
基于近似最近邻搜索的并行光流计算
2018-09-18 02:12杨昕欣姜精萍
计算机工程与应用 2018年18期
杨昕欣,姜精萍
北京航空航天大学 电子信息工程学院,北京 100191
1 引言
1.1 光流计算简介
光流(Optical Flow)的概念是Gibson于1950年首先提出的,它是由相机和场景相对运动产生的,表示的是图像中各像素瞬时相对运动的速度情况。光流场是指图像灰度模式的表面运动[1]。光流计算是当今计算机视觉的热点之一,光流算法被广泛应用于运动目标检测与跟踪[2]、机器人导航[3]、三维重建[4]等领域。20世纪80年代初期,Horn和Schunck[5]提出了建立在光流平滑性假设基础上的稠密光流算法,为光流计算的发展起了奠基性作用,之后学者们相继提出了多种计算光流的算法,Barron[6]等人根据数学方法和相应的理论基础,将计算光流的方法分为基于梯度的方法、基于块匹配的方法、基于能量的方法和基于相位的方法。
与其他计算光流的方法相比,基于块匹配的光流法具有运算速度快、易于硬件实现的优点。块匹配是图像处理中很常见的一种问题,尤其在视频编码中的运动估计中应用广泛,许多年来,学者们已经提出了许多块匹配的算法,如双十字搜索法[7]、六边形搜索法[8]、十字-菱形搜索法[9]等。为了进一步提高运算速度,学者们提出了近似块匹配算法,如局部搜索[10]、降低维度[11]等,虽然这些方法得到的结果只是精确匹配的近似,但由于其大大减少了运算量而被广泛应用于各种高层图像处理中。最近,Barnes[12]等提出了一种近似最近邻域块匹配算法,该算法利用了图像的局部相关性,基于“相邻块的最近邻域也是相邻的”这一假设,将前面已经匹配好的结果传递给相邻块,与其他近似块匹配算法相比,该算法利用了块匹配的特性,极大地减少了运算量,本文将其应用于光流计算中。
1.2 Barnes近似块匹配算法
Barnes近似最近邻搜索算法利用了块匹配结果的特点,即相邻的查询块的匹配块也有很大的可能性是相邻的。同时Barnes算法还基于另一个假设:大范围随机的初始坐标也可能包含有某些块的正确匹配块的坐标。
该算法首先定义了一个最近邻域场NNF(Nearest-Neighbor Field)。假设查询图像为A,参考图像为B,每个图像块的块坐标用其中心点的坐标表示。NNF是方程 f:A↦ℝ2,定义域为A中所有块可能的坐标,值域为匹配块相对于查询块的坐标偏移量,如果查询图像A中坐标为a的查询块的最近邻域块为在参考图像B中的坐标为b,则有:

给定某一特定距离计算函数E,E(f(a))表示查询图像中坐标为a的块与参考图像中坐标为a+f(a)的块的误差,一般用欧式距离。Barnes算法包括初始化和迭代修正两个阶段。
初始化是将NNF初始化为随机的值或是使用先验知识。例如,采用参考图像B中全部区域的独立均匀采样偏移值,作为NNF的初始值。
迭代修正包括传播和随机搜索,这两个步骤交替进行,对NNF进行修正。传播:假设当前要计算的是点p(x,y),可以利用 p的相邻像素来改善 p的结果,因为对于相邻的像素来说,其偏移量是差不多的。对于p来说,f(x-1,y)和 f(x,y-1)是已经计算好了的结果,可以用它们来修正当前块 p的匹配结果 f(x,y),即令
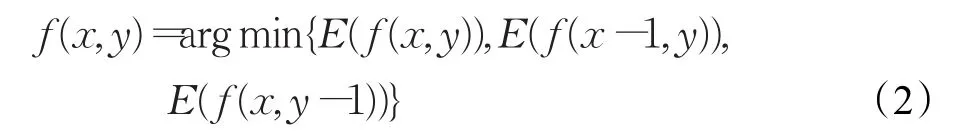
这样做的意义在于,如果(x,y)的映射是正确的,但其相邻区域ℝ的映射不正确,这样做之后,ℝ区域右方和下方的点都能得到正确的映射值。进一步,在奇数次迭代中采取右下方向的传播,在偶数次迭代中采取左上方向的传播,这样就解决了修正过程中的方向问题。随机搜索过程是以当前查询块的最近邻域值为中心,在一个窗口大小指数递减的搜索窗内随机搜索候选块,利用这些候选块来改善当前查询块的匹配信息。候选块产生方式如下:

其中v0=f(x,y),Ri为内的一个均匀采样的随机点,w为搜索窗大小,为图像的宽度和高度中的最大值,α为搜索窗半径衰减率,i=1,2,…直到wαi的值小于一个像素。
2 基于Barnes算法的块匹配光流法
本文参考facebook在surround 360中的源码,将Barnes算法应用于计算稠密光流时,有以下三个调整。
2.1 基于梯度的匹配准则
Barnes算法中的误差计算函数D常用的是绝对误差和准则(SAD),SAD在块匹配中应用的最多,因为其不需要进行乘法计算,因此节省时间容易实现。SAD公式表示为:

其中块大小为M×N,块的运动矢量即为SAD最小时的 (u,v),即

SAD虽然常用,但当场景中存在光照变化时,得到的光流场会有明显的离散化,因此本文使用另一种匹配准则,基于梯度守恒的准则[13]。
图像序列可以看成是图像灰度值与时间、空间位置的函数,可以将图像中像素点的灰度值表示为函数的形式:

使用泰勒公式将 f(x+u,y+v,t+Δt)展开,忽略高阶无穷小项并认为时间无限趋近于0,得到:
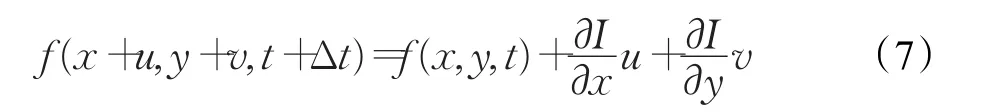
将式(7)代入式(6),得到:
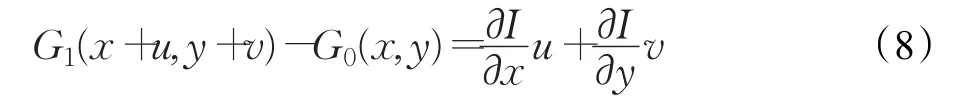
将式(8)代入式(5)中,得:
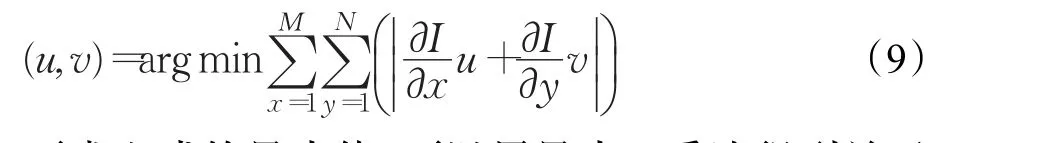
要求上式的最小值,可以用最小二乘法得到关于(u,v)T的非齐次方程组,然后可以得到新的匹配准则
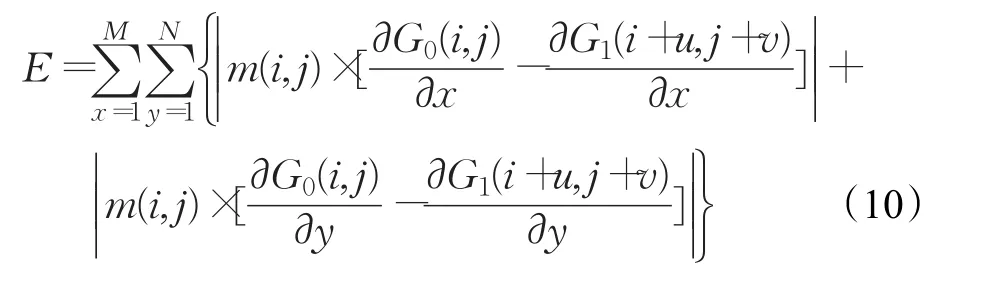
其中m(i,j)代表窗口权重,表示了块中每个像素点对匹配结果的影响,在实际计算中,一般用以ρ为半径的高斯函数代替,并计算高斯函数与图像序列梯度差值之间的卷积。可以看到,在新的匹配规则中,匹配块与待匹配块之间的差异只由图像的梯度决定,而不是灰度。而光照会对图像的灰度产生影响但不会对图像的梯度产生影响,因此,采用基于梯度的匹配准则可以很好地避免光照带来的不利因素,使得到的光流场更准确。
本文在计算稠密光流时,使用的块大小为1,即m(i,j)=1,用G0x,G0y,G1x,G1y分别表示图像G0,G1在x方向和y方向的梯度值矩阵。则式(10)可以简化表示为:

为了使E(u,v)在定义域内连续可导,将式(11)等价地写为下面的形式:

式(12)就是本文使用的匹配误差计算公式。其中u,v表示该像素点的位移,为保证计算的精确度,将其类型定义为浮点数,而G1x,G1y中只有整数坐标有值,因此计算G1x(i+u,j+v)、G1y(i+u,j+v)时需要进行线性插值。例如,在G1x中,假设点(i+u,j+v)周围最近的四个整数坐标分别为(m,n),(m+1,n),(m,n+1),(m+1,n+1),令:
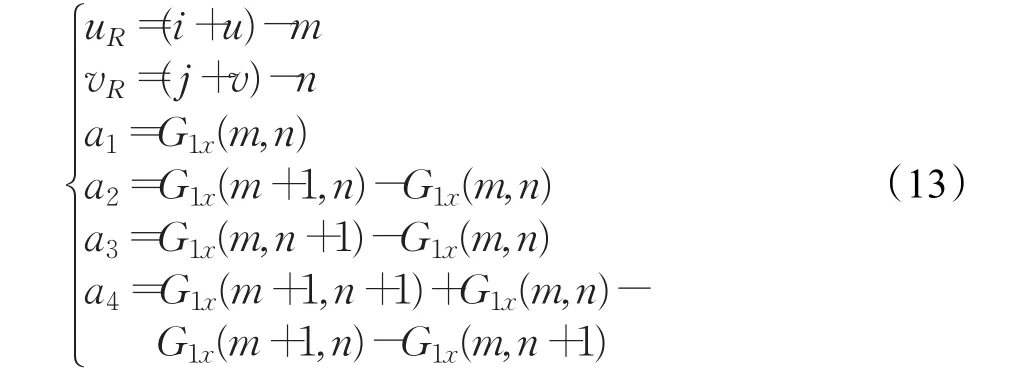
则根据双线性插值原理,得到:

于是由式(12)~(14)便可以求解出每个点的匹配误差。
2.2 多分辨率迭代
将图像按金字塔式分层,是图像处理中的一种常见的策略,经典的Lucas-Kanade光流算法后来就应用了这一策略[14]。采用由粗到精的金字塔算法,不仅可以减少运算量,还可以避免陷入局部点,增强鲁棒性。在光流算法中,采用金字塔策略,可以有效获得大位移光流。
具体方法为设图像的原始尺寸为(W0,H0),将其设为图像金字塔的最底层(即第0层),定义缩放因子λ(小于1的常数,本文设为0.9),则第一层图像尺寸为(λW0,λH0),依次类推,第 L层的图像尺寸(WL,HL)=(λLW0,λLH0),当图像的宽度或高度小于某阈值MinSize时,停止分层。
设图像金字塔共Lm+1层,光流的计算从最顶层(即第Lm层)图像开始。每层的计算方法是利用上一层的光流场作为初始值,然后逐点进行传播和修正。其中,最顶层图像的光流场初始值为(0,1)之间的随机均匀采样值。以第L层图像的光流计算为例:
设第L+1层的光流场为 fL+1,其尺寸为(WL+1,HL+1),由于第L层图像的尺寸(WL+1/λ,HL+1/λ),因此首先需要对 fL+1进行上采样,为使结果尽量平滑,上采样过程中使用双三次插值[15]。设经上采样后的光流场为那么第L层图像光流场的初始值为:

乘上1/λ是因为图像放大后,相应的像素点的运动位移也会变大。接下来对每个像素点进行传播修正,用伪代码描述如下:

其中,匹配误差的计算公式见式(12),梯度下降法修正光流将在2.3节论述。至此,第L层图像的光流场计算完毕。每一层都如此计算,当计算完第0层时,就得到了最终的光流场。
2.3 光流修正
Barnes算法的迭代修正过程中,传播和随机搜索交替进行,随机搜索是在大范围内设置搜索窗口来改善匹配结果,而视频序列中连续的两帧图像的时间间隔一般很小,大部分像素的运动矢量也较小,这种情况下,对每个块在大范围随机搜索来改善匹配结果的效率就不高。同时,由于采取了多分辨率迭代策略,已经可以有效获得大位移光流,因此,在传播后,可以不再用随机搜索,而是使用梯度下降法来修正光流。
对于某个点来说,其匹配误差可以看成是其运动矢量的函数(见式(12)),其真实的光流矢量就是使误差函数最小时的运动矢量。
在式(12)中,G0x和 G0y与 u,v无关,而由式(13)、(14)可知,G1x和G1y是关于u,v的连续可导的函数,于是误差函数E(u,v)也是关于u,v的连续可导的函数,由微积分原理可知:


注意上式仅在逼近点(u,v)的邻域内成立,在实际计算中,用下式近似计算:

式(18)中,du和 dv取0.001,根据前面的分析,每次传播后,修正光流矢量为:

由式(16)可知,修正后误差总是会减小。式(19)就是机器学习中常用的梯度下降法。其中,α为步长,本文采用动态步长的策略,因为在接近图像金字塔顶层时,误差一般较大,可以将步长设置大一些,当接近金字塔底层时,步长应该小一些。将步长α可以设置为金字塔层数的函数,第L层的步长为:

综上所述,整个算法流程用伪代码描述如下:
//开始
读入两帧图像G0,G1;转换为灰度图并做归一化;
初始化第Lm层的光流场 fLm为(0,1)之间的随机均匀采样值;

对光流场 fL进行一次右下方向的传播修正;
对光流场 fL进行一次左上方向的传播修正;
对光流场 fL进行中值滤波;
if L>0:
对 fL进行上采样,作为下一层的初始值;
}
//结束
现对整个算法的复杂度进行简要分析。对于n×n的原始图像,总共处理的像素点个数为:

对于每层图像的每个像素点,其传播过程仅与相邻的4个像素点有关,所用时间为常数;其光流修正过程与周围像素点无关,所用时间也为常数;因此传播和修正算法的时间复杂度仅为O(c⋅1),其中c为常数。因此整个算法的时间复杂度为,即等效于平方复杂度O(n2)。
3 并行加速方法
图形处理器GPU是由成千上万的更小、更高效的核心组成的大规模并行计算架构,专为同时处理多任务而设计。如今,GPU的运算能力已经远远超过了CPU。GPU相比CPU在浮点运算能力,内存带宽,以及价格上都体现了极大的优势。
关于图像的算法由于要处理数量庞大的像素点,通常比较耗时。例如,本文在计算每个像素点的光流时,要计算相邻4个点的匹配误差,用梯度下降法修正光流时,还要计算一次匹配误差,而每次计算匹配误差都要进行双线性插值运算,因此每个像素点总的运算量也不小,随着图像尺寸的增大,总的运行时间会以快速增加。因此,对算法用GPU进行并行加速就非常有意义。
但从上面Barnes的算法描述可知,Barnes算法并不易于在GPU上并行实现,原因在于其传播过程是以逐块扫描式的,即当前块(x,y)的计算依赖于(x-1,y)和(x,y-1)两个块的计算,这样的串行性使得算法难以并行实现。
为此,本文对传播过程稍作修改。每次传播时,将当前块的计算仅依赖于相邻的一个块,而不是之前的两个块,同时将好的结果也只传播给相邻的一个块,这样就可使得每一行或每一列的传播变得独立,因此很容易在GPU上并行实现。
具体来说,对每层图像的光流场,由之前的传播两次变为传播4次,依次是从左到右、从上到下、从右到左、从下到上。每次传播时,每行或每列的计算是并行的。
该方法的可行性分析如下,假设其中的某个块p获得了最好的匹配结果,其传播的过程如图1所示。

图1 传播过程示意图
图1 中深色的块表示当前传播到的块。可以看出,经过4次传播,其好的结果能传遍图像中所有的点。
4 实验分析
实验将本文算法及本文并行加速的算法与OpenCV实现的稠密光流Farneback[16]算法和Dual TV L1[17-18]算法进行对比。
Farneback算法的基本思想是用一个二次多项式来对图像进行近似建模:,其中A是一个2×2对称矩阵,b是2×1的矩阵。对于每帧图像中的每个像素点周围设定一个邻域(2n+1)×(2n+1),利用邻域内的共(2n+1)2个像素点作为最小二乘法的样本点,拟合得到中心像素点的系数。该过程中使用了分离卷积的方式,有效地降低了运算量。对于某个像素点,假设其原灰度值为 f(x),增加全局位移后的值为f(x+d),由灰度一致性假设可知 f(x)=f(x+d),然后根据多项式相应的系数相等,可以求解出该像素点的全局位移d。对每个像素点均计算后,就得到了图像的稠密光流场。
Dual TV L1算法是在TV L1光流模型的基础上提出的。TV L1光流模型是指基于L1范数的整体变分(Total Variation-TV)光流模型,它是用L1范数代替文献[5]中HS光流模型的L2范数,因为基于L1范数的方程具有更优的间断处理能力。但由于TV L1方程的数据项和平滑项没有完全、连续的可微性,因此求解较困难。Zach[17]等为此提出了一种对偶的方法来求解TV L1光流模型,它将原模型数据项中的原光流变量(u,v)用对偶变量(u′,v′)替换,从而构造了TV L1的对偶模型(Duality TV L1)。同时将模型分为两部分凸替求解(u,v)和 (u′,v′)。这样求得的结果相比传统的TV L1光流模型具有更好的全局最优性。
4.1 评估指标
光流场的评估理论和方法一直是学者们研究的一个重要主题。2011年,Baker[19]等对光流场的评估方法做了一个详细的总结。本次实验的评估指标采用常用的平均角误差(Average Angle Error,AAE)和平均点误差(Average Endpoint Error,AEE)。

AAE的计算公式为:其中,N表示图像中像素点的总数,(ui,vi)表示计算得到的图像某像素点的光流矢量表示图像某像素点标准的光流失量。AAE反映了计算得到的光流矢量整体偏移标准光流矢量的角度,是评估光流算法准确性的重要指标。
平均点误差(AEE)的计算公式为:
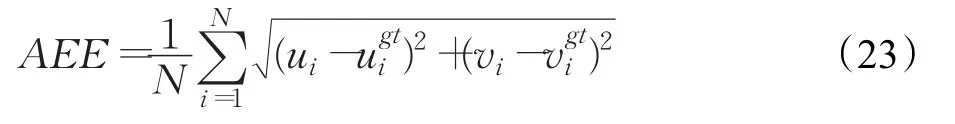
AEE反映的计算得到的光流场矢量端点偏离标准光流场矢量端点的距离,这是个绝对的量,有一定局限性,比如当标准光流场矢量很小时,这个值一般较小,而当标准光流场矢量较大时,这个值一般较大,为方便不同图片的比较,本文还使用Mccane[20]定义的归一化点误差(Normalized Endpoint EEROR,NEE),其计算公式为:

其中c表示真实光流,e表示计算光流,T为显著性阈值,设置T是为了避免小光流带来的不利影响。本文使用归一化化点误差的平均值(ANEE)作为统计指标:

ANEE反映了点误差占标准光流矢量大小的平均百分比。
4.2 实验过程
实验的硬件环境为:CPU为Core i7 3.4 GHz,RAM 32 GB,显卡为NVIDIA GeForce GTX 1080。
实验的软件环境为:Windows 10,Visual Studio 2015,OpenCV3.1.0,cuda 8.0。
实验的测试图片采用Middlebury[21]网站提供的包含真实光流场的训练组序列。训练组序列包含自然场景序列和合成场景序列,自然场景序列包括Dimetrodon、Hydrangea、RubberWhale,其中包含了大位移运动,非刚性运动以及真实而多样性的光照效果;合成场景序列包括Grove类序列以及Urban类序列,其中Grove类序列是由多个程序合成的石头和树组成,地面纹理和表面位移是随机生成的,含有明显的遮挡,摄像机还有自旋和3D运动。Urban类序列是模拟的城市环境,含有许多的运动间断点,较大的位移,还有独立的运动物体。目前所有的合成序列明显超越了先前的Yosemite序列。
实验时记录各个算法在每组序列中的各项误差指标,同时记录各算法的运行时间,对于各算法的运行时间均采用多次实验(10次)取平均的方法。另外,由于本文算法和本文并行加速的算法是随机初始化的,故每次实验各项误差数据也会有些微不同,因此也采用了多次实验(10次)取平均的方法记录误差数据。对于各算法得到的光流场,采用文献[18]中使用的彩色图表示法以方便直观的对比,彩色图中不同的颜色代表不同方向的光流矢量,颜色的深浅表示该点光流矢量的大小;各算法计算的光流场与标准的光流场的误差用灰度图表示,图中黑色的点表示没有误差,灰度值越大表示该点的误差越大。
4.3 实验结果及分析
以自然场景序列Dimetrodon为例,实验结果如图2。
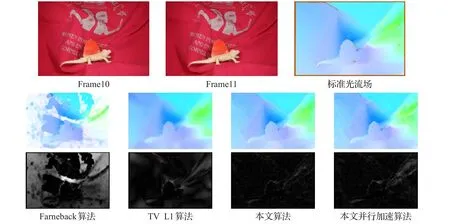
图2 Dimetrodon序列测试结果

表1 不同算法的各项指标对比
图2中第二行彩色图为各算法所计算的光流场经可视化后的图像,第三行灰度图为各算法计算得到的光流场的误差。详细的测试数据如表1所示。
结合表1和表2可以看出,Farneback算法各项误差最大,Dual TV L1算法的对于自然场景序列效果较好,而对于有大位移的合成序列,算法误差较大,比如对于序列Urban2,其平均点误差超过了3个像素长度。而本文基于Barnes算法实现的块匹配光流法对于所有序列均表现良好,从表2的平均性能来看,其平均角度误差不超过5°,平均点误差不超过半个像素长度,归一化点误差约为10%。而经并行加速的算法的准确度与原算法基本一致,均明显好于OpenCV实现的两种稠密光流算法。另外,本文原算法采用的是基于梯度的匹配准则,对于光照变化的场景有良好的鲁棒性,但对于有旋转、缩放的场景,梯度守恒的假设便不再适用,因此本文算法对Grove3序列的准确性次于其他序列。

表2 不同算法在所有测试图片中的平均误差
从时间性能来看,Farneback算法最快,本文原算法次之,Dual TV L1算法最慢,而本文的并行加速算法相比原算法有大约2.5倍的加速比,速度与最快的Farneback算法十分接近。
综合准确度和速度来看,本文的并行加速光流算法性能最佳。
5 结束语
本文在Barnes算法基础上实现的稠密光流算法,使用了梯度作为匹配准则,采用了金字塔分层策略,使用了梯度下降法修正光流,每个像素点的时间复杂度仅为O(1),并且其准确性明显优于OpenCV实现的两种稠密光流算法。本文对原算法的传播过程进行改进,从原来的两次传播变为4次传播,使算法易于在GPU上实现并行加速,由此得到的并行加速算法相比本文的原始算法,而速度快了约2.5倍,几乎与OpenCV中最快的Farneback算法相当,而其各项误差指标明显优于Farneback算法。
猜你喜欢
导航定位学报(2022年5期)2022-10-13
北京航空航天大学学报(2021年9期)2021-11-02
中学生数理化·高一版(2021年11期)2021-09-05
现代电子技术(2021年1期)2021-01-17
上海大学学报(自然科学版)(2018年5期)2018-11-02
电脑知识与技术(2018年35期)2018-02-27
自动化学报(2017年11期)2017-04-04
现代防御技术(2016年1期)2016-06-01
新高考·高一物理(2016年1期)2016-03-05
中北大学学报(自然科学版)(2014年3期)2014-11-22
