
基于语义的文献资源发现服务体系构建
2018-09-19 01:55:22刘爱琴于贾燕
图书馆理论与实践 2018年8期
刘爱琴,于贾燕,尚 珊
(山西大学经济与管理学院)
当前互联网上海量文献资源的品质参差不齐,导致用户无法及时有效地检索目标信息,文献资源发现服务体系服务效率低下,查准率较低,且无法实现对不同信息的统一访问。[1]基于语义的文献资源发现服务体系是借助人的智慧创建的依托于机器的智能化系统,提供人与机器之间信息通信的中介,可借助与客户检索文献信息相关的语义知识地图实现对知识的深度挖掘以及用户与计算机间对数据信息的一致理解和认识。本研究致力于在语义的基础上搭建将目标文献资源以“与用户检索内容相匹配的数字资源的全文信息PDF汇编文档”的形式,替代当前简单的检索目录呈献给用户的文献资源发现服务体系,进而根据用户需求实现知识重组,促进知识创造的发展。
1 国内外研究成果
语义Web起源于英国,由国际W3C主席Tim Berners-Lee首次提出,即给出一种机器可理解的描述资源的方式,在保证查全率的基础上大幅提升查准率。[2]当前,比较典型的语义数字资源服务系统有BRICKS、Fedora和JeromeDL。BRICKS是依托分布式开放结构的集成化整合文化知识服务资源建设的开源软件系统;[3]Fedora是基于Web2.0灵活可扩展的、通用的数字对象管理系统;[4]JeromeDL是基于语义Web的高互操作性、高可用性、开源社会化语义数字资源服务系统。[5]上述三个语义数字资源服务系统各具特色,对语义技术有较强的支持作用,为数字信息领域提供了典型的研究范例,具有极强的参考价值。
中国学者刘健等为应对传统数字文献资源内容推荐服务过程中无法充分挖掘资源语义信息等问题,提出对用户检索关键词实行语义扩展,并尝试采用全新的语义相似度计算方法,借助本体推理规则,计算文献资源内容相似度。[6]李佳南提出以用户需求为核心出发点,在馆藏资源特征分析的基础上提出语义知识库构建的方法,采用自底向上的构建思想构造层次化的馆藏资源语义知识库框架体系。[7]高俊峰提出一种基于语义标签的数字文献资源组织方法,力求为新技术标准下的数字图书馆知识服务工作的开展提供解决方案。[8]但令人遗憾的是,目前国内仍然没有学者明确提出构建基于语义的文献资源发现服务体系。
本研究尝试搭建实现转变关键词为主题词、对主题词进行科学切分和重组,从而能够根据用户需求实现知识重组、促进知识创造的基于语义的文献资源发现服务体系。该体系可以将匹配用户检索信息的相关数字资源以PDF文档格式条理化、可视化的形式呈献给用户,实现全文信息呈现替代当前的检索目录可视化,进而借助形象化、具体化的描述提高信息的可理解性和可认知性的程度,提高数字资源的有效利用率,以达到减少用户检索获取知识资源的时间与精力的目的。
2 基于语义的文献资源发现服务体系机理分析
提供基于语义的文献资源发现服务,更好地揭示数字文献资源的语义特性,实现由关键词到主题词的转变及主题词的切分和重组,深度集成和统筹互联网数字资源,反馈给用户可视化的目标文献资源全文信息。以语义Web技术为支撑,从用户层、检索层、语义分析层、预处理层、知识集成层五个层次挖掘并整合互联网数字文献资源(见图1)。
(1)用户在用户层进行检索查询时制定的检索策略会直接传递给检索层。该层是实现用户与机器直接信息交流的平台,若用户访问一个信息内容实例,则把该内容以指定的中介格式(PDF文档)反馈给用户。同时,该层还负责以动态跟踪的方式实时跟踪所提供的知识服务,以主动推送的方式优化知识服务,进一步提升用户满意度。
(2)检索层的检索工具将用户需求传递至推理机,提取需求特征后进行本体扩展,消除语义冲突和语义分歧等,并在服务器的基础上完成数字资源语义冲突的智能化识别和处理。从而在已经建立的语义化信息或知识及相关算法的支持下,实现用户需求的初步解读。用户需求数据库通过推理机传递的经解读分析后的数据信息了解用户对知识服务的需求,从而进行整理和储存。然后对用户感兴趣及习惯性的信息进行定期跟踪查新,并通过用户层及时将最新信息推送给用户。
(3)用户需求库将解读后的需求信息传输至语义分析层数据库,在语义Web技术的基础上,从索引库、主题词库、文献文档三个维度对匹配用户需求的相关文档进行语义方面的逐层解析,进而筛选调用语义标准化后的数字资源,形成基于XML的检索目录。
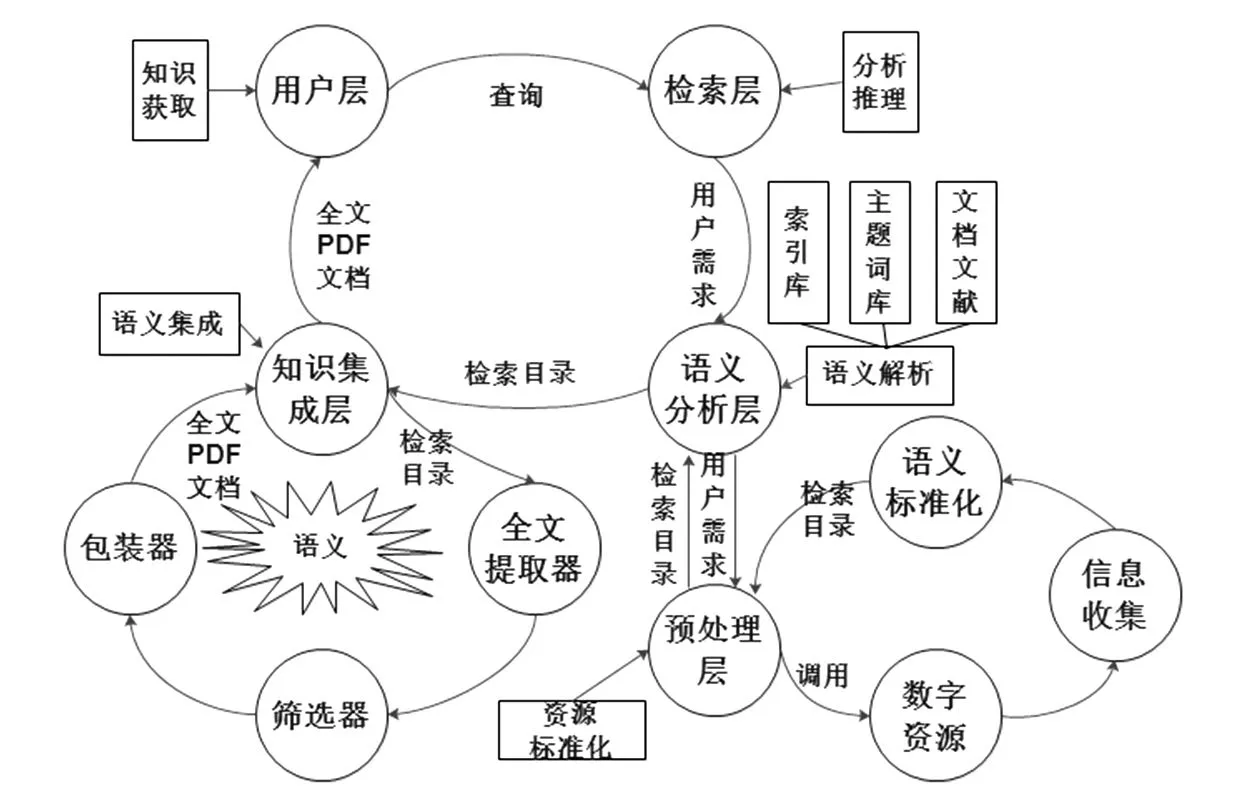
图1 基于语义的文献资源发现服务体系机理分析
(4)预处理层响应语义分析层的要求,收集为匹配用户需求而筛选调用的文献文档,然后借助语义Web技术对其进行解析处理,具体过程如下。① 在数字资源尾部找到属性标签;② 转入数字资源文档根对象;③ 转入数字资源文档页根对象;④ 转入内容对象,解读字体信息、位置信息和文本信息;⑤将所有内容对象的解码流连接起来,组成文本内容流。该层基于语义技术通过突破描述异构、传输异构、兼容异构、功能异构以及过程异构等多种语义本体异构问题,将解析后形式各异的馆藏数字资源用统一化、标准化、机器可理解的语言描述,为下一步的全文内容抽取奠定基础。
(5)知识集成层由提取器、筛选器和包装器三个模块构成,对语义分析层形成的检索目录中的资源进行全文内容获取,进而逐步实现推理解析、语义组别划分和知识单元关联汇总,基于数字信息资源聚类、分类和学习等算法研究,完成推理任务描述与分解技术研究,实现提取资源全文内容的生成、重用和演化,最终打包成包含匹配用户需求的所有文献文档全文信息的PDF集成文档呈现给客户,实现基于语义的智能化文献资源发现整合服务,更易于被用户发现和浏览。
3 基于语义的文献资源发现服务体系构建
实现高效准确的基于语义的文献资源整合及知识推送服务的前提是基于语义标准化数字资源的筛选凝聚,在实现由关键词到主题词转变的基础上,系统才能高效满足用户的深层次知识需求,增进知识认知、推动知识解读、促进知识整合、推进知识创作。基于此,本研究构建的基于语义的文献资源发现服务体系由用户层、检索层、语义分析层、预处理层和知识集成层五个层次支撑并实现(见图2)。

图2 基于语义的文献资源发现服务体系模型
(1)用户层。该层与检索层紧密相连,根据用户的检索需求,准确得到用户目标信息,高效、可视化地反馈给用户与检索信息相匹配的文献资源PDF整合文档,这也是整个基于语义的文献资源发现服务体系中最能直接体现其高速、高效、高水准知识服务的模块。
(2)检索层。该层主要发现、解析并整合用户的检索需求,具体流程如下。① 用户在用户界面上的检索栏通过关键词检索、模糊检索、相关机构检索等检索方式进行查询检索。基于语义的文献资源发现服务体系在用户层可实现动态自适应界面功能,并将用户需求传递至检索工具。② 推理机可实现将事实查询和本体概念合并为一个查询,经推理机借助领域本体规则,获取用户需求概念后依次进行特征描述、特征提取、概念扩展等处理,进而推理整合分析后,将用户需求、用户偏好、用户特点等信息汇总至用户需求库。③ 系统自动将用户需求库汇总所得到的信息传递到语义分析层的特定数据库进行匹配,进一步分析处理后调用语义标准化后的文献文档数据资源。
(3)语义分析层。该层基于语义Web技术首先从索引库、主题词库、文献文档三个维度对需匹配用户需求的相关文档展开解析处理,并对书目进行层次划分处理,分离属性特征,概括并提取实体和属性的语义关系,构建相应的数据库,包含关键词表、作者表、期刊表、引文表等。数据库进而筛选调用预处理层语义标准化后的数字资源,将关系型数据库中的数据换成RDF格式,以RDF有向图的形式描述和表达各种关系;借助固定的、普遍的词汇集实现概念规范,形成立体的组织模式;最终采用XSLT和XPATH(W3C协会提供)语言实现XML的目录层集成,实现相关信息检索目录的可视化。
(4)预处理层。该层次的任务是回应语义分析层的需求,将数据库所需筛选调用的文献文档预先进行标准化处理。① 收集并整合馆藏数字资源,通过Spider实现任务分发,借助CNKI、万方、维普和其他收集整理模块形成源数据,包括结构化数据和非结构化数据。② 由于源数据存在格式不一致的问题,必须进行数据标准化处理,消除数字资源之间的异构特性。为简化语义分析层的标准化步骤,省去不必要的麻烦,故在该层事先进行数据预处理。将出处各异、结构不同、格式不一、类型多样的海量数字资源进行统一描述,确定各独立资源节点、知识要素之间的语义关联,保障其具有一致的标准,为计算机识别与知识细粒度化提供便利。
其中,语义标准化的具体过程如下。① URI、U-nicode在整个语义Web结构中处于最底层URI对Web上所有资源进行统一描述,保证唯一标识其中任意一个资源,借助链接实现资源的引用;Unicode为确保机器能有效地识别资源编码而使用国际上的通用字符集。② XML为文档提供结构化的语法,借助URI实现引用标识,达到资源存储方式的统一。③ RDF(S)是一种借助数据模型提供简单的语义资源描述框架,实现资源描述方式的一致化。④ 本体层通过提供确切的形式化语言,帮助准确定义术语及术语间的关系。⑤ 逻辑、证明和信任。逻辑层主要负责推理规则,证明层注重认证机制,信任层着重信任机制。⑥数字签名的本质是一段数据加密块,是实现Web信任的关键技术和基础。
(5)知识集成层。该层是实现基于语义的文献资源发现服务体系与其他知识服务不同的关键所在。分别通过提取器、筛选器和包装器三部分对检索目录中的资源进行全文内容提取、语义组别划分和知识单元关联汇总,最终提供给用户匹配其检索内容的文献资源PDF集成文档。① 提取器借助由W3C协会提供的RDF和SOAP对检索目录中的资源实现全文内容提取。进而采用OntoBroker推理引擎对资源全文内容进行深度推理解析,动态识别资源主题,包括关键词和主题词,集成资源的核心研究问题、主要研究方法以及主要技术与工具。作为一个面向对象的逻辑推理系统,OntoBroker可以实现以数据库现有知识为基础提取新知识的功能。② 系统通过筛选器对提取器所得数据单元进行筛选整合,将推理扩展得到的内容在层次深度、区域密度、概念属性三方面进行语义相似度计算,进而实现资源相关度计算,并按专题、年份、作者或其他因素进行语义组划分,接着将相似文档聚类成组。③ 通过包装器,对同组别知识单元实现关联,采用K关联/S关联等技术过程中通过补充关键词、对摘要和题名进行切分词处理等方式,实现对信息资源已有知识的发现与重组,进而形成全新的知识元,完成深度聚类和数据关联。
区别于传统的聚合方式,基于语义关联的知识聚合主要从数字资源的概念关系、引证关系、等级关系、映射关系等层面进行语义分析,然后提取语义元数据与异构信息接口,解决异构数字资源之间的语义冲突,进而实现基于语义关联的知识聚合。同时,突破篇名、作者、机构、内容知识单元、来源出版物和参考文献等传统题录项之间的显性关系构建,借助语义消歧、关系约简及重构等方式综合了题目、目录、关键词、数据、主题词、内容等多种类型外部特征与语义元素之间的关联方式,实现动态、多维的知识关联。
最后,借助文件打包器对聚合的文档进行汇总打包,实现智能、可视化知识获取,将目标资源的全文信息以PDF文档格式条理化、可视化地呈献给用户。取代先前简单的检索目录,用户即可获得与其查询内容相匹配的文献数字资源的全文信息PDF汇编文档,以期给用户带来更加智能化、便利化、柔性化的文献资源发现服务。
4 总结与展望
针对当前数字文献资源数据整体上不能实现互相关联,只能实现局部范围内组织的现状,导致形成了大量分散、相互独立的信息孤岛。本研究专注探索如何借助语义Web技术对数字文献资源进行统一描述、统一汇编等问题,为完成打造一个能够实现语义功能的数字资源服务平台的任务,搭建了一个基于语义的文献资源发现服务体系。该体系核心是基于语义元数据的构建与关联实现与检索目标信息相匹配的数字文献资源的全文内容PDF文档汇编,替代当前简单的检索目录。不可否认,语义Web的产生是搭建文献资源发现服务体系的一个良好契机,提供了预处理层的语义级支持。在此基础上,本系统匹配更加自动化、智能化的技术,如,高精度的知识筛选聚合技术、深层次的推理技术、高水平的可视化技术等,解决了传统数字文献资源服务推荐过程中存在的无法充分挖掘资源语义信息等问题,为用户提供更加便利化、柔性化的知识服务。基于语义的文献资源发现服务提升了数字文献资源的筛选利用与整合汇编的效率,为知识汇总与获取提供了有效的途径,保障用户能够高效率地知识选择、知识摘录、知识利用、知识转化、知识表达和知识创新。
猜你喜欢
中国交通信息化(2022年5期)2022-07-23 08:21:58
中国新闻周刊(2021年26期)2021-07-27 04:02:12
人大建设(2019年5期)2019-10-08 08:55:18
人民调解(2019年3期)2019-03-16 00:22:32
信息安全研究(2016年4期)2016-12-01 06:06:54
Asian Pacific Journal of Reproduction(2015年1期)2015-12-22 12:09:35
西北工业大学学报(2015年1期)2015-02-22 00:29:19
西北工业大学学报(2015年1期)2015-02-22 00:29:19
中国卫生(2015年1期)2015-01-22 17:20:15
沈阳医学院学报(2014年4期)2014-12-27 13:44:34
