
云数据存储技术在气象数据存储中的应用
2018-08-15 08:02:34吴京生胡永亮
计算机应用与软件 2018年8期
陈 晴 杨 明 肖 云 吴京生 滕 舟 魏 爽 胡永亮 庞 俊
1(浙江省气象信息网络中心 浙江 杭州 310017)2(武汉科技大学计算机科学与技术学院 湖北 武汉 430065)
0 引 言
随着气象业务现代化建设的深入,气象已进入大数据时代,表现在以下几方面:1) 数据体量巨大,数据量达到PB级,不断增加的数据量需要存储容量能动态扩展;2) 数据种类繁多,既有地面、高空、卫星、雷达等监测数据,又有多种数值预报产品以及各种气象服务产品[1];3) 数据响应速度要求快,从大量的气象数据中获取有效的信息是气象服务的迫切需求[2]。
云存储技术通过集群应用、网格技术和分布式文件系统等技术手段,让网络中大量各种不同类型的存储设备在应用软件的管理下协同工作,共同对外提供数据存储和业务访问功能[3-4]。
根据气象部门对气象数据的要求,对云数据存储方法进行研究和探索,针对气象数据的特点设计并实现了一套基于云分布式存储技术的数据存储方法,利用云计算的分布式存储和并行化处理海量数据,为气象大数据的存储和计算提供支撑。
1 气象数据云存储的总体设计
1.1 云存储平台整体架构
基于云分布式存储技术的数据存储重点在于解决海量气象数据的存储和处理问题,提高用户的访问效率。云存储平台整体架构划分为4个层次,自底向上依次是:数据存储层、存储管理层、业务服务层与用户访问层[5],见图1。
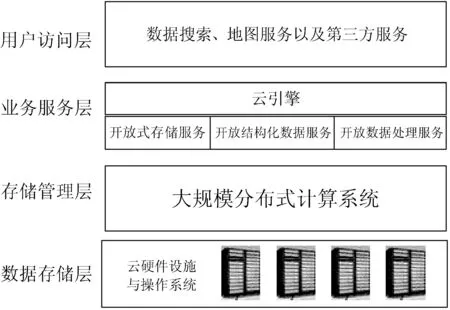
图1 云存储平台整体架构
数据存储层主要包括服务器集群以及将集群连接起来的物理链路,实现数据的统一管理。考虑到设计的云存储平台需可扩展性强、可靠性高、成本尽量低等特点,同时存储设备要便于集中管理[6-7],方案中统一选择X86服务器构建普通机器集群,操作系统选择Linux操作系统。
存储管理层主要包括大规模的分布式计算系统,负责管理集群系统资源以及资源的虚拟化、控制分布式程序运行、隐藏下层故障恢复、数据冗余、数据备份和数据容灾等细节,有效地提供弹性计算和负载均衡的服务。
业务服务层采用云分布式服务技术,将不同的数据存储和计算功能分解成各种微服务,实现大规模数据的存储共享、查询及处理服务。在此之上的云引擎为第三方云应用提供了弹性、低成本的运行环境,帮助简化云应用的构建和部署。
用户访问层通过用户授权、认证机制,使用户对数据进行特定权限范围的操作。这一层具体包括一些数据搜索服务、地图服务以及第三方服务。
1.2 气象数据的组织
根据数据结构的差异,气象数据主要可分为离散型数据、网格数据、栅格数据。自动气象站各种气象要素的实时和历史数据,水利、环保、海洋等外部门单位的站点数据以离散型数据形式存在;各种气象要素的网格化产品,数据以网格数据形式存在;云图、雷达以及模式预报的输出产品,数据以栅格数据的形式存在。其中离散型数据属于结构化数据,网格数据和栅格数据属于半/非结构化数据。
1.3 数据存储模型的选择
云数据库是部署和虚拟化在云计算环境中的数据库,在云数据库应用中,客户端无需了解云数据库底层细节,底层硬件都已被虚拟化[8]。云数据库对用户而言就像运行在普通服务器上的数据库一样,但数据的存储、处理能力与传统意义的数据库相比有了质的飞越[9-10]。
考虑到气象数据自身的特点以及数据能够被快速访问的需求,同时气象数据中的实时数据与历史数据是一体化的,因此数据量极为庞大。传统的关系型数据库存储管理系统可以满足数据的一致性和可用性,在小规模数据量时可以达到很好的效应,随着数据量与应用范围的增长导致节点增加,需要考虑数据同步和分区失败等开销,性能会快速下降,因此数据分布式存储是必然选择[1]。
数据分布式存储较常见的有两种形式:分布式关系型数据库和非关系型数据库(NoSQL)。结构化数据采用分布式关系型数据库存储,半/非结构化数据采用NoSQL数据库存储。具体如表1所示。
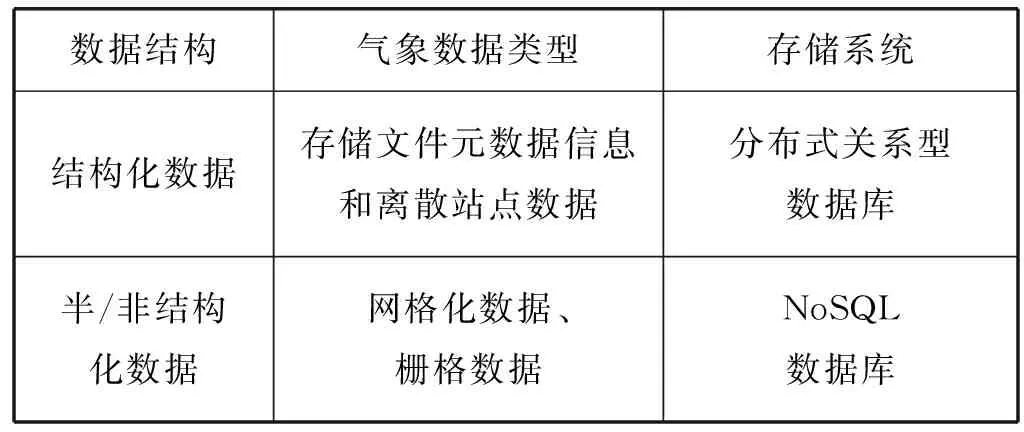
表1 数据的存储模型
2 关键技术
2.1 结构化数据的存储方式
结构化数据采用分布式关系型数据库存储,获取低延迟与高并发吞吐能力。分布式关系型数据库采用传统的表-字段形式存储,将数据表水平拆分到后端的每个分数据库的分表中,分布式关系型数据库中由每个分库负责每一份数据的读写操作,从而有效地分散了整体的访问压力,提高了大型数据的访问效率。
2.2 半/非结构数据的存储方式
半结构数据主要以网格化数据为主,非结构数据以栅格数据为主,这两种数据通常被当作字符串或二进制数据,采用NoSQL数据库存储。NoSQL数据库采用了键值(Key-Value)模型,模型中Key值指向Value的键值。该结构主要分为主键、属性和值三部分,基于值存储的数据相对较大的特点,对数据进行切分与压缩相结合的技术处理可以大幅提升数据传输能力。
2.2.1 主键表及属性列表设计
(1) 网格数据的设计 气象数据中的网格化数据通常Micaps4类格式数据文件的形式存在。Micaps4类格式数据文件包括3个维度的信息:时间、经度和纬度。根据气象要素和查询的时刻能够快速获取到相应的经纬数据。表2为网格数据的主键设计表,表3为数据的属性列设计表。

表2 网格数据主键设计表
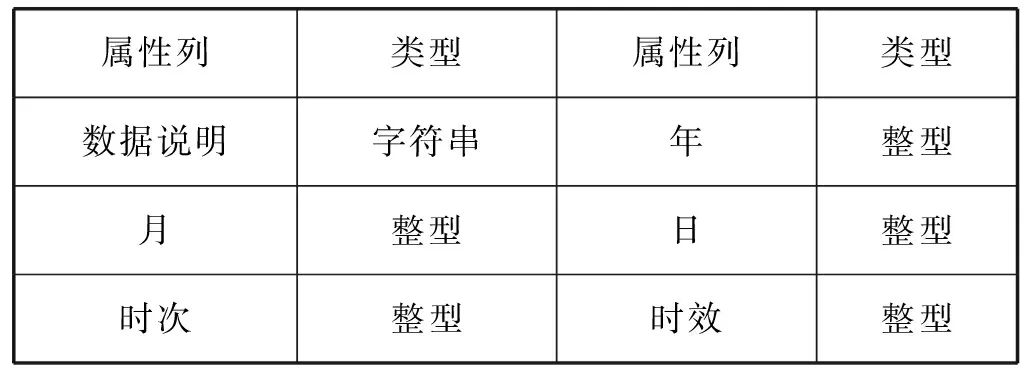
表3 网格数据属性列设计表

续表3
(2) 栅格数据的设计 气象数据中的栅格数据通常以二进制文件的形式存在,这类数据没有对其中某一片段的单独读取需求,通常会读取整个文件进行解析。对于这类数据,每一行只有一个属性列用来存放压缩后的二进制文件数据,整个文件具有较高的压缩比。由于每天产生的文件较多,较为适合压缩后存储在表格存储上。表4为网格化数据的主键设计表,表中主键二为兼容Micaps 4数据格式增加的一列主键,无实际意义,可以恒为0。表5为数据的属性列设计表。

表4 栅格数据主键设计表
表5 栅格数据属性列设计表
2.2.2 半/非结构化数据的分块与压缩技术
半/非结构化数据以网格数据或栅格数据为主,可对数据进行分块与压缩进行存储。NoSQL对象存储一般采用面向列的存储方式,其存储结构保证了数据表列的扩展性及I/O的高吞吐量,避免了表结构改变带来的维护压力,有效提高了数据分析的吞吐性能。
基于半/非结构化气象数据的特点,对属性列的数据进行一定比例的行列切分。切分规则如下:按照行切分成M份,按照列切分成N份,即将数据切分成M×N个方格。假设数据的latitude_point=X,longitude_point =Y,我们使切分后的方格rowsCount=X/M+1, colsCount=Y/N+1,切分后属性列data扩展为M×N个属性列,如表6所示。

表6 属性列数据的分块

2.3 气象数据间的转化
为了提高数据的存储、传输和使用效率,降低数据维护的成本,特别是对数据量庞大、时间序列长的气象数据,根据气象数据类型的不同选择不同的存储系统。将使用频率较高,数据生成时间与当前时次临近的热、温数据存放在在NoSQL对象存储中,如实时的格点数据、栅格数据等;将使用频率较低,数据生成时间与当前时次间隔时间较长的冷数据存放在NoSQL文件存储中,如历史文件数据、长序列数据等;将关系型数据存放在关系结构型存储中,如存储文件元数据信息和离散站点数据等。热、温、冷数据之间的转换策略遵循时间度及数据使用度的原则。各存储系统之间数据的转换如图2所示。
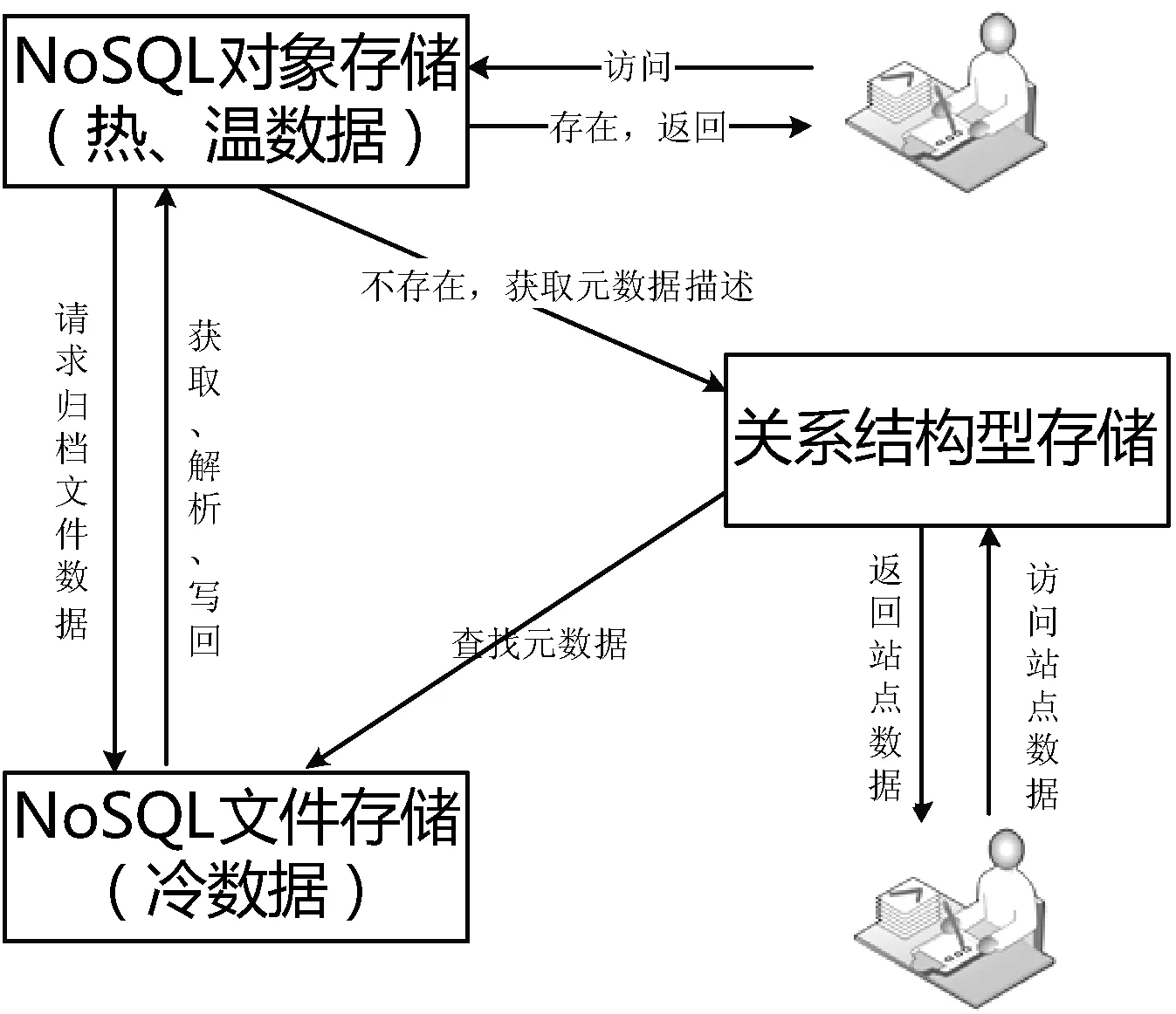
图2 热、温、冷数据之间的转换
3 实验分析
3.1 测试数据集的建立
对结构化数据以及半/非结构化数据在云存储平台上的读取效率进行测试。本文实验采用的数据为雷达降水产品、风廓线雷达产品、循环同化10米风、5分钟最大风场等半/非结构化数据,存储类型选择NoSQL数据库;降水、温度、风、能见度等结构化数据,存储类型选择分布式关系型数据库。
3.2 云存储平台实验结果
半/非结构化数据测试,对网络状态相同情况下两种数据环境中调用数据所耗的时间进行测试对比。场景1:将数据存储在开放结构化数据服务(OTS)中,对数据进行调用,获取数据传输到客户端的时间。场景2:常规数据服务中对数据进行调用,获取数据传输到客户端的时间。测试结果如图3所示。
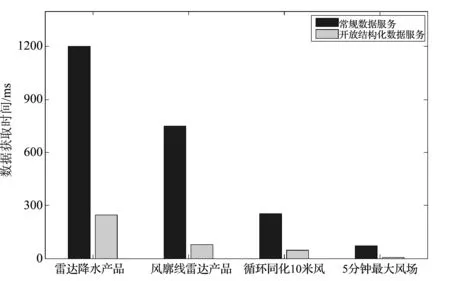
图3 常规数据服务与开放结构化数据服务性能测试结果对比图
结构化数据测试,对网络状态相同情况下两种数据环境中调用数据所耗的时间进行测试对比。场景1:将数据存储在分布式关系型数据库(RDS)中,对数据进行调用,获取数据传输到客户端的时间。场景2:利用SQL server对数据进行调用,获取数据传输到客户端的时间。测试结果如图4所示。
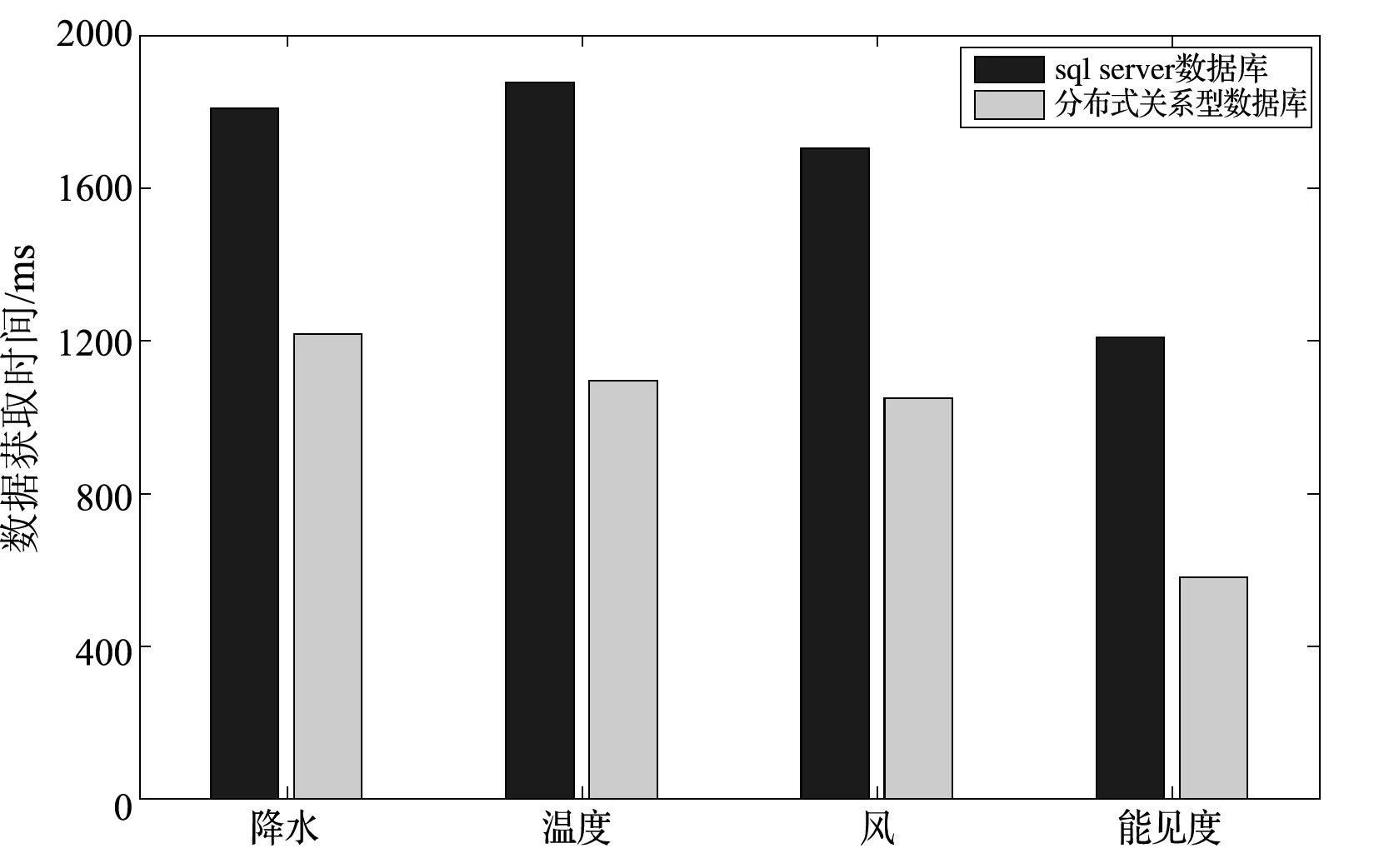
图4 SQL server数据库与分布式关系型数据库性能测试结果对比图
3.3 实验结果分析
结果显示,借助云存储平台气象数据的读取性能有了一定的提高。其中NoSQL数据库中数据读取性能与常规数据服务中数据读取性能做比较,性能上有了很大提高。分布式关系型数据库中数据读取性能比SQL server数据库中数据读取性能做比较,性能上也有提高,但提高幅度没有前者大。
4 结 语
本文针对气象数据的特点,对云数据存储方法进行探索和研究,基于云分布式存储技术设计了一套数据存储方法实现气象大数据的存储。
(1) 根据气象数据结构的不同分成结构化数据与半/非结构化数据,针对不同结构类型的数据选择云存储模型,结构化数据采用分布式关系型数据库存储,半/非结构化数据采用NoSQL数据库存储。
(2) 在对半/非结构化数据存储设计中,对数据进行主键表及属性表设计,并对属性表中的数据进行分块压缩,提高数据的存储读取性能。
(3) 根据气象数据时间度及数据使用度的不同,将数据分成热、温、冷三种类型的数据,并阐述了不同类型数据间的转换规则。
实验证明借助云存储平台,气象数据的存储读取性能有了显著的提高。本文对气象数据的云存储方法的设计思路是可行的, 为气象数据的云化建设提供一定的借鉴和参考。
猜你喜欢
无线互联科技(2022年15期)2022-11-03 03:19:00
河北理科教学研究(2021年4期)2021-04-19 13:34:44
计算机教育(2020年5期)2020-07-24 08:53:00
教育界·中旬(2019年7期)2019-11-24 05:53:39
地矿测绘(2016年2期)2016-07-16 03:03:01
河南水利与南水北调(2015年23期)2015-11-26 02:38:46
计算机工程(2015年8期)2015-07-03 12:20:35
华东理工大学学报(自然科学版)(2014年5期)2014-02-27 13:49:32
无线互联科技(2013年7期)2013-04-29 03:43:54
城市建设理论研究(2012年19期)2012-10-15 04:17:46
