
基于ELM-KNN算法的网络入侵检测模型
2018-08-17 03:15:34顾兆军
计算机工程与设计 2018年8期
顾兆军,李 冰+,刘 涛
(1.中国民航大学 信息安全测评中心,天津 300300; 2.中国民航大学 计算机科学与技术学院,天津 300300)
0 引 言
BP神经网络作为传统神经网络的一种,凭借较强的非线性拟合能力、可映射任意复杂的非线性关系等特性,在入侵检测领域得到很好的应用,但BP神经网络存在训练时间长、易陷入局部极小等问题[1-5]。基于统计学习理论的支持向量机(support vector machine,SVM),相对于传统神经网络泛化能力得到很大提高,且对于小样本网络入侵检测问题具有较高的检测率,但SVM需人为指定核函数及参数,并且处理大规模样本存在效率低等问题[6-8]。极限学习机(extreme learning machine,ELM)是由Huang等[9,10]提出的新型单隐层前馈神经网络(single-hidden layer feed forward networks,SLFNs)。它克服了传统神经网络训练速度慢,易陷入局部最小等缺点,无需迭代调整参数,具有更好的泛化能力和更快的训练速度,但存在过拟合现象。K最近邻算法(K-nearest neighbor,KNN)采用投票机制,有效避免了过拟合现象。AK Alshamiri等[11]提出了用于聚类的新型极限学习机K均值算法,实验结果表明ELM与K均值算法的集成,提高了聚类质量。随后,卢诚波等[12]提出了基于ELM特征映射的K最近邻算法,并通过实验验证了该算法在分类领域的优良性。
本文将ELM特征映射的KNN算法应用于入侵检测模型,通过仿真实验,验证了模型的有效性。
1 ELM-KNN算法
1.1 KNN算法
假设样本集样本有n个属性,每个样本用n维空间中的一点表示,通过判别与待分类样本最接近或最相似的K个已知类别标签的样本类别,确定该样本的类别。K个相邻样本是通过距离来判断,比如:两个点或者元组X1=(x11,x12,…x1n)和X2=(x21,x22,…x2n)的欧几里得距离为
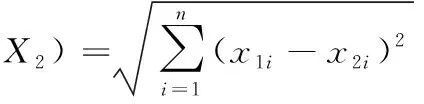
(1)
KNN算法的基本步骤如下:
(1)计算未知样本和每个训练样本之间的距离dist。
(2)将得到的未知样本和训练样本之间的距离进行排序,根据距离找出最接近未知样本的K个最近邻样本。
(3)统计K个最近邻样本中每种类别出现的次数。
(4)选择出现频率最多的类别作为未知样本的类别。
KNN算法达到良好分类效果的前提,要求样本之间的距离呈现椭圆形或者超球形,如果样本集的分离边界是非线性的,分类效果可能不佳,因此,为了达到良好的分类效果,可以将低维输入空间中复杂线性不可分的样本投影到高维特征空间,在高维特征空间中对样本进行分类。在使用SVM进行特征映射时,存在容易产生次优解以及计算量过大等缺点[13]。极限学习机与SVM相比有自己独特的优点,具有更高的泛化性和更好的可扩展性。
1.2 极限学习机
与传统前馈神经网络相比,极限学习机训练过程中随机生成隐含层权重以及偏差,无需调整参数,并且其隐含层和输出层的权重通过最小二乘法计算得到,因此极限学习机训练速度以及泛化能力均好于传统前馈神经网络。极限学习机学习模型如下:给定N个训练样本集{(xi,ti)|xi∈Rd,ti∈Rm,i=1,…N},具有L个隐层神经元且激活函数为g(x)的SLFNs的输出为
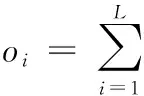
(2)
其中,ω=[ωi1,…,ωid]T、β=[βi1,…,βim]T分别是ELM算法执行过程中随机生成的权重向量,ω是隐含层神经元和输入神经元的输入权重,β是连接隐含层神经元和输出神经元的权重,bi是随机生成的第i个隐含层神经元的偏差。ωi·xi为ωi和xi的内积。本文通过实验,选择Sigmoid函数作为激活函数,设变量为t,则该函数为
(3)
要使得具有L个隐层神经元且激活函数为g(x)=(ωi·xi+bi)的SLFNs零误差逼近N个样本,需使式(4)成立
(4)
即存在βi、ωi、bi使式(5)成立
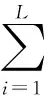
(5)
式(6)可表达为
Hβ=T
(6)
其中
H=
(7)
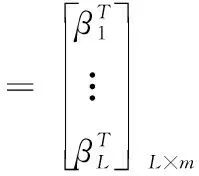
(8)
(9)
其中,H表示隐含层输出矩阵。
综上所述,给定N个训练样本,具有L个隐层神经元,激活函数为g(x)的单隐层前馈神经网络算法的基本步骤如下:
(1)随机生成输入权重向量ωi和隐层神经元的偏置bi,i=1,…,L。
(2)计算隐层输出矩阵H。
(3)计算输出权值β
β=H+T
(10)
式中:T=[t1,…,tN],H+是隐层输出矩阵H的Moore-Penrose广义逆。
2 基于ELM-KNN的入侵检测模型
鉴于ELM单隐层前馈神经网络以及KNN算法的各种优良性能,将其引入到入侵检测模型中。极限学习机训练过程中随机生成隐含层参数以及利用最小二乘法计算输出权重,使得学习速度得到了很大的提高,克服了梯度下降算法的一些缺点。但激活函数的选择、隐含层节点数的分配等问题,可能使ELM训练过程中产生非优化节点,影响ELM的泛化的能力。因此相比于传统的参数调整型神经网络,ELM算法要更加合理的选择激活函数以及隐含层节点数目。本文将KDD Cup99数据集分为测试集和训练集,将训练样本放入模型中进行训练,最后再对测试样本进行测试,判断属于哪类攻击。
假设样本集为:X={(xi)|xi∈Rd,i=1,…,N},样本集通过ELM单隐层前馈神经网络的映射函数φ将x向量映射到L(L>>d)维特征空间F中
φ:Rd→F
(11)
ELM的典型结构如图1所示。

图1 ELM典型结构
对映射到高维特征空间中的向量执行KNN分类算法。将ELM-KNN算法用于入侵检测中的流程如图2所示。

图2 ELM-KNN算法的入侵检测流程
ELM-KNN算法具体步骤总结如下:
给定样本集X={(xi)|xi∈Rd,i=1,…,N},单隐层前馈神经网络的激活函数为g(x),隐含层节点数为L。
(1)随机生成隐含层权重ωi以及偏差bi。
(2)通过实验选择合适的激励函数。常用的激励函数有Hardlim函数、Sigmoid函数、Sine函数等。
(3)通过实验选择最佳的隐含层节点个数。ELM算法可以在一个较大的隐含层节点范围内取得同样小的验证误差,但是隐含层节点数超过一定的数量会影响训练时间和测试时间,甚至导致模型过拟合[9]。因此,为了得到一个准确的模型结构,本文通过实验对比,选择合适的隐含层节点个数。
(4)实验选择KNN算法中的近邻数。KNN算法中参数K的选择直接影响到分类结果的好坏。
(5)利用ELM将样本数据xi映射为
G(xi)=g(ωi,bi,x)
(12)
(6)对映射到高维特征空间中的向量执行KNN分类算法。
(7)若G(xi)属于第j类,则原始样本属于第j类。
3 实验研究
3.1 实验数据及实验环境
为了测试基于ELM-KNN算法的入侵检测模型的性能,在Intel(R) Core(TM) i7-3770 3.40 GHZ CPU、4 G内存,Windows 7操作系统,Matlab R2013a软件环境中,采用KDD Cup99数据集[14]实现仿真实验。该数据集分为四大攻击类型:Probe(端口扫描与探测)、Dos(拒绝服务攻击)、R2L(远程机器的非法访问)和U2R(对本地超级用户的非法访问),Normal表示正常访问。原始数据数据量庞大,并且每条记录包括41个特征属性(具体见表1),因此选择其中一部分作为实验数据[15]。训练集和测试集的样本见表2。
3.2 实验结果与分析
3.2.1 冗余特征的筛选
对特征属性较多的样本采用KNN算法分类时,可能会因特征属性过多,造成计算量变大,影响分类效果。样本中是否存在冗余特征也是影响入侵检测效率和正确率的重要因素之一。KDD Cup99数据集的41个特征中,有些特征对分类效果没有太大的影响,反而只会降低入侵检测的分类效率,甚至导致分类结果出现偏差。因此,为了提高入侵检测的效率和正确率,对KDD Cup99数据集的样本特征属性进行筛检。图3为K=5时,样本集不同数量属性特征的入侵检测正确率。
由图3可得,KDD Cup99的样本存在冗余属性。特征属性个数从2增加到10时,检测率呈现快速增长趋势;当特征属性为10的时候,模型已经具有较高的检测率;特征属性个数从10增加到25时,检测率趋于稳定;当特征属性个数大于25时,检测率呈现出不稳定的趋势。据此本文仿真实验采用13个特征属性,以提高入侵检测的正确率。

表1 KDD Cup99的特征

表2 数据描述

图3 不同特征子集的入侵检测正确率
3.2.2 KNN算法的K值的选择
近邻数K的取值问题,直接影响到KNN算法分类效果的好坏。关于K值的选择,K的值从1开始逐渐增加,观察K值的变化对入侵检测正确率的影响,结果如图4所示。
由图4可知,当K值从1增加到3时,入侵检测正确率大幅度增加,当K值从3增加到5时,入侵检测正确率增加幅度减缓,当K值等于5时,达到最大的入侵检测正确率,当K值大于5时,入侵检测正确率逐渐降低,据此,本文实验近邻数K的取值为5。

图4 不同K值下的入侵检测正确率
3.2.3 ELM隐含层节点个数和激励函数的选择
由极限学习机的工作原理可知,隐含层节点个数和激励函数的选择对ELM泛化性能以及分类精度影响较大。图5给出了3种不同激励函数(Sigmoid函数、Sine函数、Hardlim函数)在隐含层节点个数的影响下,入侵检测正确率的变化。由图5可以得出,Sigmoid函数、Sine函数、Hardlim函数无论在数值上还是变化趋势上都有很好的一致性,且3条曲线在隐层节点个数为500的时候,入侵检测正确率达到最高。由图可见,Sigmoid函数在隐含层节点个数达到500的时候,入侵检测正确率最高,基本上稳定在95.33%。因此,为了得到一个更加适合的模型结构,本文隐含层节点个数选取500,激励函数选取Sigmoid函数。
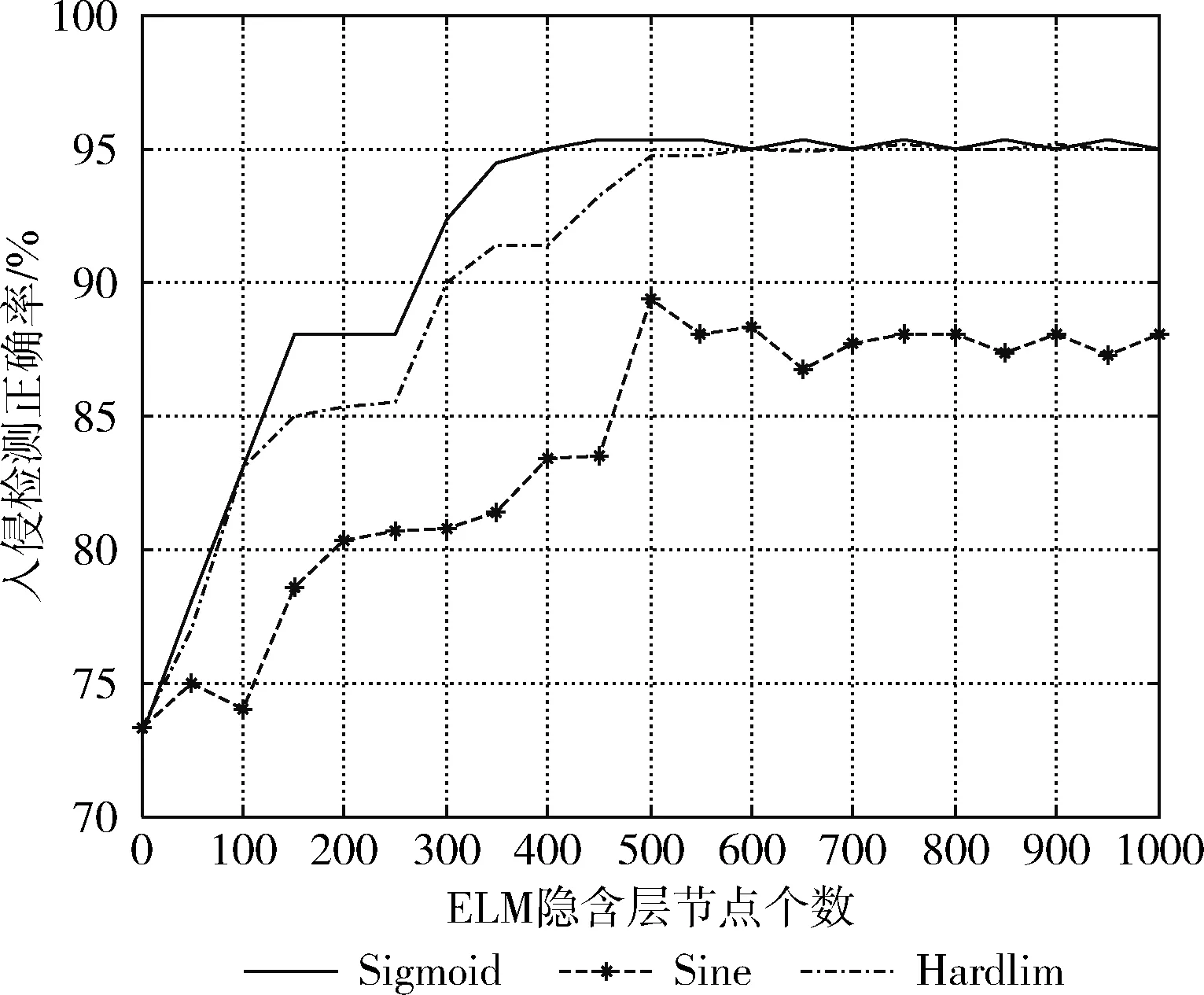
图5 不同激励函数在隐层节点个数变化下的入侵检测正确率
3.2.4 结果与分析
为了使基于ELM-KNN算法的入侵检测模型的检测结果有对比性,采用未进行高维映射的KNN的检测模型、BP神经网络、Kernel-KNN的检测模型以及只使用ELM算法分类的检测模型作为对比模型。
将训练样本分别输入到BP、KNN、ELM、Kernel-KNN模型中进行学习,本文通过对比正确率、误报率、漏报率3个指标来评价模型

(13)

(14)

(15)
通过对表3~表5进行分析,可以得到如下结论:
(1)相对于Kernel-KNN、BP、KNN、ELM,ELM-KNN的网络入侵检测正确率较高,有效降低了误报率、漏报率。相对于ELM算法,平均检测正确率大约提高了5.45%,提高的幅度最大。
(2)ELM-KNN算法较BP神经网络的入侵检测正确率高,是由于BP神经网络存在易陷入局部极小等缺点;ELM-KNN算法相比于KNN算法入侵检测正确率较高,主要是因为ELM-KNN算法将低维空间复杂线性不可分的样本数据投影到高维特征空间中,使得样本变得线性可分,从而提高了网络入侵检测的正确率;ELM-KNN算法相比于Kernel-KNN算法,具有更好的泛化性能和分类能力,能更加逼近目标函数;ELM-KNN算法的网络入侵检测率完全优于ELM算法的检测率,是因为ELM算法采用最小二乘法计算,会出现过拟合现象,而KNN算法采用的是投票机制,不会出现过拟合现象。
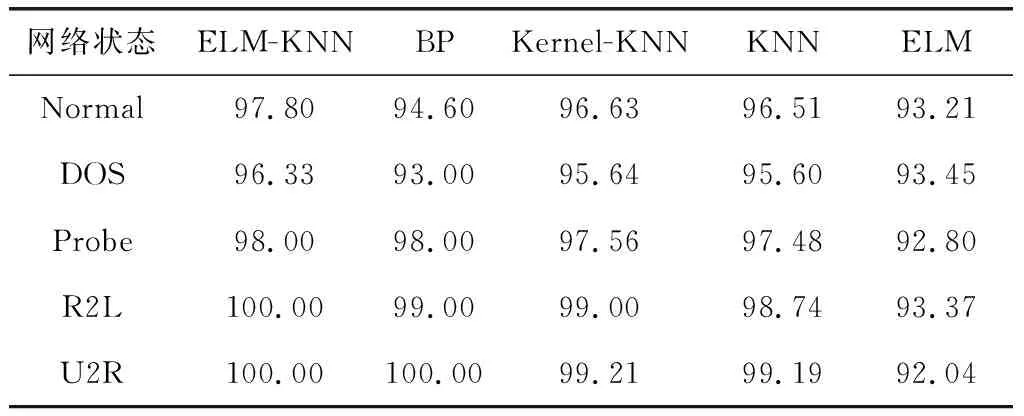
表3 不同模型的检测正确率对比/%
4 结束语
针对传统神经网络算法存在易陷入局部最小、人工参与调节参数过多、泛化能力差等缺点,本文提出了基于ELM-KNN算法的网络入侵检测模型,建立入侵检测分类器。ELM算法具有泛化能力强、学习速度快等优点,但易出现过拟合现象,采用投票机制的KNN算法能有效避免过拟合现象,思路简单,易于实现。结果表明,相比于与BP神经网络、KNN算法、ELM算法以及Kernel-KNN算法,ELM-KNN算法在入侵检测中具有更高的准确率。

表4 不同模型的误报率对比/%
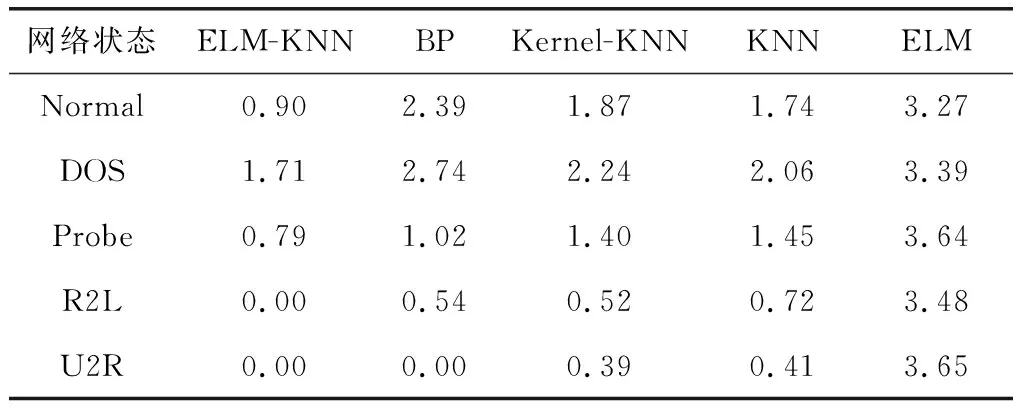
表5 不同模型的漏报率对比/%
猜你喜欢
数学小灵通(1-2年级)(2021年4期)2021-06-09 06:25:56
中华养生保健(2020年7期)2020-11-16 01:14:26
电子制作(2019年19期)2019-11-23 08:42:00
中学生数理化·七年级数学人教版(2019年4期)2019-05-20 10:06:32
中学生数理化·七年级数学人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年级(2017年9期)2017-10-13 22:27:46
家教世界·创新阅读(2016年11期)2016-12-27 18:49:15
天津护理(2016年3期)2016-12-01 05:40:01
故事会(2016年15期)2016-08-23 13:48:41
重型机械(2016年1期)2016-03-01 03:42:04
