
一种融合话题和行为的在线问答社区领域专家发现方法
2018-09-17 04:32:12李科霖
计算机与现代化 2018年9期
李科霖
(北京交通大学计算机与信息技术学院,北京 100044)
0 引 言
近年来,由于各类现代技术的迅猛发展,人们对专业知识的需求不断增加,因此常常需要从多种不同的渠道获取自己需要的知识来满足学习或者工作的需求。其中,在线问答社区逐渐成为最为可靠和有效的知识来源之一[1]。
互联网和信息技术的发展,见证了如Wikipedia、Quora和知乎等中英文在线问答社区的蓬勃发展。与传统的专家咨询系统不同,在线问答社区通常是指由用户参与问题提问和回答的知识分享社区,它的基本模式是用户根据自己的知识需求进行提问,通过一定的激励或者推荐机制来发动其他具有相关领域知识的用户回答问题,提供个性化的答案[2]。例如,作为最受欢迎的中文在线问答社区之一,知乎拥有千万级别用户,每天产生大量不同领域下的问题和答案。然而,由于问题回答者的专业水平良莠不齐,产生的答案质量也往往高低不一。因此,准确地发现问答社区中不同领域下具有专业知识水平和影响力的专家用户,把提问者提出的问题及时推荐给这些专家用户,将有助于高效而准确地产生专业答复,从而提高问答社区知识库的知识水平,增加用户对社区的粘度,还能为外部搜索引擎提供较高质量的信息资源。因此,基于用户产生的问答信息和点赞等行为信息,准确地发现在线问答社区中的领域专家用户,就显得尤为必要。
针对在线问答社区领域专家发现问题,本文根据答案的产生过程,提出一种问题-回答者-话题(Question-Answerer-Topic, QAT)模型,用来对问题-回答者对的话题分布进行建模,以此刻画不同用户对领域内不同话题的参与度,并基于此模型融入用户答案的被点赞数目信息以衡量用户在各话题下的专业水平,最后结合链接分析的方法,提出一种主题敏感的PageRank改进模型,进一步衡量用户的权威度,从而得到用户的最终专家得分并进行排序。
本文采用Gibbs采样的方法对QAT模型进行推导和求解,通过不断地采样语料库中每个词的主题指派来近似推断语料库中问题-回答者对、主题和词的联合分布。Gibbs采样收敛后,就可以根据语料库中每个词的采样结果来估计出问题-回答者-话题分布。
本文从中文在线问答社区知乎网上采集了人工智能领域下的真实数据集进行实验,并与现有的专家发现方法进行对比与分析。实验结果表明,相较于现有的专家发现方法,本文提出的方法能有效地识别出领域专家用户。
本文的工作主要包括以下3点:
1)根据答案的产生过程,以及问题和答案之间的关联性,提出了问题-回答者-话题模型,可有效约束问题-回答者对的话题分布,从而更准确地发现回答者的话题分布,刻画其领域话题。
2)基于问题-回答者-话题模型,融入答案点赞信息来计算用户在领域内各话题下的专业水平,并结合链接分析的方法,提出一种主题敏感的PageRank改进模型,有效衡量用户在各话题下的权威度,最终计算出用户在领域内不同话题下的专家得分,并进行排序。
3)从知乎网采集了一个高质量的人工智能领域问答数据集,并对提出的模型进行了充分的实验,验证了本文提出的方法的有效性。
1 相关工作
在线问答社区中的专家发现,是指发现社区中具有较高专业水平和影响力、能提供较多高质量回答、值得信赖的用户[3]。对于在线问答社区的专家发现问题,很多学者提出了不同的模型和方法。目前,在线问答社区的专家发现研究主要分为基于统计分析的方法、基于链接分析的方法和基于信息抽取的方法。
基于统计分析的方法主要使用一些统计特征,如答案的相关性、客观性、真实性、易读性以及问答数目比例关系等,来进行专家排序。例如,Zhang等人[4]提出基于用户提问和回答数目的比例关系的模型,即假定用户提供的答案越多,问题数量越少,则他们的专业知识水平就越高,反之亦然。作者将该模型应用于大型的在线问答社区——Java Forum,取得了良好的效果。Jeon等人[5]为每个答案生成一个特征向量,记录答案的接受率、答案长度、问题的评价、回答者活跃度、回答者专业类别等信息来进行评级排名。Bouguessa[6]等人将用户获得最佳回答者的次数作为计算用户专家权威度的标准来进行专家排序。总体来看,这些基于统计分析的方法很容易被用户恶意作弊所欺骗,并且有些评价指标的得分需要人工手动生成,还有一些指标特征比较难收集,因此分析起来也较为费时。
基于链接分析的方法主要包括基于PageRank[7-9]的方法和基于HITS[10-11]的方法。基于PageRank的方法将PageRank应用于在线问答社区的专家发现,其核心思想是根据问答关系构建社交网络,利用网络迭代传播的思想求解用户专家权威程度得分。一个用户的专家权威程度得分取决于该用户帮助的用户数量,用户得分越多,则其专家权威程度也就越高。HITS的思想与PageRank类似,它将用户分为Hub和Authority这2组,其中Hub组是提问的用户集合,Authority组是回答问题的用户集合。同样,Hub和Authority值可以通过网络迭代求解。如果只考虑用户问答关系网络,而不考虑答案质量,PageRank和HITS在专家发现方法中应用广泛。然而,据统计显示,问答社区中约有1/3的问题存在明显的不足,约有1/10的答案为低质量答案[4]。因此,除了考虑问答关系等链接关系外,还应考虑用户产生内容的质量。
基于信息抽取的方法由于其信息覆盖的全面性和多样性而受到广大学者的青睐。Liu等人[12]将专家用户定义为在给定的问题下,回答过相似问题的用户,然后基于查询相似度模型[13]、关联模型[14]和基于聚类的语言模型[15]检索得到最有可能回答该问题的用户。刘健等人[16]提出了基于LDA话题模型的改进模型,在模型生成过程中抽取专家用户。Yang等人[17]利用LDA模型抽取用户兴趣的话题分布,并结合链接分析的方法提出以人为中心的专家发现方法。
此外,也有不少学者提出混合模型来进行专家发现。Wang等人[1]提出融合候选专家经验、候选专家权威度和PageRank链接分析的方法来进行在线知识社区候选专家排序。Kao等人[18]进一步综合用户知识领域、用户声誉和链接分析来评选专家用户。Yang等人[19]提出基于LDA的改进模型,在模型中融入问题标签和点赞信息,并结合链接分析的方法,来衡量用户的专家水平和兴趣分布。
上述模型虽然取得了不错的效果,但是并没有考虑到问题和回答者产生的答案之间的相互约束关系,即一个用户在回答问题之前,会先根据提问信息选择自己擅长的问题,然后根据问题的描述来产生自己的答案。基于上述答案生成过程,本文提出一种QAT模型,并以此为基础进一步提出一种融合话题和行为的领域专家发现方法。
2 领域专家发现模型
本章首先介绍在线问答社区领域专家发现方法的整体框架,然后详细描述本文提出的问题-回答者-话题(QAT)模型,最后介绍基于QAT模型提出的融合话题和行为的领域专家发现方法。
2.1 整体框架
融合话题和行为的领域专家发现方法的整体框架如图1所示,具体流程为:
1)针对某领域内的问答数据,进行信息抽取和关系抽取。信息抽取主要是抽取出由问题和问题下的回答者组成问题-回答者对qa以及问题-回答者对所对应的答案文本信息,关系抽取主要是根据问答关系构建问答关系网络。
2)利用问题-回答者-话题(QAT)模型,计算问题-回答者对qa的话题分布。
3)在QAT模型中融入点赞信息,计算得到用户在不同话题下的专业度得分。
4)结合基于主题敏感的PageRank改进算法,得到用户在领域内不同话题下的最终专家得分。

图1 融合话题和行为的领域专家发现方法整体框架
2.2 问题-回答者-话题(QAT)模型
本节将详细介绍问题-回答者-话题(QAT)模型,并对模型进行参数估计,表1列出了本文使用的相关符号和含义说明。
表1 相关符号及说明
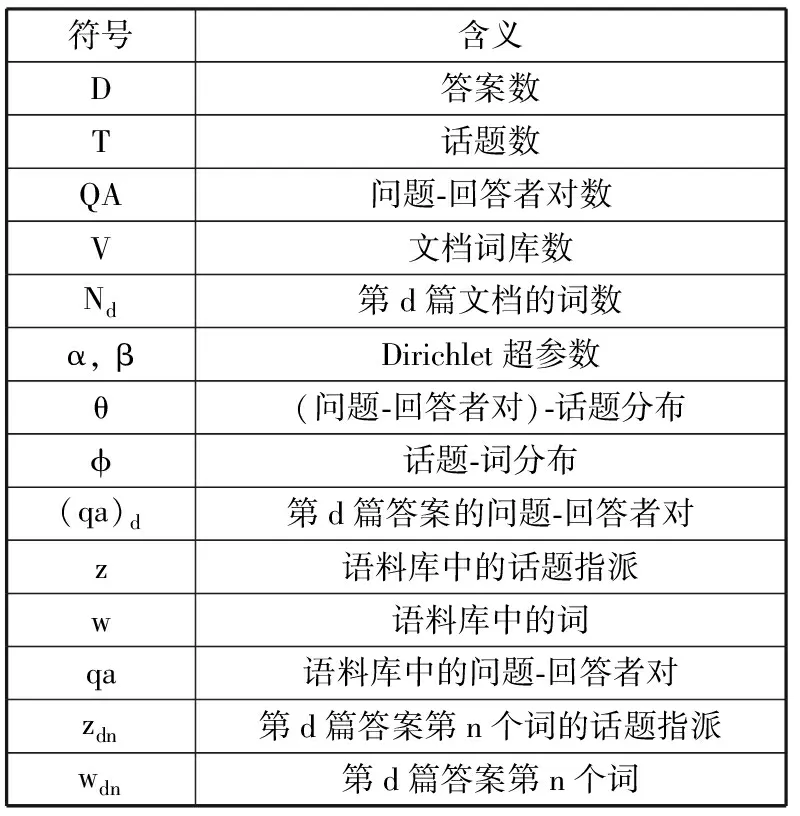
符号含义D答案数T话题数QA问题-回答者对数V文档词库数Nd第d篇文档的词数α, βDirichlet超参数θ(问题-回答者对)-话题分布ϕ话题-词分布(qa)d第d篇答案的问题-回答者对z语料库中的话题指派w语料库中的词qa语料库中的问题-回答者对zdn第d篇答案第n个词的话题指派wdn第d篇答案第n个词
2.2.1 模型描述
在线问答社区中,用户作为提问者在提问问题的时候,常常将自己的知识需求以问题标题加问题描述的形式进行提问,而用户作为回答者在回答问题时,通常会结合自己所具备的相关领域知识和问题标题、问题描述等信息,来产生自己的答案,此时用户所产生的答案通常体现了他们在问题相关领域的话题类别。即问题和回答者共同决定了生成答案的话题分布。基于此,本文以LDA模型为基础,同时加入问题和回答者信息,提出一种问题-回答者-话题(QAT)模型。
QAT模型的直观含义是:问题和回答者共同决定了回答者在每个问题下生成的答案的话题分布,而答案的话题决定了词的生成。与LDA模型类似,QAT模型仍然是层次式的贝叶斯概率模型,它包含词、话题、文档、问题-回答者对这4层结构,其概率图模型如图2所示。
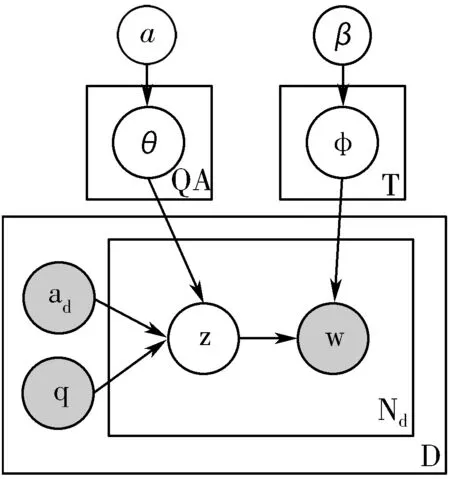
图2 QAT模型盘式表示
在QAT模型中,每篇答案d对应一个问题q和回答者a组成的问题-回答者对qa。每个qa对应的话题的多项式分布为θqa,每个话题对应词的多项式分布为φt。该模型的形式化描述详见算法1:首先,根据Dirichlet超参数分布分别采样问题-回答者对-话题分布θ、话题-词分布φ,其分别服从Dirichlet分布Dir(α)、Dir(β);然后,对于每篇答案中的每个词,根据答案对应问题-回答者对的话题分布θ采样生成一个话题z,z服从多项式分布Mul(θ);最后,基于生成的话题z独立地从话题-词分布φ中采样生成一个词w,w服从多项式分布Mul(φ)。
算法1QAT模型的生成过程
输入:α、β、D、T、QA
输出:答案文本
for每个问题-回答者对qa∈QA do
根据超参数α采样问题-回答者对的话题分布θqa~Dir(α);
end for
for每个话题z∈T do
根据超参数β采样话题的词分布φz~Dir(β);
end for
for每篇答案d∈[1,D]以及答案对应的问题-回答者对qa do
for每个词n∈[1,Nd] do
根据θqa采样一个话题zdn~Mul(θqa);
根据φzdn采样一个词wdn~Mul(φzdn);
end for
end for
给定超参数α、β以及答案d对应的问题-回答者对qa,语料库的生成概率如公式(1)所示。
P(θ,φ,z,w|α,β,qa)
(1)
2.2.2 参数估计
Gibbs采样是Markov链Monte Carlo理论(MCMC)中用来获取一系列近似等于指定多维概率分布观察样本的算法,它通过迭代采样来对高维复杂的概率分布进行推导。本文采用Gibbs采样算法来近似推导QAT模型。为了得到参数θ、φ,需要计算词wdn的话题指派的条件分布p(zdn|z,qa,w,α,β),其中,z指答案d中除第n个词外的其它所有词的话题指派。
为了简化公式描述,引入Δ函数来统一表示隐变量θ、φ,含有M维Dirichlet均匀先验δ的Δ函数被定义为如公式(2)所示:
ΔM(δ)=Γ(δM)/Γ(Mδ)
(2)
其中Γ(·)是伽马函数。
基于图2所示概率图模型定义的条件独立性假设,给定所有超参数,则话题、问题-回答者对、词的联合分布可以形式化为公式(3)所示:
P(z,w|α,β)=P(z|α)P(w|z,β)
(3)
P(zdn|z,qa,w,α,β)
(4)
Gibbs采样收敛后,就可以根据采样结果估计问题-回答者对-话题分布θ与话题-词分布φ,分别如公式(5)和公式(6)所示。
(5)
(6)
2.3 融入点赞信息计算用户的专业水平
问答社区中的点赞信息作为社区中浏览者对答案质量的一种反馈行为,直接反映了回答者在每个问题下的专业水平,一个具备较高专业水平的回答者所产生的答案往往会收获更多的点赞数。因此,本文考虑融入用户在每个问题下的答案点赞信息来更加准确地衡量用户的专业水平。
利用回答者在每个问题下产生答案所收获的点赞数目信息计算用户在该问题下的答案质量权重,计算公式如公式(7)所示。
(7)
其中v(q,a)表示回答者a在问题q下的答案质量权重,Nq表示问题q下所有答案的数目,na表示回答者a在问题q下的答案所获点赞数。
然后将回答者在每个问题下的答案质量权重除以该用户所有答案的质量权重总和作为加权因子,对公式(5)得到的每个问题-回答者对qa的话题分布θ(qa)z进行加权求和,得到回答者在不同话题下的专业水平得分,其定义如公式(8)所示。
(8)
其中EX(ui,z)表示用户ui在话题z下的专业水平,Qi表示用户ui回答问题总数,θ(jui)z表示QAT模型推断出的问题j和回答者ui所组成的问题-回答者对jui在话题z下分布的概率。
2.4 用户问答关系网络
QAT模型是对问题-回答者信息和文本信息进行建模的多隐变量模型,可以根据用户的话题分布用来发现用户的领域专长,并融入答案的点赞信息来计算用户在领域内话题下的专业程度。然而,用户关系网络结构对于领域话题下专家专业水平和权威度的度量同样重要。为了得到用户的网络权威度,本文构建问答关系网络来计算其在网络中的重要度。
在问答社区中,用户i提出问题q,用户j对此问题进行回答,则用户i和用户j通过提问-回答的交互产生链接关系。用户之间问答交互的链接关系可以表示为图3所示,用户1提出问题1,用户2和用户3回答问题1。通过这种问答交互抽取用户之间关系,转化为用户1分别指向用户2和用户3的有向边,如图4所示。按照这种方法,构建用户问答关系网络。
用户问答关系网络图可以形式化为:G=(V,E),其中V={ui}表示领域内所有用户的集合,E={(eij,wij)}表示领域内所有有向边集合,eij为一条边,表示用户j回答了用户i提出的问题,wij为边eij的权重,表示用户j回答用户i所有问题的数目。
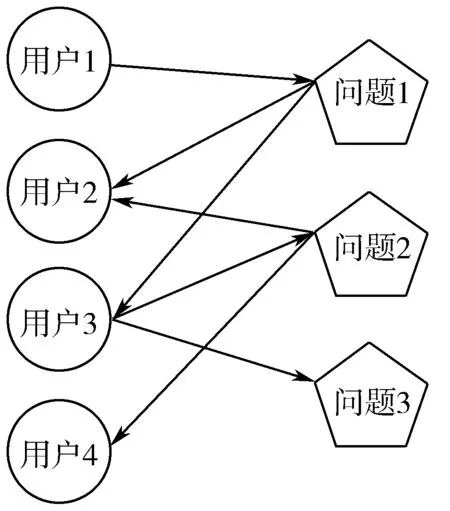
图3 用户-问题关系网络图
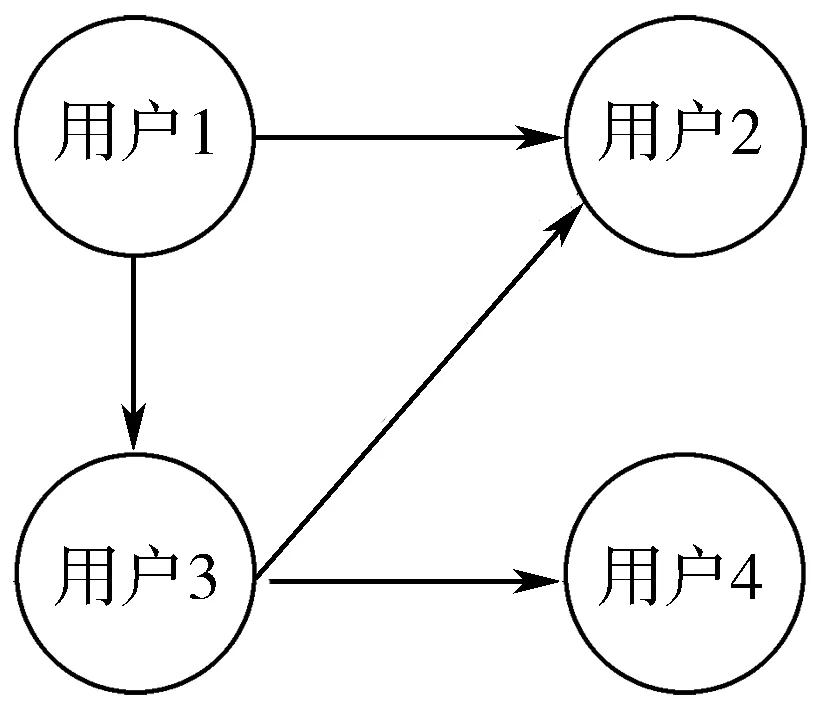
图4 问答关系网络图
2.5 融合链接分析计算用户最终专家得分
根据已经建立好的用户问答关系网络,可以利用随机游走的方法,求得网络中每个节点访问概率的平稳分布。在最初利用PageRank算法进行专家发现时,远程跳转时随机跳向每个节点的概率都是相同的。后来Zhou等人[9]根据话题下用户的相似度设置随机游走跳转概率,提出基于主题敏感PageRank算法的改进模型。
考虑到在随机跳转时,往往会倾向于跳转到专业水平较高的用户节点。因此,与传统的主题敏感的PageRank算法不同,本文将公式(8)计算得到的融合点赞信息的用户话题专业水平值作为随机跳转值,提出一种融合用户话题专业水平的主题敏感PageRank算法,求解给定话题z下,用户的最终专家得分,其定义如公式(9)所示。
PR(ui,z)=(1-d)EX(ui,z)+
(9)
其中PR(ui,z)表示用户ui在话题z下最终的专家得分,U(ui)为指向用户ui的所有用户的集合,N为用户uj所指向用户的集合。对于只参与提问而未回答过问题的用户ui,本文认为其专业水平较低,从而将其EX(ui,z)值设置为0。
3 实验结果与分析
本章将基于知乎网人工智能领域的真实问答数据集对提出的方法进行实验验证分析。
3.1 实验数据
本文采用的数据来自中文在线问答社区知乎网,采集了知乎网人工智能领域下的4396个精华问题及其相关信息。每个问题的信息包括:
1)文本信息:问题标题、问题描述以及问题下的所有答案。
2)用户信息:问题提问者和回答者的用户ID。
3)行为信息:每条答案的被点赞数目。
首先对采集的数据进行必要的预处理,包括去除字数答案中少于150字的短文本信息与对应回答者,去除文本中的代码块、HTML标记和URL链接,然后采用NLPIR分词工具进行分词,在分词的过程中去除停用词和低频词,利用TF-IDF方法计算低权重词并去除,最终得到处理后的数据集统计信息如表2所示。
表2 数据集统计信息
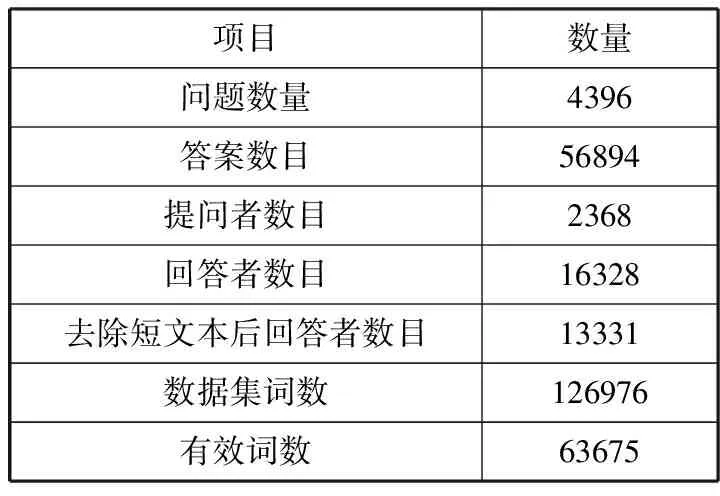
项目数量问题数量4396答案数目56894提问者数目2368回答者数目16328去除短文本后回答者数目13331数据集词数126976有效词数63675
除此之外,知乎网也给出了人工智能领域下的话题划分,包含自然语言处理、图像识别等共20个话题,在划分的每个话题下,知乎网列出了该话题下推选出的优秀回答者列表。将这些知乎网划分的话题根据关键字与本文方法所得到的话题做一一映射,并采集各个话题下优秀回答者列表中的用户ID,用本文提出的方法所得到的各个话题下的专家用户和采集到的知乎网推选出的各话题下专家用户做对比,分析验证实验结果。
3.2 评价指标
为了定量评价本文提出的方法在领域专家发现方面的性能,将得到的话题与采集到的已有话题进行映射,然后将映射后各个话题下的专家用户与知乎网各个话题下推荐的专家求交集,具体地选出每个话题下得到的前10、20、50、100个用户,计算每个话题下的命中率,最终通过计算所有话题下的平均命中率,作为实验的评价指标。
3.3 对比方法
为了对实验结果进行对比评价,选取目前已有的效果较好的专家发现方法作为对比,对比方法包括:
1)PageRank。该方法由于只使用链接分析的方法进行专家排序,并未包含隐话题,因此,在使用其作为基准方法时,本文用它发现的人工智能领域下所有专家用户分别与采集到的各个话题下的专家用户做对比,然后计算平均准确率。
2)HITS。该方法与PageRank方法类似,也未包含隐话题。同样,在使用此方法作为基准方法时,本文用该方法发现的人工智能领域下所有专家用户分别与采集到的各个话题下的专家用户做对比,然后计算平均准确率。
3)InDegree(ID)。该方法[6]通过计算用户在回答问题时获得问题最佳回答者的次数来作为评判标准识别专家用户。在实验中,将每个问题下获赞最多的用户标记为问题的最佳回答者。与PageRank类似,由于该方法不会产生隐话题分布,本文将该方法识别出的专家用户分别与采集到的各个话题下的专家用户做对比,然后计算平均准确率。
4)TSPR。这是Zhou等人[9]提出的综合话题模型和链接分析方法的混合模型。其中,话题模型为LDA的改进模型——用户话题模型(User-Topic Model),该模型将每位用户产生的问题和答案综合起来当成一篇文档,并假设每位用户决定了其文档话题的生成,而话题决定了词的生成。模型利用所有用户产生的文档集合对每位用户的话题分布进行建模,求解得到每位用户的话题分布,其概率图模型如图5所示。图中D表示所有用户产生的文档集合,Nd表示用户u所产生文档的词数。该模型的生成过程是首先根据用户u的话题分布θ随机采样生成一个话题z,z服从多项式分布Mul(θ);然后基于生成的话题z,从话题-词分布φ中采样生成一个词w,w服从多项式分布Mul(φ)。重复上述生成过程直到文档中所有词均已生成。与QAT模型求解问题-回答者对的话题分布不同,用户话题模型以用户为中心求解每个用户的话题分布。在结合链接分析时,TSPR将用户之间的话题相似度作为影响链接跳转的因子,并分别计算用户在每个话题下的专家水平,最后对各个话题下的用户进行排序。
5)QAT-VOTE。本文提出的结合QAT和点赞行为信息计算用户专家专业水平得分的方法。
6)QAT-VOTE-LA。本文提出的结合QAT和点赞行为信息计算专家用户专业水平得分,并融合链接分析计算用户最终综合专家得分的方法。

图5 TSPR中用户话题模型盘式表示
3.4 参数设置
在实验中,本文对各种方法需要的实验参数进行相同的设置。对于话题数目,为了和知乎网已有话题数目统一,设置话题数目T=20。对于Dirichlet超参数,根据文献[20],将其设置为固定值:α=50/T、β=0.05。在模型训练的过程中,发现在迭代次数达到1500次时基本达到收敛,因此本文将迭代次数设置为2000。对于参数d,将其设置为0.85。
3.5 实验结果
3.5.1 QAT模型话题聚集结果
在QAT模型迭代收敛后,通过公式(6)计算得到每个话题下的词分布。通过人工分析每个话题下的词义,将QAT模型产生的20个话题和已有知乎网人工智能领域中的话题做映射,并从20个话题中随机选择10个话题,列举出每个话题下的前10个话题词,如表3所示。可以发现,QAT模型聚集出来的话题之间区别较为明显,而且每个话题的语义也较为容易理解,每个话题在语义上都与话题有较强的相关性。
表3 QAT话题模型话题聚集效果
3.5.2 领域专家发现结果
将本文提出的QAT-VOTE和QAT-VOTE-LA这2种方法,与4种常用的专家发现方法进行对比,实验结果如表4所示。
表4 各种方法的专家发现命中率结果对比
从表4中可以看出,PageRank算法的结果要好于HITS,这是因为HITS算法中有权威度(Authority)和中心度(Hub)2个指标。权威度体现了用户作为回答者时的重要性,而中心度体现了用户作为提问者时的重要性。这2个指标是相互关联耦合的,所以一些提问较多的用户会影响作为回答者时的权威度。
InDegree算法的结果比所有方法的结果都要低,这是因为InDegree仅根据用户在回答的问题中获得最佳回答者的数量来进行专家排序,而没有考虑更多例如用户话题分布情况、用户链接关系情况等情形。
TSPR方法的结果优于PageRank、HITS、InDegree和QAT-VOTE方法。这是因为PageRank和HITS算法仅考虑用户之间的链接关系,InDegree仅考虑用户作为最佳回答者的数量信息。QAT-VOTE方法虽然考虑了结合话题模型和点赞信息,但是并没有融合链接分析的方法。而TSPR方法既使用LDA改进模型对每个作者的话题分布进行建模,又使用主题敏感PageRank改进模型进行用户专家得分计算。这也在一定程度上说明了话题模型和链接分析相结合的方法,在在线问答社区专家发现研究中倾向于取得更好的结果。
本文提出的QAT-VOTE-LA方法,结果明显好于前面几种方法。这是因为TSPR在使用话题模型时,仅从用户产生内容的角度,对每位用户的话题分布进行建模,而未考虑用户在回答问题时,问题本身也会对用户所产生答案的话题分布产生约束。与TSPR不同,本文提出的QAT模型对问题和回答者组成的问题-回答者对的话题分布进行建模,从而对话题有着更好的聚集效果。此外,QAT-VOTE-LA也引入了每个答案的获赞数据计算用户在每个话题下的专业水平,因此,在衡量用户在各个话题下的专业水平时有着更好的效果。综合起来,其实验结果相较TSPR有明显的提升。
4 结束语
本文首先根据在线问答社区中答案的产生过程,提出了问题-回答者-话题(QAT)模型,对某一领域中问题-回答者对的话题分布进行建模;然后在该模型的基础上,融入每条答案的点赞信息,计算用户在领域不同话题分布下的专业水平;最后结合链接分析的方法,提出一种基于主题敏感PageRank方法的改进模型,来进行领域专家发现。与传统的问答社区专家发现方法相比,本文提出的方法不仅考虑了问题-回答者之间话题分布的约束关系,还将每个答案的点赞信息作为用户专业水平的评判因素之一,而且还结合了链接分析的方法,因而可以有效地发现在线问答社区中的领域专家用户。本文提出的方法可以用于在线问答社区问题推荐和专家推荐等具体的应用场景,并以此提高在线问答社区的用户粘性。
本文提出的方法也有一定的不足之处。例如,用户的专业水平和链接关系往往会随着时间的变化而变化,本文并未将时序因素考虑在内,这是一个有待于继续研究的问题。
猜你喜欢
计算机应用(2022年2期)2022-03-01 12:35:06
幼儿园(2021年6期)2021-07-28 07:42:08
小学科学(学生版)(2020年3期)2020-03-25 13:31:22
中国诗歌(2019年6期)2019-11-15 00:26:47
当代陕西(2019年16期)2019-09-25 07:28:38
中国信息技术教育(2016年14期)2016-09-10 07:22:44
宠物世界·猫迷(2016年3期)2016-04-23 19:54:06
少儿科学周刊·少年版(2015年3期)2015-07-07 21:10:04
中学生天地·高中学习版(2013年8期)2013-04-29 13:56:52
传媒国际评论(2013年1期)2013-03-11 15:11:52
