
基于支持向量的最近邻文本分类方法
2018-09-18 09:48古丽娜孜艾力木江乎西旦居马洪孙铁利梁义
智能系统学报 2018年5期
古丽娜孜·艾力木江,乎西旦·居马洪,孙铁利,梁义
文本分类(text classification,TC)是对一个文档自动分配一组预定义的类别或应用主题的过程[1]。随着数字图书馆的快速增长,TC已成为文本数据组织与处理的关键技术。数字化数据有不同的形式,它可以是文字、图像、空间形式等,其中最常见和应用最多的是文本数据,阅读的新闻、社交媒体上的帖子和信息主要以文本形式出现。文本自动分类在网站分类[2-3]、自动索引[4-5]、电子邮件过滤[6]、垃圾邮件过滤[7-9]、本体匹配[10]、超文本分类[11-12]和情感分析[13-14]等许多信息检索应用中起到了重要的作用。数字化时代,在线文本文档及其类别的数量越来越巨大,而TC是从数据海洋当中挖掘出具有参考价值数据的应用程序[15-16]。文本挖掘工作是政府工作、科学研究、办公业务等许多应用领域里书面文本的分析过程。朴素贝叶斯、k近邻、支持向量机、决策树、最大熵和神经网络等基于统计与监督的模式分类算法在文本分类研究中已被广泛应用。提高文本分类效率的算法研究对web数据的开发应用具有重要意义。
合理的词干有助于提高文本分类的性能和效率[17-18],特别是对于哈萨克语这样的构词和词性变化较复杂语言的文本分类而言,词干的准确提取极其重要。从同一个词干可以派生出许多单词,因此通过词干提取还可以对语料库规模进行降维。文本文档数量的巨大化和包含特征的多样化,给文本挖掘工作带来一定的困难。目前,众多文本分类研究都是基于英文或中文,基于少数民族语言的文本分类研究相对较少[19];但是国外对于阿拉伯语的文本分类工作比中国少数民族语言文本分类工作成熟[20–21],投入研究的人员也较多。
哈萨克语言属于阿尔泰语系突厥语族的克普恰克语支,中国境内通用的哈萨克文借用了阿拉伯语和部分波斯文字母,而哈萨克斯坦等国家用的哈萨克文是斯拉夫文字。哈萨克文本跟中文不同的一点是哈萨克文文本单词以空格分开的,这点类似于英文,都需要文本词干提取过程。由于哈萨克语与英语语法体系不一样,英文词干提取规则还不能直接用到哈萨克语文本分类问题上,要研究适合哈萨克语语法体系的词干提取规则之后才能实现哈萨克语文本的分类工作。哈萨克语具有丰富的形态和复杂的拼字法,因此哈萨克语文本分类系统的实现是有难度的。为了实现文本分类任务需要一定规模的语料库,语料库里语料的质量直接影响文本分类的精度。到目前为止在哈萨克语中还没有一个公认的哈萨克文语料库,当然,也有不少人认为新疆人民日报(哈文版)上的文本可以当作文本分类语料库。本文为了保证文本分类语料库的规范化和文本分类工作的标准化,经过认真挑选中文标准语料库里的部分语料文档并对其进行翻译和新疆人民日报上的部分文档来自行搭建了本研究的语料库。本文在对前期研究里词干提取程序词干解析规则[22-24]进行优化改善的基础上实现本研究的文本预处理,提出新的样本测度指标与距离公式,并结合SVM与KNN分类算法实现了哈萨克语文本分类。
1 文本特征提取
1.1 文本预处理
文本预处理在整个文本分类工作中扮演着最重要的角色,其处理程度直接影响到文本分类精度。因为它是从文档中抽取关键词集合的过程,而关键词的单独抽取因语言语法规则的不同而不同,所以这层工作属于技术含量较高的基础性工作,需要设计人员熟练掌握语言语法规则和计算机编程能力。目前存在一个现实问题,即包括作者在内的很多编程人员因研究工作的需要一般从事于中英文文字资料上的研究,所以对母语(哈萨克语)语法规则的细节不精通,对从小开始在汉语授课学校上学的编程人员情况则更严重,所以要实现词干解析需要向语言学专家或相关人员全面请教,这也是影响哈萨克语文本分类工作进展的一个客观问题。
哈萨克语文字由24个辅音字母和9个元音字母的共有33个字母组成。因为哈萨克语语法形式是在单词原形前后附加一定附加成分来完成的,所以哈萨克语言属于黏着语,即跟英文类似一个哈萨克语单词对应多种链接形式,因此对其一定要进行词干提取。
本文前期系列研究工作基本完成了哈萨克语文本词干提取以及词性标注工作,已完成哈萨克语文本词干表的构建。该词干表收录了如图1所示的由新疆人民出版社出版的《哈萨克语详解词典》中的60 000多个哈萨克语文本词干和如图2所示的438个哈萨克语文本词干附加成分。

图1 哈萨克语词干Fig. 1 Kazakh text stem

图2 哈萨克语附加成分Fig. 2 Additional components in Kazakh text
本文在前期准备研究工作的基础上,给出3种词性的有限状态自动机,并采用词法分析和双向全切分相结合的改进方法实现哈萨克语文本词干的提取与单词构形附加成分的细切分。以改进的逐字母二分词典查询机制对词干表进行搜索,提高词干提取的效率。以概率统计的方法对歧义词和未记载词进行切分。在此研究基础上,设计实现了哈萨克语文本的词法自动分析程序,完成哈萨克语文本的读取预处理。处理结果如图3所示,上半窗体上显示的是待切分的文档原文,下半窗体上显示是词干切分后的结果。

图3 哈萨克语文本词干切分结果示例Fig. 3 Example segmentation results of the Kazakh text stem
1.2 特征处理
特征是文本分类时判别类别的尺度。模式识别的不同分类问题有不同的特征选择方法,而在文本分类问题中常用到的方法有互信息(MI)、X2统计量(CHI)、信息增益(IG)、文档频率(DF)、卡方统计等[25]。这些方法各具优点和不足之处。MI、IG和CHI倾向于低频词的处理,而DF则倾向于高频词的处理。目前,也有许多优化改进方法[26-28],其中文本频率比值法(document frequency ratio,DFR)以简单、快捷等优点克服了以上几种方法存在的问题,综合考虑了类内外文本频率,其计算公式为
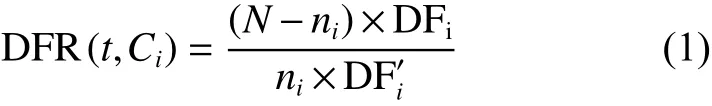
式中,对于词t,N是训练文本数,ni是Ci类别中的文本数,DFi是Ci类别中包含词t的文本数,而显然是除了Ci类以外的别的类别中包含词t的文本数。
通过词频统计、词权重计算和文档向量化表示等一系列的预处理工作之后才能运用分类算法,所以对文本分类工作而言这些都是非常重要的阶段性基础工作。图4所示的是每类文档里(如体育类文档中)每一个单词(如“排球”)的总出现次数。图5所示的是词的权重计算结果,即统计某词在判别文档类别所属关系中的隶属度,当然隶属度越高说明该词在文档分类时的贡献越大。最后把文档由如图6所示的形式向量化表示,生成分类问题的文档向量,即“X号特征词:该特征词的特征向量”形式向量化表示。

图4 词频统计结果Fig. 4 Term frequency statistical result

图5 词权重计算结果Fig. 5 Term weight computed result

图6 文本向量文件Fig. 6 Text vector files
2 SVM与KNN方法
2.1 SVM方法
支持向量机(support vector machine,SVM)是在1995年由Cortes和Vapnik首次提出来的一种模式识别分类技术[29]。SVM是在统计学习理论(statistical learning theory,SLT)原理的基础上发展起来的机器学习算法。SVM方法的重点在于在高维特征空间中能构造函数集VC维尽可能小的最优分类面,使得不同类别样本在这分类面上分类上界最小化,从而保证分类算法的最优推广能力。图7所示的是SVM方法的分类原理示意图。SVM在有限训练样本情况下,在学习机复杂度和学习机泛化能力之间找到一个平衡点,从而保证学习机的推广能力[30]。
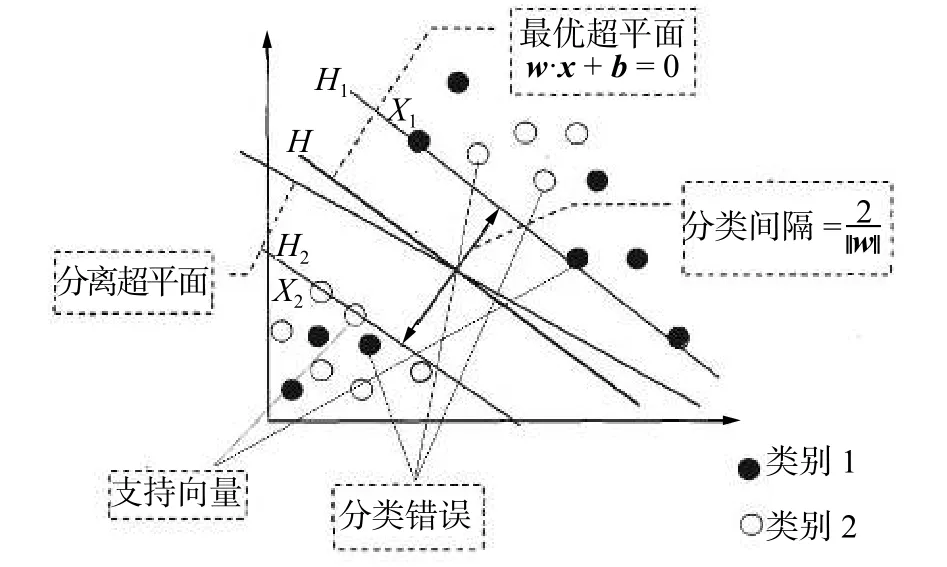
图7 SVM 分类原理示意图Fig. 7 SVM classification schematic diagram
根据样本分布情况与样本集维数,SVM算法的判别函数原理大致可分为线性可分与非线性可分两种形式。
1)线性可分
带有以式(2)所示训练样本集的SVM线性可分分类问题的数学模型可通过式(3)来表示:
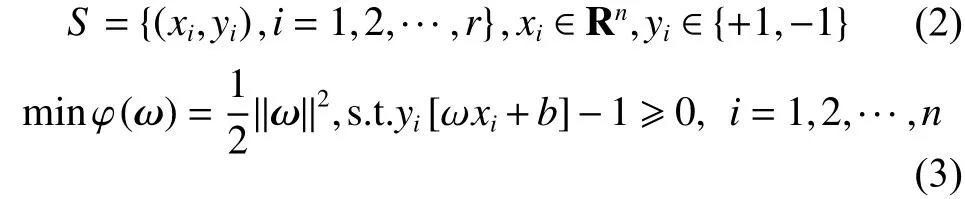

式中对应ai≠0时的样本点就是支持向量。因为最优化问题解ai的每一个分量都与一个训练点相对应,显然所求得的划分超平面仅仅与对应ai≠0 时的那些训练点 (xi·x)相关,而跟 ai=0 时的那些训练点没有任何关系。相应于ai≠0时的训练点(xi·x)里的输入点xi就是支持向量,通常它们是全体样本中的很少一部分。得出结论,最终分类分界面的法向量ω只受支持向量的影响,不受非支持向量训练点的影响。
2)非线性可分
为此,需要在式(3)中增加一个松弛变量ξi和惩罚因子C,从而式(3)变为
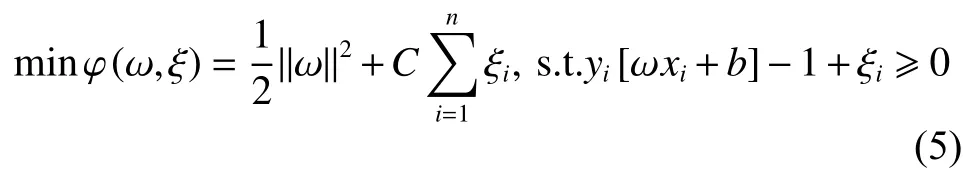
式中:ξi≥ 0;i = 1, 2, ···, n;C 为控制样本对错分的调整因子,通常称为惩罚因子。C越大,惩罚越重。
虽然原理看起来简单,然而在分类问题的训练样本不充足或不能保证训练样本质量的情形下确定非线性映射是很困难的,那么如何确定非线性映射呢?SVM通过运用核函数概念解决这个问题,核函数是SVM的其他分类算法无法替代的独特功能。
SVM通过引入一个核函数K(xi·x),将原低维的分类问题空间映射到高维的新问题空间中,使核函数代替内积运算,这个高维空间就称为Hilbert空间。引入核函数以后的最优分类函数为

2.2 KNN方法
KNN(K nearest neighbor)分类法是基于实例的学习算法,它需要所有的训练样本都参与分类[31]。在分类阶段,利用欧氏距离公式,将每个测试样本与和它邻近的k个训练样本进行比较,然后将测试样本归属到票数最多的那一类里[32]。KNN算法是根据测试样本最近的k个样本点的类别信息来对该测试样本类型进行判别,所以k值的选取非常重要。k值若太小,测试样本特征不能充分体现;k值若太大,与测试样本并不相似的个别样本也可能被包含进来,这样反而对分类不利。KNN算法在分类决策上只凭k个最邻近样本类别确定待分样本的所属类。目前,对于k值的选取还没有一个全局最优的筛选方法,这也是KNN方法的弊端,具体操作时,根据先验知识先给出一个初始值,然后需要根据仿真分类实验结果重新调整,调整k值的操作有时一直到分类结果满足用户需求为止。该方法原理可由式(7)表示:

式(7)表明将测试样本di划入到k个邻近类别中成员最多的那个类别里。
在使用KNN算法时,还可由其他策略生成测试样本的归属类,如式(8)也是被广泛使用的公式:

当x(j∈ci时,;当xjci时,;是测试样本di和它最近邻xj之间的余弦相似度。余弦相似度测量是由一个向量空间中两个向量之间角余弦值来定义的。式(8)说明测试样本di被归到k个最近邻类里相似性最大那个类别里。
一般情况下,不同类别训练样本的分布是不均匀的,同样不同类别的样本数量也可能不一样。所以,在分类任务中,KNN中k参数的一个固定值可能会导致不同类别之间的偏差。例如,对于式(7),一个较大的k值使得方法运行结果过拟合,反过来一个较小的k值使得方法模型性能不稳定。实际上,k的值通常由交叉验证技术来获取。然而,像在线分类等情况,就不能用交叉验证技术,只能给出经验值,因此k值的选定很重要。
KNN虽是简单有效的分类方法,但不能忽略以下两方面的问题:1)由于KNN需要保留分类过程中的所有相似性计算实例,从而随着训练集规模的增多,其计算量也会增加,在处理较大规模数据集分类时方法的时间复杂度会达到不可接受的程度[33],这是KNN方法的主要缺点;2) KNN方法分类的准确性可能受到训练数据集中特性的无关性和噪声数据的影响,若考虑这些因素其分类效果也许更好。
3 基于SV-NN的哈萨克语文本分类算法
本文提出一种组合分类方法,把SVM算法当作KNN算法的训练阶段,这样可以避免k参数的选择。组合分类方法结合了SVM算法的训练和KNN算法的学习阶段。首先运用SVM算法对所有训练样本进行一次训练获得每一类别的少量的支持向量(support vectors,SVs),在测试阶段使用最近邻分类器进行测试并分类测试样本,即计算出新测试样本与每个类别SVs平均距离值后对其进行对比分析,该测试样本与哪一类别SVs平均距离值点离得最近就把它归为该类别中。分类决策依据是各类别SVs平均距离值后对其与测试点之间距离的数值分析,所以简称该算法为支持向量与最近邻方法(the support vector of nearest neighbor,SV-NN)。
3.1 SV-NN算法描述及流程图
假设共有n个类别,每个类别含有m个支持向量。
SVM: T1→svij;//通过使用 SVM 定义每个类别的支持向量。
while(k<l)
{ 输入 xk;
利用式(9)计算xk与svij之间的距离(Dk);
利用式(10)计算xk与svij之间的平均距离(averDk);
SV-NN 分类算法:
Start:
{ integer i, j,k,l;
利用式(11)计算xk与svij之间最小平均距离
将xk划入到基于的最近类别;
k=k+1;
}
}
End
SV-NN分类方法的工作流程如图8所示。
3.2 SV-NN 算法实现
1)将所有训练点映射到向量空间,并通过传统SVM确定每一个类别的支持向量。

式中:支持向量svij是从输入文档中提取的(共有n个类,每个类别含有m个支持向量)。确定每一类的支持向量之后,其余的训练点可以消除。
2)使用欧氏距离公式(9)计算测试样本xk与由1)生成的每一类支持向量svij之间的距离。


图8 SV-NN分类方法工作原理Fig. 8 SV-NN classification approach working principle diagram
3)使用式(10)计算测试样本xk与每一类支持向量svij之间的平均距离:
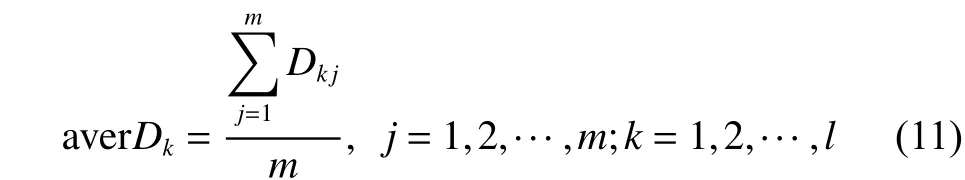
4)计算最短平均距离minD,并将测试样本xk划入到最短平均距离对应的那一类中。

即输入点被确认为与svij之间最短平均距离值对应的正确类。
重复步骤2)~4),直到所有的测试样本分类完为止。
4 实验结果与评价
通常,语料库里语料的质量与数量直接影响文本分类算法的分类性能。中、英文等其他语言文本分类研究都有标准的语料库,而哈萨克语文本分类工作却还没有一个公认的标准语料库。本文考虑到文本分类工作的规范性和语料的标准性,由中文标准语料部分文档的翻译和挑选新疆日报(哈文版)上的部分文档来搭建了本研究的语料库。在前期研究里,同样是通过翻译收集语料集的,只是其规模小了点,本文的语料工作算是对前期研究语料集的补充和优化完善。前期研究语料集语料文档只有5类文档,本文扩充到8类文档。通过跟语言学专家们的多次沟通,选择具有代表性的文档,同时对词干提取程序解析规则也作了适当的调整。虽然本文所构建的语料库还不能称得上“标准”词语,但对现阶段哈萨克语文本分类任务的完成具有实际应用价值。
本文把语料集规模扩大到由计算机、经济、教育、法律、医学、政治、交通、体育等8类共1 400个哈萨克语文档组成的小型语料集,如表1所示。数据集被分为两个部分。880个文档(63%)用于训练,520个文档用于测试(37%)。

表1 数据集Table 1 Data set
本文文本分类实验评价指标采用了召回率、精度和F1这3种评价方法。精度评价是指比较实际文本数据与分类结果,以确定文本分类过程的准确程度,是文本分类结果是否可信的一种度量。高精度意味着一个算法返回更相关的结果,高召回率代表着一个算法返回最相关的结果,所以文本分类工作期望获得较高的精度和召回率。
本文在前期研究中搭建的哈萨克文语料集的补充完善以及对其词干提取程序提取规则细节的优化改善基础上实现了本研究哈萨克语文本的预处理。分类任务的实现运用了SVM、KNN与本文提出的SV-NN算法,并对3种算法分类精度进行了较全面的对比分析。通过对表2和图9上的仿真实验数字的对比分析,发现SVM算法优于KNN算法,而SV-NN算法优于SVM 算法。SV-NN方法F1指标除了教育类和法律类以外在其他类上的F1指标都高于都SVM、KNN对应指标。SVM、KNN和SV-NN平均分类精度分别为0.754、0.731和0.778,这说明本文提出算法对所有类别文档词的召回率和区分度较稳定。本研究提出的算法模型继承了SVM算法在有限样本情况下也能获得较好分类精度的优点,另外,本算法没有去定义KNN算法的k参数,也没有跟所有类所有训练样本进行距离运算。所以,本研究提出的算法无论从算法复杂度的分析还是算法收敛速度的分析都是有效的。当然,总体精度还是没有像中、英文等其他语言文本分类精度那么理想,因为涉及很多方面的因素,如研究语料库语料文档数量、每一类文档本身的质量、词干表里已录用的词干数量和质量、词干提取程序解析规则的细节等,但目前所获得的分类精度比前期系列研究成果理想,本算法的文本分类性能有了很大的提升也较好地提高了召回率。
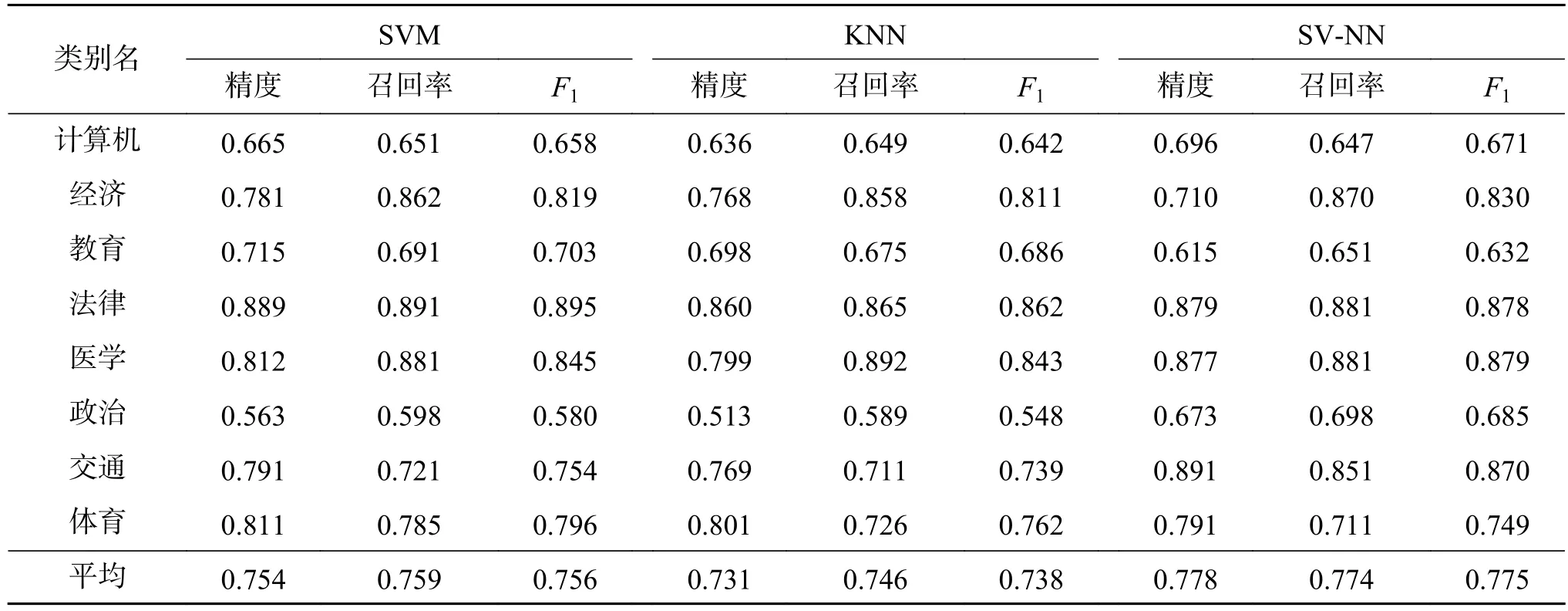
表2 SVM、KNN、SV-NN的分类精度对比Table 2 SVM KNN and SV–NN comparison of classification accuracy

图9 分类精度的对比分析(每一类别均含175篇文档)Fig. 9 Comparative analysis of classification accuracy (each category contains 175 documents)
5 结束语
本文在前期系列研究中所搭建的哈萨克文语料集和词干提取程序的优化完善基础上实现了哈萨克语文本的预处理。分类任务的实现上运用了模式识别的3种分类算法,并对3种分类算法分类精度进行了较全面的对比分析。通过仿真实验客观数字的对比分析,说明本文提出算法的优越性。本文算法对所有类别文档词的召回率和区分度较稳定。本文算法在继承SVM算法的分类优越性基础上,还有效避免了KNN算法设置k参数的麻烦和跟所有训练样本进行距离计算而带来的巨大时间复杂度,进而保证了分类算法的收敛速度。
本研究仍有许多待优化完善的问题,本文接下来的研究工作中将系统地研究并解决影响文本分类精度的阶段性问题,获得满意的分类精度。
猜你喜欢
文化创新比较研究(2022年15期)2022-07-12
文化创新比较研究(2020年13期)2021-01-14
少儿画王(3-6岁)(2020年4期)2020-09-13
天津外国语大学学报(2020年1期)2020-03-25
课程教育研究·新教师教学(2016年1期)2017-04-10
中国民族博览(2017年7期)2017-01-24
西夏学(2016年2期)2016-10-26
山东青年(2015年4期)2015-12-09
浙江大学学报(工学版)(2015年1期)2015-03-01
外语教学理论与实践(2014年4期)2014-06-13
