
面向科技人才情报的多策略组合模型同名消歧方法*
2018-09-03 09:53刘林
通信技术 2018年8期
刘 林
( 杭州电子科技大学 计算机学院,浙江 杭州 310018)
0 引 言
近年来,随着科技成果转化产业的发展,企业对科技成果转化的需求日益扩大。它们急需寻找到合适的科技人才来解决企业技术难题,因此搭建一个面向企业的科技人才搜索引擎具有重要的现实意义。网络爬虫是搜索引擎最重要的数据来源。然而,由于数据的多源异构性,采集的数据往往存在一定的噪音,如科技人才的同名歧义现象等。如果对同名歧义数据不做消歧处理,那么将无法保证搜索结果的准确性。
当前的同名消歧方法主要有以下三种。一是基于向量空间模型的聚类消歧方法,如杨欣欣通过抽取网页中与人名相关的特征及命名实体,利用二阶段聚类算法实现同名消歧[1];辛涛提出利用待消歧人名的组合特征,通过层次凝聚聚类(Hierarchical Agglomerative Clustering,HAC)算法来实现同名消歧[2]。二是基于社会网络的聚类消歧方法,如郎君利用检索结果中共现人名构建社会网络,并结合谱分割算法和模块度指标进行聚类实现同名消解[3];2014年,Mohammad-Hossein等人提出的CSLR方法是通过合著者构建社会网络,并结合姓名模糊度因子进行聚类实现同名消歧[4]。三是基于实体链接的消歧方法,如Peng通过计算待消歧人物文本与知识库实体文本的相似度,实现实体链接的映射以达到消歧目的[5];宁博通过抽取中文维基百科等知识库形成实体对象,并与待消歧对象进行链接以实现重名消歧[6]。
基于向量空间模型的聚类消歧方法将不同的特征组合在一起,没有考虑不同特征之间的区分度问题。基于社会网络的聚类消歧方法仅使用了人名的社会关系特性,适用性一般。基于实体链接的消歧方法对知识库信息的完整性要求过高。此外,以上的同名消歧方法,初始条件只有人名这单一信息,消歧外延过大。为此,本文通过工作单位这一具有高区分度的特征来缩小消歧外延,将同名消歧问题具体化到姓名相同、单位不同的科技人才歧义消解问题上,并利用科技人才的成果信息(包括学术论文、专利和科研项目)组合多个消歧策略,提出了一种基于多策略组合模型(Combination Model of Multi-Strategy,CMMS)的消歧方法。
1 流程框架及数据准备
为了搭建科技人才搜索引擎,本文利用分布式爬虫技术从互联网上采集海量的科技成果,包括学术论文、专利和科研项目,并从中提取作者、负责人及其工作单位等信息,经过必要的数据预处理形成待消歧数据集。同时,将采集的科技成果进行向量化表示,以便后续计算成果相似度时使用。另外,从高校和科研院所官方网站采集科技人才信息,构建科技人才知识库。整个流程框架如图1所示。

图1 流程框架
1.1 数据预处理
从科技成果中提取作者或负责人的工作单位后发现,关于单位信息有很多噪音。
一种情况是单位之间具有包含关系,如从专利《一种基于文档评分模型和相关度的学术论文搜索排序方法》(申请号:CN201710461109.9)中抽取得到科研人才徐小良的工作单位是杭州电子科技大学,从学术论文《基于RSS空间线性相关的WLAN位置指纹定位算法》中抽取得到科技人才徐小良的工作单位是杭州电子科技大学计算机学院。针对此种情况,直接依据单位之间的包含关系进行消歧,认为他们属于同一个现实实体。
另一种情况是工作单位出现曾用名。由于时代的发展,很多高校和科研院所都存在改名或合并的情况。如果一位科技人才在某一个单位工作的时间较长,且在该单位改名前后都有成果发表,那么从成果中提取科技人才时就会出现错误。比如,从科技成果中可以提取到“严义,杭州电子工业学院”和“严义,杭州电子科技大学”。实际上,杭州电子工业学院在2004年改名为杭州电子科技大学。为了避免这种情况的发生,本文利用分布式爬虫技术采集现有的高校和科研院所名单及其改名或合并信息,并对抽取得到的科技人才的工作单位进行规范化处理,一律使用现用名替代曾用名。这也属于一种同名消歧的方法。
1.2 成果向量化表示
为了计算科技成果之间的相似度,需要将它们进行向量化表示。本文采用词向量模型Word2vec表示科研人才的成果。首先,通过海量的语料库训练词向量;其次,构建语义化的科技成果向量;最后,计算成果之间的相似度,用于同名消歧。
成果向量化表示的具体步骤如下。
(1)构建语料库。语料库由学术论文、专利和科研项目三项成果组成。鉴于每一种成果都有很多属性,只选取强特征属性。因此,选取了学术论文的标题、摘要和关键词3个属性,选取了专利的标题和摘要2个属性,选取了科研项目的标题、中文摘要和中文主题词3个属性。选好属性后,将属性的内容以字符串拼接的形式构成一段文本,该段文本就表示一项成果,从而形成了一个大型的语料库。
(2)处理语料库。训练词向量前,需要对语料库进行分词、过滤停用词和提取特征词的处理。准确的分词需要高效的分词算法和高质量的词库。结巴分词满足了需求,是目前最好的Python中文分词工具包,分词准确、运行速度快且占用资源少[7]。中文中有许多使用广泛但实际意义不大的词,如“的”“了”和“这”等,被称为停用词(Stop Words)。分词时,需要将这些停用词过滤掉。对于这类停用词,网络上有许多公开的停用词库,如哈工大停用词库、百度停用词库等。在成果文本中,还有很多类似“基于”“研究”“提出”和“方法”等高频词。这些词不仅不能反映成果文本的特征,还影响语义表达的准确性,因此分词时也需要剔除。剔除这类词可以构建自定义的停用词库来完成。经过公开的停用词库和自定义的停用词库过滤后,将得到处理后的分词结果。同时,本文通过提取科技成果的关键词或主题词构建科技领域词典,用该科技词典来进行成果的特征词提取。
(3)训练词向量。语料库处理完成后,可以训练词向量。本文采用Google开源的词向量表示工具Word2vec,并选择CBOW模型训练语料库,设置词向量的维度为300维,最后输出词向量文件。
(4)生成成果向量。将每项成果的所有特征词所对应的词向量相加,就得到了该项成果的向量表示。最终得到的成果向量如图2所示。

图2 成果向量
2 基于多策略组合模型的科技人才消歧方法
如上所述,本文的消歧对象是姓名相同、单位不同的科技人才。由于数据的多源异构性,通过网络爬虫采集的科技人才难免会出现同名歧义的问题。为了解决这一问题,本文在已采集的科研人才信息基础上,通过组合多个策略构建决策模型,以对姓名相同、单位不同的科技人才进行消歧,即多策略组合模型(Combination Model of Multi-Strategy,CMMS)。所考虑的消歧策略包括实体链接、成果时间窗、成果合著者和成果相似度。为了便于描述,设两个姓名相同、单位不同的科研人才分别为 P1和 P2。
2.1 基于实体链接的消歧策略
实体链接消歧策略是一种将待消歧对象与现实世界中的实体进行匹配链接以达到消歧目的的方法[8]。该方法的重点和难点是构建现实世界实体对象的知识库。本文采用分布式爬虫技术,从高校和科研院所官方网站采集科技人才信息构建科技人才知识库,并以月为周期进行更新和增量采集,确保构建的知识库信息及时准确。
本文的初始条件是已知待消歧对象的姓名和工作单位,因此在进行实体链接时,只需要对姓名和工作单位进行匹配即可。
判断规则如下:
(1)若P1与知识库中的的姓名和单位相匹配,则认为是P1的实体链接;若P2与知识库中的的姓名和单位相匹配,则认为是 P2的实体链接。因为和是不同的实体,所以认为P1和P2是不同的人。
(2)当P1和P2中只要有一个没有实体连接,则无法判断P1和P2是否为同一人,需要进一步利用其他策略进行判断。
该策略是一个很好的消歧策略,能直截了当地实现一些待消歧对象的消歧。但是,科技人才的范畴十分广泛。高校和科研院所的工作人员只是科技人才的一部分,企业和其他机构同样拥有大量的科技人才。由于隐私性等原因,采集这些科技人才的信息十分困难。因此,该策略的局限性显而易见,其消歧效果直接受知识库数据规模的影响。

图3 成果时间窗之间的关系
2.2 基于成果时间窗的消歧策略
成果时间集是指一个科技人才已取得的所有科技成果的年份的集合。将这些年份数字按照从小到大进行排序,选取最早和最晚的年份作为端点,将端点及其内部的所有年份构成的年份窗口叫作成果时间窗。具体地,对于学术论文,选取该论文被出版的刊期年份;对于专利,选取专利的公开日年份;对于科研项目,选取项目的实施年份。
任何两个科技人才的成果时间窗都具有相离、相交、包含三种关系,如图3所示。
现实世界中,一个科技人才在某一时间段内只能拥有一个正式的工作单位。科技人才在工作单位所取得的成果归单位所有。因此,可以根据科技人才所取得的成果的时间窗来判断两个姓名相同单位不同的科技人才在现实世界中是否为同一个人。
设P1和P2的成果时间窗分别为ATW1和ATW2,判断规则如下。
(1)若ATW1和ATW2交集的元素个数大于2,则认为P1和P2不可能为同一个人,即P1和P2是两个人。
(2)若ATW1和ATW2交集的元素的个数小于或等于2,则无法判断P1和P2是否为同一个人,需要利用其他策略进行判断。
该策略利用了科技人才成果时间窗的互斥属性来实现排歧,但是它无法消除工作单位发生变动的同名科技人才的歧义问题。
2.3 基于成果合著者的消歧策略
人们在进行科研活动时,往往以课题组或科研团队的形式进行。这种形式在科技成果上的表现就是一项科技成果有多个参与者。从待消歧对象的科技成果中抽取成果合著者,构成成果合著者集合。具体实现时,将使用二层合著者关系挖掘合著者,如图4所示。

图4 二层成果合著者
设P1的直接合著者构成的集合为A,二层合著者构成的集合为A',P2的直接合著者构成的集合为B,二层合著者构成的集合为B',判断规则如下:
(1)只要 A∩ B、A ∩ B'、A'∩ B、A'∩ B'有一个不为空集,即P1和P2有成果合著者,则认为P1和P2是同一个人。
(2)若 A ∩B、A ∩B'、A'∩ B、A'∩ B'都为空集,则无法判断P1和P2是否为同一个人,需要利用其他策略进行判断。
该策略依据“物以类聚,人以群分”的思想,通过待消歧对象的学术网络实现消歧。然而,它仅仅利用了关系网络这单一属性,消歧效果并不显著。
2.4 基于成果相似度的消歧策略
通常情况下,一个科技人才的研究方向会随着时代的发展发生一些变化,但是其研究领域是不会发生重大变化的。比如,从建筑领域转到医疗领域,概率是极低的,可以认为几乎不可能。基于以上的现实情况可以认为,一个科技人才在其成果时间窗内所取得的成果都是属于某一个研究领域的,即其成果具有很高的相似度。根据这个结论,可以通过计算两个姓名相同、单位不同的科技人才的成果相似度来进行消歧。
为了计算成果之间的相似度,首先需要将成果进行向量化表示。本文采用词向量模型Word2vec表示科研人才的成果。成果向量化表示后,采用余弦相似度来计算成果之间的相似度。设P1和P2的成果集分别为 AC1=(x1,…,xi,…,xm)和 AC2=(y1,…,yj,…,yn),其中m、n表示成果的个数。两个成果xi、yj之间的相似度计算公式为:

将两个成果集AC1和AC2中所有的成果之间的相似度计算完成后,取所有相似度的平均值作为两个成果集之间的相似度,即:

然后,通过设定的相似度阈值θ可以进行判断了,具体规则如下:
(1)若sim(AC1,AC2)≥θ,则认为P1和P2是同一个人;
(2)若sim(AC1,AC2)<θ,则认为P1和P2是两个人。
该策略利用科技人才的研究领域具有极强的固定性这一现象将其成果向量化表示。运用计算成果之间的相似度来实现消歧,其消歧的准确性直接依赖于相似度阈值的设定。
2.5 多策略组合模型消歧方法
前面分别介绍了基于实体链接、成果时间窗、成果合著者和成果相似度的消歧策略。然而,每个策略都有其局限性:基于实体链接的消歧策略的效果依赖于知识库的数据规模;基于成果时间窗的消歧策略无法实现对工作单位发生变动的同名科技人才进行消歧;基于成果合著者的消歧策略效果一般;基于成果相似度的消歧策略的准确性取决于相似度阈值的设定。鉴于上述原因,将以上的4种消歧策略进行组合,提出了多策略组合模型CMMS的消歧方法,其组合形式如图5所示。

图5 多策略组合模型组织形式
当对两个姓名相同、单位不同的科研人才P1和P2进行消歧时,首先将他们与科技人才知识库进行匹配。若在知识库中找到了他们的实体链接,则可以判定P1和P2属于两个不同的实体;若没有匹配到实体链接,则判断他们的成果时间窗的交集是否大于2。若大于2,则判定他们属于两个实体;若不大于2,则判断他们有无成果合著者。若有成果合著者,则认为P1和P2是同一个实体;否则,利用成果相似度来消歧。若成果相似度小于θ,判定他们属于不同的实体;若成果相似度不小于θ,判定他们属于同一实体。
然而,姓名相同、单位不同的科技人才往往有很多,将单位不同的某一姓名的科技人才构成的集合称为该姓名所对应的伪集合。之所以称为伪集合,是因为集合里面的元素可能重复。不妨设该伪集合的元素个数为n。那么,消歧将扩展为对n个姓名相同、单位不同的科技人才的消歧。
消歧过程实际上就转化为:
(1)从伪集合中任选两个元素Pi和Pj,通过模型进行判断;
(2)若Pi和Pj为同一个人,则将他们合并,伪集合的元素个数变为n-1;重复步骤(1),直至所有的元素之间都通过模型进行了判断;
(3)若Pi和Pj为两个人,则将伪集合裂变成两个子伪集合,重复步骤(1),直至所有的元素之间都通过模型进行了判断。
根据排列组合原理,很容易得到进行判断的次数在n-1到Cn2之间。
3 实验设计及分析
3.1 实验数据
实验数据来源于第2章所述的待消歧数据集。由于数据量巨大,本文选取10个姓名所对应的伪集合作为实验数据并进行了人工消歧,数据如表1所示。同时,将消歧过程中未与其他待消歧对象合并的对象称为独立实体,与其他待消歧对象合并的对象称为非独立实体。例如,在消歧前伪集合为(A,B,C),消歧后的结果为(A,BC),则称A为独立实体,B和C为非独立实体。
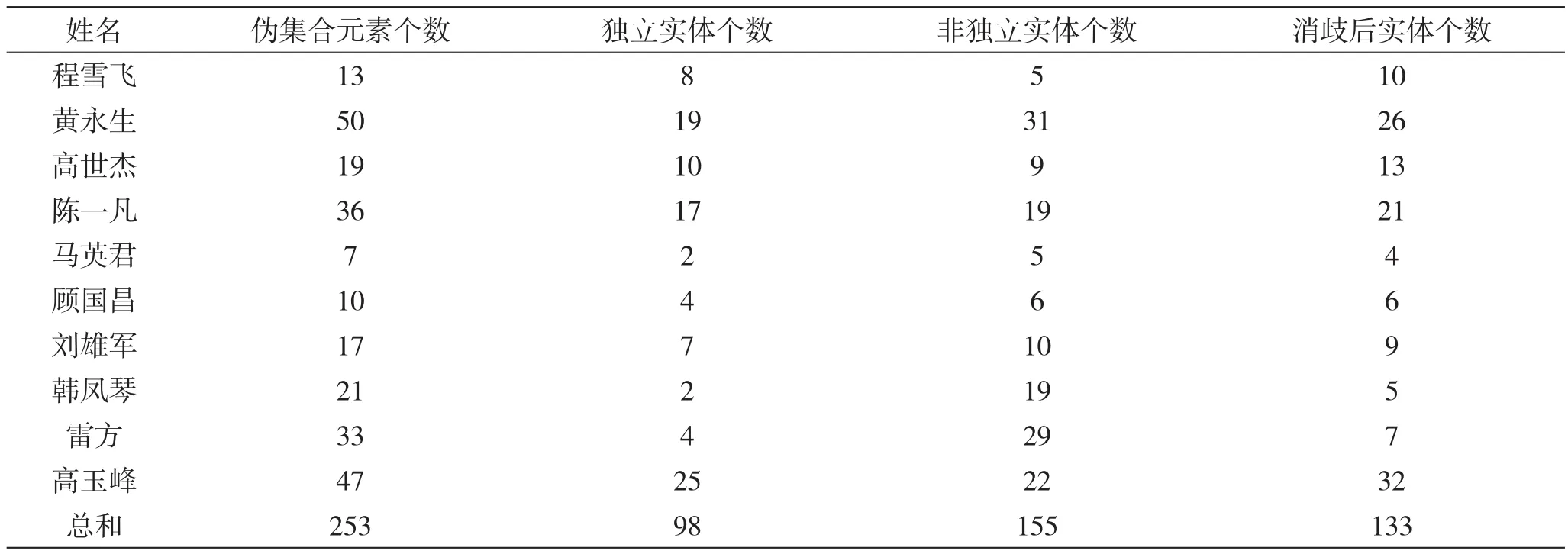
表1 实验数据
3.2 评价指标
本实验采用实体消歧方法中最常用的查准率P、召回率R和综合评价指标F1作为评价指标。针对一个伪集合,设TP表示被消歧模型判定为独立实体且实际上也是独立实体的个数,FP表示被消歧模型判定为独立实体而实际上却是非独立实体的个数,TN表示被模型判定为非独立实体且实际上也是非独立实体的个数,FN表示被消歧模型判定为非独立实体而实际上却是独立实体的个数。
评价指标的计算公式如下:


式(3)、式(4)和式(5)中,P表示查准率,R表示召回率,F1是结合查准率和召回率的综合评价指标。
3.3 实验分析
本文从两个角度对实验数据进行分析:一是相似度阈值θ的设定;二是将本文提出的多策略组合模型与基于成果聚类的消歧方法Word2vec+HAC及文献[4]中提出的CSLR方法在实验数据集上进行对比实验。其中,Word2vec+HAC利用基于Python平台的scikit-learn机器学习包实现,CLSR方法根据文献[4]中提供的下载程序实现。
3.3.1 相似度阈值θ的设定
使用表1中的实验数据,完成对相似度阈值的设定。通过枚举法对成果向量之间的夹角β从15°到75°、步长为5°进行实验。结果如表2所示,其中P值、R值和F1值都表示平均值。
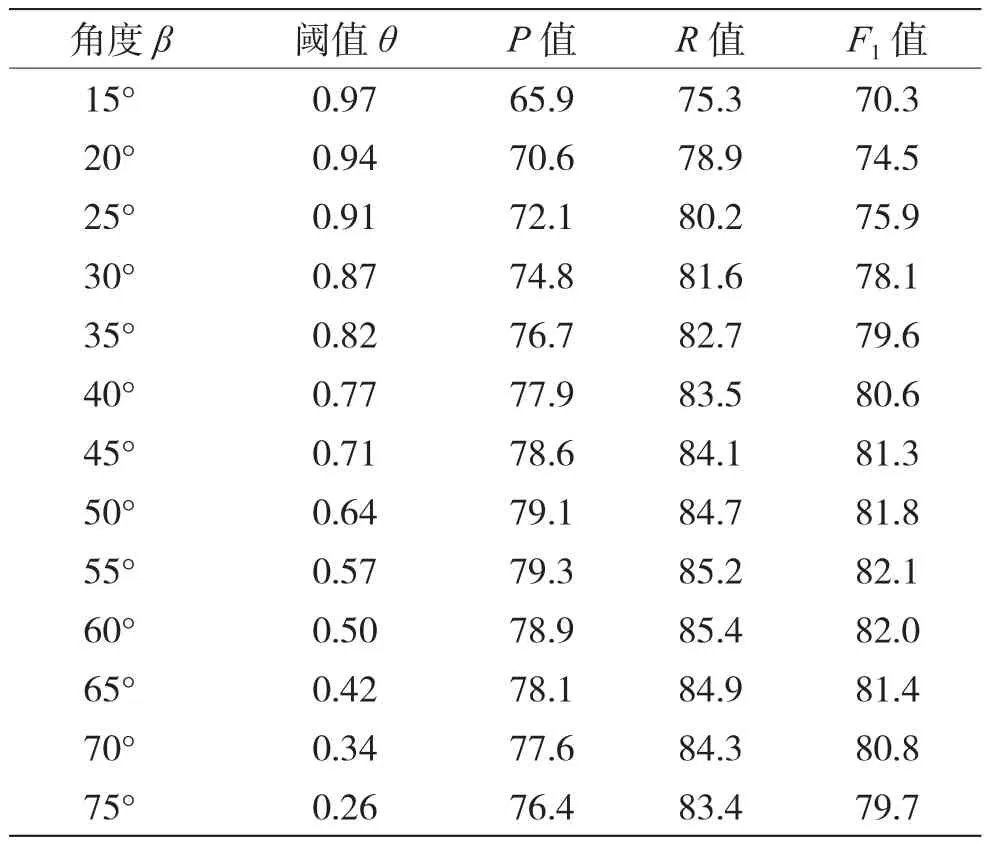
表2 实验结果
可以看出,当相似度的阈值在0.50~0.57时,P值、R值和F1值较好。当相似度阈值很大时,只有两个待消歧对象的成果非常相似时,模型才会判定他们属于同一实体。然而,如果一个科技人才从事科技活动的时间很长,虽然其研究领域几乎不会发生重大转变,但是其研究方向会随着时代发生相应变化,这样就会导致本应该合并的消歧对象没有合并。当相似度阈值设置很小时,虽然能避免上述情况,但往往又会造成过度合并的情况。因此,在后面的实验中,将相似度阈值设定为0.50和0.57的平均值,即0.535。
3.3.2 CMMS与其他两种方法的对比实验
将本文的CMMS方法与Word2vec+HAC方法和CLSR方法进行对比实验。其中,Word2vec+HAC使用基于Python平台的scikit-learn机器学习包实现,CLSR方法根据文献[4]中提供的下载程序实现,实验结果如表3所示。为了更直观显示实验效果,使用柱状图进行表示,如图6所示。
可知,CMMS方法的平均查准率、平均召回率和平均F1值都优于其他两种方法。Word2vec+HAC和CSLR方法的三项评价指标较为接近。
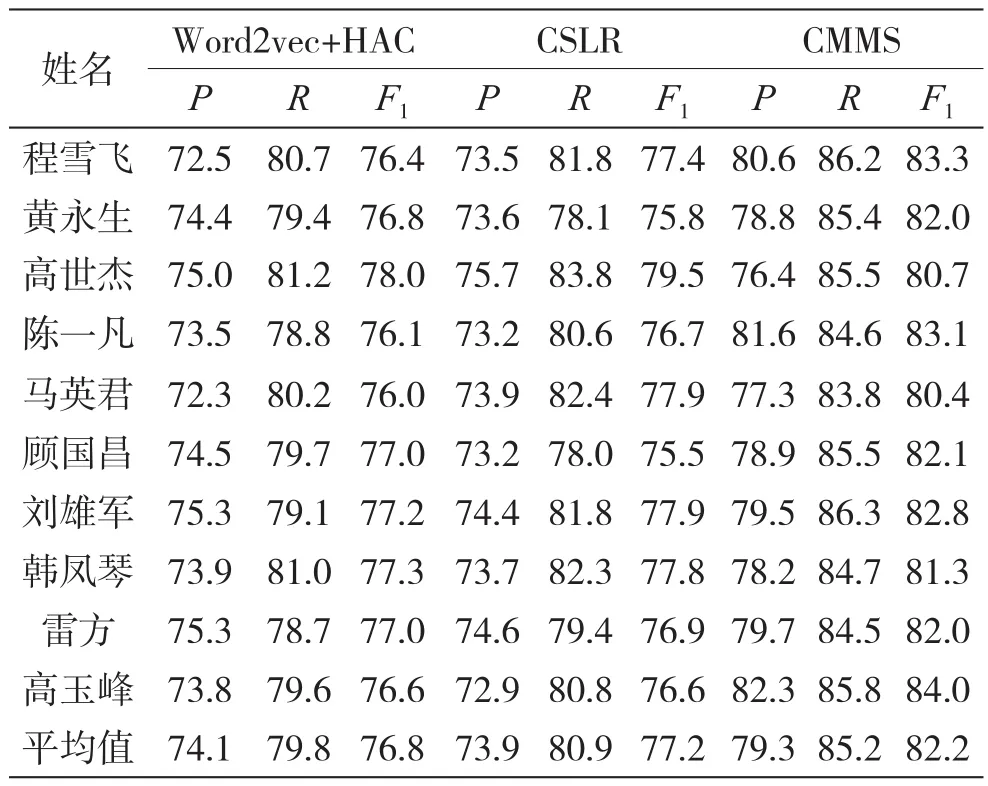
表3 实验结果

图6 实验结果柱状图
4 结 语
针对目前同名消歧方法只考虑单一策略且消歧外延过大的问题,本文通过工作单位这一具有高区分度的特征来缩小消歧外延,将同名消歧问题具体化到姓名相同、单位不同的科技人才歧义消解问题上,并利用科技人才的成果信息,组合了实体链接、成果时间窗、成果合著者和成果相似度四个消歧策略,提出了一种基于多策略组合模型的消歧方法。实验结果表明,该方法取得了较好的同名消歧效果。同时,在实验过程中发现,知识库在消歧中的作用很大,可以保障准确度。因此,如何找到更高效的方法来丰富和扩充知识库以提高消歧效率,值得进一步研究。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
北京大学学报(自然科学版)(2022年1期)2022-02-21
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
河北农机(2020年10期)2020-12-14
制造技术与机床(2019年6期)2019-06-25
商周刊(2018年18期)2018-09-21
当代陕西(2017年12期)2018-01-19
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
海军航空大学学报(2015年1期)2015-11-11
