整个词忠实于元音的发音部位。
在下一阶段,辅音发音部位开始被赋值,部位不同的辅音也逐渐出现在同一个词中(如[plk])。然而,在上一阶段忠实于成人形式的发音在这一阶段却开始偏离,如荷兰语单词koek(饼干)在初始阶段发成[kuk](3个音段皆为舌根音),在本阶段却变为[touk]。Fikkert和Levelt认为这是忠实性的倒退,并且是M>>F的初始排序无法解释的,因为M制约条件的降级应使儿童越发忠实于成人形式。Fikkert和Levelt指出导致忠实性倒退的是禁止词首舌根音的 M制约条件∗[DORSAL,而∗[DORSAL源自儿童对目标语词汇频率的总结:在儿向语言(child directed speech)里词首舌根音的比例远低于舌尖音和唇音,儿童会将这一分布趋势加以概括并形成∗[DORSAL。∗[DORSAL进入语法后会位于F制约条件之上,从而使koek被实现为[touk]。
根据Fikkert和Levelt的分析,U形发展反映的是F>>M的初始语法,M>>F只是由词汇学习引发的一个中间状态。然而,他们的分析存在问题。首先,初始阶段的语言并非完全忠实于元音的发音部位。 根据 Fikkert和 Levelt(2008:253, 264)提供的数据,首阶段的儿童同样会产出与元音发音部位不同的辅音,如有的词以“舌根辅音+舌尖元音+舌根辅音”的组合形式存在(如[klk]);另一些词出现辅音之间部位不同的情况,如“唇辅音+舌尖元音+舌尖辅音”。
这些反例对Fikkert和Levelt的观点形成质疑:整个单词是否真的忠实于元音的赋值?如将这些反例理解为儿童忠实于原音段(包括元音和辅音)的发音部位赋值,Fikkert和Levelt又凭何认为其他词(如[dɛt])中的辅音未赋值呢?若无法解释这些反例,初始阶段的语言很难被视作忠实性的反映。其次,依照Fikkert和Levelt的分析,首阶段的忠实性其实是对元音发音部位的忠实(而非辅音)。然而阶段二中的[touk]和成人形式[kuk]的元音皆为舌根音,并未发生忠实性倒退,而成人与儿童间的辅音差异([k]和[t])也不属于这一倒退范畴。另外,∗[DORSAL这样的M制约条件本身也值得怀疑,它们仅来源于儿童对某一阶段接触到的词汇的概括,既没有类型学事实依据,也缺乏生理基础。随着儿童接触的词汇进一步增多,这类制约条件会被降级,抑或从语法中消失?Fikkert和Levelt未给出进一步解释。
6 比较分析
在数量和论证角度上,支持M>>F初始排序的观点始终是主流,而通过对Hale和Reiss(1998),Fikkert和Levelt(2008)的分析不难发现,F >>M 的观点并不可取。因此,本文进一步证实M>>F的主流观点。尽管如此,支持M>>F的论述仍存在一些值得商榷之处。
根据Tesar和 Smolensky(2000)从可学性出发的论述,语法学习靠的是由显性形式引起的M制约条件降级,我们可以做出如下假设:从M>>F排序转变为F>>M是可行的,但从F>>M转变为M>>F理论上行不通。可在Trapman和Kager(2009)对二语习得的研究中,母语语法为F>>M的学习者却能成功习得排序为M>>F的目标语法。对Trapman和Kager的实验结果有两种可能的解读:(1)子集语法的可学性问题根本就不成立,显性形式同样能带来F制约条件的降级;(2)由于二语习得涉及到更多的显性教学,学习者会接触到更多的反面证据,这些反面证据会带动F制约条件的降级。究竟那一种解读正确还有待进一步的研究来证明。若解读(1)正确,儿童初始语法当然也有可能是介于M>>F和F>>M之间的某种中间状态,类似于成人的二语初始语法。
Smolensky(1996a)预测儿童非标记的语言产出及忠实的感知。但Pater(2004)指出,早期的语言感知并非完全如Smolensky所预测的那般准确无误,如Jusczyk等(1999)曾记录儿童无法正确感知语音的现象。Pater认为,语法中应存在两组F制约条件,一组负责语言产出,另一组负责语言感知,两组F制约条件与同一组M制约条件相互作用(Pater 2004:230)。根据Pater的观点,初始排序应为{M >> F感知, F产出},而 Smolensky(1996a) 反映的其实是随后的{F感知>> M >>F产出}。无论Smolensky与Pater哪一方正确,他们的观点在本质上体现的都是M>>F的初始排序。
相比以上角度,对M>>F排序最无可争议的证据来自儿童的非标记语言。从习得顺序来看,儿童语言普遍遵循的是一条由非标记到标记的发展路径;若儿童语言里出现非忠实的表层形式,表层形式的标记性往往低于其底层形式。在F>>M或无排序的初始语法下,我们很难解释为何儿童语言中最早出现的是CV音节,也无法解释为何儿童首先掌握的音节首音是塞音。
7 从汉语声调习得看OT初始语法
诚然,儿童的习得实证是对初始语法最有力的证明,但前人的研究集中于英语、荷兰语等非声调语言,考察的通常是音段或音节的习得,对声调等超音段的习得却很少考虑⑩。汉语作为声调语言,儿童对汉语声调的习得恰巧能填补这一理论空白,为初始语法提供进一步的依据。为此,本文将从OT语法的角度来重新审视前人的实证研究。
基于发音难度,Yip(2001:315)将不同声调的标记性归结如下:
(1)曲折调的标记性高于平调:∗CONTOUR
(1)升调的标记性高于降调:∗RISE>>∗FALL
(3)高调的标记性高于低调:∗H>>∗L
以上的M制约条件可反映为一组固定排序,即∗RISE>>∗FALL>>∗H >>∗L.根据以上制约条件,汉语普通话的第三声(降升调)涉及到两组曲折调,标记性理应最高;第二声(升调)和第四声(降调)虽然同为曲折调,但第二声的标记性高于第四声;第一声为高平调,标记性最低。根据M>>F的初始语法,排序越低的M制约条件应越早遭到降级,标记性越低的声调也理应越早出现在儿童语言中,我们可以为普通话预期这样的习得顺序:高平调→降调→升调→降升调。
儿童语言习得是否也遵循同样的发展路径呢?本文将以Zhu(2002:78-105)的历时研究为例讨论这一问题。Zhu记录4名北京儿童从一岁至两岁期间对普通话声调的习得,普通话四声调分别于以下时间出现在这4名儿童的语言中:

表4 北京儿童对普通话声调的习得顺序⑪
高平调与降调在同一时间出现,是出现最早的声调;升调紧随其后,其于一个月后出现在两名儿童的语言中,另两名儿童则在同一时期开始掌握一、二、四声;对所有4名儿童而言,最晚出现的声调均是降升调。因此,Zhu的声调习得顺序大致可总结为“高平调、降调→升调→降升调”。这一顺序基本符合M>>F的预期,但仍有一处不同:高平调的出现并未早于降调。然而,Zhu(2002)提供的另一组数据显示这一预测仍然适用,表5显示这4名儿童第一声和第四声的发音正确率达到66.7%的时间。
高平调正确率达到66.7%(即Zhu指的稳定期)的时间普遍早于降调,这也反映出降调确实对儿童构成更大的习得困难。另一个支持“高平调→降调”顺序的证据来自Li和Thompson的普通话母语习得研究,他们(1977:191)着重描述习得初期的一个有趣现象:曲折调极少出现,除少数例外,多数曲折调被发成平调,见表6⑫。
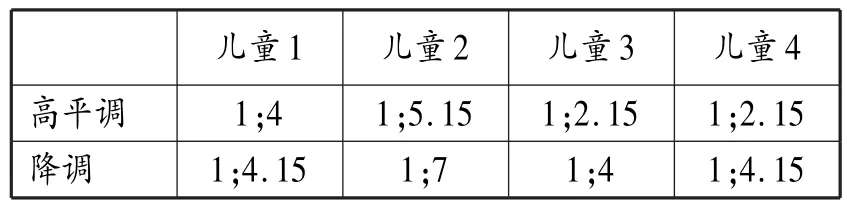
表5 儿童一、四声发音正确率达到66.7%的时间
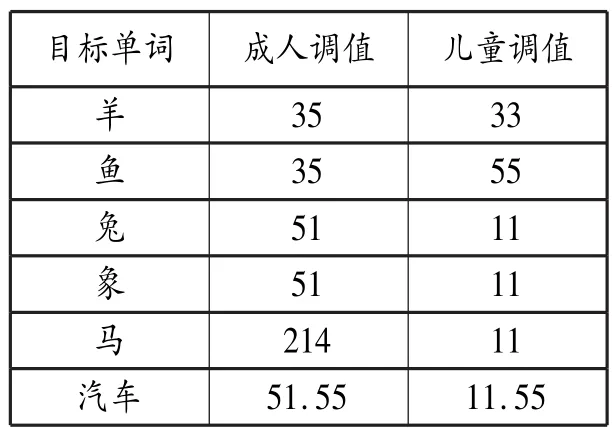
表6 儿童对曲折调的发音
表6中“羊”和“鱼”的升调分别变成中平调33和高平调 55;“兔”、“象”和“汽车”的“汽”均由降调变为低平调11,而“车”字原本的高平调维持不变。儿童对平调的偏爱表明平调的习得应早于曲折调,与M>>F的预期相符。值得注意的是,“兔”和“象”并非是直接变为普通话业已存在的高平调,而是变成低平调11。考虑到∗H>>∗L的标记性排序,低平调的出现应能等到解释——降调变成标记性更低的低平调。低平调的意外出现也恰巧反映OT中的“非标记产生”现象(the emer⁃gence of the unmarked)(McCarthy, Prince 1994),进一步支持M>>F的初始排序。事实上,M>>F的初始排序在其他汉语方言的声调习得中也有体现,例如Tse(1978)记录儿童对粤语声调的习得,结果同样显示平调的出现早于曲折调,降调早于升调⑬。
8 M>>F排序的进一步问题
不管论证的出发点是什么,绝对的M>>F排序本身也有待进一步探讨。OT语法中存在一类固定排序的M制约条件,Prince和Smolensky(1993/2004:141)给出以下例子:
(1) 音节首尾和谐度:∗a >>∗i >> ...>>∗d>>∗t
(2) 音节峰和谐度:∗t >>∗d >>...>>∗i >>∗a
上面的(1)表示在音节首尾(margin)位置,音段a的接受度最低,i次之,t最高;(2)表示在音节峰(peak)位置音段的接受度恰好相反。然而,(1)和(2)的制约条件会被任何表层音节违反:任何首音和尾音都违反(1),任何音节峰都违反(2)。在绝对的M>>F排序下,优选项会将底层音段统统删除,这是因为若表层无任何音段,对(1)和(2)的违反也就无从谈起,付出的代价仅仅是违反低排序的F制约条件MAX.由于固定排序的M制约条件,M>>F初始排序将导致语法无法生成任何表层形式,其结果为儿童没有语言产出。对于M>>F是否仍然正确,存在两种可能。
第一,以儿童产出的首个有意义的单词为界,若儿童之前发出的咿呀、咕咕等声是受语法支配的语言,M>>F初始排序将无法自圆其说,因为M>>F预测的是儿童如哑巴一般什么都不说。但根据Stager和Werker(1997)的儿童感知研究,早期的儿童似乎很难将听到的语音与其意义联系起来,若儿童无法在声音及意义之间建立联系,我们当然不能把咿呀、咕咕等视为有意义的语言,因此该可能不成立。
第二,若儿童首词之前的咿呀学语是无意义的语言,M>>F的初始排序仍能说得通,因为咿呀、咕咕根本不是语法的产物,与生成零表层形式的语法并不冲突。但照此理,当儿童说出首个有意义的单词时,他们的语法已不是绝对意义上的M>>F,某些M制约条件已经受到降级。尽管M>>F排序下的语言系统是极其简单的,但这一简单的习得起点恰恰反映儿童语言从无到有,从简单到复杂的蜕变过程。
以上的论述还回答Fikkert和de Hoop(2009:319)提出的初始语法的改变究竟是发生在首词前还是首词后的问题——当儿童开始说出首个单词时,初始语法已经改变;在真正的初始语法下,儿童其实并不具备语言产出能力。既然真正的初始语法存在于首词之前,我们就要在未来的研究中获取尽可能早期的儿童语言证据。显然,Da⁃vidson等(2004)采用的转头范式为将来的研究提供一个可借鉴的模板。
除儿童语言外,我们还可以从其他领域寻找初始语法的证据,这里值得一提的是二语习得和借词。一些在一语显现不出作用的M制约条件在二语会变得至关重要,通过观察这些M制约条件在学习者语言中的排序,我们可以获知它们在初始语法的位置。例如Broselow,Chen和 Wang(1998)探究普通话母语者学习英语时的尾音清化现象,并将此分析为NOVOICEDOBSCODA位于F制约条件之上。但普通话中并没有阻塞尾音,自然也不存在提升NO⁃VOICEDOBSCODA的语法过程,因此NOVOICEDOB⁃SCODA的高排序只能源自M>>F初始语法。类似的,Shinohara(2004)和 Davidson 等(2004)对借词的研究也为M>>F初始排序提供支持。
9 结语
本文回顾和分析对OT语法初始状态的各家观点,鉴于F>>M初始排序在解释力上的不足,本文进一步证实M>>F的主流观点,同时认为对M>>F排序最具说服力的证据来自儿童早期的语言产出及感知。有鉴于此,本文从汉语声调习得的角度进一步探究这一问题,结果显示超音段习得同样也遵循M>>F的初始排序。作为OT语法的重要一环,M>>F的初始排序对我们把握语言习得及普遍语法的本质具有重要意义。由于汉语与西方语言分属不同语系,有诸多不同,通过考察儿童对汉语的习得,我们能为初始语法研究提供更多新的信息,这也是我们中国学者能为理论界做出贡献的一个方向。
注释
①关于OT语法可学性的论述,参见马秋武(2003)。
②C1,C2,C3等指代不同的制约条件。
③近年来,新的可学性算法相继问世(如Boersma 2009,Tesar 2012),但这些算法并未过多提及初始排序问题,此处不做讨论。
④M制约条件∗STOP+NASAL阻止“塞音+鼻音”的辅音丛;F制约条件MAX要求输出项保留输入项的音段。
⑤图1中的 C 表示辅音,V 表示元音。 (iv⁃a)和(iv⁃b)代表个体间习得顺序的差异,一些儿童先掌握复杂尾音,另一些先掌握复杂首音。
⑥为便于表达,所有F制约条件被统一概述为FAITH.
⑦关于转头范式的具体介绍,见Jusczyk(1998)。
⑧根据基础丰富性原则,可有数量上无限的候选输入项。
⑨Fikkert和Levelt(2008)认为,辅音和元音的赋值差别源于语音感知,在感知中元音更凸显。
⑩须要说明的是,习得包含音系、句法、语义等层面,由于篇幅有限,也由于OT研究集中于音系领域,本文讨论的主要是音系的习得。
⑪表4中的1;2表示一岁两个月;1;2.15表示一岁两个半月。
⑫表6采用的是Chao(1930)的调值标注系统,声调高度被分为5个等级,1为最低,5为最高。
⑬儿童发出的平调有可能是无调状态,这一点有待进一步考证。但姑且不论平调是否是调,“降调 → 升调 →降升调”的习得顺序足以说明M>>F的排序。
猜你喜欢
《学习方法报》语文七年级(2023年23期)2023-03-24 14:23:13
军民两用技术与产品(2022年2期)2022-06-01 06:29:44
黄河之声(2019年5期)2019-12-18 12:47:03
浙江国土资源(2016年7期)2016-06-15 20:30:07
现代工业经济和信息化(2016年8期)2016-05-17 05:37:24
设备管理与维修(2016年6期)2016-03-16 02:21:44
散文百家(2015年4期)2015-04-16 00:32:15
人间(2015年21期)2015-03-11 15:24:02
中国卫生(2014年2期)2014-11-12 13:00:14
小说林(2014年5期)2014-02-28 19:51:47
