
去冗余Top-k对比序列模式挖掘
2018-09-18 09:48:06江冰谷飞洋何增有
智能系统学报 2018年5期
江冰,谷飞洋,何增有
至今已经有很多种序列模式被提出,包括周期模式[1]、偏序模式[2]、闭合模式[3]、对比序列模式[4]、频繁序列模式[5]等。对比序列模式挖掘作为数据挖掘中重要的一个问题,目前已经积累了大量的研究成果[6-7]。对比序列模式是指在一类数据集中频繁出现,而在另一类数据集中很少出现的序列模式。对比序列模式可以描述不同数据集之间的差异,在很多领域有广泛应用。例如,对比序列模式可以用于纳税人行为分析[8],患者的风险预测[9]等。在对比序列模式挖掘中,Top-k对比序列模式挖掘是一种重要的挖掘策略。 Topk方法是指在给定的标准下挖掘出差异最大的k个模式的方法。该方法被广泛应用在关联规则[10]、序列规则[11]、相关模式[12]和序列模式[7]等领域中。但是,在Top-k策略挖掘结果中依然存在冗余的问题。针对这一问题,本文提出了挖掘去冗余Top-k对比序列模式集合的方法。
1 相关工作
对比序列模式挖掘主要包括基于阈值的对比序列模式挖掘和Top-k对比序列模式挖掘两个研究方向。基于阈值的对比序列模式挖掘的目标是找出所有满足给定阈值的模式。最直接挖掘对比序列模式的方法是枚举所有的序列模式,然后统计它们在每个类别上的频率。很明显这种方法的效率太低,不能满足实际应用的需求。Chan等[13]于2003年提出一种基于后缀树的挖掘对比序列模式的算法(emerging substrings mining,ESM)。与朴素的挖掘算法相比,ESM提高了一定的效率。Ji等[14]于2007年定义了MDS (minimal distinguishing subsequence) 的概念,并提出了相应的挖掘算法,即ConSGapMiner (contrast sequences with gap miner)算法。ConSGapMiner是比较经典的对比序列模式挖掘算法,它能以较快的效率挖掘出对比序列模式。但是MDS定义的对比序列模式在正例集中大于一个固定的阈值,在反例集中小于一个固定阈值,这种定义可能使一些有意义的模式没有被挖掘出来。2010年Deng等[15]在Con-SGapMiner的基础上利用F-ratio作为对比度;2011年Yu等[16]提出了TSEPsMiner算法;TSEPsMiner利用GrowthRate作为对比度,而且将这个对比度应用在了挖掘对比序列模式的算法中;2014年Wang等[17]提出用gd-DSPMiner算法来解决MDS定义中存在的问题。在不明确数据的差异程度时,使用基于阈值的对比序列模式挖掘难以挖掘出预期的序列模式。在这种情况下,Top-k对比序列模式挖掘是一个可行的办法。Top-k算法不用设定对比度的阈值,只需要设置想要挖掘模式的数目。杨皓等[7]于2015年提出了新的Top-k挖掘算法,即kDSP-Miner(Top-k distinguishing sequential patterns with gap constraint miner)算法。但是kDSP-Miner并没有考虑冗余问题,kDSPMiner挖掘出的序列模式可能会有大量的冗余。
2 问题定义
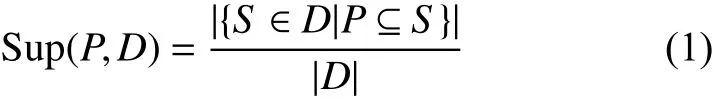


表1 含有两个类别的基因数据集Table 1 A gene data set with two classes
Top-k对比序列模式挖掘的目标是找出给定数据集中对比度最大的k个序列模式。
定义3 (冗余对比序列模式) 对于两个给定的对比序列模式和,如果满足:

表2 表1中基因数据集的Top-5对比序列模式Table 2 Top-five discriminative sequential patterns from gene data set in table 1
定义4 (去冗余Top-k对比序列模式)集合L满足Top-k对比序列模式集合的要求,同时对于每个序列,不存在;对于任意序列,,不是相对于的冗余对比序列模式。

表3 表1中基因数据集的Top-5去冗余对比序列模式Table 3 Top-five non-redundant distinguishing sequential patterns from gene data set in table 1

表4 符号及其含义Table 4 Symbols and their meaning
3 算法设计
为了挖掘去冗余Top-k对比序列模式的集合,用本文提出的BFM和PBFM算法,来解决挖掘出的结果集合的冗余问题。BFM和PBFM算法基于广度优先生成树的原理来寻找Top-k序列的集合,树的生成过程就是Top-k集合的更新过程。相比于使用深度优先的方法来生成树结构,使用广度优先的方法每次更新时不改变Top-k集合的大小,所以不会出现冗余的Top-k集合。
3.1 广度优先的生成树算法
3) 创建一个队列,将字母表中的每个元素放入队列中。
4) 对于队列的第一个元素,在其末尾分别与字母表中的每个元素连接,形成新的序列。
6) 将队列的第一个元素弹出。
7) 重复 4)~6),直到队列为空。
例5 对表1的数据集进行去冗余Top-k对比序列模式挖掘, 令k =5。找出基因数据集的字母表为。将字母表的每个元素放入队列中,生成的树结构和队列如图1所示。
在Top-k对比序列模式挖掘中,去除冗余序列模式是提高挖掘结果质量的重要一步。但是在原有挖掘过程的基础上,加入去冗余的步骤后,一个新的序列可能会替换Top-k集合中的多个序列,使Top-k集合中的序列模式数目小于k个。针对以上问题,本文提出基于广度优先的生成树算法BFM (breadth-first miner)来去除冗余的序列模式。使用BFM算法可以在去除冗余序列模式的同时,保证Top-k集合的大小不发生变化。

图1 生成树和队列的动态变化Fig. 1 The dynamic change of spanning tree and queue
算法1 BFM (breadth-first miner)
/*初始化*/
2)创建队列,初始化队列queue为空;
4)创建树的根节点,建立由根节点分别指向字母表中每个元素的连接,令min TopkCR = get-MinTopkCR (L);
如果 P′被找到且 P不是相对于P′的冗余序列模式,则把P加入集合L, 更新;
如果 P′被找到并且P是相对于P′的冗余序列,则用P替换集合L中对比度最小的序列更新,否则,用P替换集合L中对比度最小的序列更新;
7)重复步骤 5)、6),直到对列为空。
3.2 剪枝策略
为了提高算法的性能,本文中应用了一系列剪枝策略来辅助算法的运行[7]。运用这些剪枝策略,可以使程序运行的效率提高,更快地找出Top-k集合。
加入以上3条剪枝策略后,树结构生成的速度会加快,可以在更短的时间内找到Top-k对比序列模式。对于某一类数据集,使用剪枝后,算法的效率会显著提升。加入剪枝后的算法如算法2。
算法2 PBFM(pruning breadth-first miner)
输出 包含Top-k对比序列模式的集合L。
/*初始化*/
2)创建队列,初始化队列queue为空;
4)创建树的根节点,建立由根节点分别指向字母表中每个元素的指针,令min TopkCR = get-MinTopkCR (L);
7)重复步骤 5)、6),直到队列为空。
4 实验结果
4.1 实验环境
本文设计了一系列实验来评估算法的有效性。算法用C++语言来实现。实验中所用到的数据集为4组真实数据。这4组数据分别是:E.Coli数据集,记录了两个不同类型的DNA序列。在E.Coli数据集中,每个DNA序列前面都用“+”和“–”标记出了序列所属的类别。UJI数据集,记录了超过11 000个独立的手写数字。ADLs数据集,记录了一段时间内不同的人在自己家中的活动情况。Question数据集,记录了各种不同的问题,可以将每个问题看作由不同单词组成的序列。前3个数据集来自UCI的机器学习数据集。最后一个数据集是Question的训练数据集。实验运行的环境是:Core i3的处理器,Windows 7操作系统,2GB RAM 的计算机上完成。表5中列出了实验中用到的数据集的特征。

表5 数据集的特征Table 5 The characteristics of the data sets
4.2 实验结果分析
1) 实验1(去冗余前后Top-k集合对比实验)
实验1的目标是比较去冗余前后Top-k集合中序列模式的变化,来验证去冗余算法的有效性。在该实验中,使用了3组数据来对比去冗余前后Top-k结果集合的不同。每组数据分别找出了含有冗余序列的Top-k集合和不含冗余序列的Top-k集合,并比较其中序列的组成。在实验中,k值设置为5。实验结果如表6~8所示。

表6 去冗余前后Top-k序列模式集合的变化(ADLs数据集)Table 6 The set of Top-k sequential patterns before and after eliminating redundancy(ADLs data set)
通过实验结果可以发现,去冗余Top-k集合中出现了冗余Top-k集合中没有出现的序列模式。同时,去冗余Top-k集合中删去了冗余的序列模式。因此,本文的算法能够有成效地去除冗余对比序列模式。
2) 实验2(加入剪枝策略前后的对比实验)
实验2的目标是比较算法1与加入剪枝策略后算法效率的变化。分别在ADLs数据集和Question数据集上进行对比实验,比较算法1和算法2运行的时间,来衡量算法的效率。

表7 去冗余前后Top-k序列模式集合的变化(E.Coli数据集)Table 7 The set of Top-k sequential patterns before and after eliminating redundancy(E.Coli data set)

表8 去冗余前后Top-k序列模式集合的变化(UJI数据集)Table 8 The set of Top-k sequential patterns before and after eliminating redundancy(UJI data set)
将k的值分别从1取到20,比较算法1(BFM)和算法2(PBFM)运行的时间如图2所示。从图2中可以看出,随着k值的增加,两种算法的运行时间都在增长,但PBFM的运行时间明显少于BFM的运行时间。在ADLs数据集中,随着k值逐渐变大,这一区别越来越明显。在Question 数据集中,当k值较小时,这一区别较为明显。随着k值的增大,Top-k集合的最小对比度minTopkCR逐渐变小,当时,PBFM算法中删除的元素个数较少,但PBFM算法运行的时间仍然少于BFM算法运行的时间。


图2 BFM和PBFM的效率对比Fig. 2 Comparison of BFM and PBFM efficiencies
5 结束语
本文首先提出了一种挖掘去冗余Top-k对比序列模式的算法BFM,这是一种基于广度优先生成树的算法。通过不断的比较子序列和超序列的对比度,Top-k集合不断地更新,直到树结构的生成过程结束。相比之前的Top-k对比序列模式挖掘算法,BFM算法可以得到去冗余的Top-k集合,并且不需要其他集合的辅助。
在BFM算法的基础上,提出了性能更好的PBFM算法。与BFM算法相比,PBFM算法可以在更短的时间内完成挖掘任务,并且不需要额外的操作。
猜你喜欢
保健医苑(2022年5期)2022-06-10 07:47:22
成都信息工程大学学报(2021年6期)2021-02-12 03:00:54
疯狂英语·新读写(2018年2期)2018-11-29 17:59:24
天津诗人(2017年2期)2017-03-16 03:09:39
浙江大学学报(理学版)(2017年1期)2017-02-07 09:53:45
发明与创新·小学生(2016年4期)2016-08-04 09:04:23
电脑知识与技术(2015年14期)2015-07-24 11:30:20
浙江大学学报(工学版)(2015年6期)2015-03-01 01:18:24
计算机工程(2014年6期)2014-02-28 01:26:33
河南科技(2014年11期)2014-02-27 14:17:57
