
融合人脸表情的手语到汉藏双语情感语音转换
2018-10-10 12:53宋南吴沛文杨鸿武
声学技术 2018年4期
宋南,吴沛文,杨鸿武
融合人脸表情的手语到汉藏双语情感语音转换
宋南,吴沛文,杨鸿武
(西北师范大学物理与电子工程学院,甘肃兰州 730070)
针对聋哑人与正常人之间存在的交流障碍问题,提出了一种融合人脸表情的手语到汉藏双语情感语音转换的方法。首先使用深度置信网络模型得到手势图像的特征信息,并通过深度神经网络模型得到人脸信息的表情特征。其次采用支持向量机对手势特征和人脸表情特征分别进行相应模型的训练及分类,根据识别出的手势信息和人脸表情信息分别获得手势文本及相应的情感标签。同时,利用普通话情感训练语料,采用说话人自适应训练方法,实现了一个基于隐Markov模型的情感语音合成系统。最后,利用识别获得的手势文本和情感标签,将手势及人脸表情转换为普通话或藏语的情感语音。客观评测表明,静态手势的识别率为92.8%,在扩充的Cohn-Kanade数据库和日本女性面部表情(Japanese Female Facial Expression, JAFFE)数据库上的人脸表情识别率为94.6%及80.3%。主观评测表明,转换获得的情感语音平均情感主观评定得分4.0分,利用三维情绪模型(Pleasure-Arousal-Dominance, PAD)分别评测人脸表情和合成的情感语音的PAD值,两者具有很高的相似度,表明合成的情感语音能够表达人脸表情的情感。
手势识别;表情识别;深度神经网络;汉藏双语情感语音合成;手语到语音转换
0 引言
手语是目前言语障碍者与正常人之间最重要的一种沟通方式,手语识别研究一直受到广泛的关注[1],手势识别技术逐渐成为人机交互系统方面的研究热点。早期,利用穿戴技术通过数据手套进行手语识别[2]。近年来,模式识别技术中的隐Markov模型(Hidden Markov Model, HMM)[3]、反向传播(Back Propagation, BP)神经网络[4]及支持向量机(Support Vector Machine, SVM)[5]等算法应用在手势识别上,获得了一定的效果。目前,随着深度学习技术的发展,深度学习也应用到手语识别中[6],使得手语识别率获得了较大提高。同时,在日常生活交往中,面部表情在言语障碍者的交流中也起到很重要的作用,表情可以让交流的信息传达得更加准确。现有的表情识别技术发展迅速,基于SVM[7]、Adaboost[8]、局部二值模式(Local Binary Pattern, LBP)、主成分分析(Principal Components Analysis, PCA)[9]以及深度学习的人脸表情识别[10]都已经得到了实现。手语信息与人脸表情信息的融合将会让信息表达更加明确。目前基于HMM的语音合成方法广泛应用在情感语音合成领域[11-12],通过该方法可将文本信息转换成情感语音。但现有的研究方向大都是分别对手势、人脸表情及情感语音合成进行研究。一些学者采用信息融合的方法,将人脸表情、肢体语言及语音信息进行融合,实现了多模式融合下的情感识别[13];将手势识别与语音信息融合,实现了对机器人的指挥[14];将面部表情信息与语音信息融合,实现了对机器人轮椅导航的控制[15];这些研究表明,多模式信息融合逐渐成为一种趋势。前期的研究[16-17]虽然实现了手语到语音的转换,但合成出的语音并没有包含感情和情绪的变化,忽视了聋哑人情感的语音表达,容易使听者的理解产生歧义。
将手语和人脸表情的识别技术与情感语音合成方法相结合,实现融合人脸表情的手语到情感语音的转换,对言语障碍者的日常交流具有重要作用。本文首先利用静态手势识别获得手势表达的文本,利用人脸表情识别获得表达的情感信息。同时以声韵母作为语音合成基元,实现了一个基于HMM的汉藏双语情感语音合成,将识别获得的手势文本和情感信息转换为相应的普通话或藏语情感语音。
1 系统框架
融合人脸表情的手语到汉藏双语情感语音转换系统框架如图1所示。为了实现转换系统,将系统设计为三部分:手势和人脸表情的识别、情感语音声学模型训练及情感语音合成。在识别阶段,将输入的手势图像进行预处理,再通过深度置信网络(Deep Belief Network, DBN)模型进行特征提取得到手势特征,利用SVM识别得到手势种类;将输入的人脸表情图像进行预处理,再通过深度神经网络(Deep Neural Network, DNN)模型进行特征提取得到表情特征,利用SVM识别得到情感标签。在训练阶段,将语料库中的语音和文本分别进行参数提取与文本分析,得到声学参数和标注信息,再通过情感语音的合成平台进行HMM训练,得到不同情感的语音声学模型。在合成阶段,将获得的手势种类利用定义好的手势文本字典得到手势文本,通过文本分析得到情感语音合成所需的上下文相关的标注信息,同时利用情感标签选择情感语音声学模型,最终将上下文相关的标注信息和情感语音声学模型,通过情感语音合成系统合成出情感语音。
2 融合人脸表情的手语到情感语音合成
2.1 手势识别
手势识别主要包括3个部分:预处理、特征提取以及SVM识别。图像的预处理过程通过对手势信息进行数据整合,把采集到的手势图像转化为灰度图像,并将其格式从28×28变换为784×1。针对所有图像构成一个二维矩阵,然后构建数据立方体。(轴坐标表示一个小组内不同样本的编号,轴坐标表示一个小组中特定一个样本的维度,轴表示小组的个数),把其作为DBN模型统一读入数据的格式。手势特征采用5层的DBN模型进行提取,其过程包括受限玻尔兹曼机(Restricted Boltzmann Machine, RBM)调节和反馈微调,利用RBM来调节相邻两层之间的权值[18],RBM在隐藏层到可见层之间有连接,每层内部都没有连接,其隐藏层与可见层之间的关系可以用能量函数表示为

图1 面向言语障碍者的手语到情感语音转换系统框架
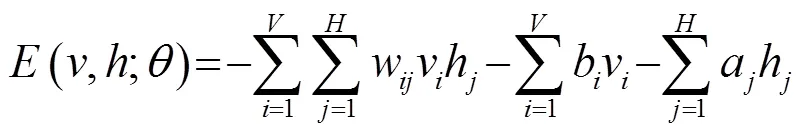

可见层与隐藏层之间的条件概率计算如下:

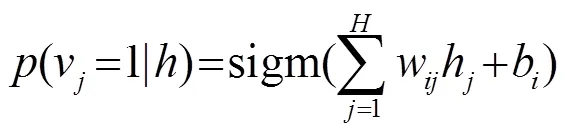
其中,是函数,是一种神经元非线性函数。RBM模型的更新权重能够通过导数概率的对数得到。
在调节过程中,通过逐层训练的方式得到每层的权值,完成可见层与隐藏层之间的反复三次转换,分别得到相应的重构目标,并利用缩小原对象同重构对象之间的差异,实现对RBM参数的调节。
微调是把全部的经过初始化后的RBM按训练的顺序串联起来,组成一个深度置信网络,通过深度模型的反馈微调可以得到手势图像的特征信息。SVM识别过程是把获得的手势图像的特征信息进行分类识别得到手势种类,其过程如图2所示。
2.2 人脸表情识别
人脸表情识别过程如图3所示,包括预处理、特征提取和SVM识别3个阶段。预处理阶段对原始图像中可能会影响到特征提取结果的一些不重要的背景信息进行处理。首先对原始的输入图像使用具有68个面部地标点的检测器进行检测,然后再将图像调整到地标边缘,在保留完整表情信息的前提下对图像进行裁剪,剪裁后删除图像的一些没有特定信息的部分,使神经网络模型的输入图像大小为96×96。在特征提取阶段,利用一个22层的DNN模型进行特征提取,从输入的每张表情图像中得到128维的特征。在SVM识别阶段,将得到的表情特征利用一个训练好的SVM分类器进行分类识别,从而得到人脸表情对应的情感标签。

图2 手势识别

图3 人脸表情识别
2.3 情感语音声学模型训练
本文以普通话和藏语的声母和韵母为语音合成的基本单元,利用说话人自适应训练(Speaker Adaptive Training, SAT)获得了情感的语音声学模型,情感语音声学模型的训练过程如图4所示。

图4 情感语音声学模型训练过程
首先,利用一个普通话中性大语料库(多说话人)和一个藏语中性小语料库(1个说话人)中的语音和文本分别进行声学参数提取与文本分析,得到声学特征对数基频(Log-fundamental Frequency, logF0)和广义梅尔倒谱系数(Mel-generalized Cepstral, MGC)以及文本的标注信息(上下文相关标注和单音素标注);然后利用声学特征和标注信息进行说话人自适应训练,得到混合语言平均声学模型。
最后将从多说话人普通话情感语料库中提取的情感语音声学特征和相应文本的标注信息,与获得的平均声学模型一起通过说话人自适应变换得到目标情感的说话人相关声学模型,以合成普通话或藏语的情感语音。
本文采用基于半隐马尔可夫模型(Hidden Semi-Markov Model, HSMM)[19]的说话人自适应训练算法训练声学模型,以减少不同说话人之间的差异对合成语音音质的影响。时长分布与状态输出分布的线性回归方程分别为
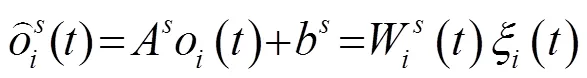

本文采用约束最大似然线性回归(Constrained Maximum Likelihood Linear Regression, CMMLR)[20]训练得到平均声学模型,进而获得上下文相关的多空间分布半隐马尔科夫模型(Multi-Space Hidden semi-Markov models, MSD-HSMM)。训练平均声学模型后,将基于MSD-HSMM的CMMLR自适应算法应用于多说话人普通话情感语料库,得到用来合成普通话情感语音和藏语情感语音的说话人相关混合语言目标情感声学模型。状态下状态时长和特征向量的变换方程如式(7)、(8)所示:




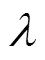
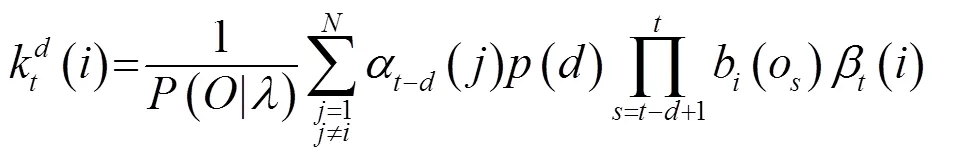
MAP估计为


2.4 手语到情感语音转换
为了获得手势文本,根据《中国手语》[22]中定义的手势种类的含义,设计了一个手势字典,该字典给出了每个手势对应的语义文本。在手语到情感语音的转换过程中,首先通过手势识别获得手势类别,然后查找手势字典,获得手势文本,最后对手势文本进行文本分析,获得文本的声韵母信息以及声韵母的上下文信息,从而能够利用决策树选择出最优的声韵母的声学模型。声韵母的上下文信息以上下文相关标注的形式给出,包括普通话或藏语的声韵母信息、音节信息、词信息[23]、韵律词信息[24]、短语信息和语句信息。同时,采用人脸表情识别获得情感标签,利用情感标签选择相应情感的语音声学模型,从而能够利用文本的上下文相关标注信息合成出普通话或藏语的情感语音。手语到情感语音转换流程如图5所示。

图5 手语到情感语音转换框图
3 实验结果
3.1 手势识别
3.1.1 手势数据
在实验中构造的手势样本集合主要来自2位测试人所生成的样本,每位测试人打30种手势,每种手势的样本个数均为1 000,以此来生成30个深度学习模型。预定义的30种静态手势如图6所示。

图6 预定义的30种手势
3.1.2 手势识别率
为了验证DBN模型在手势识别上的有效性,本文从图6所示的30种手势库中随机挑选了4 000个样本,分别利用DBN模型和PCA方法进行了5次交叉实验,每次实验的训练集和测试集样本数分别为3 200和800,并将这五次实验分别进行编号(集1到集5);最终利用SVM识别得到如表1所示的识别率。从表1中可以看出,在5次交叉验证中,利用DBN模型进行特征提取的手势识别率优于PCA方法,表明通过DBN模型提取到的特征能更好地反映出手势的本质特征。

表1 5次交叉验证识别率(%)
3.2 人脸表情识别
3.2.1 人脸表情库数据
本文采用扩充的Cohn-Kanade数据库(the extended Cohn-Kanade database, CK+)[25]和日本女性面部表情(Japanese Female Facial Expression, JAFFE)数据库[26]进行人脸表情的训练和测试。CK+数据库中每个序列图像都是以中性表达式开始到情感峰值结束。实验数据库中包含8种情感类别的表情图像,但在实验中,蔑视和中性表情图像没有被使用,并且只选取了一些具有明显表情特征信息的图像来作为样本集使用。将JAFFE数据库中7种表情中的6种表情进行了实验,没有使用中性表情图像,其中每人的一种表情图像大小均为256×256。数据库中图像的一些例子如图7所示。
3.2.2 DNN模型
本文采用了nn4.small2的神经网络模型[27]去提取表情图像特征,图8展示了一张裁剪后的图像经过该模型的第一层卷积后输出的特征图,该图显示了输入图像的第一个卷积层的64个全部滤镜。网络模型定义如表2所示。其中包含了8个Inception的模块。池化层可以有效地缩小矩阵的尺寸,而最大池化表示对邻域内特征点取最大,平均池化表示对邻域内特征点只求平均。池项目表示嵌入的最大池化之后的投影层中1×1过滤器的个数,池项目中最大池化用表示,降维后的池化用表示。

图7 数据库示例

图8 卷积层可视化示例

表2 网络模型定义
3.2.3 表情识别率
在CK+数据库上进行5次交叉验证的实验,得到6种表情相应的识别率。在JAFFE数据库上进行3次交叉验证的实验,得到6种表情相应的识别率。如表3所示。
从表3可以看出,JAFFE的数据库上的识别率要低于CK+数据库上的识别率,主要原因是在实验中JAFFE数据库的表情图片数量少于CK+数据库的表情图片数量。

表3 不同数据库上的人脸表情识别率(%)
3.3 情感语音合成
3.3.1 语料
普通话语料库选用7个女性说话人的中性语料,每个说话人的语料各包含169句,共计1 183句(7×169句)语料。普通话情感语料库,是本研究设置特定的场景采用激发引导方式录制的9个女性说话人 11 种情感的普通话情感语音库,每个说话人的每种情感语料各包含100句,录音人不是专业演员,实验中选取了其中的6种情感语料(9人×6种情感×100句)。藏语语料库是本研究录制的一个藏语女性说话人的800句语料。所有实验的语音均采用16 bit量化、16 kHz采样、单通道的WAV文件格式。采用5状态的上下文相关的一阶MSD-HSMM模型来建立声学模型。
3.3.2 情感相似度评测
通过情感平均意见得分(Emotional Mean Opinion Score, EMOS),对合成的普通话情感语音以及藏语情感语音分别进行情感相似度评测。给10名普通话评测者播放100句原始普通话情感语音作为参考,然后按照情感顺序依次播放6种情感的普通话情感语音。同时给10名藏语评测者播放100句合成的中性藏语语音,作为中性参考语音,之后按照6种情感顺序播放藏语情感语音。在评测打分过程中是按照播放语音的先后顺序来进行的,要求评测者参照现实生活中的情感表达经验,给每句合成出的语音,按5分制进行情感相似度打分,结果如图9所示。

图9 合成普通话和藏语的情感语音EMOS得分
从图9中可以看出,利用普通话情感语料训练的情感声学模型合成出的藏语情感语音的EMOS评分,要低于合成出的普通话情感语音的EMOS评分。
3.3.3 客观评测
由于只有普通话情感语料库,所以仅对合成的普通话情感语音进行了客观评测。本文计算了原始语音与合成语音在时长、基频及谱质心上的均方根误差(Root Mean Square Error, RMSE),结果如表4所示。从表4可以看出,时长、基频及谱质心的均方根误差值较小,说明合成的普通话情感语音与原始的普通话情感语音比较接近,合成的情感语音音质较好。
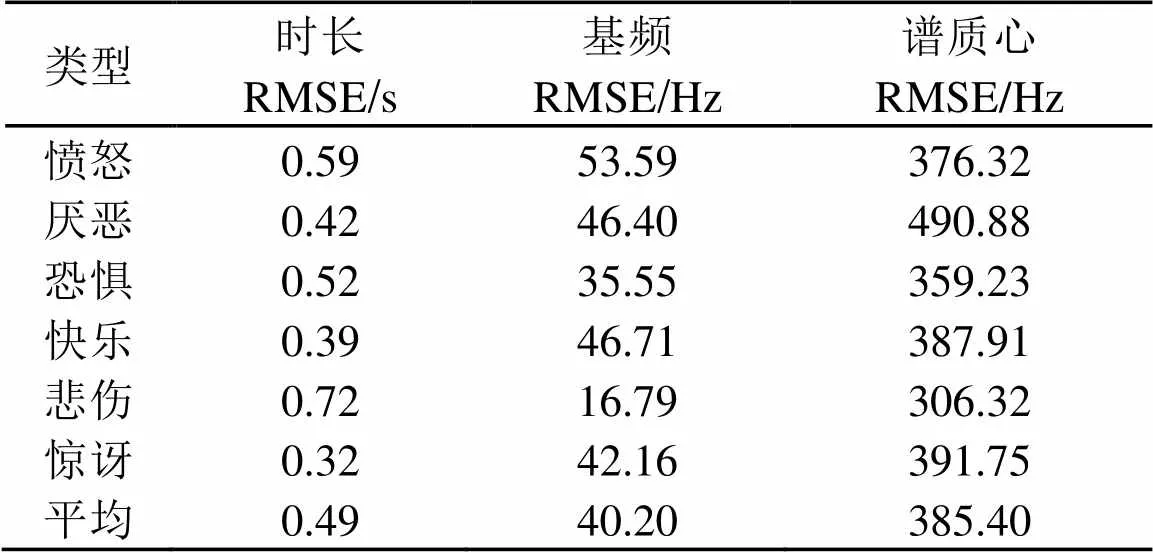
表4 普通话合成情感语音与原始情感语音在时长、基频及谱质心 上的均方根误差
3.4 表情图片与情感语音的PAD评测
为了进一步评测合成语音对原始人脸表情的情感表达程度,本文采用PAD三维情绪模型,对比了表情图片的PAD值与合成语音的PAD值的差异。本文采用简化版本的PAD情感量化表[28],对人脸表情图片及其对应的情感语音在PAD的3个情绪维度上进行评分。首先随机播放所有人脸表情图片,评测者根据观测到图片时感受到的心理情绪状态,完成PAD情绪量表。然后随机播放合成的情感语音,同样要求评测者根据听情感语音时感受到的心理情绪状态,完成PAD情绪量表。由于藏语评测人不足,所以本文只对合成的普通话情感语音进行了PAD评测。最后,计算出在同一种情感状态下表情图片的PAD值与情感语音的PAD值的欧氏距离。评测结果如表5所示。从表5可以看出,表情图片和情感语音的PAD值在同一情感状态下的欧氏距离较小,表明合成的情感语音能够较为准确地再现人脸表情的情感状态。

表5 PAD的评测结果
4 结 论
本文提出了一种融合人脸表情的手语到汉藏双语情感语音转换的实现方法。首先,将手势库中的手势图像通过DBN模型进行特征提取,同时对人脸表情数据库(CK+和JAFFE)中的表情图像利用DNN模型进行特征提取,把获得的手势特征与表情特征进行SVM识别,并分别转换为手势文本的上下文相关标注及相应的情感标签。再利用情感语料库以及中性语料库(普通话中性大语料库和藏语中性小语料库),训练了一个基于HMM的普通话/藏语的情感语音合成器。最后,根据识别获得的情感标签选择的情感语音声学模型和手势文本的上下文相关标注进行情感语音合成,从而实现手势到情感语音的转换。实验结果表明,转换获得的汉藏双语情感语音的平均EMOS得分为4.0分;同时,利用PAD三维情绪模型对表情图片以及合成出的情感语音进行PAD评定后发现,表情图片与合成出的情感语音在PAD值上的欧式距离较小,表明合成的情感语音能够表达人脸表情的情感状态。进一步的工作将结合深度学习优化手势识别、人脸表情识别及汉藏双语情感语音合成的算法结构,提高识别率和合成情感语音的音质。
[1] KALSH E A, GAREWAL N S. Sign language recognition system[J]. International Journal of Computational Engineering Research, 2013, 3(6): 15-21.
[2] ASSALEH K, SHANABLEH T, ZOUROB M. Low complexity classification system for glove-based arabic sign language recognition[C]//Neural Information Processing. Springer Berlin/Heidelberg, 2012: 262-268.
[3] GODOY V, BRITTO A S, KOERICH A, et al. An HMM-based gesture recognition method trained on few samples[C]// 2014 IEEE 26th International Conference on Tools with Artificial Intelligence (ICTAI). IEEE, 2014: 640-646.
[4] YANG Z Q, SUN G. Gesture recognition based on quantum-behaved particle swarm optimization of back propagation neural network[J]. Computer application, 2014, 34(S1): 137-140.
[5] GHOSH D K, ARI S. Static Hand Gesture Recognition using Mixture of Features and SVM Classifier[C]// 2015 Fifth International Conference on Communication Systems and Network Technologies (CSNT). IEEE, 2015: 1094-1099.
[6] OYEDOTUN O K, KHASHMAN A. Deep learning in vision-based static hand gesture recognition[J]. Neural Computing and Applications, 2017, 28(12): 3941-3951.
[7] HSIEH C C, HSIH M H, JIANG M K, et al. Effective semantic features for facial expressions recognition using svm[J]. Multimedia Tools and Applications, 2016, 75(11): 6663-6682.
[8] PRABHAKAR S, SHARMA J, GUPTA S. Facial Expression Recognition in Video using Adaboost and SVM[J]. Polish Journal of Natural Sciences, 2014, 3613(1): 672-675.
[9] ABDULRAHMAN M, GWADABE T R, ABDU F J, et al. Gabor wavelet transform based facial expression recognition using PCA and LBP[C]//Signal Processing and Communications Applications Conference (SIU), 2014 22nd. IEEE, 2014: 2265-2268.
[10] ZHAO X, SHI X, ZHANG S. Facial expression recognition via deep learning[J]. IETE Technical Review, 2015, 32(5): 347-355.
[11] BARRA-CHICOTE R, YAMAGISHI J, KING S, et al. Analysis of statistical parametric and unit selection speech synthesis systems applied to emotional speech[J]. Speech Communication, 2010, 52(5): 394-404.
[12] WU P, YANG H, GAN Z. Towards realizing mandarin-tibetan bi-lingual emotional speech synthesis with mandarin emotional training corpus[C]//International Conference of Pioneering Computer Scientists, Engineers and Educators. Springer, Singapore, 2017: 126-137.
[13] CARIDAKIS G, CASTELLANO G, KESSOUS L, et al. Multimodal emotion recognition from expressive faces, body gestures and speech[C]// IFIP International Conference on Artificial Intelligence Applications and Innovations. Springer, Boston, MA, 2007: 375-388
[14] BURGER B, FERRANÉ I, LERASLE F, et al. Two-handed gesture recognition and fusion with speech to command a robot[J]. Autonomous Robots, 2012, 32(2): 129-147.
[15] SINYUKOV D A, LI R, OTERO N W, et al. Augmenting a voice and facial expression control of a robotic wheelchair with assistive navigation[C]// 2014 IEEE International Conference on Systems, Man and Cybernetics (SMC). IEEE, 2014: 1088-1094.
[16] YANG H, AN X, PEI D, et al. Towards realizing gesture-to-speech conversion with a HMM-based bilingual speech synthesis system[C]// 2014 IEEE International Conference on Orange Technologies (ICOT). IEEE, 2014: 97-100.
[17] AN X, YANG H, GAN Z. Towards realizing sign language-to-speech conversion by combining deep learning and statistical parametric speech synthesis[C]// International Conference of Young Computer Scientists, Engineers and Educators. Springer Singapore, 2016:678-690.
[18] FENG F, LI R, WANG X. Deep correspondence restricted Boltzmann machine for cross-modal retrieval[J]. Neurocomputing, 2015, 154: 50-60.
[19] ZEN H, TOKUDA K, BLACK A W. Statistical parametric speech synthesis[J]. Speech Communication, 2009, 51(11): 1039-1064.
[20] YAMAGISHI J, KOBAYASHI T, NAKANO Y, et al. Analysis of speaker adaptation algorithms for HMM-based speech synthesis and a constrained SMAPLR adaptation algorithm[J]. IEEE Transactions on Audio, Speech, and Language Processing, 2009, 17(1): 66-83.
[21] SIOHAN O, MYRVOLL T A, LEE C H. Structural maximum a posteriori linear regression for fast HMM adaptation[J]. Computer Speech & Language, 2002, 16(1): 5-24.
[22] 中国聋人协会. 中国手语[M]. 北京:华夏出版社, 2003.
China Association of the Deaf and Hard of Hearing. Chinese Sign Language[M]. Beijing: Huaxia Publishing House, 2003.
[23] YANG H, OURA K, WANG H, et al. Using speaker adaptive training to realize Mandarin-Tibetan cross-lingual speech synthesis[J]. Multimedia Tools & Applications, 2015, 74(22): 9927-9942.
[24] 杨鸿武, 朱玲. 基于句法特征的汉语韵律边界预测[J].西北师范大学学报(自然科学版), 2013, 49(1): 41-45.
YANG Hongwu, ZHU Ling. Predicting Chinese prosodic boundary based on syntactic features[J]. Journal of Northwest Normal University (Natural Science Edition), 2013, 49(1): 41-45.
[25] LUCEY P, COHN J F, KANADE T, et al. The Extended Cohn-Kanade Dataset (CK+): A complete dataset for action unit and emotion-specified expression[C]// Computer Vision and Pattern Recognition Workshops. IEEE, 2010:94-101.
[26] LYONS M, AKAMATSU S, KAMACHI M, et al. Coding facial expressions with gabor wavelets[C]// Third IEEE International Conference on Automatic Face and Gesture Recognition. IEEE, 1998: 200-205.
[27] AMOS B, LUDWICZUK B, SATYANARAYANAN M. OpenFace: A general-purpose face recognition library with mobile applications[R]. Technical report, CMU-CS-16-118, CMU School of Computer Science, 2016.
[28] LI X M, FU X L, DENG G F. Preliminary application of the abbreviated PAD emotion scale to Chinese undergraduates[J]. Chinese Mental Health Journal, 2008, 22(5): 327-329.
Gesture-to-emotional speech conversion based on gesture recognigion and facial expression recognition
SONG Nan, WU Pei-wen, YANG Hong-wu
(College of Physics and Electronic Engineering, Northwest Normal University, Lanzhou 730070, Gansu, China)
This paper proposes a face expression integrated gesture-to-emotional speech conversion method to solve the communication problems between healthy people and speech disorders. Firstly, the feature information of gesture image are obtained by using the model of the deep belief network (DBN) and the features of facial expression are extracted by a deep neural network (DNN) model. Secondly, a set of support vector machines (SVM) are trained to classify the gesture and facial expression for recognizing the text of gestures and emotional tags of facial expression. At the same time, a hidden Markov model-based Mandarin-Tibetan bilingual emotional speech synthesis is trained by speaker adaptive training with a Mandarin emotional speech corpus. Finally, the Mandarin or Tibetan emotional speech is synthesized from the recognized text of gestures and emotional tags. The objective tests show that the recognition rate for static gestures is 92.8%. The recognition rate of facial expression achieves 94.6% on the extended Cohn-Kanade database (CK+) and 80.3% on the JAFFE database respectively. Subjective evaluation demonstrates that synthesized emotional speech can get 4.0 of the emotional mean opinion score. The pleasure-arousal-dominance (PAD) tree dimensional emotion model is employed to evaluate the PAD values for both facial expression and synthesized emotional speech. Results show that the PAD values of facial expression are close to the PAD values of synthesized emotional speech. This means that the synthesized emotional speech can express the emotion of facial expression.
gesture recognition;facial expression recognition; deep neural network; Mandarin-Tibetan bilingual emotional speech synthesis; gesture to speech conversion
TP391
A
1000-3630(2018)-04-0372-08
10.16300/j.cnki.1000-3630.2018.04.014
2017-10-09;
2017-12-17
国家自然科学基金(11664036、61263036、61262055)、甘肃省高等学校科技创新团队项目(2017C-03)资助。
宋南(1990-), 男, 河北迁安人, 硕士研究生, 研究方向为信号与信息处理。
杨鸿武,E-mail: yanghw@nwnu.edu.cn
猜你喜欢
家庭影院技术(2020年6期)2020-07-27
红领巾·萌芽(2019年9期)2019-10-09
活力(2019年15期)2019-09-25
家庭影院技术(2019年1期)2019-01-21
家庭影院技术(2018年11期)2019-01-21
小学科学(学生版)(2018年12期)2018-12-19
家庭影院技术(2018年10期)2018-11-02
小学阅读指南·低年级版(2017年6期)2017-06-12
现代特殊教育(2016年21期)2016-12-14
青少年科技博览(中学版)(2015年8期)2015-10-28
