
考虑随机观测误差影响的改进集对分析模型在水质模糊评价中的应用*
2018-09-11 01:42舒持恺候星甫王建金
中国科学院大学学报 2018年5期
舒持恺,候星甫,王建金,杨 侃†
(1 河海大学 水文水资源学院, 南京 210098; 2 河海大学 理学院, 南京 210098) (2017年5月10日收稿; 2017年9月26日收修改稿)
一直以来,水环境问题是全球的研究热点,水质评价是水环境评价的重要内容。当前水质评价方法众多,一般可分为确定性与不确定性两类[1]。其中确定性方法以综合指数法为主,虽然存在许多不足,但由于其计算简便、易于操作,仍然得到广泛应用。近年来,随着人们对模糊评价的深入研究,水质评价的不确定方法逐渐兴起,如人工神经网络[2]、灰色理论法[3]、投影寻踪法[4]等。这些方法使得对水质评价中存在的不确定信息处理更加全面合理,相比确定性方法,是很大的进步。但不确定性方法也有各自的不足之处,如人工神经网络法中存在参数率定较难、收敛速度慢、易陷入局部极小等缺点[1];灰色理论法存在评价值趋于均化,分辨率不高等缺点[5];投影寻踪法存在优化投影方向问题,实现全局最优困难。相应理论还在摸索研究中[1]。
水环境系统是一个不断演化、相互作用的大系统,有其复杂性与不确定性,在水质评价工作中应给予重视。水质评价过程就是将确定性的评价标准与不确定性的监测样本相结合进行比较分析的过程[6],如果仅依赖评价标准,而忽略其不确定性,得到结果不一定合理。如对于指标总氮,Ⅰ级标准为0.2 mg/L,若实测值为0.19 mg/L,则评价等级应为Ⅰ,若实测值为0.21 mg/L,则评价等级应为Ⅱ,这显然是不合理的,忽略了观测过程中存在的随机误差[7],以及各个评价等级之间相互联系的事实。因此,在水质评价过程中需要考虑到随机观测误差的影响,同时针对各个评价等级之间相互联系的事实,引入集对分析理论。
集对分析理论是中国学者赵克勤于1989年首次提出[8],该理论认为事物之间存在同、异、反三种联系,将事物之间进行巧妙的辩证统一分析,其包含随机、模糊、灰色等不确定性理论思想,对于水质评价过程中的不确定信息是一种很好的处理方法。但水质分类比较细化,评价等级可分为“Ⅰ、Ⅱ、Ⅲ、Ⅳ、Ⅴ、劣Ⅴ”,即存在着“好、稍好、一般、较差、差、很差”的概念区别,而集对分析中的同、异、反联系概念则比较泛化,对于水质评价结果区分不够理想。因此有必要对其进行细致刻画,构建改进集对分析模型,使其能够更好地适应水质评价问题中的复杂性与不确定性[1,9]。
1 改进集对分析模型
1.1 集对分析基本理论
集对分析理论[8]认为两个事物存在同、异、反三种联系,可以很好地描述和处理事物之间存在的不确定信息。集对分析在对问题研究过程中先构建一个集对S=(E,F),对集对S的特性进行展开分析,共得到M个特性,其中A个特性为集合E与集合F共同具有的,C个特性为集合E与集合F相互对立的,剩下的B=M-A-C个特性为集合E与集合F既不共同具有也不相互对立,则有
式中:μ为综合联系度;a、b、c为联系度分量,分别为同一度、差异度和对立度,并且满足归一化条件;i为差异度的系数,规定取值在[-1,1];j为对立度的系数,规定值为-1,需要说明的是同一度系数为1。
1.2 改进集对分析理论
针对同异反联系度细致刻画问题,主要就是对差异度与对立度进行精确划分,使之能够适应水质分类要求[1,9]。在水质评价问题背景下,对于m个水质样本、n个指标,每个指标分为p个等级,

(3)
式中:Xij表示第i个水质监测样本的第j个评价指标实测值;Skj为第j个评价指标第k等级的标准值,1≤k≤p。传统集对分析中若Xij处于评价标准Skj中,则认为是同一;若Xij处于评价标准Skj相邻级别中,则认为是差异;若Xij处于评价标准Skj相隔级别中,则认为是对立。这样对于水质多级别判断会产生障碍,如当指标实测值处于标准Ⅲ,对于标准Ⅱ与Ⅳ都被认为是差异,对于标准Ⅰ和Ⅴ都被认为是对立,而无法区分优劣。针对于此,对集对分析中差异度与对立度作出改进。当Xij处于评价标准Skj相邻级别中,进一步考虑Xij是在其优越级别中还是劣差级别中:若在其优越一边,则将这种差异认为是优异,记为b1,若在其劣差一边,则将这种差异认为是劣异,记为b2。同样,当Xij处于评价标准Skj相隔级别中:若是优越的一边,则认为这种对立是优反,记为c1;若是劣差的一边,则认为这种对立是劣反,记为c2。则式(1)可写为
μ= a+bi+cj=a+(b1+b2)i+(c1+c2)j
=a+b1i++b2i-+c1j++c2j-,
(4)
式中:a+b1+b2+c1+c2=1,-1≤i-≤0,0≤i+≤1,j+={0,1},j-=-1。
采用距离贴近度计算联系度分量a、b1、b2、c1、c2。若指标实测值处于评价级别标准中,则a=1,b1、b2、c1、c2=0。若指标实测值处于评价级别标准之外,则a<1,并且越远离该等级标准,a越小,若是处于相邻等级且往等级优越一边远离,则b1越大,b2、c1、c2=0,若是处于相邻等级且往等级劣差一边远离,则b2越大,b1、c1、c2=0;若是处于相隔等级且往等级优越一边远离,则b1越小、c1越大,b2、c2=0,若是处于相隔等级且往等级劣差一边远离,则b2越小、c2越大,b1、c1=0。则改进的集对分析模型各等级联系度按下式计算:

(6)
其中联系度μ1、μ2、μ3、μ4、μ5、μ6分别对应于水质等级Ⅰ类、Ⅱ类、Ⅲ类、Ⅳ类、Ⅴ类、劣Ⅴ类。
1.3 指标权重计算
水环境质量往往受到多个因子的共同影响,在水质评价过程中每个指标因子都或多或少影响着评价结果,因此要慎重考虑各因子对评级结果的贡献[10]。为客观评价水质状况,先采用熵值法计算客观权重,反映数据本身效用值,同时还要考虑超标因子对水质状况的影响,用超标倍数法反映超标因子的作用。在构建组合赋权,将两种权重方法结合,这样既能兼顾监测数据本身的效用值,又能突出超标因素的影响。此外,水质监测是一个随机观测过程,文献[7]运用最大熵原理与蒙特卡罗法证明水环境评价过程中随机观测误差影响的重要性。因此有必要考虑随机观测误差影响,对组合权重结果加以修正。
1.3.1 熵值法
1) 将水质监测数据xij标准化,
2) 计算第j项指标下,第i个样本数据的比重yij,
3) 计算第j项指标的权重
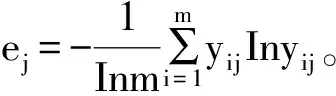
1.3.2 超标倍数法
计算第j项指标权重
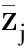
1.3.3 组合赋权法
由熵值法计算得到权重向量为ω1,超标倍数法计算得到权重向量为ω2,构建组合赋权ω:
ω=ηω1+λω2,
(13)
η+λ=1.
(14)
式中η、λ为两种权重方法的分配系数。
考虑两种权重方法计算的权重差异,按下式计算距离函数d(ω1,ω2):
其中ω1k、ω2k分别为权重向量ω1、ω2中第k个指标的权重值。
为平衡两种权重方法的差异,设定组合权重分配系数差异与两种权重方法计算差异保持一致[11],可使
计算得到S1=71 m;S2=26 m,S3=68 m。边坡段落为K1+160—K1+310,其走向长度为150 m,综合计算的到该边坡滑动影响土地面积为37 234 m2,合计3.73 hm2,当地每亩征地费用为13.175万元,计算得到土地资源价值为737.8万元。
(η-λ)2=d2(ω1,ω2),
(16)
结合式(14),可以解得η、λ,代入式(13)即得组合权重向量ω。
1.3.4 随机观测误差权重的影响
随机观测误差影响在评价过程中不容忽视,有时甚至可能改变评价结果。考虑随机观测误差影响的权重计算按下述步骤进行[7]:
1) 计算各指标数据的均值与方差;
2) 将各指标均值与方差相除,然后与组合权重对应相乘,再进行归一化处理,即得考虑了随机观测误差影响的权重结果。
1.4 水质监测数据的优化
水质监测的原始数据复杂而冗余,有必要对数据进行筛选与剔除。为使指标数据在现有评价标准下具有良好的分化效果,引入差异系数β来刻画一组数据在空间上的相对波动程度[12],计算公式为
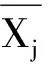
此外,在上述步骤之后,还要考虑数据之间的相关性,利用皮尔逊相关系数分析数据两两之间的相关程度,剔除相关性较大的指标。
2 应用实例
将模型应用于宜兴市地表水功能区评价,选取10个水功能区监测断面(见表1)2015年水质监测数据作为评价样本,监测断面位置见图1。宜兴市地表水功能区水质监测数据共包含17项指标,按式(17)计算各指标数据差异系数β,并以β≥0.4为标准,当指标β<0.4认为分辨性差,对评价体系层次划分起到的分类效果不明显,剔除该指标。经计算,剔除5项,保留12项。再对剩下的12项指标进行相关性检验,结果见表2。

表1 宜兴市地表水功能区水质监测项目
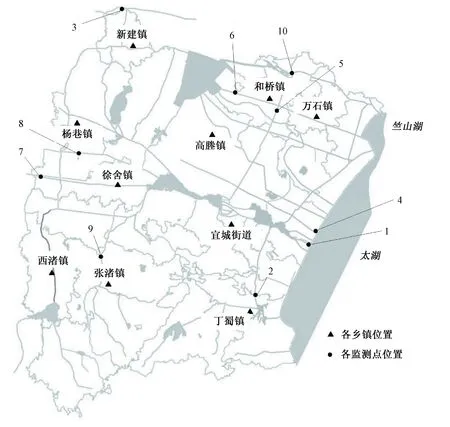
图1 宜兴市地表水功能区水质监测断面位置图Fig.1 Locations of Yixing ground water functional zone water quality monitoring sections
可以看出氨氮与总氮相关性系数高达0.84,并通过显著性水平为0.01的检验,因此剔除指标总氮。以剩下11个指标建立水质评价体系,评价等级标准见表3。
以城东港宜兴缓冲区陈东桥监测断面为例,按式(5)~式(10)计算其联系度矩阵
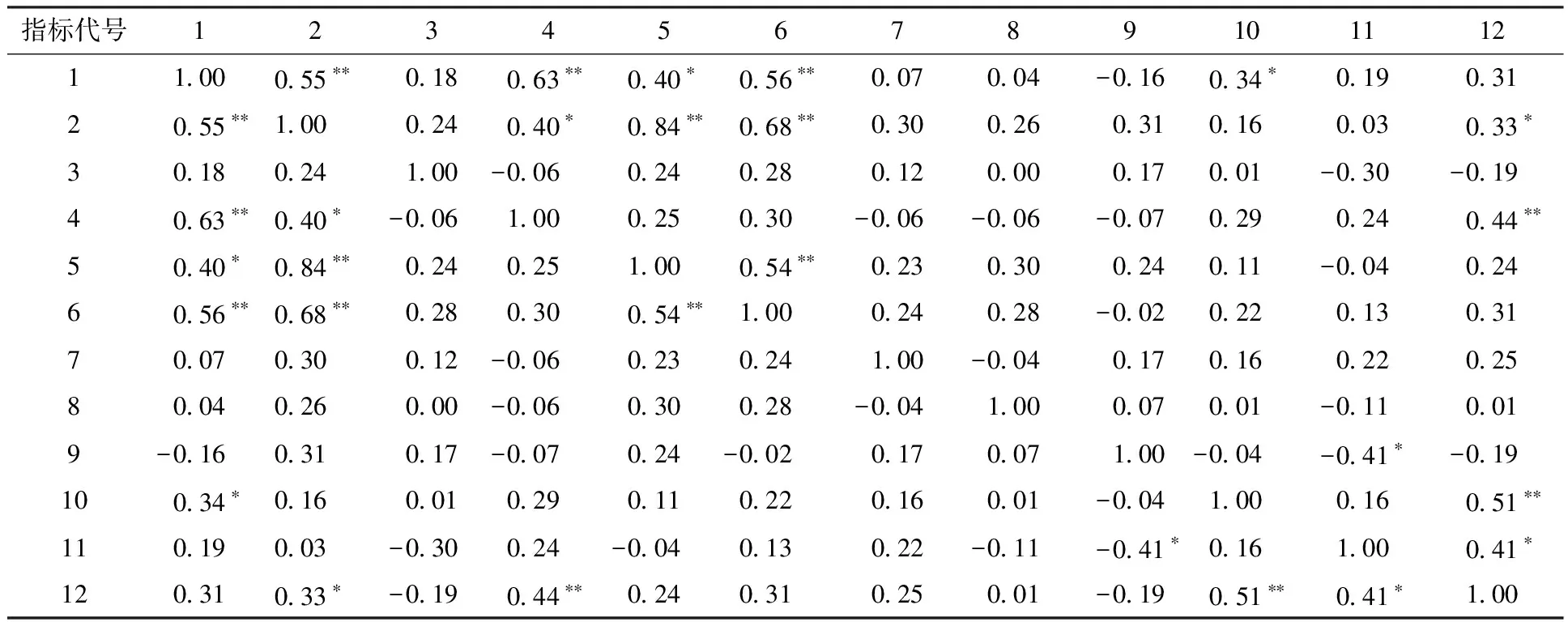
表2 12项指标皮尔逊相关系数
注:数字1~12分别表示指标:五日生化需氧量(BOD5)、氨氮(NH3-N)、铅、化学需氧量(COD)、总氮(TN)、总磷(TP)、铜、锌、镉、阴离子表面活性剂、硫化物、粪大肠菌群。*表示显著性水平为0.05,**表示显著性水平为0.01。
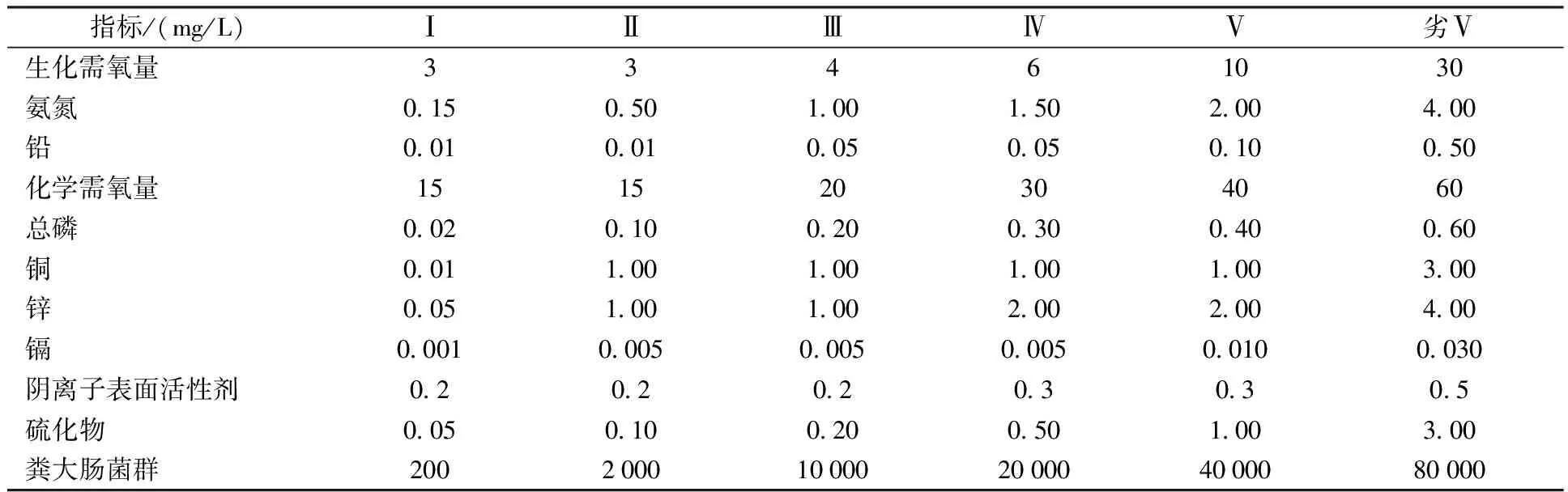
表3 地表水水质指标分类等级标准Table 3 Ground water quality indicator standards set for the six classes
注:参考地表水环境质量标准基本项目标准限制(GB 3838—2002),其中劣Ⅴ类限值在GB 3838—2002并没有,表中劣V类限值是根据宜兴市水功能区实际监测情况拟定,具有地域性。实际操作中应适具体情况而定。
μ=(a+b1i++b2i-+c1j++c2j-)j×p=

按式(11)~式(16)计算,并考虑随机观测误差权重的影响,对组合权重加以修正,得到最终权重向量W=[ω1,…,ωj,…,ω11]=[0.130 5,0.216 5,0.020 0,0.209 5,0.137 3,0.002 9,0.006 6, 0.032 4,0.078 4,0.008 8,0.157 2]。将联系度矩阵μ与权重向量W相乘得到综合联系度矩阵Z
利用集对势shi(μ)判断水质结果:shi(μ)=a/c。当a/c>1时,描述为集对同势,表示评价样本与等级标准存在同一趋势;当a/c<1,描述为集对反势,当a/c=1时,描述为集对均势。集对同势又可分为3种:当a>c>b时,为强同势;当a>b>c时,为弱同势;当b>a>c时,为微同势。
按上述定义计算陈东桥断面水质监测数据对应6个级别的集对势分别为:
shi(μ1)=1.125 0,shi(μ2)=1.617 5,
shi(μ3)=7.250 1,shi(μ4)=9.966 1,
shi(μ5)=6.075 7,shi(μ6)=3.634 0.
进行归一化处理,得到水质结果对6个级别的趋同程度分别为:3.8%、5.5%、24.4%、33.6%、20.5%、12.2%,判断其水质级别为Ⅳ类。同样可以计算其余监测断面水质结果,见表4。
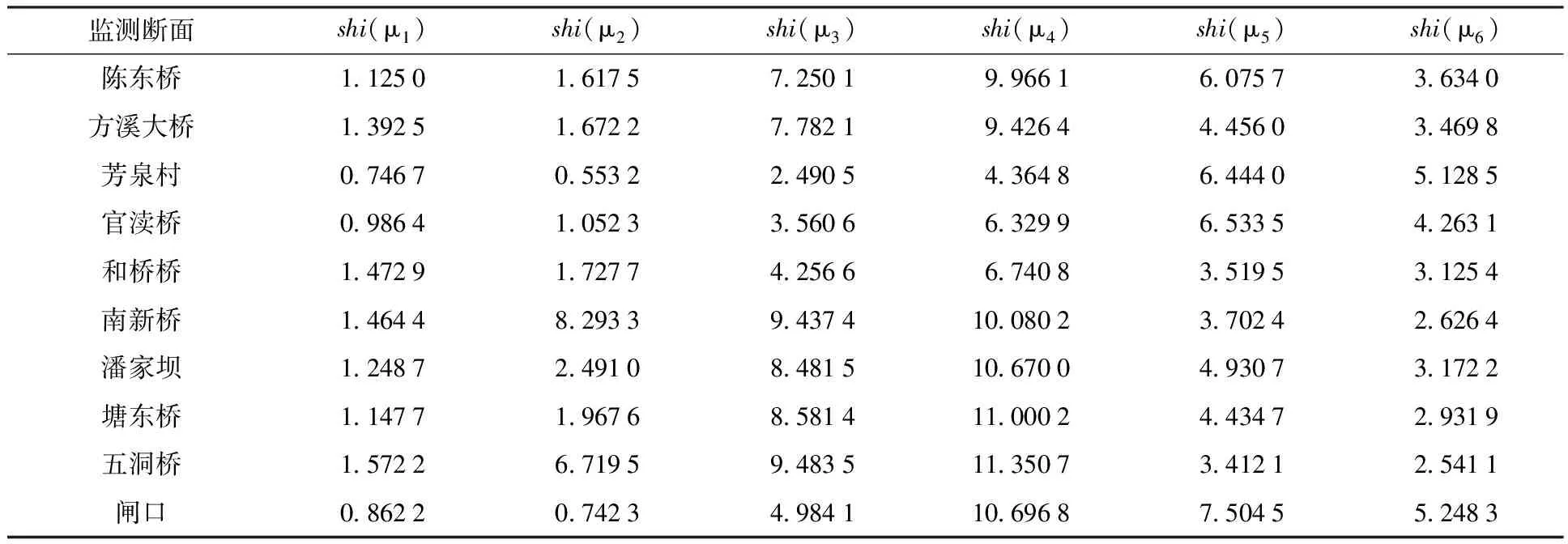
表4 各水质监测断面模型计算结果Table 4 Model calculation results for different sections
需要说明的是当不同级别的集对势存在相等或相近情况时,会影响判断结果。此时可以根据集对势的强弱,或者综合比较c1、c2的大小,强同势说明对等级趋同程度比较强,c1较大说明对等级优反程度比较大,c2较大说明对等级劣反程度比较大。如官渡桥断面shi(μ4)=6.329 9,shi(μ5)=6.533 5,两者数值比较接近,但shi(μ5)为强同势,shi(μ4)为弱同势,且μ5中c1、c2均比较小,说明其等级优反、劣反程度比较小,等级距离比较近,因此综合考虑确定官渡桥断面水质级别为Ⅴ类。同样,根据上述判断原则可以得到其余断面水质结果。为验证模型对水质级别判断的合理性,另外采用人工神经网络[2]、灰色理论法[3]、投影寻踪法[4]3种不确定性评价方法进行计算,并将结果进行比较,见表5。
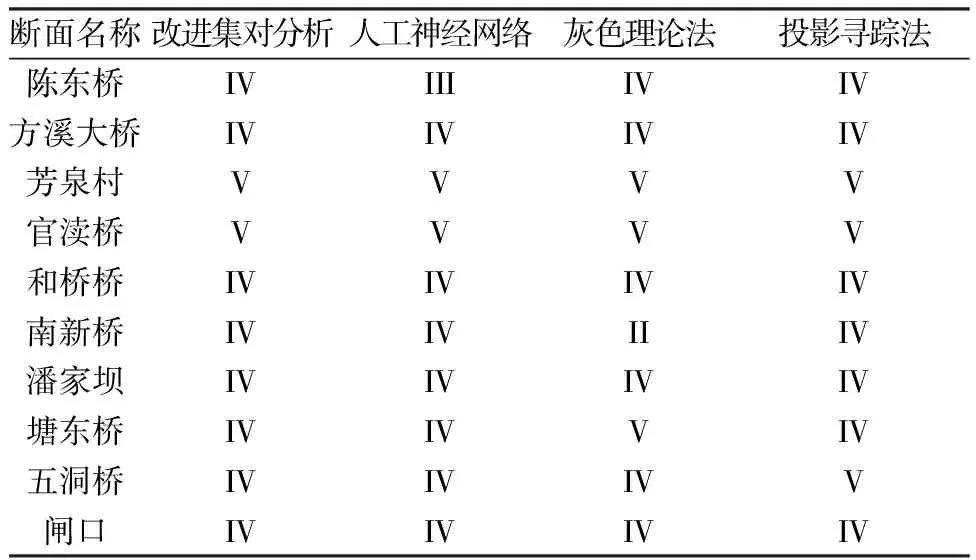
表5 4种方法评价结果比较Table 5 Comparison of evaluation resultsamong the four different methods
可以看出,4种方法所得结果基本上一致,小部分断面存在差异。在陈东桥水质监测断面上,人工神经网络判断结果为Ⅲ类,其余3种方法结果均为Ⅳ类,此断面上,11项指标中有1项为Ⅰ类,4项为Ⅲ类,5项为Ⅳ类,1项为劣Ⅴ类,综合判断为Ⅳ类比较合适。在南新桥水质监测断面上,灰色理论法结果为Ⅱ类,其余3种方法为Ⅳ类,此断面上,11项指标中有5项Ⅱ类,3项Ⅳ类,3项Ⅴ类,1项劣Ⅴ类,综合判定为Ⅳ类比较合适。塘东桥水质监测断面灰色理论法结果、五洞桥水质监测断面投影寻踪法也是类似情况。可以看出,改进的集对分析模型对于水质判断结果是比较合理的。从模型评价结果来看,与宜兴市地表水功能区水质目标(见表2)进行比较,选取的10个水功能区中,只有武宜运河宜兴景观娱乐、工业用水区,殷村港宜兴景观娱乐、渔业用水区,桃溪河宜兴工业、农业用水区,漕桥河宜兴市渔业、工业用水区4个水功能区达到水质目标要求,其余6个水功能区均未达标。
3 结论与展望
1) 通过对传统集对分析模型进行改进,将同异反联系度概念进行延伸扩展,把差异度细分为优异与劣异,对立度细分为优反与劣反,可以使其更好适应于水质评价等级细化问题。将模型应用于宜兴市地表水功能区水质评价,并将结果与人工神经网络、灰色理论法、投影寻踪法的结果进行比较,发现改进的集对分析模型水质评价结果更符合实际情况,评价结果更可靠。选取的10个水功能区中,4个水质达标,6个水质不达标,水功能区评价结果不理想。
2) 水质评价原始指标数据复杂而冗余,利用差异系数与相关性进行指标进行筛选,剔除冗余的指标,取得了不错的效果。权重计算综合使用熵值法与超标倍数法,这样既能兼顾监测数据本身的效用值,又能突出超标因子的影响。同时考虑随机观测误差对权重的影响,利用误差权重对组合权重进行修正,使得权重分配合理性得以有效提高。
3) 模型应用还处在初步阶段,可能还存在不足之处,比如模型对于结果的量化区分度不高,当水质处于同一级别时,就较难进一步区分其优劣。这在以后的模型应用中有待于进一步研究与完善。
猜你喜欢
河南科技(2022年9期)2022-05-31
安徽农业科学(2022年9期)2022-05-17
北京大学学报(自然科学版)(2022年1期)2022-02-21
黑龙江水利科技(2020年8期)2021-01-21
山西水利科技(2020年2期)2020-08-27
当代水产(2019年11期)2019-12-23
晚晴(2018年3期)2018-12-06
家庭影院技术(2018年5期)2018-06-29
家庭影院技术(2018年3期)2018-05-09
农村百事通(2018年7期)2018-05-08
