
图书馆大数据知识服务情境化推荐系统研究
2018-09-19 01:55:20刘海鸥孙晶晶张亚明
图书馆理论与实践 2018年8期
刘海鸥,陈 晶,孙晶晶,张亚明△
(燕山大学 a.互联网+与产业发展研究中心;b.经济管理学院)
1 引言
随着大数据时代到来,图书馆知识服务面临两个日益凸显的矛盾,其一是知识爆炸性增长与用户选择能力局限性之间的矛盾,其二是信息量极度丰富和用户感兴趣信息局限性之间的矛盾。图书馆大数据知识服务的个性化推荐技术是解决该问题的一个有效工具。图书馆大数据知识服务的个性化推荐是将读者兴趣、知识领域等关联信息加工为能够生动描述读者偏好的知识元,由此来支持数字图书馆各种推荐服务,最终为用户提供满足其个性化需求的知识资源。面对海量的知识资源,用户的需求并非一成不变,会随着其所处的环境与场景(情境)而发生变化。有研究表明,[1,2]用户这种情境的变化对其个性化需求会造成不同程度的影响。但目前大多数图书馆对情境因素的感知能力不足,因此难以为图书馆用户提供与其情境最为匹配的精准个性化服务。
为解决个性化推荐系统存在的“情境缺位”问题,国外学者Mallat等[3]在其构建的个性化推荐系统中对用户的情境信息进行了定义,可根据用户当时所处的情境来进行个性化推荐;Adomavicius等[4]在研究过程中引入了用户的购买时间,将其作为情境变量来构建集成用户情境的协同过滤推荐模型;Anand等[5]在研究中讨论了如何在推荐系统中对情境进行模拟的问题,基于此提出了融合用户情境信息的推荐方法;Bao等[6]通过研究提出了一种无监督方法,由此来对移动用户的个性化情境进行实时模拟;Sen[7]、Karatzoglou[8]、Rendle 等[9]也各自在其推荐系统中融入了用户情境信息,由此提出情境感知推荐方法、融合情境的多元推荐方法以及基于情境分解机的推荐方法。
在图书馆个性化服务推荐研究领域,我国学者郭顺利、李秀霞[10]探讨了图书馆用户信息需求的情境敏感性以及推荐即时性特点,基于此提出了图书馆用户信息需求模型,并通过实验验证了情境要素对提升图书馆个性化推荐质量的关键作用;毕达天、晁亚男[11]在数字图书馆用户兴趣建模过程中,从用户情境偏好的角度出发,探讨了数字图书馆资源情境对用户接受推荐结果的重要影响;李静云[12]构建了用户情境感知的图书馆知识推荐系统,以此来提高图书馆知识推荐的针对性与准确性;张文萍等[13]进一步分析了影响数字图书馆个性化知识服务的多个情境因素,基于此探讨每个情境维度对知识服务个性化推荐的影响;周玲元[14]探讨了移动环境下的情境感知计算流程,基于此构建了图书馆联盟情境感知推荐系统;曾子明、陈贝贝[15]从智慧图书馆建设的角度出发,提出构建智慧图书馆情境感知的个性化服务推荐系统,通过深层次融合情境信息为广大用户提供与其情境更为匹配的智慧信息资源,从而实现精准个性化服务;胡慕海等[16]通过研究提出了基于信息熵的用户情境敏感性度量方法,由此对用户进行相似性计算,该方法在一定程度上提高了图书馆知识推荐精度,有利于为用户提供满足其个性化知识资源。
综上所述,国内外学者已对融合情境信息的协同过滤(Collaborative Filtering,CF)推荐进行了一定的研究,也有部分研究在图书馆个性化推荐系统中引入了读者的情境信息。但是当前大多数研究主要通过用户静态信息与评分项目进行推荐,对图书馆用户的位置情境、时间情境、业务关联情境等挖掘不够深入,图书馆推荐服务中的情境信息共享、情境兴趣建模以及情境感知的个性化服务机制等问题仍需要进一步研究。[17]此外,图书馆用户的行为数据与情境信息在大数据环境下呈指数式爆炸性增长,这极大增加了从海量数据中挖掘用户情境兴趣与相关知识的难度,且项目评分的稀疏性问题也愈加突出。鉴于此,本研究在传统推荐算法中引入图书馆用户的情境信息,提出面向图书馆大数据知识服务的情境化推荐系统,采用大数据MapReduce处理技术实现协同过滤算法的并行分布式推荐,最后给出推荐结果。
2 图书馆大数据知识服务情境化推荐系统设计
在借鉴分布式架构、用户个性化兴趣建模以及CF推荐技术的基础上,本研究提出面向图书馆大数据知识服务的情境化推荐系统架构(见图1)。

图1 面向图书馆大数据知识服务的情境化推荐系统架构
从图1可以看出,图书馆情境化服务推荐系统部署在Hadoop分布式环境下,对推荐系统而言,随着图书馆用户服务请求规模的不断增加,其面临的大数据处理压力也逐渐增大。此时,Hadoop分布式处理的计算优势就得以充分发挥,它可以将图书馆用户服务请求部署到Hadoop集群进行处理,通过横向扩展Hadoop节点数量,增加集群并行计算性能,以此缓解推荐系统面临的大数据处理压力。具体来讲,面向图书馆大数据知识服务情境化推荐系统包括如下模块。
(1)图书馆用户大数据获取与存储模块。数据获取模块的主要目的是提取图书馆用户相关数据,同时将其存储到Hadoop相应的存储模块中。鉴于面向图书馆大数据知识服务的情境化推荐系统需对用户的即时兴趣迅速作出回应,因此对数据存储层的响应时间提出了较高要求。Hadoop中的HBase分布式存储面对海量数据具有快速的服务响应能力,因此可通过横向扩充集群节点来实现图书馆用户大数据的存储。
(2)情境兴趣建模模块。图书馆大数据知识服务情境化推荐系统的核心模块为情境兴趣建模,即如何融合图书馆用户的情境信息进行情境兴趣建模,并基于此缓解数据稀疏性导致的推荐性能下降问题。
(3)并行推荐模块。大数据环境下,协同过滤的挖掘速度与推荐系统的运行效率遇到了极大挑战。本研究引入MapReduce大数据处理工具对传统的协同过滤推荐方法进行改进,以此提高图书馆用户大数据的并行挖掘精度以及推荐系统的运行效率。
(4)情境化服务推荐引擎模块。本研究构建的图书馆推荐系统的推荐引擎主要对系统前端接收的图书馆情境化服务请求做出回应,推荐系统服务接口再使用情境化推荐方法进行推荐,最终将计算出的推荐结果提供给用户。
3 大数据的获取与存储
大数据技术的出现促使图书馆数字资源间的协同与互联达到前所未有的深度和广度,尤其是移动阅读终端的多样化和普及化为我们带来了多领域、立体化、全方位的图书馆大数据。对图书馆而言,可实现其情境化推荐服务的大数据资源主要包括:用户基本数据、用户行为数据、图书馆知识资源数据以及用户情境数据(见表1)。

表1 图书馆大数据资源类别划分
表1中的用户个人信息主要体现图书馆用户的性别、年龄、专业等,此类信息可通过系统的注册信息获取,行为数据以及知识资源数据可通过Cloudera提供的Flume系统进行采集。其中,Flume是一个开源的分布式海量日志收集系统,该系统将定期分布式存储用户的访问日志,以供后续的跟踪和分析使用。用户情境信息是本研究重点关注的要素,主要包括时间信息、地理位置信息以及环境信息,其中,时间信息和位置信息也可合称为时空情境。时空情境既包括绝对时空信息(可确切且可量化的时空信息,如,东经12.3度,北纬45.6度、样本阅览室101、图书馆入口以及确切的年月日等),还包括相对时空信息(模糊描述时间与位置的时空信息,如,图书馆一楼、图书馆大门200米处、暑假期间等)。时空数据主要可根据定位技术获取,如GPS、北斗、RFID、无线网络基站、WiFi、传感器等。环境信息主要客观描述用户所处的自然条件,如,用户周围的温度、湿度、光线、噪声、天气状况等,这些数据可以通过传感器、用户手持的智能终端设备直接获取。
此外,Hadoop的持久化分布式文件系统(Hadoop Distributed File System,HDFS)解决了图书馆大数据的存储问题。HDFS特别适于存储数据查询要求不高的图书馆信息,如,图书情报学界近年来重大新闻信息、行业发展动态信息等。对于分布式存储的高级应用,HBase具有类似关系型数据库的服务功能,其列式存储也非常适用于大规模本体数据的存储、查询以及实时更改。图书馆大数据的HDFS存储机制具体如图2所示。

图2 图书馆大数据知识服务的HDFS存储机制
4 用户情境兴趣建模
用户情境兴趣建模是大数据知识服务情境化推荐的核心部分,本节对其进行细致描述。
在情境化推荐系统中,根据图书馆用户所处的地理位置、环境温度、服务时间等不同类型的情境,本研究使用向量计算公式将其标记为Context={C1,L,Ci,L,C}n。其中Ci表示某一情境属性的向量,可以体现图书馆用户当前的时间信息、位置信息、活动状态等。如在C={c1,L,ci,L,c}n这一情境实例,ci体现的是情境属性Ci的具体属性值:若Ci为位置情境,则ci可表示东经12.3度、图书馆101、图书馆入口等。Contextx和Contexty则表示两种不同的情境,其相似度本研究记为Sim(Contextx,Context)y,Simk(Contextx,Context)y则表示情境Contextx和Contexty在k类情境背景下比较的相似程度。鉴于图书馆用户是在一定情境下对项目进行评分,且该情境信息将对用户评分产生影响,因此本研究在评分过程中引入了图书馆用户的情境信息,由此来对传统CF的用户—项目评分矩阵进行扩展,形成用户—项目—情境评分矩阵,也就是将情境信息ContextK融入到原先图书馆用户的每一个项目评分中去,实现融合情境兴趣的图书馆个性化推荐。具体而言,就是建立“用户—项目—情境评分”的三维量空间模型:{User,Item,Context},三个维度用户、项目、情境评分分别由各自的属性值构成。
首先,获取用户—项目评分矩阵及评分时用户所处的情境。在建立图书馆用户情境化推荐模型时,先建立传统的用户评分矩阵 ,该矩阵反映了用户User对项目Item的评分情况,如公式(1)所示:

其中,用户ui对项目sj的评分使用表示,用户ui的平均评分使用表示,用户uj的平均评分使用表示。
然后,根据用户在不同情境下对相同项目的不同评分,采用Pearson相关系数度量公式计算同一用户的不同情境相似度,具体如公式(2)所示。
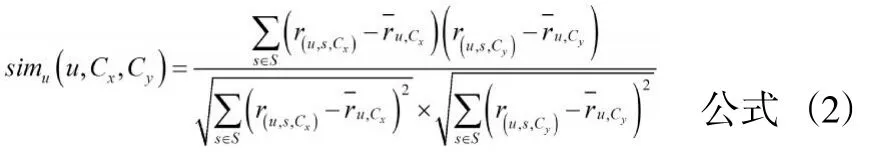
公式(2)中,S表示目标用户u在情境Cx和情境Cy都有评分值的项目集合;表示用户项目在情境下的评分值;则表示平均评分值。
最后,计算与目标用户u的近似情境集合。大数据知识服务环境下,由于图书馆用户在不同情境下共同评分的知识服务资源项目很少,这样就很难获得与目标用户u相近的情境集合。为解决这一问题,本文采用余弦相似性公式对情境Cx和情境Cy的余弦相似度进行计算,具体如公式(3)所示:

通过公式(3),可以得出与目标用户u当前情境最接近的近似情境集合,然后进行情境化协同过滤推荐,最后给出Top-N的推荐结果。
5 大数据的并行处理与推荐
由于本研究提出的情境化推荐面向的是海量数据,仅通过单机运行的协同过滤推荐方法难以进行有效的图书馆大数据知识挖掘。鉴于此,引入了大数据并行处理技术,利用Hadoop分布式环境下部署本文构建的图书馆情境化推荐系统,通过MapReduce对CF推荐方法进行并行处理,从而改进海量数据环境下CF推荐系统的挖掘性能与可扩展性。
图书馆情境化推荐的大数据并行处理与挖掘过程主要包括两个环节:第一步使用MapReduce大数据处理方法计算用户—项目评分矩阵的相似度;第二步通过相似度对未评分项目进行评分预测。在计算图书馆用户—项目评分矩阵相似度时,本文输入的键值对以〈null,(User,Item,Score)〉 的形式表示,输出的键值采用〈(Item1,Item2),Sim〉表示。该阶段的并行计算可通过两个MapReduce任务来实现,第一次MapReduce主要汇总图书馆用户对项目的评分信息,然后进行排名;其中的Map函数将输入的图书馆用户信息与项目打分信息转换为相对应的键值对,Reduce函数则合并具有相同用户的打分项目,具体过程如表2和表3所示。第二次MapReduce致力于计算项目间的相似度,将图书馆用户和各项目间(User and Item)的键值对转换成项目和项目间(Item and Item)的键值对,具体是采用Map函数获得各Item间同一User的评分,利用Reduce函数计算项目之间的相似程度。通过两次MapReduce处理后,可得出相似度的计算结果以及各Item的相似度列表。最后,根据MapReduce计算得出的图书馆用户的推荐评分相似列表,使用Map函数进行CF推荐,并通过Reduce函数输出推荐结果,具体计算过程如表4和表5所示。
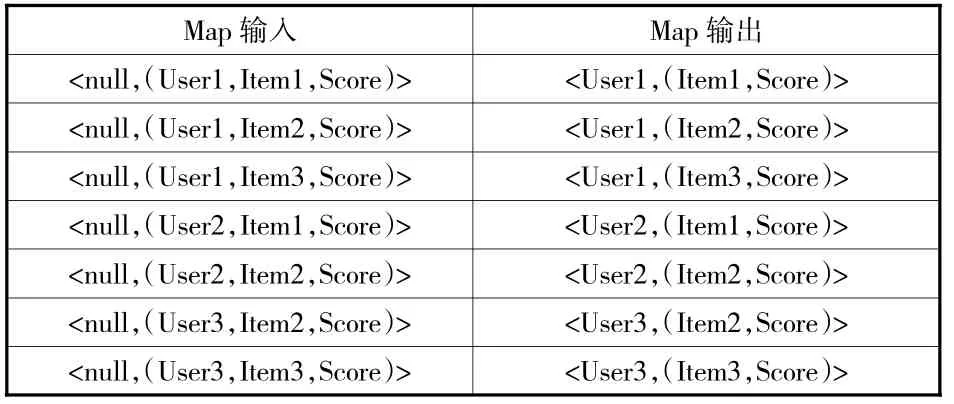
表2 第一次MapReduce的Map阶段

表3 第一次MapReduce的Reduce阶段

表4 Map函数的CF推荐阶段
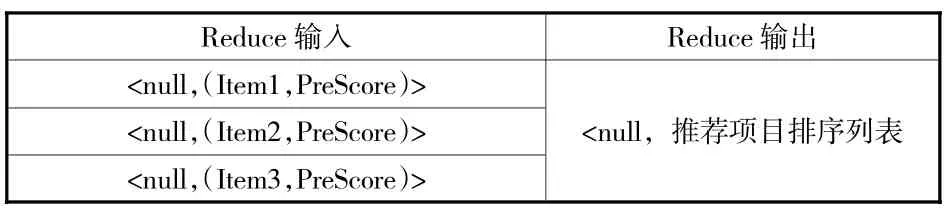
表5 Reduce函数的推荐结果输出阶段
具体而言,首先将第三部分获得的图书馆用户行为、相关图书评分等大数据知识服务信息引入推荐系统,在进行第四部分的情境兴趣建模时,引入时间或者其他情境要素的评分权重,由此可以获得Top-N的推荐结果。在大数据的处理与挖掘过程中,原始输入的参数为(Reder,Book,Score),通过 MapReduce将获得以Reder为Key值、(Book,Score)为 Value值的输入,然后利用情境相似度公式获得用户u对图书项目b的兴趣度Pref;以此类推,可获得u所有的图书项目历史浏览信息 ((Book1Pref1),(Book2Pref2),L (BooknPrefn)),采用Map输出相似度计算得出的键值对,通过函数Reduce汇总并输出以Book为 Ket值,以{(book1n1),(book2n),L (booknnn)} 为 Value值的键值对,最终得到用户u的图书相似度矩阵和Top-N的推荐结果。
6 并行推荐效果的检验方法
本研究实验评价标准主要包括两个方面:首先测试基于Hadoop的大数据并行挖掘有无提升模型计算的性能;其次是测试情境化推荐对数据稀疏性导致推荐精度下降的缓解情况。
作为并行计算测试的评价指标,加速比主要用来对比单机与并行计算两种不同环境下特定算法运行所耗费的时长,其计算方法为单机运行时间与并行运行时间两者之间的比值:S=T(1)/T(N)。其中,T(1)为算法在单机环境下的运行时间,T(N)为多机并行处理的时间,两者的比值结果即为加速比。此外,为了对比Hadoop环境下不同数目节点对并行计算结果的影响,还引入了相对加速比指标:S相对=T(单DataNode)/T(多DataNode)。其中,S相对表示相对加速比,T(单DataNode)表示单机运行的时间,T(多DataNode)表示多DataNode集群运行的时间。
在推荐性能测试方面,使用最为常见的平均绝对偏差MAE、用户覆盖率Coverage以及P(u)@N。MAE表明预测评分与实际评分间的偏差程度,MAE越小,表明算法给出的推荐结果约接近于实际情况,两者误差也就越小。MAE的计算公式为:MAE=/N。其中,{P1,P2,…,PN},为算法预测得出的用户评分集合,{q1,q2,…,qn}为实际用户评分集合。覆盖率指标主要衡量对数据集的覆盖范围,本文采用Coverage表示,计算公式为其中,测试实验执行次数使用n表示,算法计算得出的用户预测评级使用pi表示。而P(u)@N则表示推荐列表中与目标用户u当前情境相符合的用户需求项目数与N的比值,计算公式为:P(u)@N=(relevent items intop nitemsforu)/N。
猜你喜欢
福建中学数学(2023年5期)2024-01-25 17:41:36
中学生数理化·中考版(2022年10期)2022-11-10 09:37:46
文苑(2020年4期)2020-05-30 12:35:12
新闻传播(2018年12期)2018-09-19 06:27:10
小太阳画报(2018年1期)2018-05-14 17:19:25
护士进修杂志(2017年3期)2017-02-14 07:19:35
汽车与新动力(2016年6期)2017-01-04 10:50:48
少年博览·小学低年级(2016年10期)2016-11-24 06:48:23
小学生作文(中高年级适用)(2016年3期)2016-11-11 06:30:23
中国卫生(2015年1期)2015-01-22 17:20:15
