
火电厂设备状态监测与故障预警的研究
2018-08-15 08:36谢小鹏林玥廷林英明
综合智慧能源 2018年6期
谢小鹏,林玥廷,林英明
(1.湖南大唐先一科技有限公司,长沙 410007; 2.广东电网公司电力调度控制中心,广州 510600)
0 引言
近年来,全球有许多设备状态监测与故障诊断领域的、以大数据机器学习算法为热点和方向的研究。通过大数据机器学习算法,对火电厂设备健康状态的样本进行学习和预测,将提升设备状态监测、评价与诊断的及时性与准确性,并提高设备维护员的工作效率,改变设备维护员的工作模式。采用信息化的技术手段,可利用设备状态参数进行监测和分析,判断设备是否存在早期异常并对出现异常的部件和异常原因进行诊断。这对全面掌握劣化趋势、及时维护和检修、提高设备的可靠性和安全性十分必要[1-2]。
1 传统火电厂设备状态监测与故障预警的缺陷
传统火电厂的设备运行监测方式主要为关注定值报警,而较少关注参数的波动范围或劣化趋势。当设备发生参数报警、热工保护动作时,设备已经发生了明显的劣化与故障。传统的设备状态评估主要依赖设备管理人员的主观经验来判断,而非海量的历史数据,许多机组隐患不能及时被发现和处理。传统的设备故障诊断主要依赖外部专家,缺少对以往诊断经验的积累、交流与学习,缺乏诊断经验积累的支撑平台[3]。
2 设备劣化与故障预警算法研究
2.1 GMM算法介绍
GMM,即用高斯概率密度函数精确地量化事物,将一个事物分解为若干的基于高斯概率密度函数(正态分布曲线)形成的模型。在概率统计中,任意形状的概率分布都可以用多个高斯分布函数去近似,其参数求解方法一般为使用极大似然估计求解。在混合高斯模型中,权值、高斯模型的期望值和方差为模型决定参数。
2.2 K-means算法介绍
K-means算法是最为经典的基于划分的聚类方法,是十大经典数据挖掘算法之一。K-means算法的基本思想是以空间中k个点为中心进行聚类,对最靠近他们的对象归类。通过迭代的方法,逐次更新各聚类中心的值,直至得到最好的聚类结果。
2.3 两种算法比较
(1)K-means 算法优点为算法快速、简单,对大数据集有较高的效率并且具有可伸缩性;缺点为需要根据初始聚类中心来确定一个初始划分,然后对初始划分进行优化,在K-means 算法中多维空间相似性度量基于欧氏距离进行计算,并不能准确反映多维空间点中的相似情况。
(2)GMM优点:适用性广,多维空间中聚类效果好;引入概率分布,算法简单、迭代方法有效且稳定。缺点:计算速度慢;模型初始化困难,权值(a0)、均值(μ0)、方差(σ0)较难确定;由于迭代算法是局部最优解算法,虽然能保证收敛后达到局部最大点,但并不能保证收敛到全局最大点,聚类结果受初始值a0、μ0、σ0影响较大。
2.4 两种算法结合应用
结合上述两种算法优缺点,可先采用K-means 算法得到结果,转换为GMM的初始值。K-means 算法在对设备状态原始数据进行较为粗略的分类时效率较高。 采用K-means算法对EM(最大期望)算法进行初始化,会显著提高EM 算法的收敛速度,提高最终分类结果的准确率[4]。计算过程为: 使用K-means计算得到的中心点作为高斯模型初始期望μ0;同组工况点协方差得到高斯模型初始均方差σ0;同组包括的样本点占总样本的比例为高斯模型的初始权值。计算具体流程见图1。
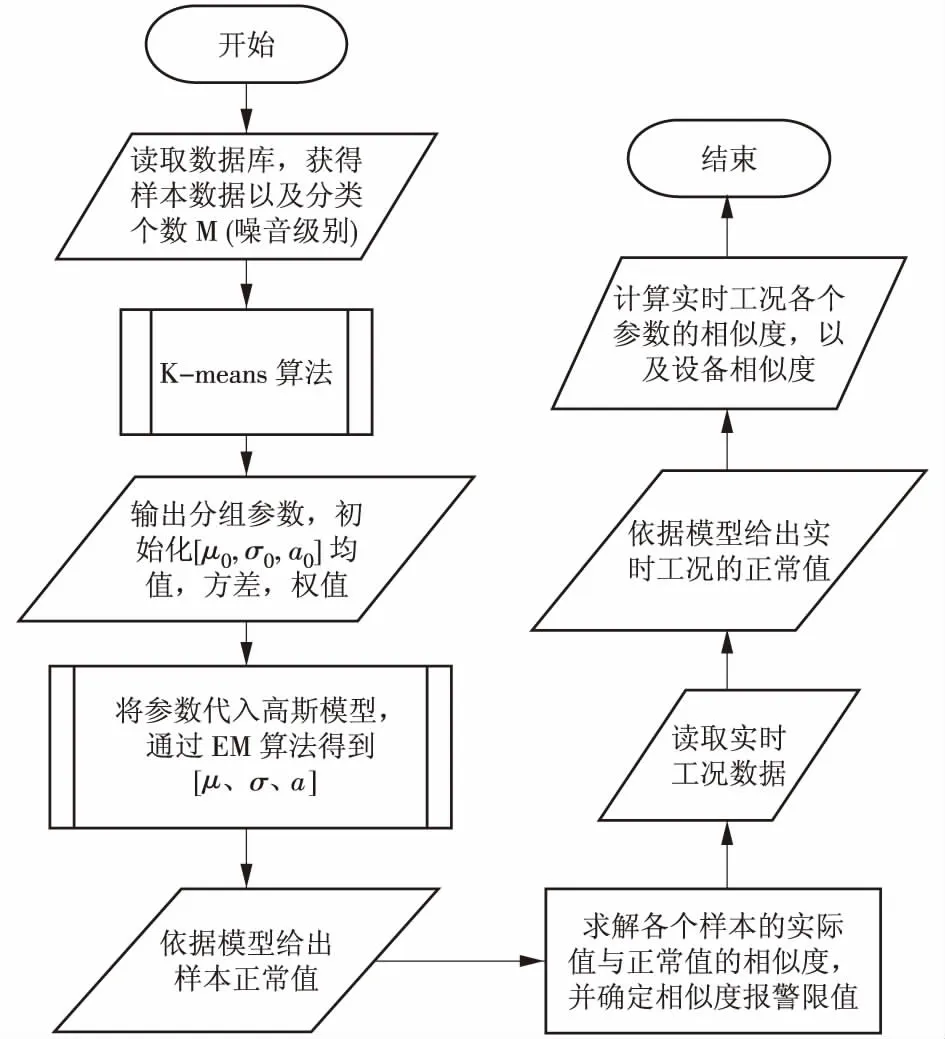
图1 总体流程
2.5 两种算法结合应用示例
以“前置泵电机模型”测试数据中的前8 000条数据作为训练样本,共得到11维、8 000多个样本点。以“前置泵电机模型”的样本数据表的后1 000个样本点为实时测试数据。整个计算通过MATLAB工具编码实现,高斯混合模型个数设定为100个,计算结果形成的趋势图如图2、图3所示。
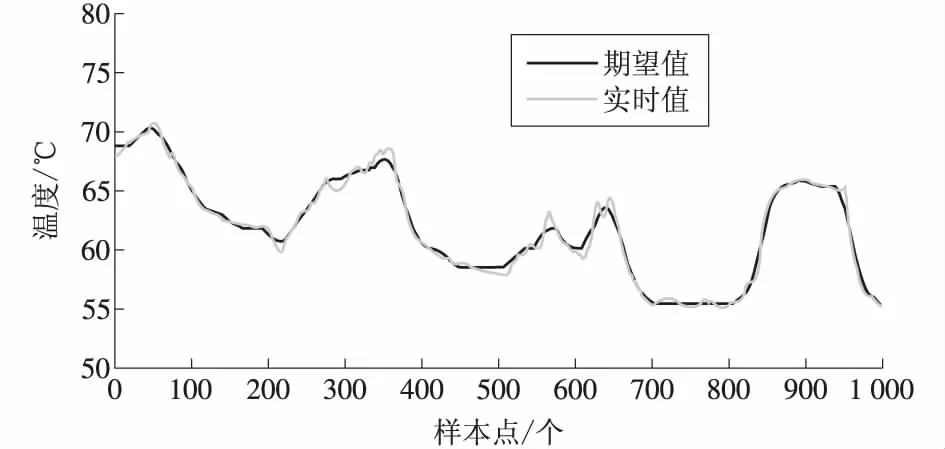
图2 前置泵电机绕组温度实时值与期望值趋势
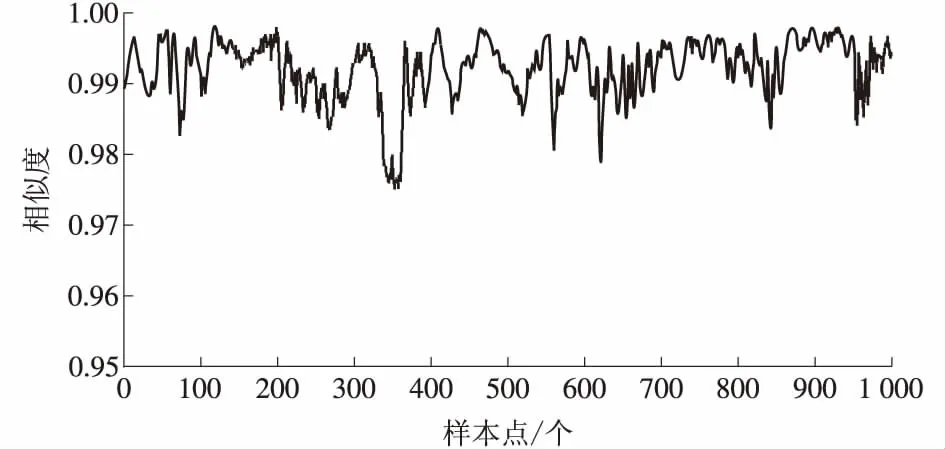
图3 前置泵电机运行相似度趋势
3 系统总体设计
3.1 研究目标
(1)充分挖掘、利用实时和历史数据的价值,采用数学方法,建立实体设备的数学模型并实时监测计算,在设备出现早期异常时进行预警,便于客户及早发现和消除故障隐患,从而降低设备故障率。
(2)提供模糊匹配和基于规则的设备智能诊断,及时发现和消除设备隐患,使用机组的被动检修变为主动检修,优化检修策略,提高机组安全性、可靠性,降低电厂的检修费用,提高机组的运行性能,从而提高电厂的经济效益。
(3)通过提供设备故障统计报告,在机组大修或小修前评估设备的健康状况,逐步实现设备的状态检修。
(4)建立企业自身的知识库,为设备管理和生产运行人员积累诊断经验提供基础平台。通过故障模式库,实现对设备潜在故障进行初步诊断;通过知识库,提供对类似情况的参考案例,以便辅助诊断。
3.2 设计思路
系统基于REAP4.0平台,研发了B/S结构的可扩展设计思想,并结合SOA(面向服务的体系结构)思想,实现即插即用的模块组件化。系统基于设备监测参数,针对电厂设备、设备群或系统,建立实时算法模型。依据大量历史数据中隐含的参数关联性、耦合性以及设备正常运行的样本数据,建立基于神经网络算法的参数正常值预测模型,实现了基于规则的设备故障诊断及运行指导,为设备管理和生产运行人员积累诊断经验提供了基础平台。
3.3 系统架构设计
系统采用面向服务SOA+B/S体系架构设计,系统设计采用成熟的三层结构,分为数据层、中间层和应用层,具体架构如图4所示[5]。数据层:数据采集接口采用标准网络通讯协议,将DCS(分布式控制系统)及其他控制系统的实时数据采集并到实时与关系数据库。中间层:基于REAP 4.0、RTDB平台,完成模型建立、模型训练、参数评估、分层评估以及潜在故障预警等数据处理环节,是系统模型运算与业务处理的核心层。应用层:系统配置管理及功能应用部分,主要包括设备状态监视、设备故障预警定位、设备故障分析、设备健康状态评价等应用。
3.4 技术要求
(1)数据采集与计算周期:原始实时数据采集周期≤1分钟;计算周期≤1分钟。
(2)模型配置与参数要求:根据电厂监测要求及训练情况,建立监测模型,建议单台机组模型不超过80个;每个监测模型的参数可以根据监测目的来选择,个数没有要求,但选择与模型监测目的无关的参数将影响模型预警结果准确性。
(3)训练样本要求:模型训练应保证正常运行时段四季的样本数据,可从不同季节中选择典型月份,再从中筛选正常标准运行数据;样本数据越全面,模型预警准确性越高,建议样本条数在8 000条以上[5]。
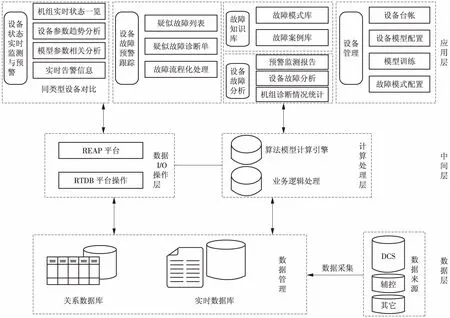
图4 系统架构图
3.5 技术亮点
(1)利用数据挖掘技术,从大量历史数据中挖掘出隐含的参数关联性、耦合性,建立基于神经网络算法的回归模型,实时预测给出监测参数的正常值。
(2)采用数据准确性甄别技术,主动地发现测点异常,为控制部和运行部提供实时和历史的测点异常清单,辅助热工测量维护工作。
(3)采用多重告警模式,实现了设备早期劣化或故障报警提示,电厂技术人员和管理人员能更高效地发现设备的异常,有助于设备状态检修。
(4)采用分层级评价方法,从安全性、经济性角度分析,评价设备参数组的状态依次得出设备、系统、机组的健康状态。评价依据充分,结果可靠。
数据准确性甄别提高了设备监测原始数据的可靠性与准确性。数据准确性甄别技术已经获得了国家发明专利,且在国内电网节能环保智能一体化系统与SIS(安全仪表系统)产品中得到了广泛应用。
4 应用效果
4.1 经济效益分析
以某电厂4×300 MW机组为例,本项目一次投入大约为100万元。系统投入使用1年后取得经济效益如下。
(1)减少人力资源投入。按每1台机组可以减少巡检员1名,1名职工支付年工资约6万元,1年该电厂4台机组共节约人力成本约24万元。
(2)减少设备检修及备件费用。根据行业统计数据,由于监控不到位、发现不及时,每年将造成4次以上辅机、轴瓦等设备损坏,直接经济损失约10万元/次,1年可减少费用40万元。
(3)减少降出力。根据电力可靠性指标发布数据显示,非计划停运次数平均为0.48次/台年,非计划停运年平均值为33.00 h/台。若系统能在设备发生异常前提前报警,保守估计1台300 MW机组每年减少一次“降出力”事件。若降出力负荷为机组额定负荷的20% ,即60MW,降出力时间为20 h,1年将能挽回降出力经济损失约104万元。
综上所述,此电厂总计1年的经济效益约168万元。
4.2 社会效益
(1)本产品的应用,为发电行业设备状态监测、诊断系统的应用提供了一个标杆,特别是基于大数据机器学习算法,改变了传统的依靠人员管理经验进行设备状态监测与诊断方法;
(2)设备点检长、点检员对于设备状态监测与评估有据可依、有记录可查,日常工作量和工作压力得到降低,工作效率至少提高20%;
(3)帮助火电厂提高了设备劣化、缺陷的监测与故障诊断水平,从而提高发电设备可靠性,减少机组非计划事件的发生[6-7]。
5 结束语
本文以火电厂设备状态监测与故障预警为研究对象,重点研究了系统设计中的高斯混合算法与K-means算法结合应用的方法,并详细介绍了系统总体设计,分析了设备状态监测与诊断在电厂的应用效果。通过建立该系统,电厂可实时掌握设备劣化与故障情况,为电厂机组设备的安全与稳定运行提供参考依据。
猜你喜欢
大电机技术(2022年3期)2022-08-06
河北电力技术(2021年2期)2021-07-29
水泵技术(2021年6期)2021-02-16
小学生作文(低年级适用)(2019年5期)2019-07-26
军事文摘(2018年24期)2018-12-26
能源(2018年6期)2018-08-01
能源(2018年6期)2018-08-01
通信电源技术(2018年3期)2018-06-26
读友·少年文学(清雅版)(2018年12期)2018-04-04
山东青年(2016年3期)2016-02-28
