
改进YOLO v2的装甲车辆目标识别
2018-09-17 07:52:06王曙光吕攀飞
计算机与现代化 2018年9期
王曙光,吕攀飞
(中国人民解放军陆军炮兵防空兵学院兵器工程系,安徽 合肥 230031)
0 引 言
基于图像的目标识别技术是指利用计算机视觉技术将目标从图像中自动检测出来,并对目标的类别、大小和位置进行判断。目前该技术已经在精确制导、目标自动跟踪、视频监控等领域得到了广泛应用。由于坦克装甲车辆仍是目前陆地的主要作战力量,因此对敌方装甲目标进行精确打击和监控对于战争结果具有不可忽视的影响。
近年来随着卷积神经网络在提取图像高层次特征方面的不断进步,各类基于卷积神经网络的目标识别算法取得了突破性进展[1]。Girshick[2]和Ren等[3]分别提出的Fast R-CNN和Faster R-CNN大幅提高了目标识别的准确率,但由于识别过程中计算量较大,帧率只能达到5帧/秒,因此不能实现对目标的实时识别。随后Redmon等[4]提出的YOLO网络虽然将识别速度提高到45帧/秒,但却牺牲了部分准确率,容易出现对目标的遗漏和误识别。Liu等[5]在YOLO的基础上提出了单发射击检测器(SSD网络),在识别速度上,SSD比之前的YOLO要快很多,在检测精度上,也和Faster R-CNN相当。为了提高检测准确率,SSD网络在不同尺度的特征图上进行预测,此外,还得到具有不同纵横比的结果,即使图像的分辨率比较低,也能保证检测的精度。此后Redmon等通过使用批量规范化、维度聚类、多尺度训练等多种改进方法在2016年提出的YOLO v2网络,在大幅提高识别速度的同时也提高了识别精度,目前,YOLO v2在VOC2007数据集上的检测速度已经达到67帧/秒,同时平均准确率mAP也达到了76.8%,在目标识别领域取得了最佳识别效果。
为了保证图像目标识别的精度和实时性,满足特定的识别任务,本文以当前具有最佳识别效果的YOLO v2为基础网络进行改进,通过对自制的装甲目标数据集中手工标记的目标框进行k-means维度聚类分析,确定了最优的anchor boxes的个数和宽高维度。
1 YOLO v2网络结构与原理
1.1 基础网络模型
YOLO v2借鉴了YOLO和SSD的网络结构,但与SSD网络不同的是YOLO v2以Googlenet[6]作为基础网络,而SSD的基础网络为VGG-16。表1为Googlenet和VGG-16网络的性能对比,由表1可以看出虽然在目标识别精度上Googlenet网络略低于VGG-16网络,但是Googlenet却大大压缩了网络训练的计算量,加快了识别的速度,这对于实时性要求较高的装甲目标识别任务具有重要作用。
表1 Googlenet与VGG-16的性能对比

网络一次前向传播的计算量/亿次检测精度/%Googlenet85.288VGG-16306.990
YOLO v2网络包含了19个卷积层和5个最大池化层,为了压缩特征同时增加网络深度,在3×3的卷积核之间加入1×1的卷积核,每次池化操作后将通道数翻倍。去掉了全连接层,使用全局平均池化进行网络预测,这大大提高了网络提取图像深层次特征的能力,使得网络对目标的识别精度得到了大幅度提高。
1.2 YOLO v2相对于YOLO的改进
YOLO v2借鉴了Faster R-CNN的anchor 机制并采用维度聚类寻找到最佳的anchor个数与宽高维度对目标框进行回归。
YOLO v2在卷积池化层与激活函数间加入Batch Normalization(批量规范化)对每一层的输入数据进行规范化,使每一层输入数据的均值为 0,方差为 1。由于神经网络每层输入的分布总是不断发生变化,因此YOLO v2通过标准化上层输出,均衡输入数据分布,使训练速度明显加快,同时降低了激活函数在特定输入区间达到饱和状态的概率,避免梯度消失问题。输入规范化也对样本进行了正则化,在一定程度上可以替代Dropout层。
训练过程一般分为2个步骤:1)通过ImageNet训练集对分类网络进行高分辨率的预训练;2)在分类网络的基础上进行微调,目的是训练检测网络。YOLO v1以分辨率为224×224的图片来训练分类网络,而YOLO v2则将分类网络的分辨率提高到了448×448,高分辨率样本将识别的mAP提高了约4%。
此外对目标框使用直接位置预测避免了直接进行anchor回归导致的模型不稳定,YOLO v2每经过10个Batch就会随机选择新的图片尺寸,为了最后一层得到特征图尺度为13×13, YOLO v2输入图片尺寸为416×416(416=13×32),降采样参数为32,通过不同尺度图片的训练提高了网络对不同环境的适应性。
2 改进的YOLO v2网络
2.1 YOLO v2的anchor机制
YOLO v2再次证明了Faster R-CNN提出的anchor机制在边界框回归过程中发挥的重要作用,如图1所示,YOLO v1采用7×7的网格对输入图像进行分割,每个网格只能预测对应2个anchor boxes,这2个box共用一个分类结果。YOLO v2采用13×13的网格对输入图像进行分割,增强了对小目标的检测能力,每个网格预测k个anchor boxes,对应了k个不同的尺度,每个box具有独立的分类结果,大幅提升了网络的平均准确率。同时,YOLO v2采用k-means[7]算法对手工标定的目标框进行维度聚类,寻找到最优的k值与anchor的宽高维度[8],使得生成的anchor boxes更具有代表性。
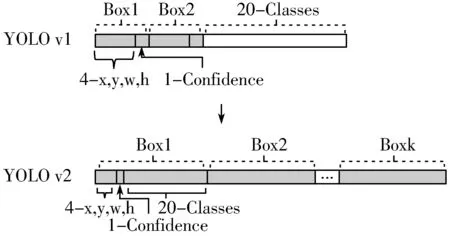
图1 YOLO v1与YOLO v2的anchor box
2.2 装甲目标数据集的anchor参数确定
尽管YOLO v2[9]在VOC和COCO数据集上取得了令人满意的效果,但其对于自制的装甲目标数据集并不完全适用。如果直接采用原有的网络参数训练生成权重文件,测试时发现容易对目标产生错误识别,平均识别率较低。
在实际目标识别的过程中发现anchor的个数和大小的选取对识别的精度和速度产生着重要影响。虽然训练过程中网络会通过学习调整边界框的宽高维度,最终得到bounding boxes,但是,如果训练阶段就选择了更好的、更有代表性的anchor box维度,那么网络就更容易学到准确的预测位置。YOLO v2通过在VOC数据集上进行维度聚类分析得到了适合自身数据集的anchor个数与宽高维度,其中扁长的框较少,而瘦高的框较多,更利于检测类似于行人的目标,自制装甲目标数据集的边界框中扁平的较多,瘦高的较少,因此对VOC数据集的维度聚类结果不利于对装甲目标进行识别。
为适应自制装甲目标数据集中手工标定的目标框,达到最优的识别效果[10],本文采用k-means算法对数据集中目标框的统计规律进行维度聚类分析,得到适合自制数据集最优的anchor个数和宽高维度[11]。
d(box,centroid)=1-IOU(box,centroid)
(1)
k-means采用的距离函数(度量标准)如式(1)所示,实验中使用爬山法选取k值,当k值增加到某一数值时目标函数d的变化越来越小,然后将此处拐点的k值作为最优的聚类个数。使用k-means算法对目标框的宽高进行维度聚类分析,直到相邻2次聚类的结果相同时停止迭代过程,取不同的k值时目标函数d的变化如图2所示,由图可得当k>4时,目标函数变化逐渐平稳,所以取聚类个数k=4。当k=4时,采用k-means算法对目标框进行维度聚类分析,产生的聚类结果如图3所示,图中不同的灰度对应着不同类别的目标框,将聚类结果中的聚类中心坐标作为anchor的宽高维度,因此anchor的个数为4,anchor参数分别为 (1.12, 1.31)、 (2.00, 2.31)、 (3.42, 3.72)、 (5.29, 5.93),分别对应Ⅰ、 Ⅱ、 Ⅲ、 Ⅳ区域的聚类中心坐标。
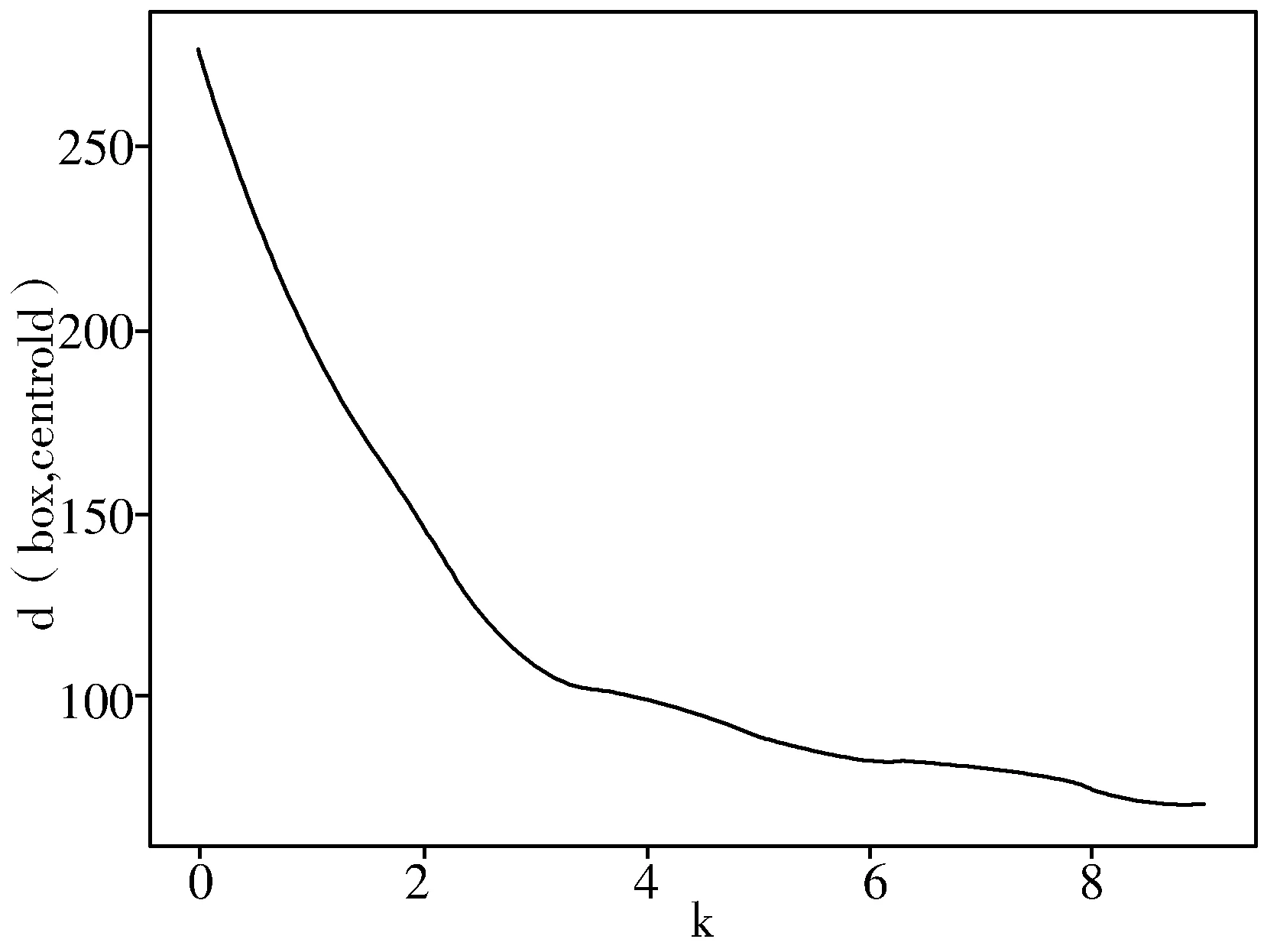
图2 目标函数变化曲线

图3 目标框聚类分布图
3 实验验证与结果分析
实验设备配置如下:CPU采用Intel(R) Xeon(R) E5-2683 v3 主频2.00 GHz;内存为32 GB;显卡采用英伟达Quadro K4200和英伟达Quadro M4000双显卡;操作系统为Windows 10;框架为TensorFlow。
网络参数配置为:learning_rate=0.0001; policy=steps; batch=64; steps=100, 25000, 35000; max_batches=45000; scales=10, 0.1, 0.1; momentum=0.9; decay=0.0005。
自制装甲目标数据集共有5000张装甲车辆图片,其中4000张图片作为训练集,1000张作为验证数据集。另外,分别建立具有400张、600张和800张图片共3个不同的测试数据集对训练效果进行检测。训练集和验证集采用VOC数据集格式进行手工标定,测试数据集用于测试训练效果。
预训练阶段首先采用ImageNet数据集对网络进行训练,然后采用分辨率为224×224大小的装甲目标数据集对网络参数进行微调,随后修改分辨率大小为416×416像素,在自制装甲目标数据集上训练10 epoches,使网络适应高分辨率下的输入,得到预训练的权重文件。
采用预先设置的网络参数和预训练阶段得到的权重对自制装甲目标数据集训练2000次,分别统计训练过程中第0次、第500次、第1500次、第2000次的类别准确率、召回率和损失值如表2所示。从表中可以看出训练过程中网络能够保持较高的召回率,网络参数能够按照预期收敛。
表2 准确率、召回率、损失值变化过程
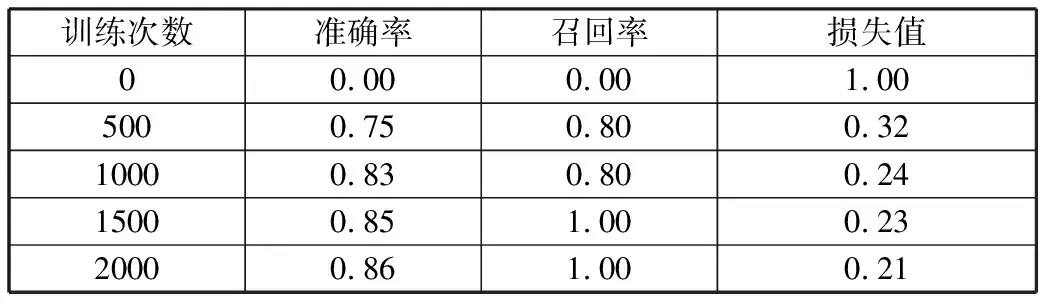
训练次数准确率召回率损失值00.000.001.005000.750.800.3210000.830.800.2415000.851.000.2320000.861.000.21
可以看出通过维度聚类的方法对自制装甲目标数据集中的目标框进行聚类分析,得到了最优anchor个数和宽高维度,优化了YOLO v2网络对特定目标的识别效果。表3比较了Faster R-CNN、 YOLO v2和经过本文方法优化后的YOLO v2对装甲目标的识别效果,可以看出本文方法可以在候选框较少,占用较少资源的情况下保持较高的平均重叠率[16]。
表3 候选框生成方法性能对比
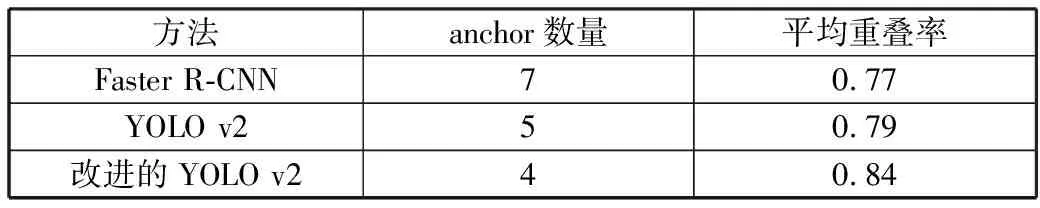
方法anchor数量平均重叠率Faster R-CNN70.77YOLO v250.79改进的YOLO v240.84
表4~表6比较了在3种不同测试数据集中目前主流的目标识别算法以及本文改进的YOLO v2方法识别的查准率、查全率和检测速度。从表中数据可以看出Faster R-CNN的识别精度较高但识别速度只有5帧/秒,不能对装甲目标进行实时识别。YOLO v2在各数据集中的准确率和查全率均优于此前的YOLO版本,但与本文方法相比,通过k-means维度聚类算法改进的YOLO v2网络对装甲目标的识别精度均高于原来的YOLO v2,可以达到85%以上,识别速度可以达到69帧/秒,满足了对装甲目标的高准确率实时识别。
表4 各算法在测试集1上的实验结果
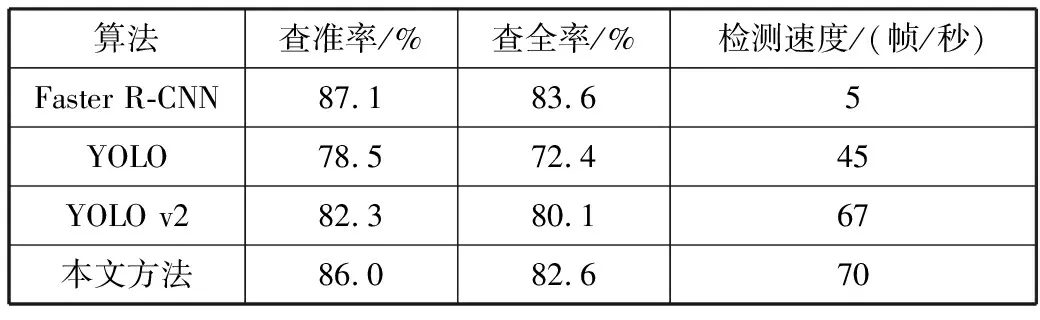
算法查准率/%查全率/%检测速度/(帧/秒)Faster R-CNN87.183.65YOLO78.572.445YOLO v282.380.167本文方法86.082.670
表5 各算法在测试集2上的实验结果

算法查准率/%查全率/%检测速度/(帧/秒)FasterR-CNN86.582.75YOLO75.170.045YOLO v281.478.668本文方法85.180.269
表6 各算法在测试集3上的实验结果
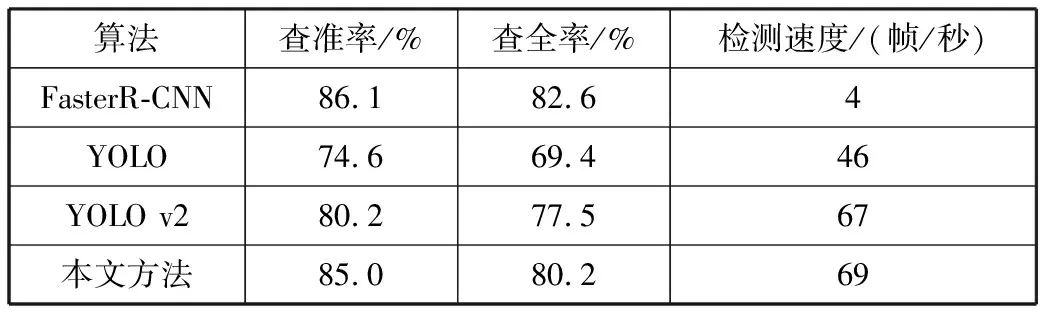
算法查准率/%查全率/%检测速度/(帧/秒)FasterR-CNN86.182.64YOLO74.669.446YOLO v280.277.567本文方法85.080.269
通过对测试数据集中的样本进行测试,未经过维度聚类分析的实验结果如图4所示,经过维度聚类后改进的YOLO v2实验结果如图5所示,可以看出本文方法相比目标框未经维度聚类分析的YOLO v2具有更精确的识别效果,大大降低了目标的误识别率。

图4 YOLO v2识别结果

图5 改进的YOLO v2识别结果
4 结束语
通过对训练数据集手工标定的目标框进行维度聚类分析,利用k-means算法找到了最优的anchor个数和宽高维度对YOLO v2进行改进,提高了训练速度和识别精度,使得网络对装甲目标识别的平均准确率达到了85%以上,并满足了对特定目标的实时性识别要求。但目前仍然存某些特殊环境下精确识别困难的问题,下一步将采取新的措施对YOLO v2网络进行改进,进一步提高网络的鲁棒性,增强在复杂环境下的识别效果。
猜你喜欢
小学生学习指导(低年级)(2021年9期)2021-10-14 07:57:00
健康之家(2021年19期)2021-05-23 11:17:39
医学食疗与健康(2021年27期)2021-05-13 18:46:23
农业科技与信息(2021年2期)2021-03-27 07:27:38
中学生数理化·七年级数学人教版(2019年10期)2019-11-25 07:34:00
小学生学习指导(低年级)(2019年9期)2019-09-25 07:43:28
小学生学习指导(低年级)(2018年9期)2018-09-26 05:59:46
中国交通信息化(2018年5期)2018-08-21 03:37:40
电子测试(2017年15期)2017-12-18 07:19:27
智能系统学报(2015年4期)2015-12-27 09:38:39
