
基于Web挖掘的个性化视频推荐系统设计与实现
2018-10-09 03:00汤伟
电子设计工程 2018年18期
汤 伟
(1.中国科学院上海微系统与信息技术研究所,上海201210;2.上海科技大学信息科学与技术学院,上海201210;3.中国科学院大学北京101407)
陪伴着“互联网+”技术的急速普及,视频业务也呈现急剧增长的趋势。用户对视频内容需求也呈现多元化趋势,视频推荐技术的重要性也更加突出。它可以根据用户的兴趣和行为向目标用户推荐个人感兴趣的视频信息,满足用户对视频的个性化和多元化需求,减少用户选择困难的烦恼[1]。
然而,视频推荐系统也存在着诸多问题,其中最常见的莫过于推荐系统中由于无相关数据而导致的推荐冷启动问题以及用户数据过于稀疏导致推荐准确度低的问题[2]。本文针对推荐系统内部存在的冷启动及推荐准确度低的问题,提出基于Web挖掘的视频推荐系统方式和改进相似度计算方法,不仅能够达到缓解推荐系统内部冷启动问题的效果,而且也提高了视频推荐精确度,从而给用户带来更舒适的体验质量,给视频提供商带来更有前景的金融效益[2-3]。
1 Web挖掘技术简介
Web数据挖掘是将传统的数据采集技术和Web开发有效的结合起来,从Web文档及Web网页中进行浏览相关数据中探索未知的、隐藏的、具有潜在效益的一种数据搜集的过程。这是数据挖掘技术在Web中的一种运用[4]。Web挖掘对比与于传统数据采集的特征只要展现在Web数据源具有很强的动态性、丰富性、多样性以及目标用户的模糊性、自身的不断改进与完善等等。根据Web数据类型差异,Web挖掘相关研究可以分成:Web日志挖掘,Web结构挖掘、Web内容挖掘。Web数据挖掘的主要流水线步骤可以分成Web数据的捕获阶段、Web数据预处理阶段、模式分析阶段三个主要过程。此外,Web数据挖掘技术也在众多领域得到广泛运用,例如:电子商务、生物信息处理、工业控制以及政府部分等[5]。本文提出的基于Web挖掘的个性化视频推荐系统,其实质是一种构建数学模型来建立目标用户兴趣模型,计算目标用户与近邻用户之间的相似程度,对目标用户举荐列表中的视频,从而使用户具有更加舒适的视频体验质量。
2 推荐系统设计
文章中在传统协同过滤算法根基上引入Web数据挖掘技术,该算法首先通过采集用户点击行为、搜索记录、评分记录等信息,建立目标用户兴趣模型,然后结合基于内容和协同过滤算法形成一种同构化的混合推荐方法,改进推荐算法中相似度计算方式,来给目标用户举荐个性化的视频列表电影内容[6-7]。系统总体设计流程如图1所示。

图1 视频推荐方式总体设计流程工艺图
具体而言,文章中采用的基于Web挖掘的视频推荐算法首先是将数据转化为“用户-视频”效用矩阵,其中效用矩阵主要采集用户的行为信息和注册信息,其行为信息包含用户对视频点赞行为、用户评分,用户搜索视频行为等,利用目标用户的量化效用矩阵,通过采取分类回归算法来创建“个性化的视频兴趣模型”,然后根据“用户-视频”的关联性计算出目标用户的相似邻居集,由于在进行近邻集筛选中,考虑到数据过于稀疏而导致的维度过高,会对数据集采用主成分分析(Principal Component Analysis,PCA)来进行降维处理,提取用户的主要特征模型。最后,计算近邻用户集与视频项目之间的关联性,从而对目标用户与视频之间的量化牵连性做出举荐,由此就可以给目标用户建立topN的视频举荐列表。这样的推荐电影方式不仅可以缓解新用户无历史数据带来的推荐冷启动问题,排除传统推荐系统中由于用户信息少而带来的稀疏性问题,也可以提高用户的视频体验质量[8]。
2.1 用户视频兴趣模型建立
用 CART(Classification and Regression Tree)算法建立用户兴趣模型。CART算法也是决策树算法的一种,它既可以用于分类也可以用于回归。其算法主要围绕决策树生成和决策树剪枝两个过程进行开展的。
CART分类树选择基尼指数来划分最有价值的特点。CART分类树生成的算法如下:
输入:训练数据集D和计算的终止条件。
输出:CART决策树。
算法步骤:
1)对每个特征A,以及它可能的每个值a,计算基尼指数,如公式(1)。

2)选取最优性状和最优的切分点:在所有性状A以及所有切分点a中选取最小的基尼指数作为最优特征和最优特征的划分点。其中,基尼指数越小说明运用该属性进行划分数据集的纯度越高。
3)对下一个子节点递归调用上面的步骤,直到满足输入的终止条件为止。
4)最终生成CART决策树。
CART剪枝是从生成树开始剪掉一些枝叶,使得决策树变小。剪枝过程主要是由两步组成(假设初始的生成树为T0):
1)从T0起始不断地剪枝,直到剪成一颗颗单节点的子树。这些剪枝会逐渐形成一个个剪枝树序列{T0,T1,…,Tn};
2)从这个剪枝序列中挑选出最优剪枝树。挑选措施是使用交叉验证法采用验证数据集对剪枝树序列进行测试。
2.2 基于PCA的混合推荐算法设计
在如今大数据和移动互联网普及的背景下,视频网站的用户和视频数量日益增加,然而大多数用户仅仅只对其中很少一部分的视频项目进行评分,致使已有的用户-视频评分的效用矩阵十分稀疏,例如就本实验中的MovieLens-100k数据集而言,用户已评分的项目记录仅约占总数据的6.3%,因此如果采用传统的协同过滤算法来计算用户之间的相似性计算会导致较大的实验误差,最终会致使推荐精确度不高,用户体验差的后果[9]。
在实际的模型构建中,因为数据量的庞大导致数据过于稀疏的问题,本文利用主成分分析(PCA)的降维技术来处理数据。这样能够在保存大部分数据的情况下,减少数据维度。此外,由于数据的过于稀疏,仅仅利用一种推荐方法得到的结果会很难用户满意。例如:协同过滤可以通过计算用户与用户之间的相似程度来获得推荐,但是它却疏忽了项目和用户自身所具有的特性,并且还存在冷启动的弊端。基于内容的推荐尽管力所能及解决协同过滤中的弊端,可是它在提取视频的内容特征上有困难。在这样条件中,将两种算法融合形成基于内容-协同过滤的同构化混合推荐算法很必要。不但能够互相弥补各自的弊端,并且也可以使视频推荐系统具备更高的精确度和效率。此外,在相似度计算上仅仅利用采用传统的Pearson或者Jaccard等相似度计算方法直接计算会带来较大的数据误差[10]。鉴于此,本文借助PCA算法和加权皮尔逊相似度计算方式提出一种为PCABsaedCBFCF的算法来做基于内容和协同过滤的混合推荐。
改进传统的相似度计算方法,例如采用Pearson相似度计算方式留有一定程度的不足,例如,在对相同的经典电影《战狼》,两个用户都给与相当高的评分,这样带来的信息肯定不如两个用户对其他电影评价不同分带来的信息更有价值。结合文本文档检索中的TF-IDF技术[11],文中提出了一种基于反文档频率加权计算模式。反文档频率的意思是指对于那些常见的词语对于区分文档没有太大作用,应该给那些仅出现在某些文档中具有代表性的词更高权重。结合视频推荐而言,如果一部电影被大多数用户给与相同的评分,那么这个电影在区分用户之间的相似度的时候占据的权重会降低一些。计算公式如(2)

其中,ui表示评价过视频i的用户数,u表示用户总体数量。改进后的Pearson相似度计算公式如(3)

其中,用户u和用户v都评价过的视频项目的集合,用户v和用户u评分相应的平均值分别为和。rui和rvi分别代表用户u和v对项目i的评分。λi的表示第i个视频所占的权重。尽管改善了传统的相似度计算方式,但是仅仅利用一种相似度的计算方式还是无法准确的反映用户之间的关系。因此,我们综合思量了多种相似度的方式,选择了Jaccard相似度计算方式,因为Jaccard相似度可以较好的反映用户和项目之间的关系。最终我们在计算用户与用户之间相似度采用了如公式(4)
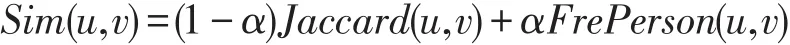
其中,α作为权重因子可以用来调整Pearson相似度和Jaccard相似度各自自身所占的权重。其中,α是在不断的变化和调节。公式(4)中的Jaccard相似度计算方式如公式(5)表示:

其中,J(A,B)体现两个集合A和B的交集元素在A、B的并集中占用的比例。最后PCABsaed CBFCF的算法表示:
输入:用户项目评分效用矩阵U,测试数据集Utest,近邻数量 K-Neighbor,权重因子α
输出:测试集上的MAE。
1)每个用户自身数据值减去用户的均值来填充原始数据集中缺失的值;
2)进行PCA分解;
3)计算用户间的Perason相似度;
4)计算用户间的Jaccard相似度;
5)利用公式(3)来计算改进的相似度;
6)根据近邻数量K-Neighbours计算测试集上的预测评分;
7)计算测试集上的MAE;
3 实验分析
在本试验中为了证实推荐算法效用性,采取MovieLens-100k数据集作为实验数据。在实验结果中,如图2是在不同相似度在不同近邻数下的MAE值的曲线差异图,在试验中选择了余弦相似度、Jaccard相似度和本文中采用的改进相似度计算法,即FrePearson相似度,从图中可以看出采用FrePerson相似度算法在平均绝对误差(MAE)上明显优胜于其他两种计算方法,此外从图中可以看出Jaccard相似度也优胜于传统的余弦相似度,也就是说FrePearson相似度计算方式优胜于Jaccard相似度,同时Jaccard相似度也比传统余弦相似度更优,这样本文在融合了Jaccard和Pearson相似度各自具有的优势,提高了推荐精确度。此外,从图2中可以看出这3种相似度在不同的近邻数下呈现很大的差异,并不是近邻数越多越好,可能选择的近邻数目越多带来一些数据过多冗余,比如有些用户在打分的时候是很随意的打分[12]。如果选择的近邻数目过多,也许会使目标用户相似度很低的用户也会被选择为邻居集,从而带来推荐精度降低的弊端,因而在实际中选择合理的邻居数目也是重要方面。

图2 不同相似度在近邻数下的MAE值
3.1 权重因子
除了近邻数目会影响推荐结果的精确度,权重因子也是一个重要的影响因子。
图3是本文算法在不同的权重因子下MAE值变化情况。从图3中可以看出不同权重因子下MAE值的变化,整体展现出先上升再下降然后再上升的趋向。其中,在α为0.2时,MAE取值最大,说明此时的推荐精度最低,在α值为1时,算法只用到了一种FrePearson相似度计算方法,在α为0时,算法只用到Jaccard相似度计算方式,MAE的取值较大,从侧面说明FrePearson的相似度计算方式优胜于Jaccard计算方式。此外,在α从0到1变化的时候,FrePearson相似度计算方式所占比重会逐步加大,MAE的值也在呈现迅速下降到逐步上升的趋势状态。在α为0.4附近,MAE的值达到了最优值(此时Jaccard相似度所占的权重更大)推荐精度也达到了最优。因此,在实验中选择合适的权重因子可以提高推荐精确度。
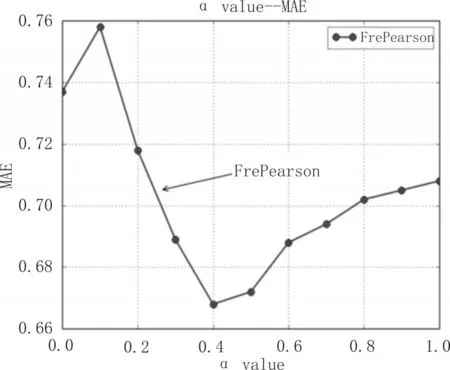
图3 不同权重因子下的MAE值
3.2 对比试验分析
图4 是本文提出的PCABasedCBFCF算法,同经典的协同过滤(Collaborative Filtering,CF)和基于内容的推荐算法(Content-based Filtering,CBF)做性能上的差异分析,从图4中看PCABasedCBF-CF算法在性能上优胜于传统的协同过滤算法和基于内容的算法,整体降低了15%和6%。
在表格1中展示本文给出的算法在不同的近邻数目下平绝绝对误差(MAE)的对应节点值变化。
4 视频推荐系统实现

图4 不同近邻数目差异算法的MAE值
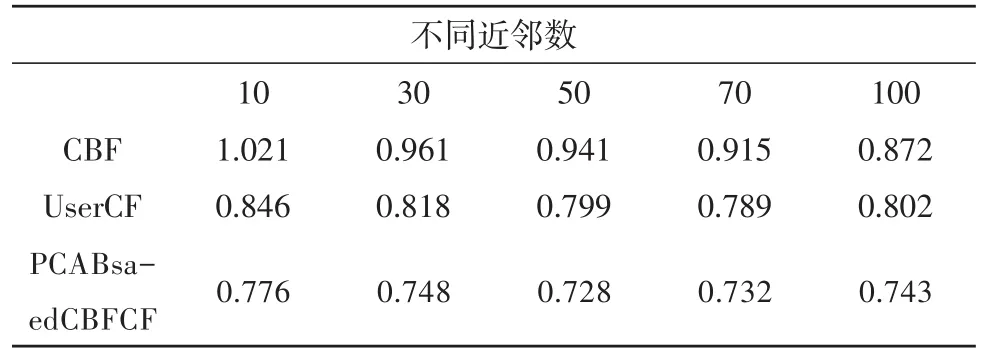
表1 不同算法对于的MAE值
前面对基于Web挖掘的视频推荐系统进行了分析和设计,并采用同构化推荐算法和改进相似度计算方法,提高了系统的推荐准确率。下一步就是在设计基础上搭建视频推荐模型,确保推荐算法可以在本系统中的模块可以平稳地工作。整个系统环境搭建是建立在 Django、Bootstrap、HTML、MySQL的基础上完成的[13-15]。
新用户注册时,系统会需要注册用户输入一个唯一的用户名,同时用户务必选择喜欢的电影类型标签,也可以设置系统内部没有类型标签[16],标签的选择可以弥补推荐系统冷启动带来的不足,如图5和图6。

图5 用户登录与注册
用户可以进入界面搜索相应的影片,或是评价电影、给电影打分。后台会将目标用户的行为记录到个人Web日志系统,然后结合之前测试的推荐算法,进行计算,产生个性化推荐列表,然后将推荐列表在前端页面展示给目用户,如图7。

图6 个性化标签

图7 视频推荐列表
这样一个具有个性化视频推荐系统和高效推荐算法融合的模型,就展现在观众面前,提高了视频网站观众的忠实度和依赖度,也为推荐系统在电子商务系统中不断前进贡献了自己的一份力量。
5 结束语
文中设计的个性化视频推荐系统融合多种推荐算法,采用Web数据挖掘建立目标用户视频个性化兴趣模型,其次针对传统协同过滤算法留存的数据稀疏性问题应用基于PCA的混合推荐算法,并引入一种将Jaccard相似度和Pearson相似度加权结合的相似度计算方法,缓解了经典相似度计算法因为数据稀疏性带来的误差,同时提高了视频推荐精度。最后利用Python Web技术搭建了电影推荐系统原型,测试并完成了一个为用户定制的个性化视频推荐系统,缓解了解决推荐系统冷启动和推荐精确度低的问题,提高了视频用户的体验质量。
猜你喜欢
重庆大学学报(2022年6期)2022-06-23
保健医苑(2022年5期)2022-06-10
客联(2021年2期)2021-09-10
成都信息工程大学学报(2021年6期)2021-02-12
当代陕西(2020年17期)2020-10-28
人大建设(2018年5期)2018-08-16
电信科学(2017年6期)2017-07-01
天津诗人(2017年2期)2017-03-16
计算机工程(2014年6期)2014-02-28
