
网页学术性判断算法设计与实现
2018-09-01 07:13:30
福建质量管理 2018年16期
(西安天和防务技术股份有限公司 陕西 西安 710075)
一、网页学术性判断现状
(一)网页学术性
学术性[1]是学术性网页的基本属性,也是学术性的网页所应具有的鲜明特征。而如如何判断网页的学术性,要从学术网页本身的内容来分析,一般从创新性、实验性、理论性三点来分析网页[2]。
首先创新性,网页所表达的学术内容是否具备创新性,创新性是学术性论文的核心,学术性论文的创新性最集中地体现为它在多大程度上消除了不确定性。因为创新性可以反应出该论文是否是是作者的原创的学术工作,而不是对他人的论文的抄袭或者重复的机械工作。
其次实验性,因为实验性是对论文中作者提出的创新性的验证,通过实验性的验证,可以很好的分析出作者提出的观点是否正确,是否可以有效的被引用,必须强调的是,实验性是对创新性的验证,而不是对既定的正确的理论进行验证的分析。
最后理论性。不论作者提出了什么创新或者验证这个创新的可行性。但是依然需要对自己所做的上述的两点内容进行总结概况,使其成为可以有效的,具有体系的理论知识。这一点可以使论文具有很好的学术借鉴性。
总之,关于有效的判断一个网页是否具有学术性,目前还没有特别系统和有效的判定方法。
(二)网页学术性判断依据
对于网页是否具备学术性,需要对网页本身进行分析,通过分析网页的内容来判断,是否该网页具备学术性的特征[4],而一个网页本身一般具有三个特征:分别是内容上的特征、网页的结构上的特征和网页外部的特征,所以对于网页学术性的判断需要从上面的三点出发进行判断和分析:
1.网页的内容特征
网页的内容特征是指:网页本身的主题内容所表达的主旨。而学术性网页的往往是对一篇对应的学术文献的总结或者大纲式的展示,它具有一般的学术性论文的大部分特征。所以在网页的内容上的学术性分析,就等价于对这个网页内容中存在的关键字的分析,分析这些关键字是否具备专业学术性的特征。例如:学术性网页的标题的内容一般都是“基于…研究”,所我们就可以选取“基于”、“研究”作为判断网页学术性的关键字。
2.网页结构特征
网页结构特征是指:网页在布局格式上是否具备学术性网站所具有的格式特征。由于学术性的网站大都是对一篇学术文献的内容总结或者大纲展示,所以多数学术性网页结构内容与一篇论文的目录无异。例如在格式上就是:标题、指导老师、作者、摘要、关键字、分类号、引用次数、浏览次数等这样分块展示,以这样的分块分别对网页所具有的学术性进行说明。
所以基于上述两点,并且针对网页的这两点进行分析和判断,基本上就可以得出一篇网页是否具有学术性或者说这个网页是否为一篇学术型的网页。
二、基于贝叶斯算法的网页学术性判断算法设计与实现
由于目前并没有一个全面的成熟的可以进行网页学术性判断的算法,因此本文提出了基于贝叶斯算法的网页学术性判断算法,而贝叶斯算法的基础就是贝叶斯定理,同时贝叶斯算法也是实现网页学术性判断算法的基础。
(一)贝叶斯定理
贝叶斯定理[7]使用理论统计学研究概率推论,它是根据已经发生的事件随后预测将来可能发生的事件。在贝叶斯定理中有明确的描述:如果某事件的发生的结果是不确定性的,那么唯一的可以量化它的方式就是来描述这个事件发生的概率。
贝叶斯定理的数学表述如下:
假定存在两个为事件A与B,且P(A)>0,在事件A已经发生的条件下,事件B发生的概率,称为事件B在给定事件A的条件概率(也称为后验概率),条件概率表示为P(B|A)。P(B)可称为无条件概率。条件概率的公式为:
(1.1)
由条件概率可得到乘法公式:
P(AB)=P(A)P(B|A)=P(B)P(A|B)
(1.2)
假设S为试验E的样本空间,A为E的事件,B1,B1,…Bn为S的一个划分,且P(B)>0(i=0,1,2…n),则全概率公式为:

(1.3)
由条件概率公式和全概率公式可得如下的贝叶斯公式:
(1.4)
由贝叶斯公式求得后验概率为:
(1.5)
(二)网页特征提取
一个网页所包含信息是非常丰富的,但是对于这个网页的主题信息而言,其实只有很少的一部分对用户来讲是有效的或者说只有一部分是关于这个网页的主题信息的表述,需要对网页信息进行筛选,选取能表示网页主题的部分关键字,即找到该网页的特征关键字。
对目标网页进行特征提取[8]的算法是否优良,会直接影响到网页分类的质量。如下表1所示,为常用网页特征提取方法的比较。

表1 常用的网页特征提取方法
关键字的特征频率可以很好的反应关键字与文章主题之间的关系,并且易于计算,所以在本文中选取特征关键字的特征频率(即不同的网页中出现的某些词组的频率词)作为我们算法的基础参数,并使用各个特征关键字的特征频率作为我们的网页学术性判断算法的基础。
1.网页学术性判别算法
依据贝叶斯定理,将总网页的样本用W={w1,w2,……,Wn}表示,而各个样本网页由多个关键字组成的,即各网页样本用H={h1,h2,……,hi}表示,P(h)表示各个不同的关键字在网页中出现的概率,P(D)示将要观察的网页数据D在没确定某一假设成立时D的概率;P(D|h)表示关键字(h)在网页数据中出现概率。最后求得P(h|D),即给定一个训练样本数据D时h成立的概率。由贝叶斯公式求得后验概率为;
(1.6)
由于在样本集合中对于给定的W,存在的关键字是多个的并且相互独立。则各个关键字的对应的概率求和相加,得到表示这个网页的主题相关度的值K,如下:
(1.7)
由于W是不依赖于h的常数,所以上式可以简化为:
(1.8)
在特定情况下,可以假设H中的任意假设hi和hj,都有P(hi)=P(hj),即它们的先验概率相等,这样就可以简化上面的公式,最后只考虑P(D|h)来确定网页主题的相关度阈值:
(1.9)
2.K值计算
第一步:选取样本:
首先在网上抓取了3000个网页作为测试数据,对这些测试数据进行人工分析,得出满足学术性的网页个数为176个。
第二步:计算机样本K值:
对于样本数据中的各个词出现的频率的统计,经过对样本网页的分析得出,有一部分关键字可以很好的对网页的学术性进行准确说明,选取这些关键字作为网页学术性特征的代表关键字,然后依靠贝叶斯算法求得各个关键字的特征频率。
首先选取的样本的代表关键字为:标题、基于、研究、引言、摘要、目录、绪论、刊名、作者、机构、致谢、分类号、关键字、结束语、参考文献、作者单位、浏览历史、下载历史、基金项目、文献标识码、所属期刊栏目。
对于上述关键字的特征频率的统计基本信息如下表2所示,第一列为网页中的关键字的序号,第二列是网页中的关键字名称,第三列是网页中出现的关键字的数量统计,第四列是对应网中出现的关键字的实际观测概率。

表2 网页信息统计
对于上面统计的关键字进行分析,发现对于网页而言,出现频率较大的词语,即概率较大的关键字是大多数的网页所共有的,并且这些关键字对于判定该网页的学术性的判定是较低的。
反而一些概率较小的关键字对于判定该网页是否具有学术性的判定则较高,所以选取一部分关键字作为判定网页是否具有学术性的判定因子。
网页特征选取的依据:在表2中发现网页关键字的特征频率的统计中,有的关键字依然不能对网页主题的学术性有较好的说明,所以需要人工剔除一部分,选出可以代表和高度浓缩网页主题的关键字,进而作为网页学术性判断定关键字。
选取的关键字有:刊名、文献标识码、所属期刊栏、分类号、摘要、关键字、作者、作者单位、浏览历史、下载历史、基金项目。对于剩余的其他关键字我们不做选择,由于剩余的关键字对网页的主题的说明上不具备说服性和代表性。
由于上述这些关键字对应的特征频率较小,采用取反的数学处理方式对其进行处理,即通过取反方法的提高了这些关键字的特征频率的数值,便于程序后续对网页是否具备的学术性进行排序。
学术算法中的选取的部分关键字列表如下表3所示:
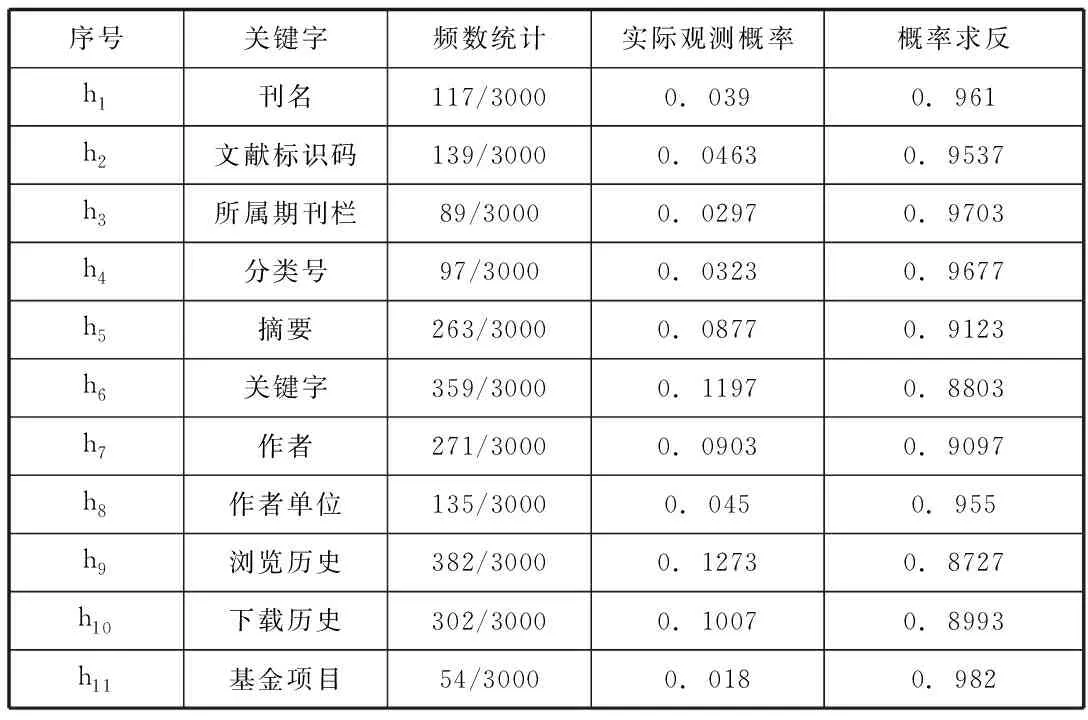
表3 网页关键字及其权值

K为网页学术性的相关度阀值,随后对于样本数据进行处理,计算出每个网页对应相关度,依据相关度从大到小排序。下图1为截取的部分排序图片:

图1 经学术判定后的网页信息
第三步:阈值选取分析:
前期在3000网页样本中,人工分析的学术网页个数是176个。而在机器排序中,选取相关度阈值前176的网页,然后人工分析这些网页的学术性,第176个网页的相关度阈值为:5.428。
由于相关性阈值为5.428处的网页个数为3个,则选取的网页个数为179。在179个网页中,再次进行人工鉴别,这179个网页中,具有学术性的网页个数是145,其中不具备学术性的个数为34个。
查全率:145/176=0.8239
精准率:145/179=0.8101;
即学术网页判定算法的精准率为81.01%。
而进行人工鉴别的时候,判断出具有学术性的网页个数为176个,再次对3000网页的排序进行人工分析,观察到第241个网页时,找到了所有的具有学术性的网页,而第248个网页对应的阈值为:4.3263。其中不具备学术性的网页个数为65个。
查全率:176/176=1
精准率:176/241=0.7302
即学术网页判断算法的查全率为:100%,而精准率为73.06%。
第四步:选取阈值:
经分析可得,查全率和精准率是无法同时满足的,所以在使用时对阈值的选取十分重要,要以满足自己的需求来选取阈值。在本算法中,要以精准率为首要考虑要求,所以选取精准率较高的阈值作为系统阈值,即:K=5.428。
三、总结
本文提出的基于贝叶斯算法的网页学术性判断算法,与单纯的贝叶斯算法进行比较,实现了贝叶斯算法有的新应用,由于目前还没有一个较为完整的对于网页学术性判断的判定算法,本文结合贝叶斯算法提出的网页学术性算法较好的完成了对于网页学术性的分类,可以较为准确的和快速的判别出抓取的目标网页是否具备学术性。
猜你喜欢
华人时刊(2022年1期)2022-04-26 13:39:28
海南开放大学学报(2020年3期)2020-12-20 06:18:51
科技创新与应用(2020年4期)2020-02-25 13:31:25
动漫界·幼教365(大班)(2019年10期)2019-10-28 01:54:09
光学仪器(2019年3期)2019-02-21 09:31:55
制造技术与机床(2018年12期)2018-12-23 02:41:22
电子测试(2018年22期)2018-12-19 05:12:28
湖北农业科学(2017年12期)2017-07-15 20:45:34
智能计算机与应用(2011年4期)2012-05-15 02:24:18
计算机应用文摘(2010年9期)2010-04-29 00:44:03
