
数据挖掘与模型构建在预测重症手足口病中的应用*
2018-08-20 03:53:26黄平冯慧芬王斌赵敬易佳音
中国现代医学杂志 2018年23期
黄平,冯慧芬,王斌,赵敬,易佳音
(郑州大学第五附属医院 1.消化内科,2.感染科,河南 郑州 450052)
手足口病(hand-foot-mouth disease, HFMD)是一种由肠道病毒引起的,以婴幼儿发病为主的急性传染性疾病[1]。尽管多数患儿表现为症状轻微,但也有少部分患儿因各种严重的神经系统、呼吸系统并发症而导致后遗症,甚至死亡,因而如何早期识别重症患者成为临床医生面临的重要难题[2]。数据挖掘是一种从大量的数据中,通过数理模式来探索隐藏数据中未知规律的过程。本研究通过数据挖掘的思想,构建决策树模型,从复杂的临床资料中找出较佳的预测指标,从而为临床医生HFMD诊断治疗提供一种辅助决策手段。
1 资料与方法
1.1 一般资料
选取2016年6月-2017年10月于郑州大学第五附属医院收治的HFMD患儿838例。其中,男性513例,女性325例;年龄3个月~4岁,平均(2.3±1.1)岁;平均住院时间(4.5±0.8)d。所有患儿经病原学确诊。根据《手足口病诊疗指南(2010年版)》中的诊断标准,将所有患儿分成轻症组480例和重症组358例[3]。轻症组:仅表现为手、足、口及臀部的皮疹,伴或不伴发热;重症组:出现神经系统受累的表现,如头痛、呕吐;精神差、嗜睡、易惊、谵妄及惊厥;肢体抖动,肌阵挛、眼球震颤、共济失调及眼球运动障碍;无力或急性弛缓性麻痹;体征可见脑膜刺激征,腱反射减弱或消失。收集患儿信息资料,初步制定预选的分析变量,包括性别、年龄、发热时间、最高体温、易惊、肢体抖动、抽搐、寒战、嗜睡及呕吐等。
1.2 方法
由专人负责设计问卷调查表,通过交叉核对,使用EpiData 3.1软件进行原始数据的录入。通过一系列数据整理,包括去除缺失、异常及重复个案等,最后生成一份完整的数据。对所有预测变量进行二分类处理,并赋值为0或1。其中连续性变量处理后分别为:年龄<3岁,发热时间≥3 d,体温≥38.5℃,白细胞≥10.8×109/L,中性粒细胞比率≥75%,血糖≥8.3 mmol/L。满足上述条件的均赋值为1,不满足上述条件的赋值为0。其余变量按照是否存在相应症状,将是赋值为1,否赋值为0;性别男赋值为1,女赋值为0;居住地农村赋值为1,城市赋值为0。最后将处理后的数据,进行统计学分析。
1.3 统计学方法
数据分析采用SPSS Statistics 23.0统计软件,模型构建和评估采用SPSS Modeler 18.0软件。Modeler软件在决策树构建模块提供了多种算法,包括随机树、分类和回归(classification and regression, C&R)树、C5.0、χ2自动交互检测法(chi-squared automatic interaction detector, CHAID)及高效统计树(quick unbiased efficient statistical tree, QUEST)等。所有算法的基本操作相同,即将数据分隔成多个子组来实现最佳分类或预测,但因输入和目标(输出)字段的类型是连续型变量或分类变量而有区别。其中C&R和CHAID的输入和目标字段可以是连续或分类变量,而QUEST和C5.0要求目标字段必须是分类变量。根据以上原理,在Modeler软件中,先选用自动分类器,对上述常见算法进行建模,最后根据总体精确性对所有算法进行筛选,选取最优算法,配置模型参数,输出分类树模型,评估模型的预测正确率,输出模型的累计收益图,评估模型拟合效果,同时绘制受试者工作特征(receiver operating characteristic, ROC)曲线,评估模型的诊断性能。
2 结果
2.1 模型构建及患者临床资料比较
经过自动分类器筛选,最终确定C&R算法最佳。C&R树是个组合,包括分类树和回归树,目标变量为分类变量时使用分类树,以Gini系数来确认分割点,为连续型变量时则使用回归树,以方差来确认分割点。决策树包括种树和修建2个环节,模型参数设置包括构建单个决策树,最大树深度为5层,修建树以防止过度拟合。中止规则为父分支使用最小记录数2%,子分支为1%。两组患儿居住地、发热时间、体温、白细胞、中性比率、血糖、精神差、嗜睡、易惊、肢体抖动、呕吐、寒战及咽部疱疹比较,差异有统计学意义(P<0.05)。见表1和图1~3。
2.2 模型结果
C&R算法构建的决策树共包括3层7个节点,其中终末节点共有4个。模型共纳入3个解释变量:易惊、呕吐及肢体抖动。决策树生成原理第一步为训练样本集生成决策树的过程,第二步为决策树的剪枝过程,以新的测试数据为对象进行模型的修建过程,即总样本被分为训练和测试2个数据集,图中节点0的总数603例即为训练样本大小,而图中未显示的测试样本量为235例。Gini系数作为分割点,它代表了目标变量组间的差异程度,其系数越小,组间差异越大。从根节点出发,计算每个节点的Gini系数,然后再计算1个系数的变化量,代表了异质性的下降,反应到决策树的图形上,显示为改进等于系数变化量。决策树从上往下分支,可以看到改进越来越小。从生成的预测变量重要性图中可以看出,HFMD的分组与肢体抖动、易惊以及呕吐相关,而与其他变量则关系不大,再次验证了决策树模型的纳入变量选择。见图1~3。
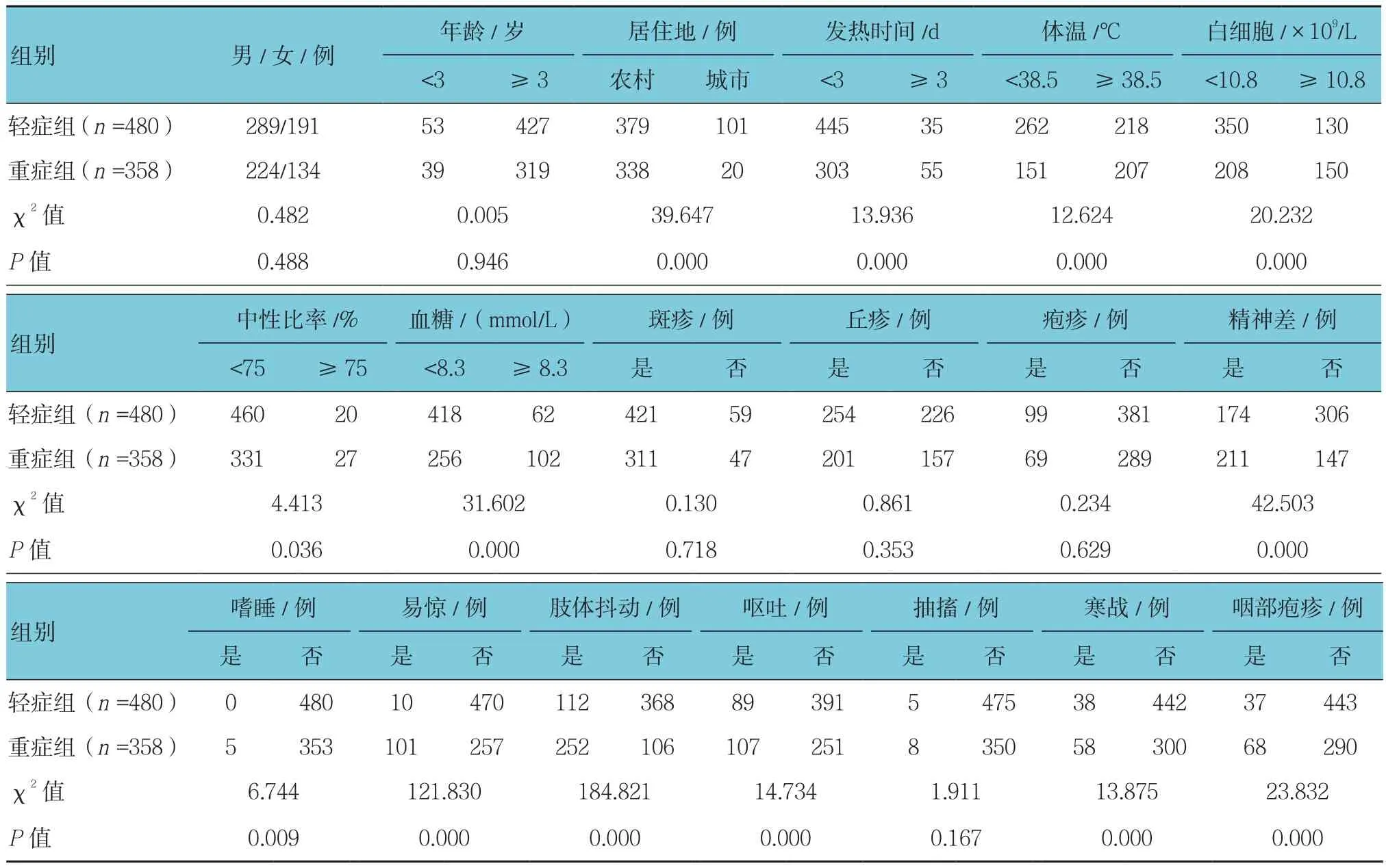
表1 患者的临床资料比较

图1 C&R算法决策树
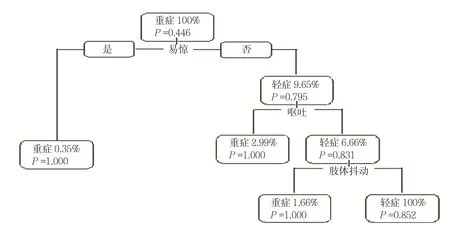
图2 简易决策树
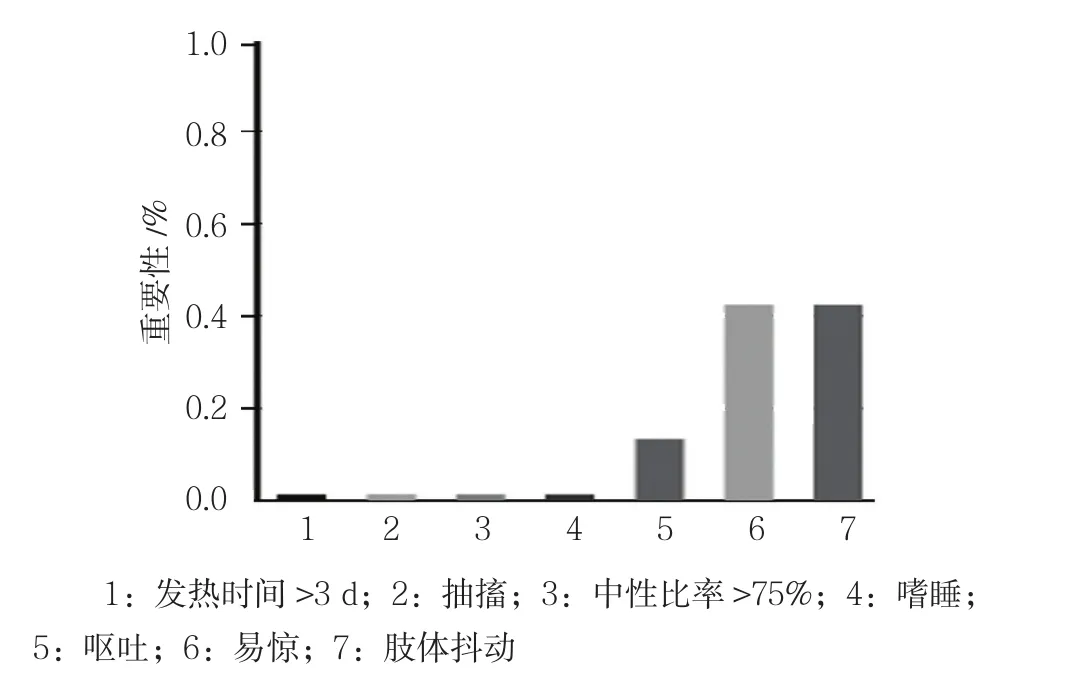
图3 预测变量的重要性
2.3 模型拟合效果
为了评价决策树模型的整体拟合效果,绘制模型累计收益图,在前期快速达到较高点后,快速趋于平稳,而本研究构建的决策树模型可以看到距离理想模型参考线较为接近;根据模型的预测结果绘制ROC曲线图,其曲线下面积为0.903[(95%CI:0.878,0.927),P=0.000]。模型的预测的准确性为91.17%,敏感性为84.36%,特异性为96.25%,见图4、5。

图4 C&R决策树模型的累计收益率

图5 C&R决策树模型的ROC曲线图
3 讨论
近年来,机器学习、人工智能等数据挖掘领域新兴技术蓬勃发展,随着大数据时代的到来,对庞大数据的处理分析也变得更为复杂和关键[4-5]。借助统计建模等领域与大数据端口的联结,可以通过分析数据提供决策向导,及时应对复杂的变化。决策树作为建模的一种算法,在处理分类问题方面具有精确性高、输出结果容易理解等优势[6]。
目前,国内关于手足口病方面的临床研究,较为常见的是使用Logistic回归模型来筛选变量,预测病情[7-10]。Logistic回归属于一种参数统计,其主要用于解决探讨危险因素以及预测发生概率等问题[11]。它属于一种线性模型,在分析主效应方面占优,但是无法处理各种变量的交互效应以及模型过度拟合的问题。而决策树属于非参数统计,可以很好地弥补Logistic回归模型的不足[12]。在处理交互相应方面较佳,能有效地避免模型的过度拟合,提升模型预测精确性的同时,提高适用广度[13]。此外,分类树模型可以很好地处理缺失值的情况,通过优化的算法,使得模型在实际使用中更高效便捷。本研究通过回顾性分析临床收集的患者资料,建立决策树模型,从众多待分析变量中筛选出预测变量,最后对模型进行评估,模型预测准确性为91.17%,提示模型拟合效果较好。隋美丽等[14]的研究显示通过决策树筛选出精神差、手足抖动、易惊及热峰≥39℃共4个解释变量,预测准确性为95.5%。ZHANG等[15]的临床研究通过更高级的迭代决策树算法,构建的模型预测准确性为92.3%。可以看出决策树模型在预测HFMD方面有一定的优势。本研究尚有一定不足,由于样本量偏小以及患者搜集时存在局限性,研究的人群能否很好地代表整体特征,以及模型的适用范围仍有待验证。任何模型都有其优势和不足,由于实际数据的复杂多样性,一种模型很难完全胜任,往往需要多种模型协调联合,通过优势互补,发挥功能。
综上所述,本研究提供了一种新的思路,通过决策树模型共纳入3个解释变量:易惊、呕吐及肢体抖动,模型预测精确度较高,对临床疾病诊疗有一定的辅助价值。后续仍需更多研究的深入开展,以挖掘出更佳算法,构建更优模型应用于临床,为重症手足口病的诊疗及预防做出更大的贡献。
猜你喜欢
四川大学学报(自然科学版)(2023年1期)2023-04-29 00:44:03
榆林学院学报(2022年4期)2022-08-02 14:30:42
中国生殖健康(2020年7期)2021-01-18 03:02:20
幼儿园(2020年18期)2020-12-30 11:58:02
家庭医学(下半月)(2020年7期)2020-08-24 07:47:00
成都信息工程大学学报(2019年3期)2019-09-25 08:31:20
电子制作(2018年16期)2018-09-26 03:27:06
计算机与生活(2018年8期)2018-08-15 08:24:34
中央民族大学学报(自然科学版)(2016年4期)2016-06-27 08:06:04
理科考试研究·高中(2016年9期)2016-05-14 00:12:18
