
基于卷积神经网络的中文人物关系抽取方法
2018-09-17 07:52:02司文豪贾雷萍戚银城
计算机与现代化 2018年9期
司文豪,贾雷萍,戚银城
(1.中国电建集团华中电力设计研究院有限公司,河南 郑州 450007; 2.华北电力大学电子与通信工程系,河北 保定 071003)
0 引 言
互联网上绝大部分原始数据都是以非结构化的自然语言形式存在,不能很好地被利用。信息抽取是把文本中包含的信息进行结构化处理,变成表格一样的组织形式,以方便进一步的分析、处理和应用[1-2]。人物关系抽取是信息抽取的重要研究内容。从文本数据中识别出人名命名实体及表达二者关系的描述子,最后以〈people, relation, people〉的三元组的形式存入数据库,可以进一步对人物网络行为进行分析或应用到知识问答、商业推荐、广告系统等领域。
基于机器学习的方法进行人物关系提取效果较好,但是需要人工选定特征。而卷积神经网络(Convolutional Neural Network, CNN)能从训练数据中自动学习并提取特征,可以解决人工特征少而不全的缺陷,在自然语言处理领域得到应用。文献[3]提出一种动态卷积神经网络(Dynamic Convolutional Neural Network, DCNN)结构,用其进行句子的语义建模。该模型使用动态池化方式,对一个线性序列做全局池化操作。该模型可以处理不同长度的输入句子,并在能够明确捕捉短期和长期关系的句子上引入特征图。文献[4]针对答案选择问题提出了采用双通道CNN来抽取输入问题和答案之间的相似性与不相似性,整合成最终的句子向量并计算相似性。文献[5]提出对单层CNN进行敏感性分析,以探索模型各个组成部分对模型性能的影响,主要用于区分重要和相对不重要的句子分类设计。
本文将深度学习应用到中文人物关系抽取上,提出一种基于CNN的中文人物关系抽取方法,并将该方法应用到来自互联网上的包含大量人物关系描述的中文短文本数据集上,用分类的方法抽取人物关系,达到较好效果。
1 中文文本挖掘预处理
1.1 文本样本数据的预处理
文本样本数据的预处理包括文本收集、文本清洗、编码处理、文本流的语言学处理和数学处理等过程。利用爬虫系统收集的网络文本是以静态页面代码的形式存在且包含很多无用数据,需要进行清洗、统一编码、分词、词性标注、去除停用词等处理。在分词和标注词性的同时还需要给每个词分配一个权重,代表该词在句子中的重要程度,即文本流的数学处理。本文采用基于条件随机场(Conditional Random Field, CRF)的分词模型[6]完成分词工作。
1.2 基于分布式表示的词向量表达
传统的独热表示(one-hot representation)仅仅将词符号化,不包含任何语义信息。实际上,词的语义由其上下文决定[7-8]。分布式词向量表示是用低维稠密的实向量来表示单词,使得2个语义上相近的词语映射到向量空间后在距离上相近。此外,低维空间的稠密向量用到深度学习模型中也不会有维数灾难问题。
谷歌的开源工具Word2vec用大量标注的语料通过神经网络算法来训练语言模型,获得每个词语的向量表示[9-11]。
本文采用搜狗实验室公开的中文全网新闻语料库来训练Word2vec模型,该语料库包含来自多家新闻站点近20个栏目的分类新闻数据,涵盖军事、教育、财经、旅游、体育、文化等多个领域,中文词条数近4亿。为了验证训练效果,即检验词向量中是否包含了原始词语的语义信息,利用训练好的词向量模型找与“林丹”相近的词语,并通过余弦距离给出相似程度,相似度最高的前10个结果如表1所示。
表1 与“林丹”相似的词语表

序号相近词相似度1陶菲克0.692鲍春来0.653谢杏芳0.614疲于奔命0.605盖德0.596张宁0.587汤杯0.568招架0.559羽坛0.5510败下阵来0.52
将训练好的模型应用到本文预提取人物关系的数据集上,来完成将划分好的词语转化成词向量表达的工作,每一个词向量的维数为50。
GE等提出将气相离散为大量气体微团[19],借助拟颗粒的运动状态来描述气体运动,气体与固体颗粒的相互作用由拟颗粒与固体颗粒的作用来代替;通过模拟气体颗粒与真实固体颗粒之间的碰撞等相互作用,精确把握气固两相流动中的一些宏观现象和微观特性,这种模型称为拟颗粒模型。
2 基于CNN的人物关系抽取方法
2.1 总体方案
本文将经典的CNN模型用于中文人物关系抽取,主要工作包含数据采集、数据预处理和标注,用CNN模型提取特征并分类,总体方案流程如图1所示。

图1 总体方案流程图
设一个句子由n个词组成,每个词都用词向量表示,则该句子可以表示为:
X1:n=X1⊕X2⊕…⊕Xn
(1)
其中Xi∈Rk代表句子中第i个词的词向量,且维数为k,⊕表示拼接操作。通常Xi:i+j表示词语Xi,Xi+1, …, Xi+j的拼接。
设有一个包含h个词语的窗口Xi:i+h-1,滤波器W∈Rhk可以抽取一个特征ci:
ci=f(W⊗Xi:i+h-1+b)
(2)
其中⊗表示卷积操作,b∈R是偏置项,f是激励函数。如果用滤波器遍历句子中所有可能的词语窗口,则可得提取的特征:
C=[c1,c2,…,cn-h+1]
(3)
其中C∈Rn-h+1,即特征图。
本文采用的CNN模型结构[12]如图2所示。
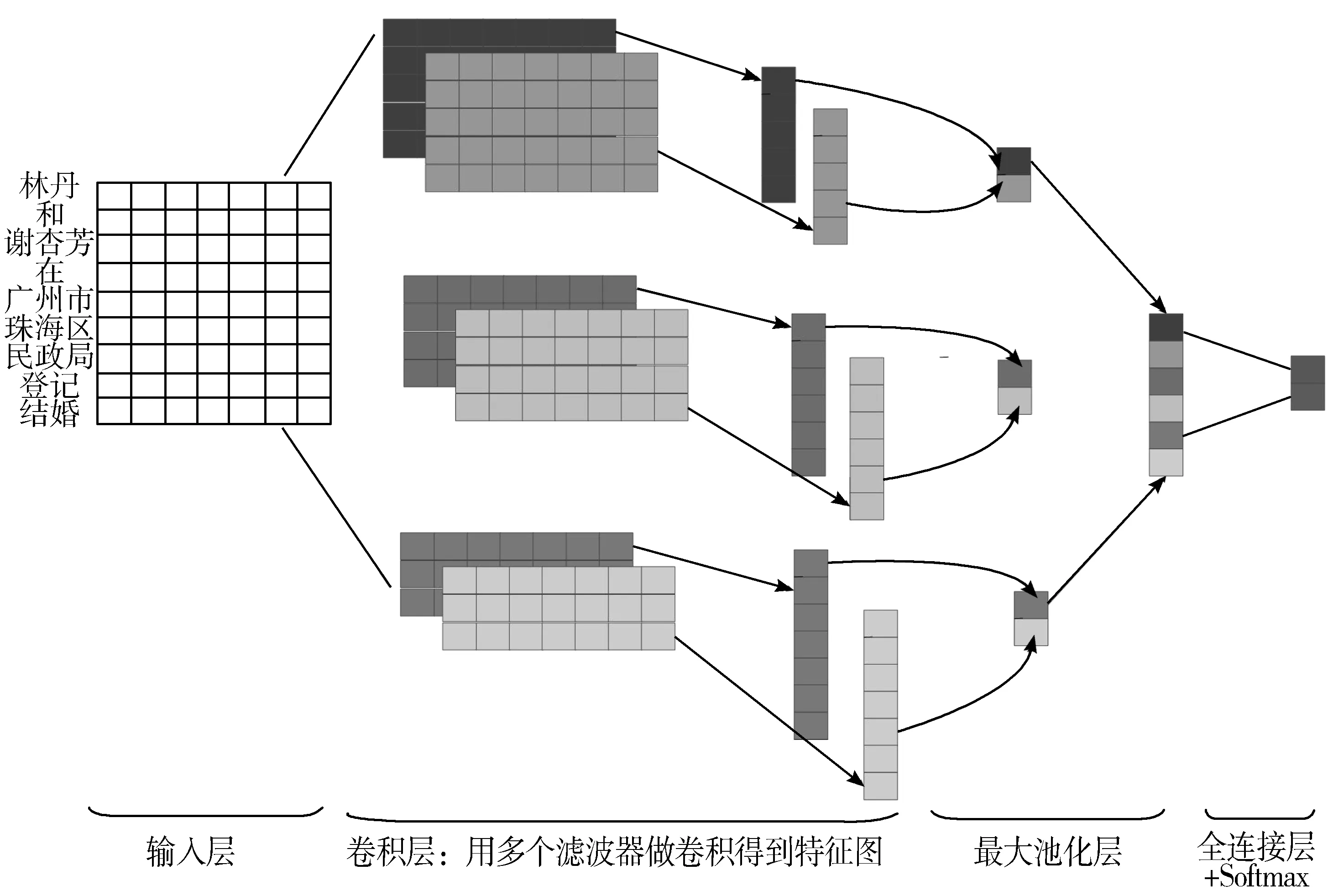
图2 CNN模型结构图
该CNN模型共有4层,具体如下:
1)输入层是n×k的矩阵,该矩阵由句中所有词语的词向量从上而下排列组成,n和k分别表示词语数量和词向量维数。
2)卷积层通过卷积滤波完成特征抽取。滤波器的个数为F,滤波器大小为h×k, h表示句子中词向量的个数。
3)池化层(Pooling)采用k-Max池化且k=1。这种池化方式可以把变长输入X整理成固定长度的输入。
4)全连接+Softmax层。池化层输出的一维向量以全连接的方式,与Softmax分类器相连,输出标签的概率分布。
2.2 训练方案
本文采用随机梯度下降算法(Stochastic Gradient Descent, SGD[13])训练,学习率更新方法采用Adadelta[14],可以对学习率进行自适应调整。在模型的全连接层,采用Dropout[15]策略,即随机选取要休息的神经元。被选中的神经元的权重在本批样本训练中不更新,还保留原来的值,等到下批样本到来时,部分神经元开始工作,另外一批神经元开始休息,防止过拟合的同时也减少了计算量。
由于随机梯度下降算法每次迭代只对一个训练样本计算梯度,直到收敛为止,一旦遇到噪音就会出现局部最优解问题。针对该问题,本文在SGD基础上采用Mini-batch[16]策略,即从所有训练样本中选取m个样本作为一个批次进行迭代,每次迭代也是使用1个样本,最后得到m个梯度,再加权平均并求和作为本批次的下降梯度,直到收敛为止。
3 实验与结果分析
3.1 本文数据集
采用百度百科有“娱乐人物”和“行业人物”标签的人物数据作为待抽取人物关系的数据集。如短文本“2010年12月13日,林丹和谢杏芳的爱情长跑修成正果,两人在广州市海珠区民政局登记结婚。”本文对5种人物关系进行分类,分别为:配偶、分手(包含夫妻离婚,情侣分手2种情况)、情侣、父母子女、兄弟姐妹,每类关系标注了1000条数据。
3.2 实验设计
数据集经过预处理、词向量转化后得到的结果,以[Revs, W, W2, Word_idx_map, Vocab]格式保存在pkl文件“mr.p”中。由于词向量的选取对实验结果有很大影响,其由2个参数决定:输入词矩阵的类型(Static和Non-Static)和词矩阵的初始化。因此本文进行了3种实验,来验证前面得到的词向量对模型性能的影响:
1)CNN-Rand:词矩阵随机初始化,矩阵类型为Non-Static,词向量作为训练过程中可优化的参数在训练过程中进行更新。
2)CNN-Static:词向量在模型训练中固定不变,矩阵类型为Static。
3)CNN-Non-Static:用训练好的词向量初始化词矩阵,词向量作为训练过程中可优化的参数在训练过程中进行更新,矩阵类型为Non-Static。
3.3 实验结果及分析
利用3种模型对本文数据集进行人物关系抽取实验,提取配偶、分手、情侣、父母子女、兄弟姐妹这5类人物关系,实验结果如表2所示。
表2 3种模型的准确率

模型准确率/%CNN-Rand88.91CNN-Static92.67CNN-Non-Static92.87
很显然,用已经训练好的词向量初始化词矩阵得到的准确率要比随机初始化词矩阵的模型准确率高3.76%,表明预训练的词向量确实包含了大量原始句子的语义特征,更容易被模型学习并分类。从词矩阵类型上看,Non-Static比Static在模型准确率上提高了0.2%,说明在CNN模型训练过程中对词向量进行适当调优也是有效果的。
对于准确率最高的模型CNN-Non-Static,进一步统计每类关系下模型分类正确的数量,得出该模型的召回率,见表3。
表3 5种人物关系的召回率
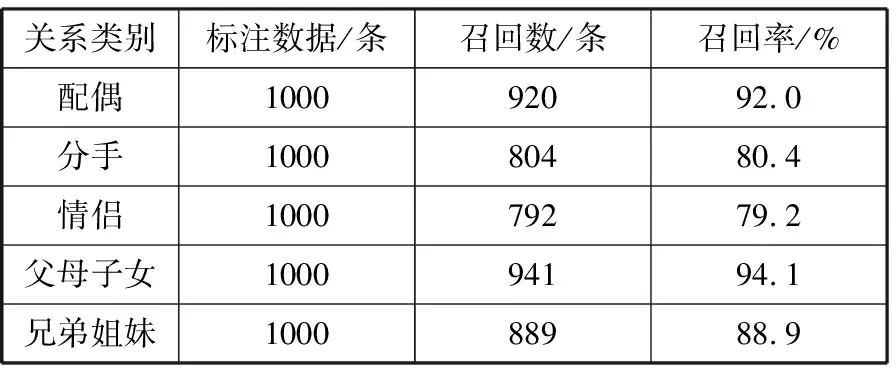
关系类别标注数据/条召回数/条召回率/%配偶100092092.0分手100080480.4情侣100079279.2父母子女100094194.1兄弟姐妹100088988.9
由表3可见,父母子女及配偶关系的召回率最好,情侣及分手的召回率相对较差,5类人物关系上的平均召回率为86.92%。情侣及分手的召回率相对较差的主要原因是情侣和分手这2类关系的原始文本对应的人物有可能与配偶关系对应的人物有重合,而一般描述配偶关系的词语特征比较明显,描述情侣和分手关系的词语特征相对模糊。另外,情侣和分手这2类关系还更多依赖输入语句前后的特征,需要模型具有一定的记忆功能,而本文采用的CNN模型没有记忆功能,因此影响了这2类关系抽取的准确率和召回率。
4 结束语
本文以互联网上大量包含人物关系的中文自然语言文本为研究对象,以抽取其中的人物关系为目的,将人物关系抽取任务转化成文本分类问题,利用卷积神经网络提取词向量特征并对人物关系进行分类。百度百科数据集上的实验结果表明,该方法可以应用到工程中完成对人物关系的抽取任务。
本文在对人物关系分类时,没有考虑人物性别属性和人物关系的位置特征,因此无法识别出父子、母子等更细粒度的关系及谁是父亲,谁是儿子。这需要在词向量表达和构建人物关系抽取模型时做进一步优化。
猜你喜欢
国际医药卫生导报(2022年18期)2022-09-29 01:29:00
新高考·高一数学(2022年3期)2022-04-28 07:02:46
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19 08:28:36
小天使·一年级语数英综合(2020年4期)2020-12-16 02:56:32
作文评点报·低幼版(2016年42期)2017-01-23 11:45:27
中央民族大学学报(自然科学版)(2016年3期)2016-06-27 07:55:32
高中生学习·高三版(2016年9期)2016-05-14 09:12:05
新高考·高二数学(2015年11期)2015-12-23 18:17:44
南都周刊(2015年4期)2015-09-10 07:22:44
南都周刊(2015年3期)2015-09-10 07:22:44
