
基于改进的VGGNet算法的人脸识别
2018-10-08 02:12喻丽春刘金清
长春工业大学学报 2018年4期
喻丽春, 刘金清
(1.福州外语外贸学院 信息系, 福建 福州 350202;2.福建师范大学 光电与信息工程学院, 福建 福州 350007)
0 引 言
随着计算机硬件和人工智能技术的发展,计算机视觉技术被广泛应用在各个领域,其中人脸识别作为计算机视觉技术的一个重要方向,也有了突破性的进展。目前,人脸识别在现实生活中已被广泛应用,如身份认证、网络支付、公共安全监控、影像追踪等。伴随深度学习技术的突破发展,人脸识别技术逐渐从传统的机器学习转变为深度学习。深度学习的概念由Hinton等人于2006年提出。深度置信网络(DBN)提出非监督贪心逐层训练算法,为解决深层结构相关的优化难题带来希望,随后提出多层自动编码器深层结构。此外Lecun等提出的卷积神经网络是第一个真正多层结构学习算法,它利用空间相对关系减少参数数目以提高训练性能[1]。在深度学习上,国内外同行已经取得了不俗的成绩,如Face Book的DeepFace[2],香港中文大学的DeepID[3], Google的FaceNet[4],百度的BaiduIDLFinal[5],这些深度学习算法依赖于大规模的训练数据和高速的计算能力,取得了优秀的成果。但在大多数实际应用项目中,小型企业或普通个人研究者一般很难获取到大批量的训练数据,能掌握的计算能力也有限,因此需要一种能在小规模训练数据条件下,计算能力有限的环境中满足实际应用的人脸识别算法技术。
针对现有的深度学习神经网络依赖大规模训练数据和强大计算力的问题,对卷积神经网络VGGNet网络结构进行改进,简化网络结构,改进损失函数,提出一种基于VGGNet改进的LiteVGGNet人脸识别算法。实验表明,在较小训练数据规模和有限计算力的条件下,改进后的LiteVGGNet深度学习算法识别率较高,能够满足实际人脸识别应用要求。
1 VGGNet神经网络介绍
VGGNet是牛津大学视觉几何组VGG(Visual Geometry Group)小组开发的一个著名的应用于图片分类的卷积神经网络模型。在2014年ImageNet大规模视觉识别挑战赛ILSVRC(ImageNet Large Scale Visual Recognition Challenge)上取得了第二名的成绩,图片特征提取能力非常优秀,其在多个迁移学习任务中表现要优于2014年第一名的GoogLeNet,因此,从图像中提取特征,VGG模型是首选算法。VGG模型的缺点是参数较多,参数量有138 M多,需要较大的存储空间,训练时间也相对较长。VGGNet的模型结构[6]如图1所示。

图1 VGGNet模型结构
VGGNet模型结构说明如下:
1)网络的输入是224×224的RGB图片,所有图片都经过均值处理。
2)网络总共有5个最大池化层,13个卷积层。3个全连接层和一个SoftMax分类器层。
3)卷积层中卷积核大小均是3×3,步长为1(stride=1),补1圈0(pad=1)。
4)池化层均采用最大池化(Max Pooling),但不是所有的卷积层都有池化层,池化窗口为2×2,步长为2,即采用的是不重叠池化。
5)所有隐含层后都配有ReLU层。
6)在第一个和第二个全连接层后面,还使用了dropout技术,防止网络过拟合。
VGGNet是著名卷积神经网络模型AlexNet的扩展。相对于AlexNet网络,VGGNet作出如下有价值的改进:
1)使用连续3个 3×3的卷积核替代1个7×7卷积核。对于C个通道的卷积核,7×7的卷积层含有参数72C2,而 3个3×3卷积层的参数个数为3×32C2,因此使用参数的个数可大大减少。
2)使用3×3卷积核的原因是:3×3是可以表示“左右”、“上下”、“中心”这些模式的最小单元,同时采用较小的卷积核有利于更好地提取图像细节特征。更多的卷积层增强了网络的非线性表达能力。
3)VGGNet不使用局部响应标准化LRN (Local Response Normalization),实验表明,这种标准化并不能提升性能,却导致更多的内存消耗和计算时间[6]。
VGG的网络参数见表1。
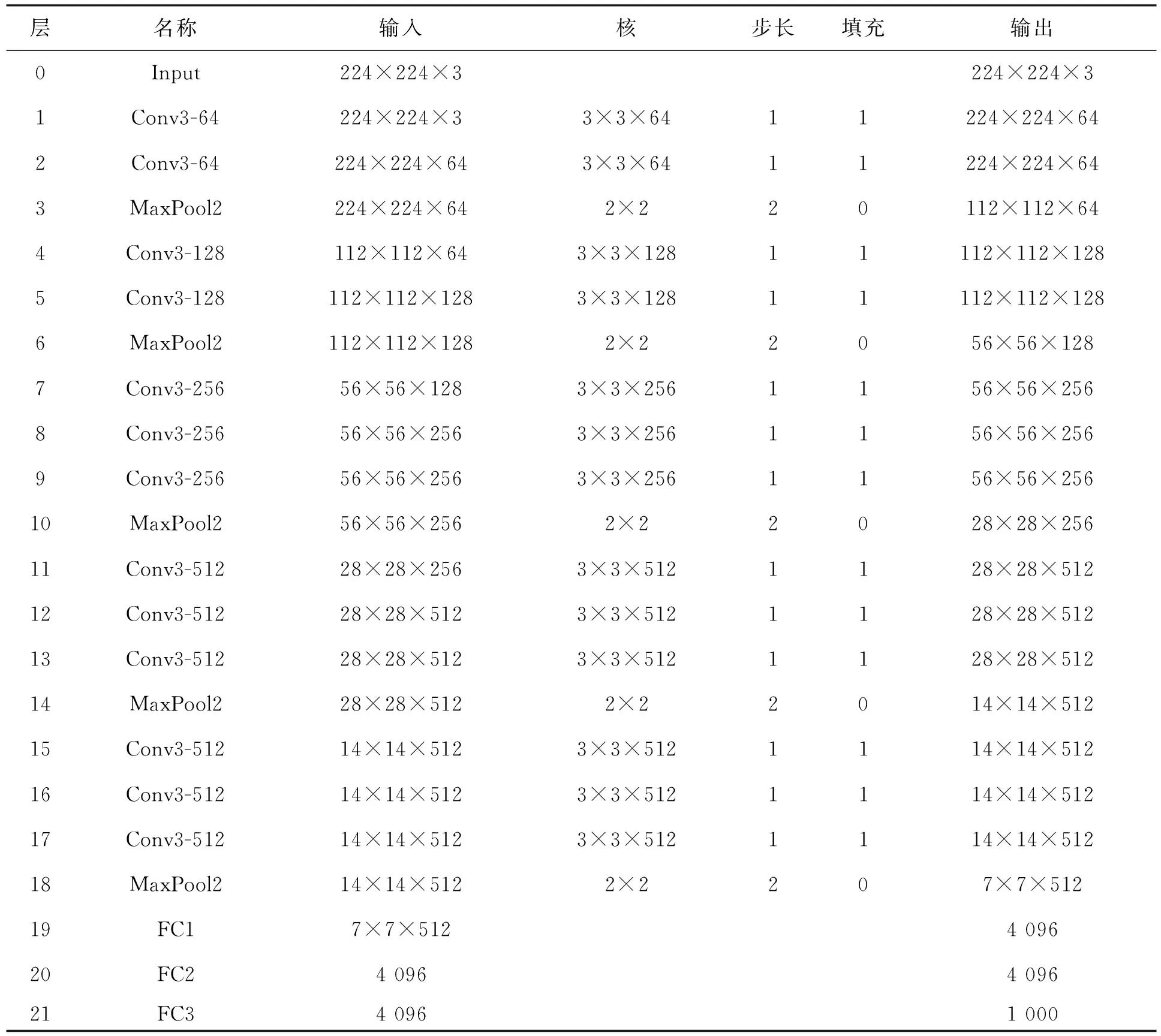
表1 VGGNet网络参数表
2 基于LiteVGGNet的人脸识别
2.1 VGGNet网络存在的不足
由于VGGNet具有良好的移植性、推广特点,文中选择VGGNet作为人脸识别的神经网络模型。VGGNet对于图像的特征提取效果出色,但存在以下不足之处:
1)网络层数较多,训练时计算量大,收敛较慢,需要大量的训练样本数据。
2)网络参数较多,存储网络所需的内存较多,训练时间也相对较长。
3)SoftMax训练出来的人脸识别模型性能较差。VGGNet采用SoftMax分类器对图像分类,SoftMax是逻辑回归的扩展,用于解决多分类问题[7]。对于普通图像分类,SoftMax简单有效,但是将其应用于人脸图像识别,由于人脸图像的特点是类内差异较大,类间差异较小,SoftMax训练得到的特征具有较大的类间距离,但类内距离不够紧凑,类内距离可能大于类间距离,容易导致人脸识别错误。
针对VGGNet存在的问题,对VGGNet进行改进,提出一种基于精简VGGNet的人脸识别算法,下面统称为LiteVGGNet。
2.2 网络结构改进
为了减少计算量,减小对大量训练样本的依赖,需要减少网络参数。从神经网络对图像特征的提取经验来看,越是靠近底层的网络,提取的特征越有效。VGGNet提取网络特征效果显著,为了保持这个特征,对底层网络不做变动,尽量修改上层网络。网络模型里面包含卷积层、池化层、全连接层。相对于卷积层,全连接层由于连接较多,会产生较多的参数,因此减少全连接层是减少网络参数最有效的办法。为了减少参数,参照模型DeepID,GoogLenet,减少三个全连接层为一个全连接层,同时修改全连接层前面的最后一个最大池化层为均值池化层,均值采样层的核大小为7×7。使用均值池化层替代最大池化层,可以最大程度地保持图像提取特征,这样可以在尽量保持网络特征提取能力的情况下,有效减少网络参数。改进后的网络结构如图2所示。

图2 减少全连接层后的VGG网络结构
改进前后的结构参数对比见表2。

表2 网络结构及参数对比
通过减少全连接层和使用均值池化层替代最大池化层后,参数值大大减少,参数个数从原来的138 M减少为16 M,这将有效减少模型计算的时间和保存模型参数所需要的存储空间。
2.3 损失函数改进
VGGNet采用SoftMax分类器对图像分类。SoftMax训练得到的特征具有较大的类间距离,但类内距离不够紧凑,类内距离可能大于类间距离,因此对于普通图像分类,SoftMax简单有效,但是由于人脸图像的相似性,容易导致识别错误。因此可以通过改进损失函数以增强分类效果。
为了得到更好的分类结果,应该将不同的类别分开,尽量减少类内距离。采用SoftMax Loss可以将不同类别分开,使用Center Loss可以使类间距离增大,同时减小类内距离。Center Loss是以SoftMax Loss分类为基础,针对每个分类,维护一个类中心。在训练时,逐步减少类成员到类中心的距离,并增大其他类成员和该中心的距离。
SoftMax Loss损失函数[7]为:
(1)
Center Loss损失函数[8]为:
(2)
混合损失函数为:
L=Ls+λLc
(3)
式中:λ——Center Loss的权重。
参照模型Caffe Face[8],对VGGNet最后的SoftMax分类层进行调整,修改为SoftMaxLoss和Center Loss联合监测训练,以达到更好的训练效果。改进后的LiteVGGNet网络结构如图3所示。
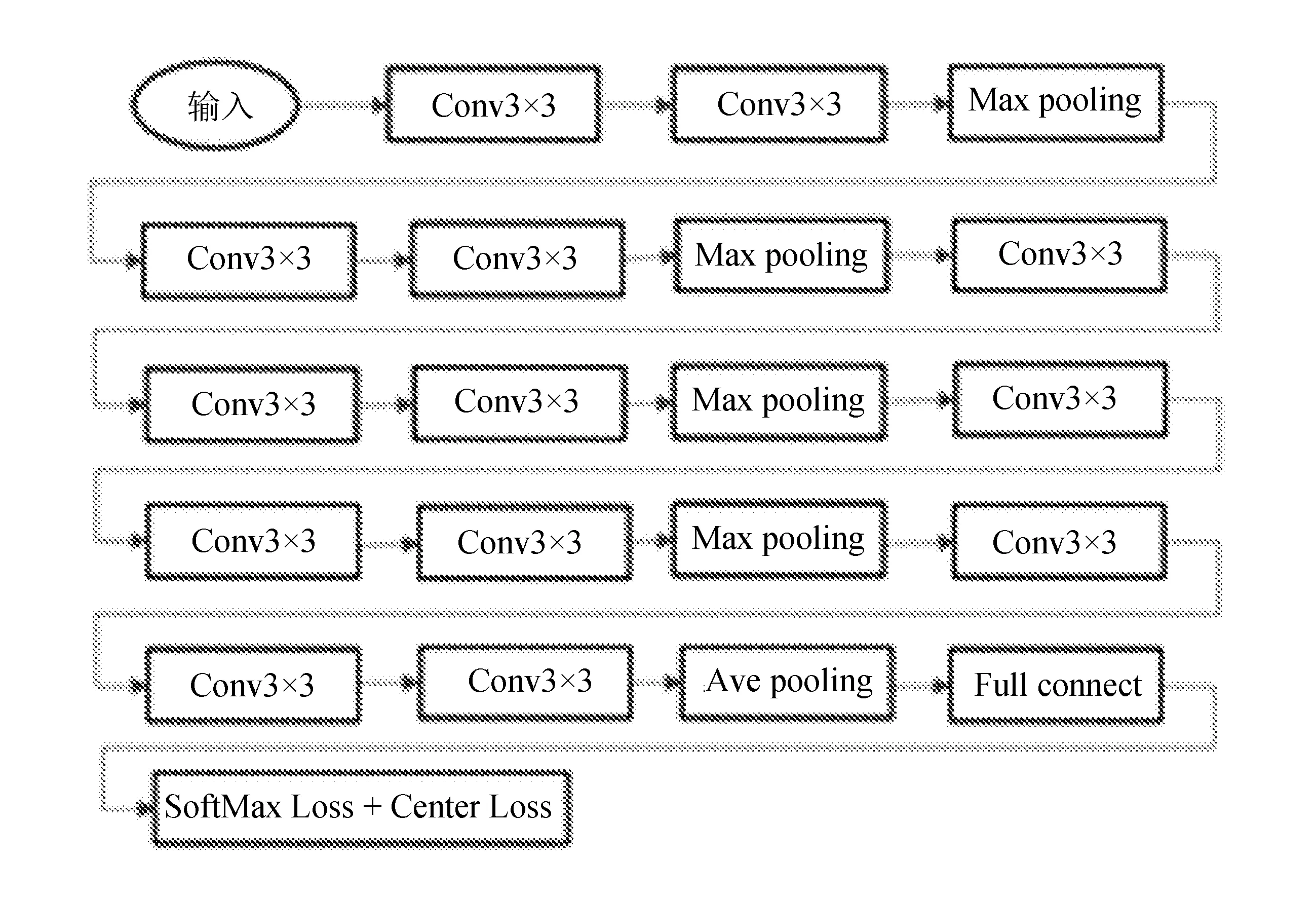
图3 LiteVGGNet网络结构
LiteVGGNet的网络参数见表3。

表3 LiteVGGNet的网络参数
3 模型训练和验证
3.1 模型训练
CASIA-WebFace是2014年中科院自动化研究所发布并建立的一个大规模人脸数据集。它包含将近50万张人脸图片,共10 575个人。文中采用CASIA-WebFace作为训练数据集,选取数据库中同一个人超过60张的人脸图片作为训练数据集。符合条件的人脸类别有2 007个,选取其中的2 000个人,每个人选取60张人脸图片作为训练数据,最终输出类别个数为2 000。DeepLearning4j(DL4J)是一套基于Java语言的神经网络工具包,可以构建、训练和部署神经网络。Deeplearning4j包括了分布式、多线程的深度学习框架,以及普通的单线程深度学习框架。定型过程以集群进行,因此Deeplearning4j可以快速处理大量数据,与 Java、 Scala 和 Clojure 均兼容,是首个为微服务架构打造的深度学习框架。这里选择DeepLearning4j作为深度学习平台。
训练之前,首先对图片进行对齐,图片对齐在人脸识别中是个较为重要的步骤[9]。这里采用人脸识别对齐工具对CASIA-WebFace人脸库进行对齐。对齐效果如图4所示。
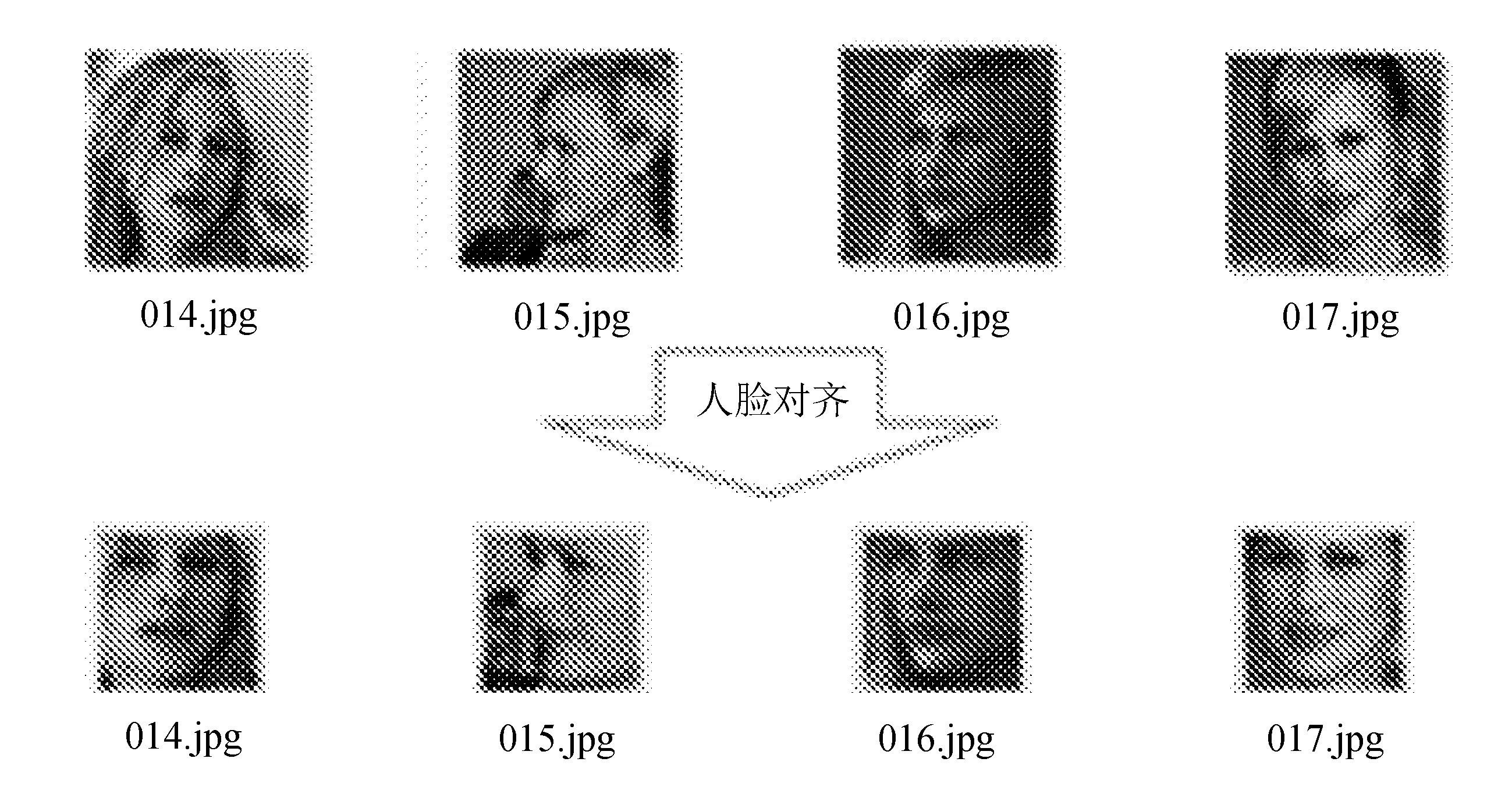
图4 训练数据人脸对齐
3.2 人脸识别验证
训练结束后,采用LFW(Labeled Faces in the Wild)人脸库作为模型结果验证。LFW人脸数据库是为了研究非限制环境下的人脸识别问题而建立。这个集合包含13 233张人脸图像,5 749个人,图像全部来自于Internet,而不是实验室环境。每个人脸被标注了一个人名。 其中有1 680个人包含两个以上的人脸。这个集合被广泛应用于评价人脸识别算法的性能。首先对测试人脸进行对齐,LFW的输入为两张人脸图像,输出为判断这两张人脸图像是否为同一个人。人脸识别验证过程如图5所示。

图5 人脸识别验证过程
LFW官方给出的测试数据集为pairs.txt,其中3 000对为同一个人,另外3 000对为不同人。实验使用pairs.txt给出的6 000对人脸对来测试网络模型的准确度。人脸图片通过深度学习神经网络提取后,得到人脸特征,计算两张人脸特征之间的距离,这里选择余弦相似度作为特征距离,同时根据阈值判断两张人脸图像是否属于同一个人。
在测试之前,对图片进行对齐。对齐工具使用Facetool,如果未找到人脸即对齐失败,则使用原图片代替对齐后的人脸图片。通过设定一个阈值T,计算结果大于T,则被视为正类;小于这个阈值,则被视为负类。若减小阈值,在可识别出更多正类的同时也会有更多的负类被误认为正类,真阳性率(TPR)和假阳性率(FPR)同时得到了提髙。若增大阀值,真阳性率和假阳性率会同时减小。因此通过逐渐増大阈值,会得到一条关于TPR和FPR的曲线,该曲线称作受试工作特征 ROC (Receiver Operating Characteristic Curve )曲线。ROC曲线是人脸识别灵敏度进行描述的功能曲线。大部分的人脸识别模型使用ROC作为评价标准。因此这里也采用ROC曲线作为改进后网络模型的评价标准。通过实验绘制出模型ROC曲线如图6所示。

图6 ROC曲线
使用测试数据集paris.txt对模型进行测试。测试结果见表4。

表4 LFW识别率
结合其他文献,将测试结果与其他著名人脸识别模型对比。对比结果见表5。

表5 网络模型识别效果对比
从表5中可以看出,相对于其他模型,LiteVGGNet模型的识别率达到了95%以上,虽然略微低于其他著名深度学习网络模型,但其训练样本个数和图片数量远小于其他模型,能够适用于训练数据集较小的应用场景,对硬件计算力要求更低,因此该模型具有一定的实用性。
4 结 语
目前深度学习算法存在依赖大规模训练数据和计算资源的问题。为解决这个问题,针对图像分类深度学习算法VGGNet进行改进,提出一种基于LiteVGGNet的人脸识别方法。改进后的算法采用CASIA-WebFace作为训练数据,并用LFW人脸库作为测试数据。实验结果表明,相对于原模型改进模型减少了参数,改进了损失函数,不但降低了对大规模训练数据库和计算资源的依赖,同时减少了类内差异,增大了类间差异,人脸识别性能较好,改进后的算法能够满足实际应用要求。
猜你喜欢
作文中学版(2022年1期)2022-04-14
少儿美术·书法版(2021年9期)2021-10-20
科技创新与应用(2021年23期)2021-08-30
小学生必读(低年级版)(2021年5期)2021-08-14
无线互联科技(2020年15期)2020-11-10
学生天地(2020年31期)2020-06-01
科技传播(2020年6期)2020-05-25
电子制作(2019年14期)2019-08-20
动漫星空(2018年9期)2018-10-26
雷达科学与技术(2018年3期)2018-07-18
