
结合稀疏表示与约束传递的半监督谱聚类算法
2018-09-18 09:49:16赵晓晓周治平
智能系统学报 2018年5期
赵晓晓,周治平
谱聚类作为聚类分析一种有效的方法,建立在谱图划分的基础上,可将数据集从原始空间转换到低维特征空间,使原始数据变成线性可分[1],目前已广泛应用于图像分割、人脸识别等领域[2-3]。另一方面,半监督学习是机器学习领域的研究热点,已被用于解决实际问题[4-6],在聚类分析中引入一些监督信息来指导聚类过程,能够提高聚类准确率。
半监督聚类算法的约束信息包括“必连”和“勿连”约束集合,引入这些约束信息可指导聚类过程。目前,针对半监督谱聚类算法已有大量的研究,Kamvar等[7]根据约束关系调整数据之间的相似度,将调整后的相似度矩阵用于改进谱聚类,但是不能充分利用初始有限的约束关系;蒋伟进等[8]提出一种纠错式主动学习成对约束算法,将挖掘到的监督信息用于调整数据点之间的距离矩阵,但约束集合对聚类结果影响较大;丁世飞等[9]通过优化高斯核参数和引入成对约束信息来调整相似度矩阵,但过多的约束信息会对聚类准确率造成负面的影响;Cucuringu等[10]将“必连”和“勿连”约束矩阵均视为图拉普拉斯矩阵,把约束聚类转化为广义特征值问题,针对2类划分效率和准确率显著提高。王翔等[11]提出一种柔性约束谱聚类框架,引入大量硬约束和软约束信息建立新的约束优化问题,有效提高聚类准确率,但是不具备约束关系传递。基于约束信息的半监督聚类算法,通常能获取数据的约束关系是非常有限的,通过约束传递来获得大量可靠的成对约束信息,可显著提高半监督聚类的性能。余志文等[12]提出一种增强型半监督聚类集成框架(incremental semi-supervised clustering ensemble,ISSCE),采用卢志武等[13]提出的约束传递方法,即基于k近邻图的标签传播方法,将少量标签样本的监督信息传递给未标签样本,但如果相似度错误反映数据点之间的相似性,会造成约束关系的错误传递。传统的谱聚类及上述大部分半监督谱聚类算法均需要存储数据的相似度矩阵且对拉普拉斯矩阵进行特征分解,空间和时间的计算复杂度比较高,在处理大规模数据集时计算代价难以承受。为了提升谱聚类的扩展性,蔡登等[14]提出基于地标点表示的谱聚类算法,通过数据点与地标点之间的相似度矩阵乘积来近似得到整体数据点的相似度矩阵,然后利用近似性质实现快速特征分解。
本文将采用基于地标点近似表示的方法,通过稀疏表示构造的相似度矩阵对柔性约束谱聚类算法模型[11]进行改进,并且根据约束集合内地标点的关系,利用Tarjan算法[15]自动检测连通区域,在每个连通区域内部动态调整近邻点,传递约束关系,从而更新稀疏表示矩阵提高聚类准确率。在5个大规模标准数据集上进行实验的结果表明,本文算法对这些大规模数据具有较好适应性,且在有效降低算法复杂度的同时,保证了约束谱聚类算法结果的准确率。
1 算法基本原理
1.1 约束 NCut算法
标准NCut的目标函数为

式中v表示松弛化的类指示向量。
假设已知“必连”约束集合M与“勿连”约束集合C,文献[11]根据约束信息生成约束矩阵 Q ,可表示为

通过式(3)来衡量 Q中约束关系与v的一致程度:
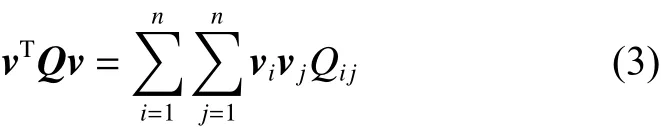
约束NCut的目标函数为
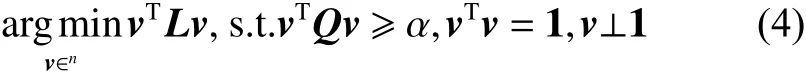
上述问题可转化为求解矩阵(的)特征(向)量[11],但是空间和时间复杂度分别为和,对于大规模数据集,计算复杂度过高;而且不具备约束传递功能,不能充分利用有限的约束信息。
1.2 依据稀疏表示的相似度矩阵
蔡登等[14]提出基于图稀疏表示的谱聚类算法,通过地标点的线性组合来实现所有数据点X的近似表示。对于给定的任一数据点,其近似数据点可以表示为


2 所提算法
2.1 约束关系传递
将在“必连”和“勿连”约束集合中的数据点视为地标点,其个数为p。根据约束关系生成一个的相似度矩阵,利用Tarjan算法检测强连通区域,会生成多个连通区域;对每个连通区域,动态调整其内数据的近邻点,进行约束关系的传递,对基于地标点近似表示方法中的稀疏表示矩阵进行更新。
根据约束信息所生成的相似度矩阵,利用Tarjan算法检测生成个强连通区域,可表示为,其中,,表示第a个连{通区域,包含}个数据点,表示的补集,,同一个连通区域内的数据之间相似度最大,在不同连通区域的数据之间的相似度最小,设置为

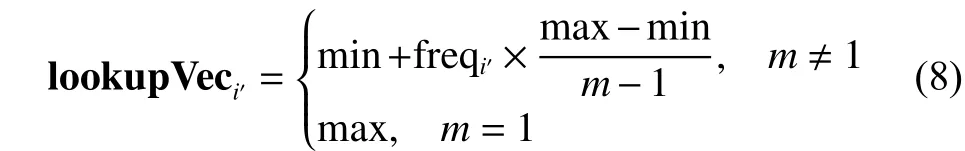

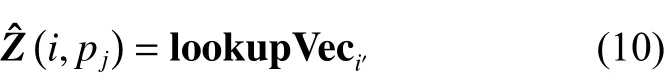
2.2 依据稀疏表示的可扩展半监督NCut算法
依据稀疏表示的约束NCut目标函数可表示为

基于文献[11]提出的方法,上述问题的求解可以松弛为一般的特征值求解问题:

【启示】只锈坏了一个扣,整条铁链也就失去了他的价值。不要对缺点和错误报以宽容的态度,哪怕是一丁点儿。否则,他就会像草原上的火种,一发不可收拾。
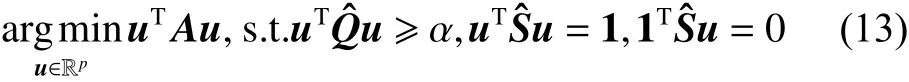
该模型等价于式(11)所表示的约束NCut目标函数,但是有两个改进:一是规范化的拉普拉斯矩阵变为矩阵;二是约束矩阵变为,因为,有效降低了计算复杂度。同样和文献[11]所提出的约束Ncut模型相比,一方面,通过地标点所构造的稀疏表示矩阵来近似获得相似度矩阵,避免对整个数据进行特征分解,大大降低算法的复杂度,能够很好地适应于大规模数据集;另一方面,在连通区域内部进行约束关系传递,更新矩阵,改进模型即式(13)中和也随着更新,可以充分利用初始有限的约束信息,提高聚类的准确率。
为了求解式(13),引入拉格朗日乘子,可扩展约束NCut问题转化为

需要满足KKT条件,即
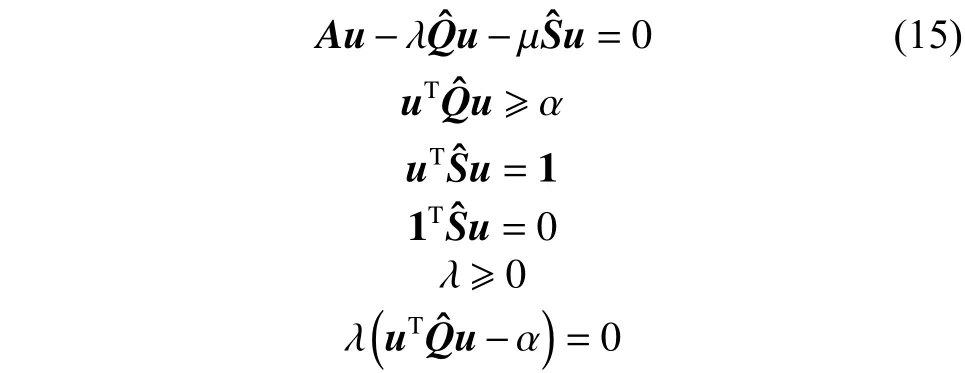
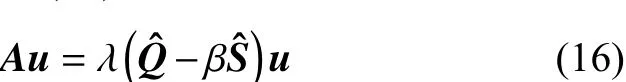
通过求解式(16)的特征值和特征向量,计算复杂度远远降低。
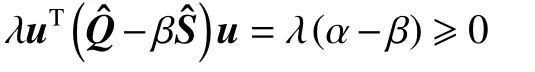
算法 结合稀疏表示与约束传递的半监督谱聚类算法
输出 类label。
1) 将在约束集合内的p个点选为地标点,并作为矩阵U的列向量;
3) 使用Tarjan算法,根据地标点之间的约束关系计算连通区域CC;
4) for 每个连通区域CC do:
根据近邻点出现频率的次数构建向量lookupVec;
根据式(9)将约束关系传递给该区域内剩余数据点;
end for
8) else求解式(16)的特征向量u;
2.3 算法复杂度分析
3 实验与分析
3.1 实验环境
为了验证本文算法的性能,选取规模较大的数据集进行实验,依次为物体图像数据集COIL100,人脸数据集CMU-PIE,手写数字数据集USPS、MNIST和UCI标准库中的森林植被类数据集CoverType,数据集的特性如表1所示。仿真实验基于MATLAB2014b平台,计算机的硬件配置为Intel i7-4770 CPU 3.40 GHz、16 GB RAM。
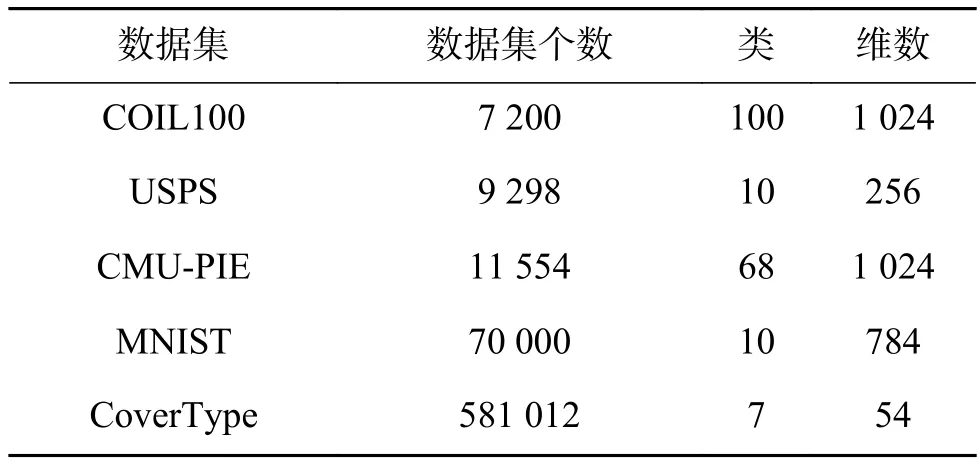
表1 实验数据集的特性Table 1 Experimental datasets features
本文算法和文献[11]的约束谱聚类方法CSP,文献[14]的基于地标点采样的快速谱聚类算法LSC-R和LSC-K,文献[15]所提出的针对大规模数据集的半监督谱聚类算法SC-PC进行对比,LSCR是通过随机采样来获取p个地标点,LSC-K是利用k-means算法来获得p个地标点。须指出,由于CSP算法在CMU-PIE、MNIST和Cover-Type数据集上计算负担过大,并没有进行相关实验的比较。
鉴于比较的公平性,具体的参数设置如下:其中文献[14-15]和本文算法的地标点个数p均设置为1 000,所有算法中k-means部分的迭代次数均设置为500,所有稀疏表示矩阵构造过程中的近邻点个数r设置为5。约束的下界即参数,其中,为的第个最大的特征值。
通过数据集中每个样本预定义的类标签来实现对聚类结果的评价,采用聚类准确率ACC和归一化互信息NMI两种度量指标[14]对聚类结果进行评估和比较分析。两个评价指标的取值范围均是在0~1之间,值越大表示聚类效果越好。
3.2 实验分析
各种算法在上述数据集的实验结果如表2所示。
根据表2可以看出,约束谱聚类算法CSP在COIL100和USPS两个数据集上的ACC和NMI均取得最佳结果,因为其考虑引入约束矩阵建立约束优化问题,提高聚类准确率,但是在上述两个数据集上的运行时间太长,耗时将近5~7 h,对于更大的数据集CMU-PIE、MNIST和Cover-Type数据集,计算负担过大,没能进行验证。本文算法在COIL100和USPS数据集的ACC分别为0.666 0和0.843 5,NMI指标分别为0.797 5和0.773 1,和CSP相比稍有降低;但从运行时间上,本文算法的运行时间仅在秒级别,耗时分别为3.51 s和1.88 s,远远少于CSP的运行时间,而且在包含581 012个样本的大规模CoverType数据集上运行时间只需要747.36 s,所以本文算法基于稀疏表示矩阵来建立相似度矩阵,降低了矩阵分解的复杂度,提高了半监督聚类算法的可扩展性。
另一方面,本文算法和LSC-K、LSC-R、SC-PC三种均为提升谱聚类的效率的算法,即快速谱聚类算法相比,在准确率ACC和归一化互信息NMI两个指标上有所提高,且在CMU-PIE和Cover-Type数据集上两个指标具有明显的提升;和SCPC算法相比,本文算法在CMU-PIE数据集上ACC、NMI分别提升了79.12%和38.58%,在CoverType数据集上ACC和NMI分别提升了15.02%和39.94%。因为在处理高维数据时,采用稀疏表示能够过滤一些异常点和噪声,同时指定约束下界,可去除一些噪声等约束关系的负面影响。因此,引入约束信息来改变谱聚类算法的目标函数,并通过在连通区域内进行约束关系传递,能够有效提高聚类的准确率。
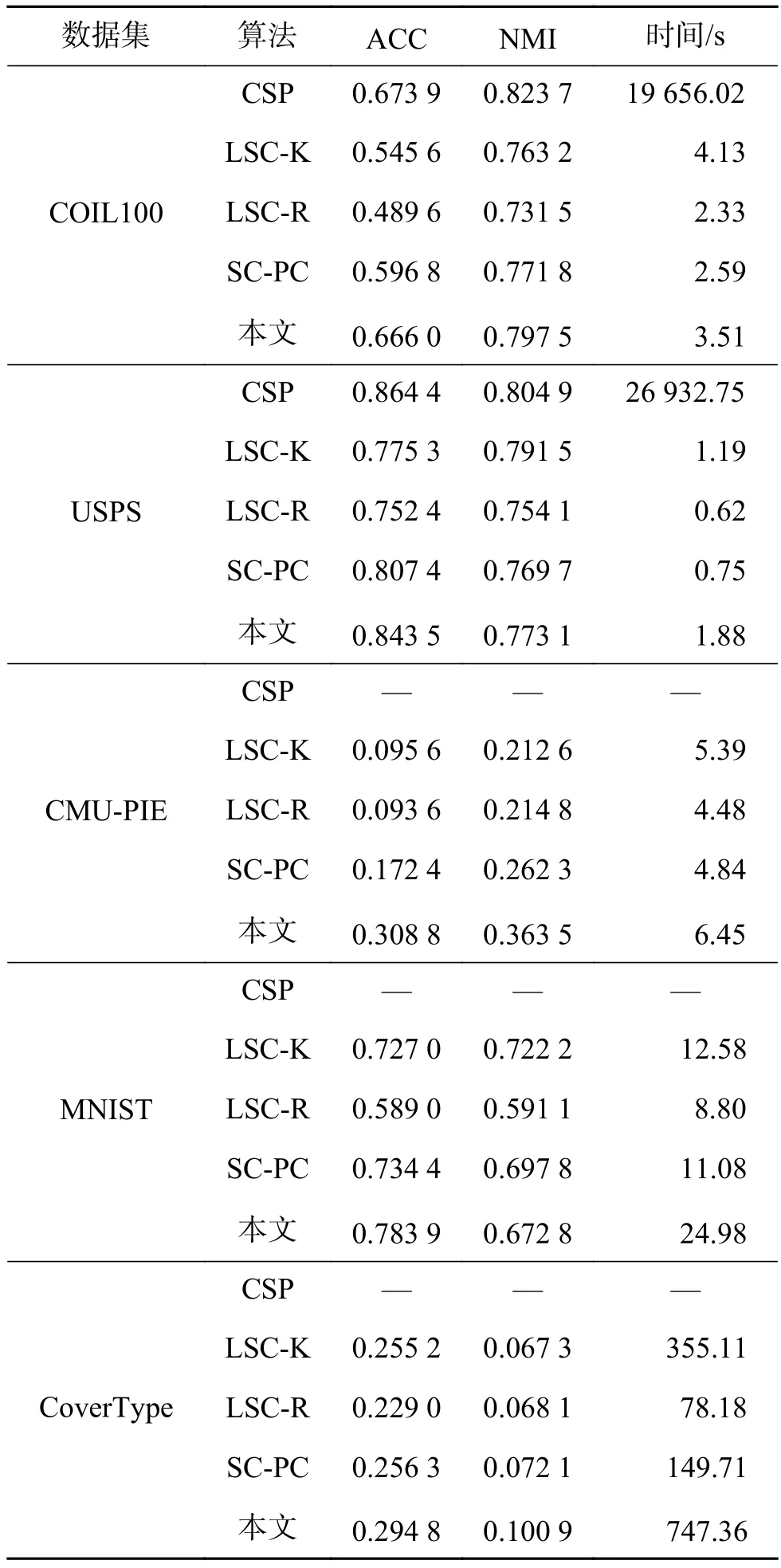
表2 各数据集实验结果Table 2 Experimental results of different datasets
为了分析初始约束信息对聚类结果的影响,添加了地标点个数p(对应半监督聚类中能获取的初始约束信息)对聚类指标影响的对比实验。同样,CSP算法只在USPS和COIL100两个数据集上实现。p依次取200、500、800和1 000。不同算法ACC和NMI的对比实验结果分别如图1、2所示。
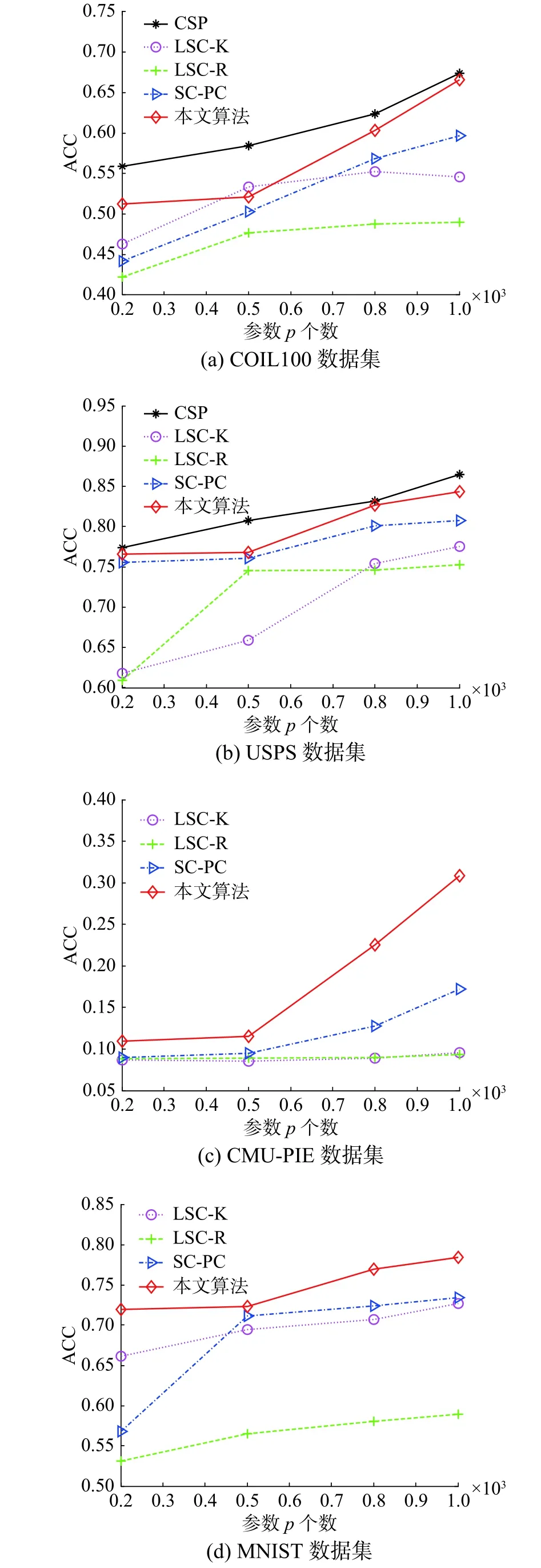

图1 不同算法的ACC比较Fig. 1 Comparison of the ACCs of different algorithms


图2 不同算法的NMI比较Fig. 2 Comparison of the NMIs of different algorithms
由图1可知,本文算法在5个数据集上的ACC比LSC-K、LSC-R和SC-PC三种算法都要高,随着参数p个数增加,每种算法的ACC也随着增加,说明ACC受p的选取影响很大。由图2可知,在NMI指标上,本文算法和快速谱聚类算法相比,在CMU-PIE和CoverType两个数据集上具有明显的优越性,同样随着p个数增多,每种算法的NMI都随着提高。总的来说,在p的不同取值情况下,本文算法能取得最好的聚类效果。
4 结束语
随着规模庞大、结构复杂数据的不断出现,对其聚类往往耗费大量的时间,同时多数半监督谱聚类算法存在没有充分利用初始约束信息的问题。本文通过稀疏表示改进约束谱聚类算法的目标函数,根据初始约束信息生成连通区域,在每个连通区域内动态调整近邻点进行约束关系传递。实验结果表明,本文算法在提高聚类准确率的同时能有效降低聚类复杂度,能够较好地适用于大规模数据集。但是本文算法的聚类准确率受采样地标点的个数和选取方法影响比较大,接下来可以针对该问题开展进一步的研究工作。
猜你喜欢
小学生学习指导(低年级)(2021年12期)2021-12-31 08:09:26
辽宁省博物馆馆刊(2021年0期)2021-07-23 07:27:08
小学生学习指导(低年级)(2020年9期)2020-11-09 09:11:22
数学年刊A辑(中文版)(2020年2期)2020-07-25 02:04:44
数学物理学报(2019年6期)2020-01-13 06:08:16
中国惯性技术学报(2019年6期)2019-03-04 09:50:10
数学物理学报(2017年5期)2017-11-23 07:51:31
中央民族大学学报(自然科学版)(2017年2期)2017-06-11 07:14:54
作文大王·低年级(2016年1期)2016-02-29 00:37:10
火控雷达技术(2016年3期)2016-02-06 02:30:28
