
基于混合神经网络的问题分类方法
2018-09-17 07:52:02陈柯锦许光銮
计算机与现代化 2018年9期
陈柯锦,许光銮,郭 智,梁 霄
(1.中国科学院大学电子电气与通信工程学院,北京 100049; 2.中国科学院电子学研究所,北京 100190; 3.中国科学院空间信息处理与应用系统技术重点实验室,北京 100190)
0 引 言
随着互联网技术与人工智能的发展,自然语言处理相关领域得到研究者们越来越多的重视。传统的搜索引擎技术采用关键字匹配和浅层语义分析已经无法解决大数据时代的诸多问题,用户亟需一种快速准确的信息获取方式。智能问答技术可对数据进行更有效的组织和管理,借助人工智能相关技术对问题和答案进行深度语义分析,向用户提供更为精确的答案,已经被预见为下一代搜索引擎的核心技术。问答系统主要分为基于Web检索的问答系统、基于社区的问答系统以及基于知识图谱的问答系统。这3种问答系统都包含问题分类、问题分析和答案选择等模块,其中问题分类是问答系统的第一步,其通过对用户期望的答案类型对问题进行分类,对后续获取更为准确的答案至关重要。
本文主要解决基于社区的问答系统中的问题分类问题,其分类的目的是对社区问题进行主题分类,有助于提高答案选择模块的排序准确率。传统的问题分类方法,主要对问题进行表示学习,通过分类模型对问题分类,但是社区问答中大多数问题表现为短文本,其存在信息缺失的问题,传统方法只借助于问题的语义特征很难判别问题类别。如表1所示,对于问题“苹果现在多少钱”,由于“苹果”的多重语义,传统的方法对于此类问题很难准确判断主题类别。除此之外,传统分类方法通常基于词袋模型或浅层语义分析,很难学习到更深层次的语义特征;此外,模型泛化能力也较差。
表1 问题分类示例

问题答案传统方法本文方法苹果现在多少钱现在普通配置的苹果电脑大约13000元左右无法判别电脑
针对上述问题,本文通过学习问题和答案的联合表示特征对问题进行分类,对于表1中的问题,如果引入答案“现在普通配置的苹果电脑大约13000元左右”的信息,不难判断该问题属于电脑类别。除此之外,为了更好地捕捉问题和答案的语义信息,本文采用深度学习模型,提出一种卷积神经网络和循环神经网络结合的混合网络模型,并对模型引入注意力机制,大幅度提高问题分类的准确率。
1 相关工作
问题分类受到了学术界和工业界的广泛关注,相关研究工作主要分为2类:1)基于传统的机器学习方法,其训练速度较快,占用的计算资源较少;2)基于深度学习模型,采用深度学习模型生成问题的分布式表示,从而对问题分类。
1.1 基于机器学习的方法
对于第1类工作,传统的方法主要为贝叶斯、最近邻、决策树和支持向量机[1]等方法。其中,Aikawa等人[2]利用问题的多元特征,采用平滑朴素贝叶斯算法对问题分类;Li等人[3]采用SNoW(The Sparse Network of Winnows)的方法对问题进行分类,取得了较好的效果,但该模型依赖于半监督学习特征。在此之后,Zhang等人[4]采用基于树核的SVM,将问题生成语法结构树的形式,采用树核函数计算2个问题的距离,实验结果表明,基于树核的SVM方法优于贝叶斯等其他4类机器学习分类方法。
1.2 基于深度学习的方法
由于传统的机器学习方法很难学习到问题和答案深层次语义和语法特征,再者,该模型泛化能力较差,很难推广到其他任务上。因此,研究者们尝试将神经网络方法应用到问题分类任务上,并取得了不错的效果。Kim等人[5]首次将卷积神经网络(Convolutional Neural Network, CNN)[6]应用到文本分类,其采用一维CNN提取文本特征,通过全连接层输出文本类别;在此之后,Ma等人[7]采用多层CNN学习不同尺度特征,并提出自编码层学习卷积特征,最后通过Softmax层对问题分类。随着长短期记忆单元(Long Short-Term Memory, LSTM)[8]和注意力机制[9]在自然语言处理诸多任务上广泛应用,相关工作也相继而出。Ding等人[10]采用多层双向长短期记忆单元(Bidirectional LSTM, BiLSTM)[11],挖掘问题语义特征,并在TREC等多个数据集取得了较好的效果;Yang等人[12]采用层级注意力网络,其网络分为词级和句子级2层网络,每层网络由双向循环网络组成,词级网络与句子级网络之间引入注意力机制,最后输出全局特征对问题分类。
第2类方法的主流模型为卷积神经网络和循环神经网络,本文利用2种网络各自的优势,提出一种基于卷积神经网络和循环神经网络的混合模型。除此之外,本文学习问题和答案的联合特征,引入注意力机制,增强问题特征的表示能力,从而提高分类准确率。
2 本文方法

图1 模型总体框架图
图1为本文模型框架,模型底层采用BiLSTM学习问题和答案的浅层语义特征,并将BiLSTM输出的答案特征学习注意力权重,使得注意力权重自动增强或减弱问题特征,从而提升问题特征的表达能力,降低冗余特征的干扰能力。对于BiLSTM提取的特征,本文采用4层卷积网络进一步挖掘语义特征,将问题和答案方向输出的卷积特征聚合得到联合特征,最后通过全连接层和Softmax层对问题分类。
2.1 双向长短期记忆单元
循环神经网络(Recurrent Neural Network, RNN)[13]具备一定记忆能力,其当前时刻的输出由前面时刻的输出决定,能够有效解决序列化问题,但存在梯度消失和梯度爆炸问题。因此为了解决该问题,Hochreiter等人[14]提出长短记忆门单元。
本文采用Graves等人[15]提出的LSTM的改进模型,对于t时刻输入序列xt={x1,x2,…,xn},其隐状态向量ht在t时刻的更新公式如下:
it=σ(Wixt+Uist-1+bi)
(1)
ft=σ(Wfxt+Ufst-1+bf)
(2)
ot=σ(Woxt+Uost-1+bo)
(3)
(4)
ht=ot·tanh (Ct)
(5)
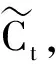
LSTM当前时刻的输出只跟前面时刻的输出有关,无法利用后面时刻提供的语义信息,存在信息丢失的问题。本文实验采用BiLSTM,利用问题和答案上下文信息,即对输入从正反2个方向使用LSTM学习,最后将其聚合,其聚合方法如公式(6)所示。
(6)
2.2 注意力机制
最近几年,注意力机制[9]被广泛应用到计算机视觉、语音信号处理和自然语言处理诸多任务上。注意力模型借鉴人类视觉的选择注意力机制,当人类观察全局图像时,对感兴趣区域投入更多的注意力,获取该区域更多的细节信息,抑制其他冗余信息。本文采用注意力机制,利用答案方向的BiLSTM输出特征学习注意力权重,并将其对问题方向的BiLSTM输出特征选择,从而达到抑制冗余特征的效果。该模型更新公式如下:
ma,q(t)=tanh (Wamhq(t)+Wqmha(T))
(7)
Sa,q(t)∝exp(wmsTma,q(t))
(8)
(9)
其中hq(t)为问题方向BiLSTM的t时刻输出,ha(T)为答案方向BiLSTM最终时刻输出特征,Wam、Wqm和wms为注意力模型超参。
2.3 卷积神经网络
本文利用卷积网络擅长捕捉局部特征信息的能力,将其作为本文模型第2层特征提取层,对问题和答案BiLSTM输出的特征分别采用4层一维CNN提取特征,其卷积核的长度等于BiLSTM隐含层输出维度,其特征提取示意图如图2所示。
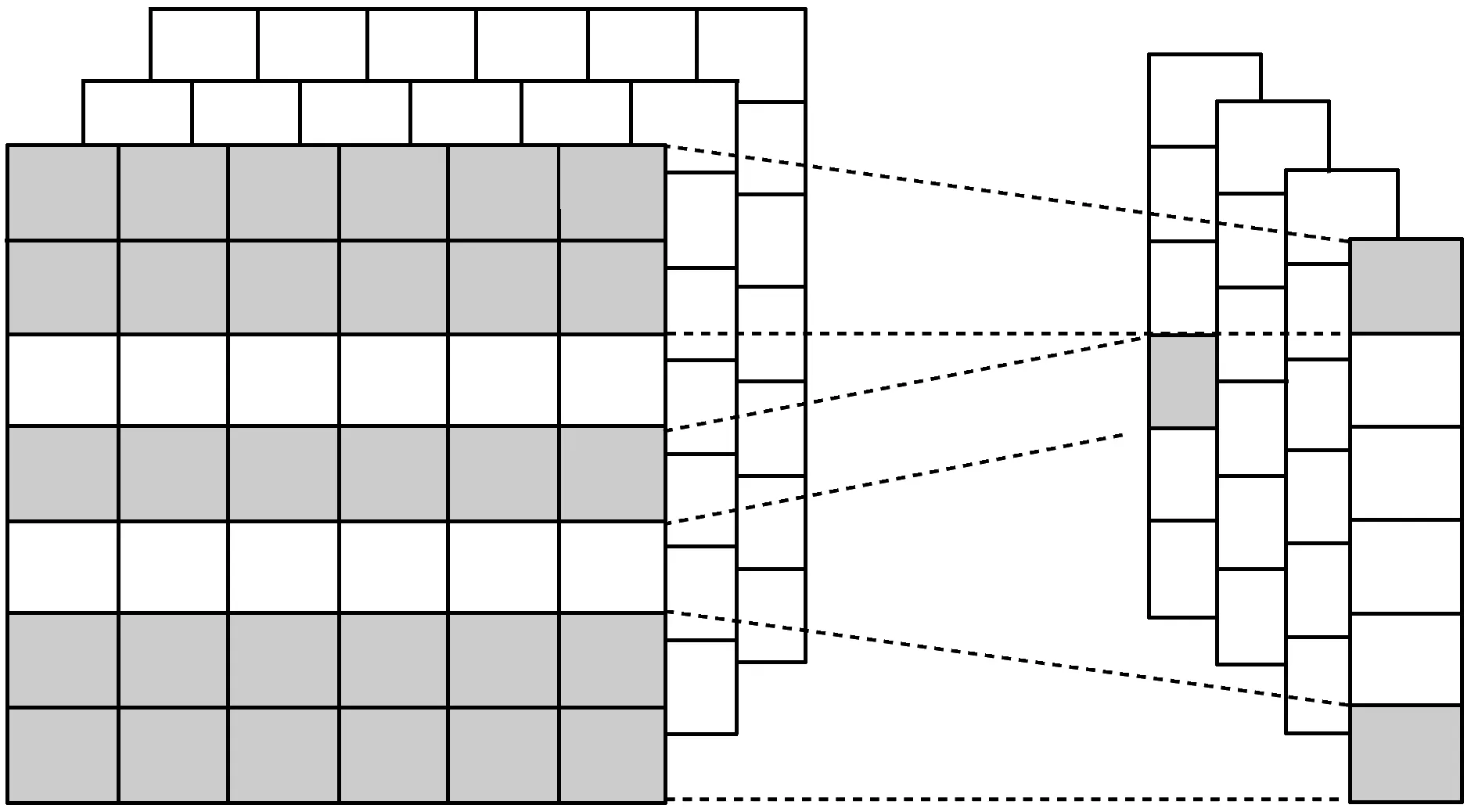
图2 不同窗口大小下卷积神经网络特征提取示意图
图2中左侧是问题或答案BiLSTM层输出的特征矩阵Xn×k,当使用卷积核Wh×k对矩阵Xn×k进行卷积操作可以得到n-h+1个特征,其具体公式如公式(10)所示。
ci=f(Wh×k·Xi:i+k-1+b)
(10)
其中Wh×k表示卷积网络卷积核,h表示窗口大小,k为BiLSTM隐层输出维度。Xi:i+k-1为矩阵Xn×k第i到i+k-1维向量构成的矩阵。b为网络偏置向量,f为激活函数,本次实验中采用tanh,ci为最终提取到的特征。对整个特征矩阵作卷积操作后,得到特征向量f={c1,c2,…,cn-h+1}。类似地,通过设定不同的卷积核大小和滤波器组数,可以得到不同尺度下的特征向量。本文分别对问题和答案BiLSTM层输出的特征矩阵采用4层一维卷积网络分别学习,然后将学习到的特征通过拼接方式聚合成联合特征,最后通过全连接层和Softmax层得到分类类别。
3 实验结果分析
3.1 实验数据和参数设置
本次实验数据集采用张栋等人[16]爬取的360问答数据集,并对其进行整理和清洗,最终得到10000条问答对。数据集主要分为5个主题类别,每个类别包含2000条问题和其对应的正确答案,本文实验按照7∶2∶1的比例将7000条数据作为训练集,2000条数据作为验证集,1000条数据作为实验测试集,其中训练集、验证集和测试集是从5个主题类别等比例抽取,防止出现样本不均衡问题。实验模型为5分类模型,通过模型的Softmax层输出判别问题类别,实验通过分类准确率评价分类效果。
本次实验的实验环境为Tesla K40、 Intel Core i7-6700k 4.0 GHZ、内存32 GB的服务器。本文通过爬取维基百科语料,采用word2vec[17]训练得到问题和答案的词向量,其中词嵌入维度为100维。本次实验网络学习采用随机梯度下降法(Stochastic Gradient Descent, SGD),其初始学习率设置为0.1,网络训练的批大小设置为100,网络迭代次数设置为100,采取早停止(Early-stop)[18]策略。
由于本文样本问题和答案的长度大多处于10~40之间,采用较短的截取长度会造成信息丢失,而采用较长的截取长度会造成较长的训练时间,经过实验验证,本文问题和答案的截取长度设置为30,可以取得较好的实验效果。除此之外,根据词嵌入维度100, BiLSTM隐含层输出维度为141维效果较好,其中dropout[19]设置为0.5。本文卷积层为4个单层CNN,其卷积核长度分别为1、2、3和5,通过设置不同长度的卷积核可以捕捉不同尺度的特征。滤波器组数设置为500,经实验验证,增加滤波器组数并不能提高分类效果,容易造成模型欠拟合。全连接层神经元个数设置为200, Softmax层输出维度为分类总类别数,本次实验设置为5。
3.2 实验结果和分析
为了验证本文方法在问题分类任务上的有效性,本次对比实验设置如下:最大熵模型、最大熵模型+标签传播算法、CNN模型、LSTM模型、BiLSTM模型、CNN+BiLSTM模型和CNN+BiLSTM+attention模型。其中,最大熵模型通过词袋模型对问题和答案表征,采用最大熵模型作为分类器。最大熵模型+标签传播算法则为半监督学习算法,通过标签传播算法标注部分数据来提高模型泛化能力。本文实验结果如表2所示,实验结果表明,本文设计的神经网络方法大多数优于监督和半监督的最大熵模型,分析其原因主要有2点:1)传统的词袋模型忽略了文本的语法和词序特征,其表征能力有限,难以捕捉复杂的上下文语义,而深度学习的词嵌入是基于大规模语料训练的结果,有助于对问题和答案的语义理解;2)深度学习模型通过自动学习文本特征,使得模型具有更好的泛化能力。相比于单一网络,本文提出的混合神经网络模型利用CNN和BiSLTM这2种方法各自的优势可以提取更深的语义和语法特征,其分类准确率相比于单一网络提升了1.6%~5.6%,取得了81.7%的准确率。除此之外,引入注意力机制可以降低冗余特征对实验结果的干扰,增强问题和答案特征的表达能力,相比于不采取注意力机制的混合模型提升了0.5%。
表2 不同问题分类方法性能比较
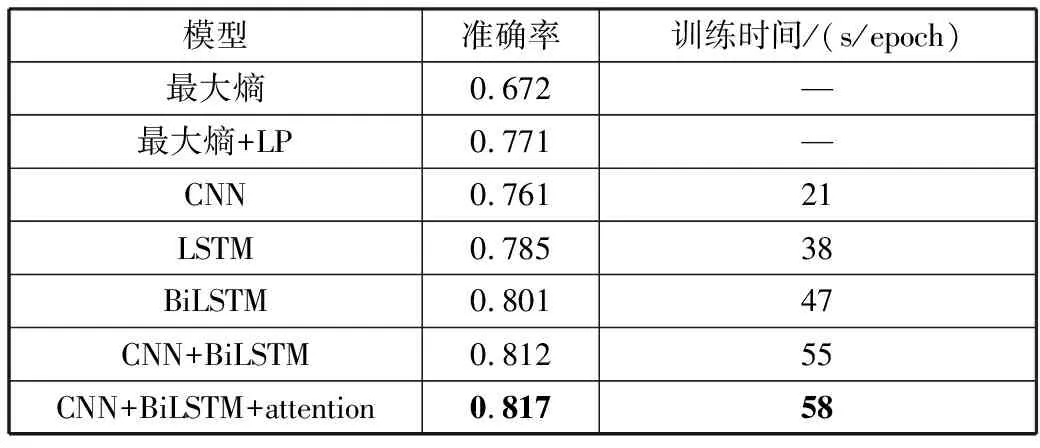
模型准确率训练时间/(s/epoch)最大熵0.672—最大熵+LP0.771—CNN0.76121LSTM0.78538BiLSTM0.80147CNN+BiLSTM0.81255CNN+BiLSTM+attention0.81758
4 结束语
基于问题和答案的联合表示特征,本文提出了一种卷积神经网络和循环神经网络结合的问题分类模型。该模型一方面通过增加答案的语义特征,提升了模型的鲁棒性;另一方面,本文采用混合神经网络模型,利用卷积神经网络和循环神经网络各自的优势,充分挖掘问题和答案的深层语义和语法特征,除此之外,该模型在BiLSTM输出层引入注意力机制,自动选择输出特征,有效抑制冗余特征,提高了模型的泛化能力。本文在360问答数据集上进行了对比实验,实验结果表明,本文模型分类性能明显优于传统神经网络模型。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
开放教育研究(2020年2期)2020-03-31 01:54:14
电子制作(2019年11期)2019-07-04 00:34:38
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
传媒评论(2017年3期)2017-06-13 09:18:10
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
现代语文(2016年21期)2016-05-25 13:13:44
大连民族大学学报(2015年2期)2015-02-27 08:28:11
电视技术(2014年19期)2014-03-11 15:38:20
