
面向新浪微博的意见领袖挖掘算法
2018-09-17 07:52:08刘俊杰邵维龙韩东红
计算机与现代化 2018年9期
刘俊杰,马 畅,邵维龙,韩东红,夏 利
(1.山西工程技术学院信息工程与自动化系,山西 阳泉 045000; 2.东北大学计算机科学与工程学院,辽宁 沈阳 110819)
0 引 言
新浪微博意见领袖一方面能有效引导热点事件的信息传播,另一方面在网络商品推荐领域也拥有强大的引导力。因此在新浪微博挖掘出符合需要的意见领袖,对于发挥微博信息的社会价值和商业价值有着非常重要的作用[1]。
基于此,本文提出在新浪微博上进行意见领袖挖掘的3步走策略整体框架。在建立新浪微博网络图模型的基础上,首先提出一种基于用户交互度的TCRank算法来对初始用户集合过滤,得到候选新浪微博意见领袖集合;其次设计基于活跃度、创新度、传播度的新浪微博意见领袖属性指标,并根据AHP层次分析法对各个特征指标权重进行计算,对候选意见领袖集合进一步精化;然后针对微博文本情感因素对意见领袖挖掘的影响,将用户博文和评论考虑进挖掘过程,引入支持度的概念,提出一种基于CNN卷积神经网络模型的新浪微博意见领袖抽取算法。
1 相关研究
当前主流用于挖掘新浪微博意见领袖的方法主要分为2种[2]:1)基于网络结构的方法;2)基于交互信息的方法。
基于网络结构的方法是根据用户间的关系构建用户网络拓扑图,然后利用复杂网络学中的知识,在以不对网络整体结构性造成破坏的前提下,对网络图中能够代表节点显著特征的指标得分进行计算[3]。文献[4]通过对复杂网络中度中心性最大的节点进行影响,验证这些节点能够控制网络中信息的传播,根据构建的社交网络图计算用户节点的中心度。发现度中心性在区分局部意见领袖上能产生更好的效果,而介数中心性和紧密中心性是用来区分全局意见领袖的显著指标。其中比较常用的包括度中心性分析[5]和PageRank中心性分析[6]。PageRank是Google算法的重要组成部分,目的是对Google网页的质量进行评估,文献[7]提出对其改进的InfluenceRank算法,同时将微博用户的博文质量和与粉丝间的联系考虑进去,计算出意见领袖的排名。
基于网络结构的方法主要关注意见领袖在网络中的结构特点,忽略了意见领袖在网络中的交互行为。新浪微博意见领袖通常会有比较高的节点度中心性分值,但并不是所有度中心性高的用户都会是微博意见领袖,为了更加准确地挖掘意见领袖,需要对更多、更细的特征进行分析。
微博用户作为新浪微博平台上信息传播的起点和终点,可以对喜欢的用户进行关注、发布自己的观点、对其他用户微博进行转发、对微博进行评论等和其他用户的交互行为,这些行为与信息在微博中的传播紧密相连,因此对微博用户交互行为的研究对分析意见领袖的特征起着很大的作用。文献[5]综合使用主观和客观加权的方法,根据构建的意见领袖指标对意见领袖进行挖掘。文献[8]介绍了社交网络中信息的传播过程,并利用#hashtag和URLs进行算法设计,对用户的传播特性进行定量计算,结果证明传播特性是区别微博意见领袖和其他用户的显著特征。文献[9]将极大似然问题的期望最大化解决方法应用到对意见领袖挖掘研究中,但算法的时间复杂度太高以至于不能应用到更大数据集上。文献[10]根据LeaderRank算法的缺陷,同时考虑了微博用户的活跃度和文本信息中点赞的属性来挖掘微博中的意见领袖。文献[3]综合使用博文的引用次数、评论次数和文本的长度来计算博文的影响力大小,挖掘出意见领袖用户。
上述2类方法各有优点和缺点。基于网络结构的微博意见领袖挖掘方法模型相对简单,计算效率比较高,适用于微博这种大规模的社交网络,但是由于忽略了一些用户自身重要属性,精确度不是很高。基于交互信息的微博意见领袖挖掘方法模型一般能够取得较好的结果,但是由于涉及大量的对交互信息的处理工作,不适合大型的社交网络。现今也有一些针对二者结合的研究。文献[11]根据用户属性挖掘的K个簇的集合同基于用户关系挖掘的中心取交集得到意见领袖集合。文献[12]根据定义的用户特征向量利用K-means聚类方法筛选意见用户集合,加入了博文的情感分析,最终得到意见领袖排名。
综上所述,可知目前用于识别微博意见领袖的方法单一,考虑的用户特征不全面而且组合方式杂乱,不能更加精确地发现新浪微博意见领袖群体。因此本文综合考虑网络拓扑信息、用户交互信息和文本情感信息等3方面的优势,旨在研究高效准确的新浪微博意见领袖挖掘算法。
2 新浪微博意见领袖挖掘算法
针对现有对新浪微博意见领袖挖掘算法的不足,本文提出通过构建网络拓扑模型的连接属性、用户行为的自身属性以及支持度对微博用户进行意见领袖的筛选。
2.1 基于连接属性的过滤算法
根据研究的需要,新浪微博社交网络拓扑结构图由3种结构构成:基于用户粉丝或关注的结构、基于微博评论的结构与基于微博转发的结构。新浪微博意见领袖的信息传播过程是在拥有链接关系的用户间进行传递的,故本文根据用户间链接关系对微博网络进行建模。
根据新浪微博本身带有的话题属性进行话题划分后得到指定话题数据集,本文根据其中的一个话题开展新浪微博的意见领袖挖掘工作。社交网络拓扑图通常由节点和边2种元素构成,其中用户用节点V表示,边用E表示,代表的是用户间链接关系。对用户间的边进行构建时,考虑到微博中经常标有“@”符号,即提醒@的用户收看这条微博,但这些用户可能并不在用户的关注列表内,因此本文也将这些用户考虑进网络结构中。网络拓扑结构的构建过程,构成本文的新浪微博用户社交网络,用以提高挖掘结果的准确性。
以微博用户为节点,用户间的关注关系和博文中的“@”用户关系为边,进行社交网络建模。模型构建算法的伪代码如算法1所示。
算法1网络拓扑模型构建算法
输入:话题下用户集合U、粉丝列表T和微博集合W。
输出:网络拓扑模型。
1.初始化队列Q为空
2.将用户集合U所有用户加入队列Q
3. While Q非空 do
4. ui=getHeadElement(Q)
5. Tj=getFollows(ui)
6. For Tj内任意用户ukdo
7. If ukin U
8. creat E(ui,uk)
9. End if
10. End for
11. For ui任意一条微博wkdo
12. If wk@ uk
13. creat E(ui,uk)
14. End if
15. End for
16. End while
行3至行5表示遍历用户集合依次获取每个用户及其粉丝列表,行6至行10表示将用户与存在于集合U中的粉丝建立连接,行11至行13,对用户与用户@过的粉丝创建连接。
建立了网络拓扑模型后,本文引入节点间交互度概念来计算网络中边的权值,并提出一种基于用户交互度的TCRank算法来对初始用户集合过滤,得到候选新浪微博意见领袖集合。
定义1转发交互度。假设用户Vj关注用户Vi,则Vj和Vi的转发交互度可计算为用户Vi被转发的博文中存在Vj用户转发的概率。计算公式如下:
(1)
其中Ni表示用户Vi微博被转发的数量,Nj表示用户Vi被转发的微博中有Nj条微博被用户Vj所转发。
定义2评论交互度。假设用户Vi关注用户Vj,则Vi和Vj的评论交互度可计算为用户Vi的博文评论中存在用户Vj的概率。计算公式如下:
(2)
其中Ci表示用户Vi微博被评论的数量,Cj表示用户Vi被评论的微博中有Cj条微博被用户Vj所评论。
定义3交互度。w(Vi,Vj)表示用户Vi和用户Vj间的交互度,计算公式所下:
w(Vi,Vj)= s+
(3)
本文认为用户在转发行为和评论行为上对交互度起到的作用是相等的,所以在计算权重的时候采用平均分配的原则。其中s代表赋给用户节点间连接边的初始权值,s的取值是通过多次实验获得的,取值0.2时实验结果更为准确。当用户A发布微博之后,假设与用户A连接的节点并没有对其微博进行评论和转发,则交互度会相对较低,但是由于与用户A间存在边的关系,还是能够通过边将自己的影响力进行分配,即拥有一个初始交互度。
传统的PageRank算法基本思想是将PR值平均传递给相连的网页,这种传递方式会造成网络中的有些旧网页由于存在的时间更长,网页被链接的数量通常高于其他网页,按照算法计算该网页会拥有较高的价值。然而旧网页中的内容可能已经没有时效性,质量不一定非常高,从而导致这些网页的PR值非常高但真实质量很低。同样该模型应用于新浪微博用户网络时,用户间的关系也不会是同等的,如同现实生活中每个人对待每个朋友的态度也会不一样。因此对于新浪微博,用户根据其他用户与自己的联系紧密程度进行影响力值的分配,联系越紧密,分配的值越高。基于上述分析,将PageRank算法应用到新浪微博网络中也是可行的,因此本文提出对PageRank进行改进的算法。改进的TCRank算法如公式(4)所示。
(4)
其中TC(Vj)为改进TCRank算法对用户Vj计算得到的分值,d为阻尼因子,一般取值范围为(0,1),本文取值为0.85。Fol(Vi)表示用户Vi的关注和Vi微博@的用户列表,w(Vi,Vj)表示用户Vi和用户Vj间的交互度,由公式(3)得到。TCRank是基于PageRank的改进,通过增加权重而应用在意见领袖集合方向,因为权重是固定值,不影响算法的收敛性,所以在用户列表很大的时候必然会迭代收敛。另外,当用户列表过少时,在对用户集合内的每个用户均进行过滤后,虽然未完成迭代,但是体现了在当前这个少量用户群体的影响力,故同样取前K个,得出意见领袖的集合。
根据上述分析过程,算法2为本节TCRank算法的伪代码。其中TCR为每个用户节点的PR值,K为算法计算得到的Top K意见领袖候选集的用户的数量,ε为算法收敛阈值,‖TCR‖表示向量的长度。
算法2基于连接属性的TCRank过滤算法
输入:话题用户集和G=(V,E),转发列表VR和评论列表VC。
输出:Top K候选意见领袖集合。
1. TCR←1
2.For each user v, u∈V do
3.根据VRv和VCu列表使用公式(3)计算用户交互度w(u,v)
4. End for
5.i←1
6. ε←0.0001
7. σ←1
8.While σ>ε do
9.使用公式(4)计算TCRi+1
10.σ←||TCRi+1-TCRi||
11. i←i+1
12.End while
13. return TopK(TCR)
首先将TCR设定为1,行2到行4对于集合V的用户,两两计算交互度。行5至行7设定初始值,行8至行12,通过公式(4)计算当前用户与其交互的TCR值,不断进行迭代直到停止条件。
2.2 基于自身属性的精化算法
为了使算法适应新浪微博平台上的意见领袖特征的独特性,本文设计更加准确的新浪微博意见领袖的特征。采用层次分析法对特征进行权重分配,从而得到精化后的候选意见领袖集合。本研究认为基于新浪微博的意见领袖自身属性研究应该从活跃度、创新度、传播度3个方面进行衡量,即分别通过公式(5)~公式(7)进行计算。
定义4用户活跃度Activity。当给定用户发帖数Npost、用户发帖频率Fpost、用户评论数Ncomment、用户评论频率Fcomment、用户收藏数Nfavorite及上述相应特征的权值W11、W12、W13、W14、W15,计算如公式(5)所示。
Activity=W11×Npost+W12×Fpost+W13×Ncomment+
W14×Fcomment+W15×Nfavorite
(5)
定义5用户创新度Innovate。当给定用户原创比例Poriginal、用户带评论转发比例Prepost、用户微博平均长度Nlength,W21、W22、W23分别表示上述相应特征的权值,计算如公式(6)所示。
Innovate=W21×Poriginal+W22×Prepost+W23×Nlength
(6)
定义6用户传播度Spread。当给定用户微博转发H指数Hrepost、用户微博评论H指数Hcomment,W31、W32分别表示上述相应特征的权值,计算如公式(7)所示。
Spread=W31×Hrepost+W32×Hcomment
(7)
H指数代表高引用数目,如果一个学者在一定的时间内发表的论文中至多有H篇被引用了至少H次,则称H为该学者论文影响力的H指数。将H指数应用到微博转发和评论中,能够增强不同微博之间的可比性,更加客观地反映用户微博的传播能力。
对于转发H指数Rh,表示一个微博用户在某一时间段内所发博文中有N篇博文的转发数不少于N的指数;对于评论H指数Ch,表示一个微博用户在某一时间段内所发博文中有N篇博文的评论数不少于N的指数。
对新浪微博意见领袖的活跃度、创新度、传播度3个特征计算用来精化候选微博意见领袖集合,本研究使用AHP层次分析法对3个特征进行加权。
在对新浪微博意见领袖进行特征设计和权值计算之后,根据公式(8)计算得到基于用户自身属性的新浪微博意见领袖得分。
Selfscore=W1×Activity+W2×Innovate+W3×Spread
(8)
2.3 基于支持度的抽取算法
在新浪微博平台上,用户经常会发布微博来表达自己的观点态度,也会对其他用户的微博进行评论,这些文本都会在意见领袖的意见传播过程中起到非常重要的作用,因此本文针对上述结果从评论文本上提出基于支持度的意见领袖抽取算法。
针对很多研究忽略了文本在挖掘意见领袖中的作用,本文提出一种基于卷积神经网络结构的文本情感分析方法,综合考虑文本中上下文信息,对微博用户的博文和评论进行文本分析。
1)文本预处理过程包括以下步骤:①评论筛选。本文只获取每条微博下用户第一次发布的评论文本。②噪声处理。在本文中的算法是基于中文评论文本,如果文本中只包含英文字符、标点符号、特殊符号、URL等非文本信息,便定义它为噪声文本。③分词处理。本文中使用中国科学院计算技术研究所张华平博士设计的NLPIR/ICTCLA2014分词系统,对获取的所有评论文本和微博文本进行分词操作。④停用词去除。根据停用词表对分完词的文本集合进行停用词的删除。⑤词向量训练。使用word2vec对分词后的文本进行训练。
2)进行模型构建,本文使用CNN模型来对微博文本进行情感支持度的分类,针对微博评论文本,在提出的CNN卷积神经网络结构图中,总共分为4个结构部分,分别为文本输入层、卷积层、下采样层、全连接层。①输入层。第一层为输入文本的向量矩阵层,即经过最初的文本预处理工作之后,为所有的评论文本构建向量表示形式。②卷积层。实验中采用ReLu函数作为卷积核函数进行特征抽取。③下采样层。使用Top K(K=2)池化方法进行简化。④全连接层。通过下采样层得到特征向量Z=(V1,V2,…,Vt), t=L×K,其中L为滤波器的个数,K为下采样层选取的Top K最大池化特征抽取方法的K值,将Z作为全连接层的输入,最后根据Softmax函数输出分类结果。基于正向和负向意见领袖提出微博意见领袖支持度的概念,基于支持度的新浪微博意见领袖抽取算法的伪代码如算法3所示。
算法3基于意见领袖支持度的抽取算法
输入:用户集合U、微博集合W、评论集合S、评论训练数据Strain、测试数据Stest。
输出:Top K微博意见领袖排名。
1.使用word2vec和情感字典构建句子词向量矩阵
2.Repeat
3.使用训练数据Strain对CNN模型进行训练
4.更新CNN模型权值
5. Until模型参数收敛
6. For each测试数据微博Wi
7.使用CNN模型对Wi进行情感标记
8. End for
9. For each用户集合中Ui
10.For each Ui微博Wj
11.For each Wj评论Sk
12.If Sk∈正例
13. SupportScore(Ui)++
14.else if Sk∈负例
15.SupportScore(Ui)--
16.End if
17. End for
18. End for
19. End for
20. return TopK(SupportScore(U))
行2至行7,使用训练集对CNN模型进行训练并对测试数据进行情感标记。行9至行18,通过每个用户的每个微博的正向及负向的评论计算用户的支持度(SupportScore),进而得到排名。
3)本文基于初始用户集合进行过滤、精化和最终抽取3个步骤,最终得到话题下新浪微博意见领袖(WeiboRank)具体算法的伪代码如算法4所示。
算法4WeiboRank算法
输入:新浪微博API爬取的所有数据。
输出:Top K微博意见领袖最终排名。
1.根据爬取的微博话题进行话题划分获得话题数据集
2.根据话题数据集用户关系进行网络建模
3. If ui∈话题用户满足基于连接属性过滤条件
4.获得新浪微博意见领袖候选集合U1
5. End if
6.对微博意见领袖设计特征指标
7.计算各特征指标权重
8. If ui∈U1满足基于自身属性的精化条件
9.获得新浪微博意见领袖候选集合U2
10. End if
11.使用评论集合训练集对CNN网络模型进行训练
12.使用CNN网络模型对评论集合测试集进行分类
13. If ui∈U2满足基于支持度的抽取条件
14.获得新浪微博意见领袖集合U3
15. End if
16.return TopK(U3)
行3至行5通过算法1,对用户进行过滤,得到意见领袖候选集合,行6至行10采用算法2,通过微博领袖的特征对候选集合中的用户进行再次筛选,行11至行15通过算法3在集合中获得最终的意见领袖集合。
3 实 验
本文的实验数据集来源为新浪微博开放平台,通过新浪微博API获取2016年5月2日到5月16日发布的微博信息,总共爬取了6126583条用户微博,其中包含539564个用户。本文面向新浪微博意见领袖算法采用话题下的数据集,从所有用户微博中抽取了所有话题中包含“#魏则西#”的微博。
实验结果评价标准如下:
1)对于评论文本的情感支持准确率定义如公式(9)所示。
(9)
其中TP表示本为正类且分类正确的文本数目,FP表示本为负类却分为正类的文本数目。
2)虽然已经出现了很多对新浪微博意见领袖挖掘问题的研究,但是还没有一个公认、统一的用于对微博意见领袖挖掘结果进行评价的标准,本文利用公式(10)对算法的挖掘结果进行评价。
(10)
其中LeaderAccuracy(K)表示挖掘结果取前K个用户的准确率,T(K)表示挖掘结果前K个用户中人工判定为真正意见领袖的个数。在本实验中,2名工作人员对初始用户集合根据用户的自身属性、交互属性、评论文本支持度属性来判断用户是否为对应话题下的意见领袖。通过以上标准验证本算法在面向新浪微博意见领袖挖掘问题上有良好的效果。对于人工评价而言,不同的实验室对于意见领袖的相关特征定义也不同,特征对意见领袖的筛选有着决定性作用,这样使不同的算法在不同的意见领袖特征下的准确度有着很大的偏差。故本次实验并没有与其他改进的算法进行比对。相比较而言,与经典算法在相同意见领袖特征的条件下进行比较,更具有代表性。
3.1 基于连接属性过滤算法分析
根据本文提出的基于用户连接属性的过滤算法,使用PageRank算法和本文提出的TCRank算法分别进行实验,其中TCRank算法公式(4)中根据经验取值为0.2,分别取排名结果前10名如表1所示。
表1 基于连接属性过滤的微博意见领袖排名

排名PageRankTCRank1财经网公元18742四处流窜骨架龙风青杨V3海外美食作家冰清椒江叶Sir4风青杨V逆光驴行5公安部打四黑除四害李昌隆6电商头条幽灵战车龙鼠君7生命时报地球剑客8拆船卖铁乌克兰丁香园9逆光驴行杜君立10lxd向东凯雷
由表1可以看出,PageRank算法和TCRank算法计算得到的用户排名有很大的不同,在PageRank算法中,对由TCRank算法得到的用户排名进行分析,可以看到排名靠前的用户粉丝量相比PageRank算法得到的排名用户的粉丝量相对较少,但是这些用户更倾向于和其他用户进行交互,而分析具体的粉丝数据也会发现整个群体的领袖得分都会比较高,说明了TCRank算法的有效性。在对初始用户集合根据TCRank算法进行微博用户的意见领袖排名计算之后,本文取排名前3000的微博用户作为过滤后的候选意见领袖集合。
3.2 基于自身属性精化算法分析
首先根据活跃度、创新度、传播度的下属指标进行权重计算,对候选意见领袖集合进行精化计算,得到基于微博自身属性的意见领袖排名,取排名结果的前10名如表2所示。由表2结果和TCRank结果进行对比可以发现,虽然TCRank算法将用户之间的交互度考虑进去,但主体结构还是根据社交网络结构进行挖掘,在很大程度上基于用户间的边关系,虽然能将所有的新浪微博意见领袖划分到最终排名的前部,但是不能对排名进行更加细化,难以对实际应用产生价值。
表2 基于自身属性精化的意见领袖排名
通过对候选意见领袖集合进行基于用户自身属性的活跃度、创新度、传播度的意见领袖得分计算,可以明显看到精化后得到的意见领袖排名前列用户,和候选意见领袖集合的前列存在重复用户,但是在排名靠前的用户中也出现了很多新用户。在对3000名候选微博意见领袖进行基于用户自身属性精化操作之后,排名靠前的用户基本满足新浪微博意见领袖的特征,本文选取其中前1000名用户进行下一步抽取,得到文本情感粒度上的意见领袖。
3.3 基于支持度的抽取算法分析
本节实验使用CNN模型对精化后的候选意见领袖集合进行抽取,首先需要对CNN模型进行训练,训练集采用精化后的候选意见领袖的全部微博和评论数据。对评论文本进行预处理后,有10253条评论数据符合本文需求。本文的训练集共分为2部分,一部分为京东有关红酒的评论集,正反支持度文本各2000条,最长评论分词后含102个词;另一部分为本文对评论文本进行人工标注获得,其中有2500条支持评论,1500条反对评论,最长评论包含有125个词。
根据训练得到的CNN模型来对剩余的评论文本的情感支持度进行计算,然后对候选意见领袖集合内的用户的支持度得分进行计算,最终得到基于支持度的新浪微博意见领袖排名,结果表3所示。
表3 基于情感支持度的意见领袖排名
由表3可以看出,对候选意见领袖集合进行基于支持度的意见领袖抽取工作,排名靠前的用户均获得了更高的支持度得分,为微博正向意见领袖。这是由于“魏则西”事件的起因,是由恶意虚假广告引起的,而网上关注这个话题下的用户在思想和行为上都比较积极向上,大多都为事件鸣不平,痛斥这种现象的发生,弘扬正能量,因此正向用户普遍较多。
本文将本节抽取的意见领袖排名靠前的用户作为最终挖掘到的新浪微博意见领袖,结果显示这些用户和基于自身属性精化得到的候选意见领袖大部分重叠,但有排名上的变化,例如昵称为“刑法韩友谊”用户在精化后候选列表中排名248名,但纵观他发布的微博文章的评论用户都是持支持态度的,因此在最终挖掘的排名中排名上升极快,这也符合挖掘新浪微博意见领袖的目的,即找到那些更具有说服力的群体作为新浪微博的意见领袖。
最后为了评估本文提出的面向新浪微博意见领袖挖掘算法的准确性,通过计算不同意见领袖挖掘算法下Top K意见领袖集合的准确率,实验结果如图1所示。
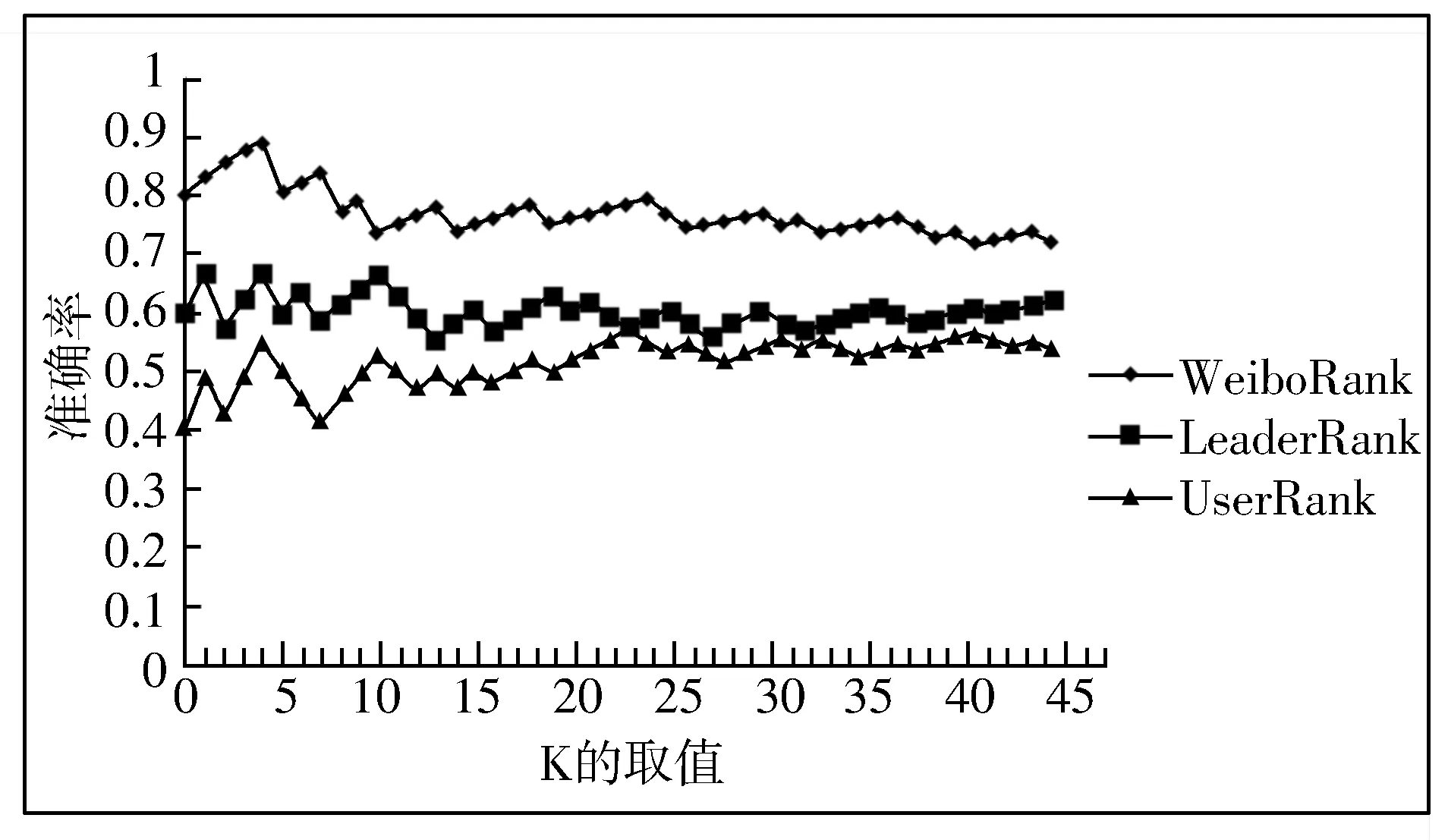
图1 不同算法下Top K意见领袖集合准确度
图1中WeiboRank算法是本文提出的新浪微博意见领袖挖掘算法,由图可以看出,本文提出的算法在K等于5时准确率最高,随着K值的增大,准确率出现了略微下降,但是准确率大小浮动不大,始终保持在80%左右,对新浪微博中的意见领袖的挖掘有着更高的准确率。
同时,通过对图中LeaderRank算法、UserRank算法和本文提出的WeiboRank算法在不同K值下意见领袖用户集合在准确率上计算所得的数值的比较,不难看出WeiboRank算法的计算结果相比其他2种算法具有更高的准确率。因为相比于其他2种算法,本文算法综合使用了网络结构信息、用户交互信息和文本信息的优势,并有效地对方法进行融合、优化,因此本文算法可以很好地适应新浪微博意见领袖的挖掘。
4 结束语
本文面向新浪微博意见领袖的挖掘研究主要分为3个步骤:基于连接属性的过滤、基于自身属性的精化和基于支持度的意见领袖抽取。首先,根据话题下数据进行新浪微博用户网络建模操作,并通过改进PageRank算法的TCRank算法对初始用户集合进行过滤。接着,通过对新浪微博用户自身属性的分析,提出活跃度、创新度、传播度的概念,并用AHP分析法计算各特征指标权重,计算微博用户的自身属性得分,对微博候选意见集合进行精化。最后,根据微博用户评论文本构建CNN模型,并用人工标注好的训练数据对其进行训练,再对测试文本进行情感分类,继续对候选意见领袖集合进行抽取,最终得到基于支持度的微博意见领袖集合。通过上述实验部分中对挖掘过程中各个步骤的结果分析可以得知,本文提出的算法与传统算法相比,具有更高的准确率。
另外,因为新浪微博API的限制,本文对数据的获取并不完整,因而会影响最终结果的准确性,因此下一步将对利用API和网络爬虫相结合的方法进行深入研究,获取更全的微博数据。同时,对话题网络的构建是根据微博文本中的话题标签进行构建,模型比较简单,会忽略掉一部分没有添加话题标签但具有相同话题的博文,因此未来需要提出更好的话题建模的方法。
猜你喜欢
作文大王·低年级(2022年3期)2022-03-19 18:09:52
读者(2021年20期)2021-09-25 20:30:35
计算机技术与发展(2018年4期)2018-04-13 01:06:55
小学生作文·小学低年级适用(2018年12期)2018-04-11 03:10:42
阅读时代(2017年3期)2017-03-11 07:24:51
电子世界(2017年2期)2017-02-17 00:54:00
校园英语·下旬(2016年2期)2016-03-18 10:23:20
快乐作文·低年级(2014年10期)2015-01-14 23:43:55
计算机与现代化(2014年7期)2014-07-03 08:16:04
测绘科学与工程(2013年2期)2013-03-11 15:07:29
