
基于大数据的IPTV视频评估模型
2018-08-15 08:15:34顾军华王守彬武君艳张素琪
计算机应用与软件 2018年8期
顾军华 高 星 王守彬 武君艳 张素琪
1(河北工业大学计算机科学与软件学院 天津 300401)2(河北省大数据计算重点实验室 天津 300401)3(天津商业大学信息工程学院 天津 300134)
0 引 言
伴随中国网络信息技术和“三网融合”的推进发展,IPTV行业的发展规模和发展速度都呈现快速增长的态势。截至2016年12月末,IPTV用户达到8 673万户[1],较2015年增加了4 084万户,增长率为89%,快速发展的同时也面临着巨大的挑战。无论是IPTV平台还是传统媒体平台,洞察和理解用户的需求是每一个媒体平台发展的重中之重。目前,依据视频供应商提供的视频信息作为评估体系的指标,并依据经验设定指标权重的方法建立的评估模型均已无法准确地评估视频,不能满足IPTV受众群体的需求。利用新媒体和传统媒体的海量视频数据建立一套完整的IPTV视频评估体系,并利用IPTV平台已经积累的历史收视数据进行数据挖掘建立针对IPTV受众群体的评估模型是解决目前视频评估困境的重要途径。
视频评估体系中各指标的确定是建立视频评估模型的基础。2009年喻国明等[2]提出电视节目的收视率无法代表观众真实的满意度,更无法测量电视媒体的社会影响;2011年刘燕南[3-4]提出节目的评估指标体系,应从指导力、影响力、传播力、专业性几个指标来选择和定档节目,国内常见的电视节目评估体系是指为实现评估目的而构建的一套多指标、综合性、定量化的评估系统,一般是将各种待评要素指标化和可测化,主要采用量化方式处理不同指标之间的关系,最终形成由各种指标、权重和数学运算组成的系统;2013年潘洪涛[5]提出大数据框架下的收视评估体系不仅要反映用户对视频内容的认知效果,更应该能洞见用户对视频内容的情感效果,并且能利用评估指标进一步预测用户对视频内容的态度;2015年韩瑞娜等[6]提出在网络电视平台、传统电视平台、手机等多屏发展的时代下,对于视频的评估要关注视频的收视度和满意度;2016年杨状振[7]提出把电视节目内容的舆论引导力、社会影响力、内容传播力、和专业化制作水平纳入评价体系,提高评价体系的科学性。目前,针对IPTV视频的评估体系还未见报道,因此,本文基于新媒体视频大数据和传统媒体视频大数据从视频收视度、视频影响度和视频内容三个方面提出一个较为完善且实用的视频评估体系,体系中各个指标数据可以通过网络爬虫技术获取,将其作为建立视频评估模型的基础。
建立评估模型的常用的方法有层次分析法和主成份分析法。层次分析法需要输入指标之间的判断矩阵,需要先验知识和人工干预。主成分分析法选取多指标中的一部分重要指标作为评估模型的输入,一定程度上损失了评估准确度。人工神经网络ANN(Artificial Neural Network)在信息评估方面的研究,在国际上已经取得了很多成果。胡伟雄等[8]指出利用BP神经网络建立评价模型对于评价的准确度有更高的价值;于战果等[9]提出基于BP神经网络的部队后勤机动平台维修能力的评估模型;张忠伟等[10]提出了采用基于BP神经网络来进行体脂百分比评估模型的构建;戴晗[11]提出了基于BP神经网络的机场类项目前期风险评估模型。本文首次提出利用BP神经网络建立视频评估模型,采用具有三层结构的ANN反向传播模型,利用ANN的并行性、容错性和自学习等特点,以及ANN具有以任意精度逼近任何连续的非线性函数的功能[12],来准确地反映视频评估体系中各个指标和视频隐式评分之间的复杂关系。
综上,本文综合新媒体和传统媒体的视频大数据完善了IPTV视频评估体系,并利用网络爬虫技术进行各大视频网站的视频相关数据采集;利用IPTV平台已经积累的历史收视数据来计算视频在IPTV平台上的隐式评分;将视频在评估体系中的各个指标数据作为输入,视频隐式评分作为输出,使用BP神经网络建立视频评估模型。实验证明,所构建的评估模型能够更加全面、准确地评估视频。本文在Spark大数据平台上建立BP神经网络的并行评估模型,证明基于大数据的视频评估模型,能够更准确地评估视频,并且提高了构建评估模型的效率。
1 基于大数据的IPTV视频评估体系
IPTV视频评估体系的各指标是评估IPTV视频的重要依据,是建立视频评估模型的基础。本文通过综合文献和IPTV已有的评估体系,分析新媒体和传统媒体海量视频数据,总结出更为完善的IPTV视频评估体系。新的视频评估体系从视频收视度、视频影响度和视频内容三个方面进行完善。视频收视度包括视频的播放量和票房;视频影响度包括网络评分、获奖情况、上映时间、上映地区和首播平台等;视频内容包括视频的创作团队、视频的所属类型,视频创作团队包含有导演、演员、原著和制片人,所属类型按照新闻、电影、电视剧、体育、生活、财经等14个大类分了不同的标签。利用爬虫技术,分别从评估体系中各个指标对应的数据来源处进行数据采集,完善后的评估体系和各指标数据来源如表1所示。
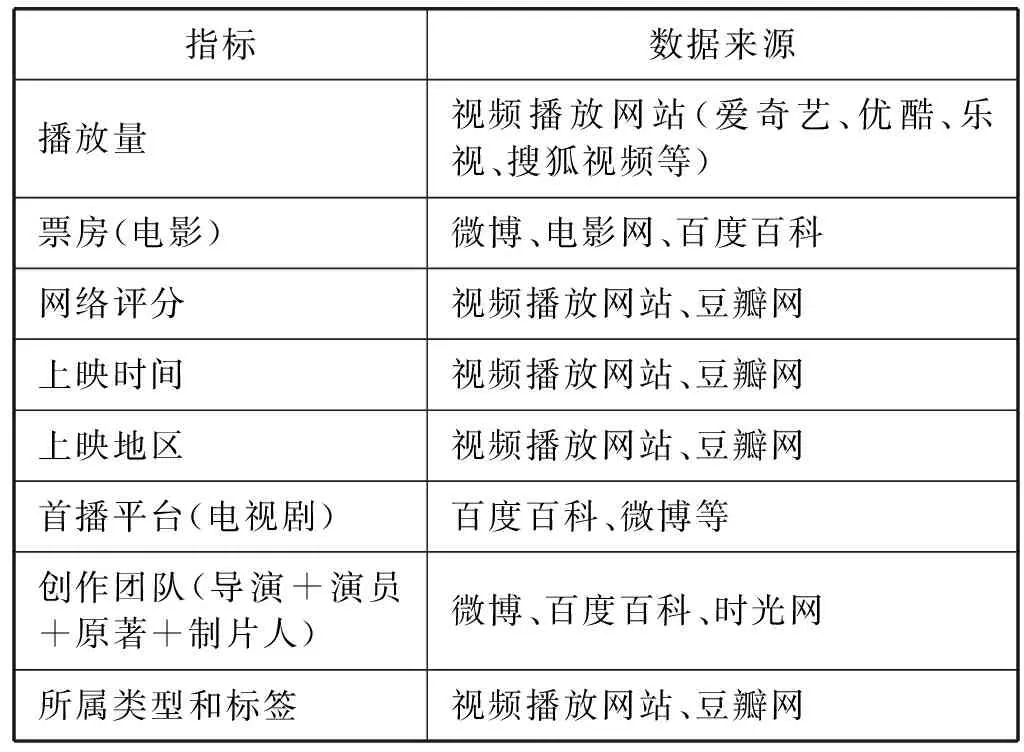
表1 完善之后的IPTV视频评估体系
2 基于BP神经网络的视频评估模型
对于完善之后的视频评估体系,如何确立各个指标对最终视频受欢迎程度之间的作用强弱是建立视频评估模型的重要任务。目前,IPTV的编辑们只是将视频各项指标的分数按照经验所设定的权重进行累加得到视频的总评分,并不能准确的反映出IPTV受众群体的喜好。本文提出利用BP神经网络来分析IPTV历史数据并建立视频评估模型,将IPTV已上线视频对应视频评估体系中的各项指标数据作为评估模型的输入,首次引入能反映这些视频受欢迎程度的隐式评分作为视频评估模型的输出,从而提高视频评估的准确度。
2.1 隐式评分
视频在IPTV平台上的受欢迎程度是视频评估模型的重要输出信息,据此建立的视频评估模型才能真正反映IPTV受众群体的喜好。在IPTV实际应用中,受到电视平台的操作性和传统用户收视习惯等条件的影响,用户往往不愿意给出视频收看后的评分和喜好程度等信息,因此隐式反馈方法更适用于IPTV平台对视频受欢迎程度的衡量。隐式反馈是通过分析用户的收视行为数据,间接得到用户对视频的偏好信息,综合所有用户对同一视频的偏好信息即可获得该视频的受欢迎程度。
本文的研究团队在以往的研究中已经提出从用户收视行为中提取用户对某个视频的观看时长、以及观看时长与节目总时长的比值两个指标作为衡量用户偏好的依据,找出了用户收视行为与隐式评分存在的关系。基于收视时长和收视比值的隐式评分模型公式如下:
β·cos2(scaleij·π)·scaleij]
(1)
式中的scoreij为用户i对视频j的隐式评分,其中α和β分别是收视时长和收视比值的权重因子,timeij为用户i对视频j的收视时长,avg_timej为用户i的平均收视时长,scaleij为用户i对视频j的收视时长占视频j总时长的比值,n为同一用户对同一视频的收视行为次数。
式(1)得到的隐式评分为一个用户对看过的一个视频的隐式评分,针对同一视频j,计算所有用户对该视频的平均评分,即为视频j的隐式评分,公式如下:
(2)
2.2 视频评估体系各指标的量化和归一化
IPTV平台上的视频类型包括电影、电视剧、新闻、纪录片、综艺和体育等14个大类。采集来的视频指标信息包括表1中的若干指标,各个指标的含义和单位各不相同,为了能够将所有指标用以建立评估模型,需要对各指标进行量化处理。在进行评估模型的训练之前,还需要对输入数据和输出数据进行归一化处理,以使数据在同一数量级,从而加快神经网络的学习速度,提高网络的收敛性和最终模型的准确度。根据完善之后的IPTV视频评估体系,结合实际采集到的视频信息,本文以电视剧类型为例说明各个指标量化和归一化的方法。
电视剧涉及到的评估指标有八项,分别是:播放量、网络评分、导演、演员、首播平台、上映时间、上映地区和视频类型。其中播放量和网络评分可直接在各大视频网站获取,直接计算两项平均值记为C1、C2,电视剧的导演、主演员和首播平台都是固定的因素,由视频评估专家按照导演的获奖情况、主演员的职业等级和首播卫视的级别情况给出的量化标准直接打分,量化后分别记为C3、C4、C5。电视剧的上映时间,上映地区和视频类型涉及到的影响因素较多,综合多个视频评估专家的意见,将这三个评估指标分别细分为多个实际因素,然后采用层次分析法计算各因素权重,将因素权重作为这三项评估指标的量化标准。下面以上映时间为例说明采用层次分析法建立量化标准的过程。
首先总结评估专家的意见,结合电视剧上映时间的实际情况,将上映时间涉及到的实际因素分为四类,分别对应着不同的时间段,建立的量化模型如图1所示。
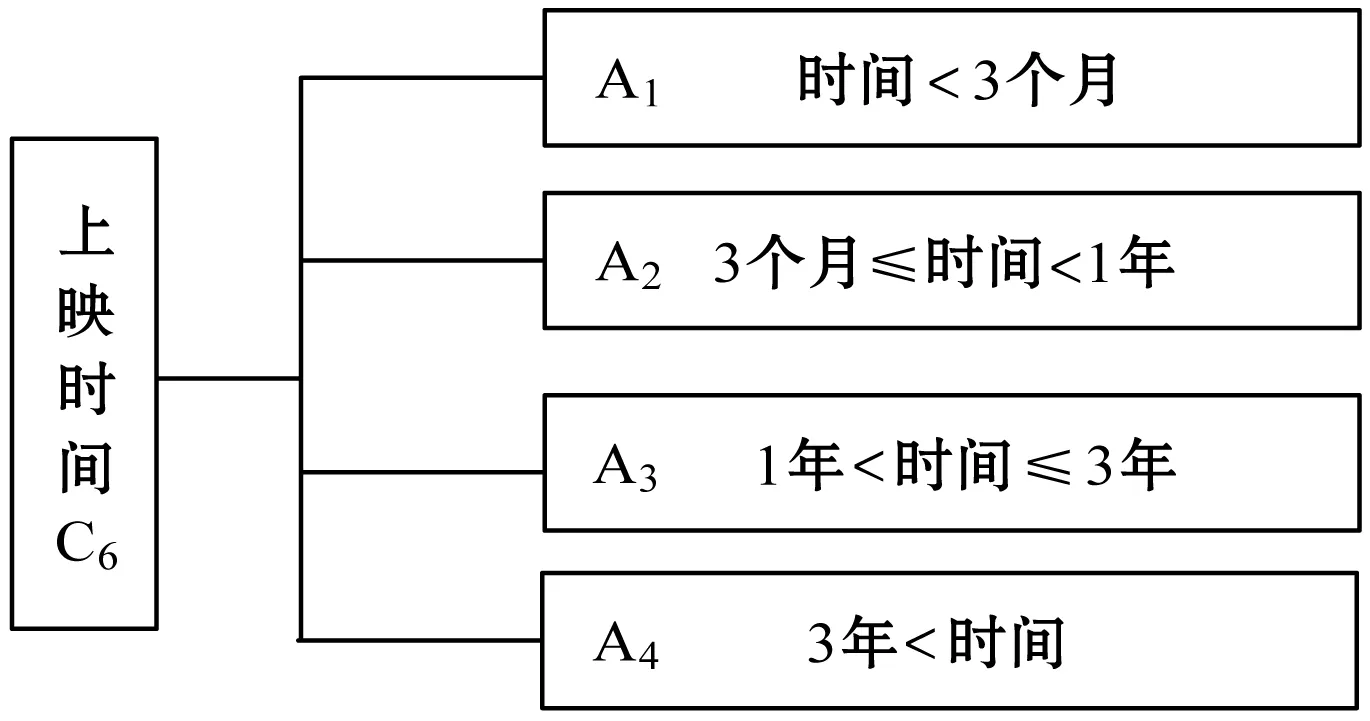
图1 量化模型图
然后针对四个实际因素的相对重要性,由评估专家进行打分,两两比较得到判断矩阵。
表2中“1”表示为两个元素相比较,具有同等的重要性,“3”表示为两个元素相比较,一个元素比另一个元素比较重要,数值的大小表示重要程度的强弱。
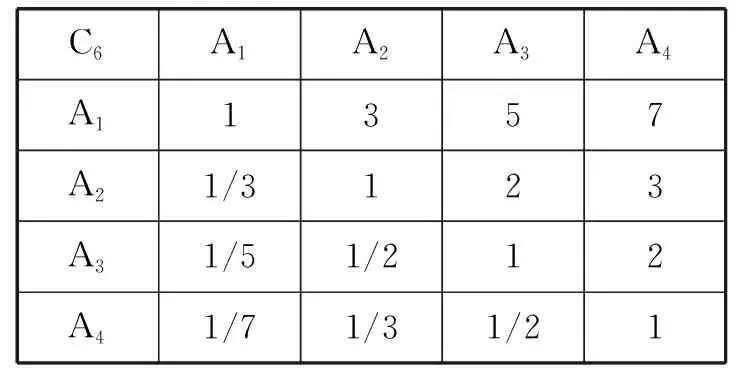
表2 上映时间C6判断矩阵
通过求解矩阵的最大特征根和特征向量,计算得到一致性指标CI=0.006 4,一致性比率CR=0.007 1<0.1,说明结果有效。最大特征值对应的单位特征向量为w=(0.587 2,0.217 9,0.122 8,0.072)T。
由此得到四个因素所对应的权重。将各因素的权重作为上映时间C6的量化标准,即:
(3)
同理可得上映地区C7,视频类型C8的量化标准如下:
(4)
(5)
综上,用Input表示评估模型的输入向量,用Output表示评估模型的输出向量,其中Imp表示IPTV电视剧的隐式评分。合成后表示公式如下。
Input={C1,C2,C3,C4,C5,C6,C7,C8}
(6)
Output={Imp}
(7)
进行训练之前需要对各项输入数据和输出数据分别进行归一化处理,将数据限定在[0,1],归一化的公式如下:
(8)
式中:Xmax,Xmin分别代表在该项数据中的最大值和最小值,Xi为最初数据。
2.3 基于BP神经网络建立视频评估模型
BP神经网络是一种多层的前馈神经网络,由输入层、隐含层和输出层三部分组成,各层神经元之间的权值通过反向传播的方法调整,是目前应用较多的神经网络模型之一,它能学习和存储大量的输入输出映射关系而无需事先揭示出描写这些关系的数学方程[13]。本文使用BP神经网络建立视频评估模型,其中输入层的节点数设定为8,各节点分别对应着C1、C2、C3、C4、C5、C6、C7、C8;隐含层的节点数设定为10;由于输入的各项指标得到的评估值只有一项,故将输出层的节点数设定为1,对应着视频的隐式评分Imp。BP神经网络的结构如图2所示。
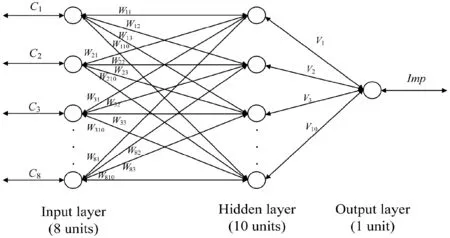
图2 BP神经网络的结构图
训练过程包括前向传播和反向传播两个过程。首先输入层接收输入信息,经过隐含层处理再将输出信息传递至输出层,通过计算输出层的输出信息与对应视频隐式评分的误差来调整神经元之间的权值。经过反复的迭代训练,使得误差逐渐下降。
3 基于SPARK的并行化视频评估模型
利用BP神经网络来建立评估模型的一个主要问题是IPTV已有的历史数据量巨大,传统的串行方式不能承担大数据规模下的不断迭代和计算的过程。IPTV的一个用户在一个星期内的收视行为在2 000条左右,而IPTV的总用户超过了8 000万,如果想得到一个准确有效的评估模型,需要综合 IPTV平台上所有用户的收视行为进行模型建立。目前,分布式的机器学习在大规模数据挖掘方面非常有效,参数服务器[14-17]使得学习算法易于部署在大规模集群上。Spark是一个基于内存的分布式计算平台,它拥有Hadoop MapReduce的全部优点,从而不再需要读写Hadoop分布式文件系统HDFS(Hadoop Distributed File System),提高了并行计算的速度[18],这使得它在大数据分析处理方面相较于其他平台更加高效。Spark的核心抽象模型是弹性分布式数据集RDD[19](Resilient Distributed Datasets),Spark为RDD提供了各种功能的操作,这使得数据集的处理更加高效快捷。本文基于Spark平台实现了BP神经网络的并行化算法,用以处理视频评估模型的大数据量训练过程。
3.1 BP神经网络并行化训练流程
本文将BP神经网络算法部署到Spark数据处理框架上进行并行训练。在BP神网络的训练中有在线学习模式和批量处理学习模式两种。在线学习模式是每计算一个样本数据的误差就进行网络权重的调整,批量处理学习模式是指在对于样本集中的所有样本完成训练后,利用所有样本总误差梯度调整网络权重[20]。与在线学习模式相比,批量处理的学习模式不仅提高了收敛速度,而且有效地避免了训练数据的输入顺序对网络模型的影响,因此本文采用了批量处理的学习模式进行神经网络的训练。具体的BP神经网络算法并行化训练流程如图3所示。
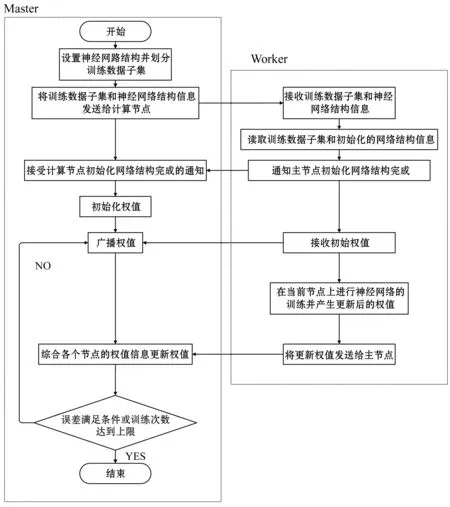
图3 算法并行化训练流程图
BP神经网络并行化训练具体步骤如下:
步骤1:将训练数据集切分成多个子集,并且存储到HDFS上;
步骤2:Master节点将设置的BP神经网络结构、数据集子集以及网络初始化权重发给Worker节点,使得每个Worker节点都实例化一个完整的神经网络;
步骤3:在每个Worker节点上,使用批量训练的方式将部分训练数据集子集作用于神经网络上,并行地进行神经网络的训练;
步骤4:Worker将训练更新之后的网络权重返回给Master节点;
步骤5:Master节点更新权重并计算期望输出与实际输出的误差,判断误差和迭代次数是否满足要求,若满足则结束训练,否则返回步骤2继续训练;
步骤6:输出训练后的神经网络模型。
3.2 RDD数据集流转过程
Spark平台的优势在于基于内存的计算,RDD的各种操作是在内存上进行,算法实现过程中对RDD进行的一系列算子操作和数据集的转换过程就显得极其重要。本次实验在并行训练阶段涉及到的RDD算子操作和数据集流转过程如图4所示。
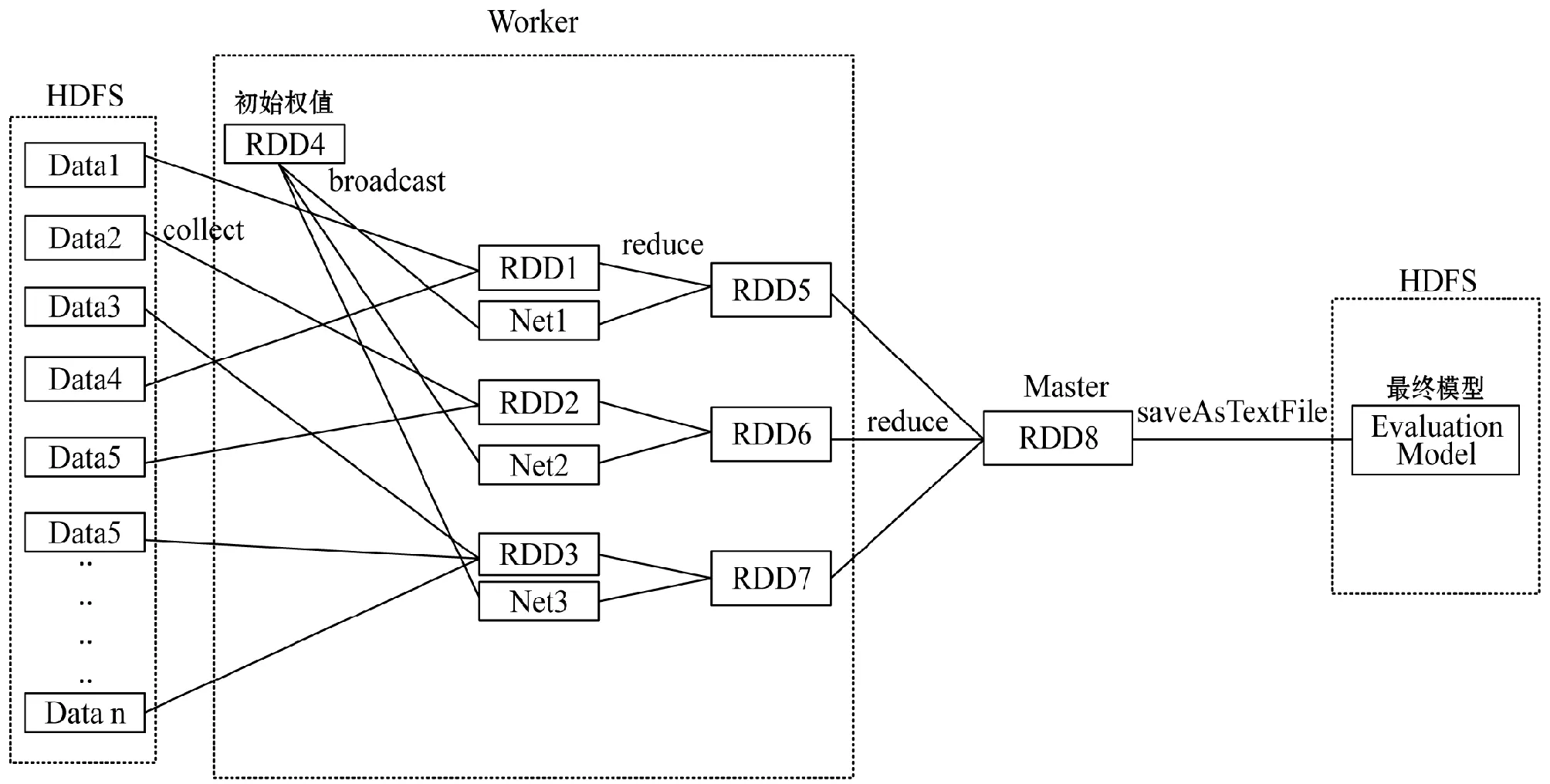
图4 并行化训练阶段数据集转换图
(1) 首先,将训练的数据集切分成多个子集,存储在HDFS里。
(2) 启动Spark集群,执行程序,使用collect算子将数据子集作为RDD输入到各个Worker节点。图示为三个Worker节点,对应的RDD分片数可根据进程所需的内存大小设定。
(3) Driver进程读取初始化的神经网络权值,并使用broadcast算子将权值传递到各个Worker节点中。
(4) 各个Worker节点使用初始化的权值实例出一个网络结构。
(5) 采用批量训练的方式,将数据子集作用于各个Worker节点的神经网络上,进行迭代训练后输出网络权值。
(6) Master节点综合各个Worker节点的输出,得到最终的网络权值。
(7) 使用SaveAsTextFile算子将训练后的神经网络模型输出到HDFS中。
4 实验结果分析
为了验证本文提出的基于大数据构建视频评估模型的有效性,实验选取2015年12月到2016年4月某市IPTV平台的1 000个用户的收视行为,根据式(1)、式(2)计算获得了视频的隐式评分,然后通过网络爬虫技术对视频进行评估体系指标信息的采集,按照2.2节中的方法进行量化和归一化,得到800 MB完整的实验数据。本实验主要验证两方面性能:一是基于BP神经网络建立的视频评估模型的有效性验证,二是并行化建立视频评估模型有效性验证。
4.1 基于BP神经网络的视频评估模型的有效性验证
为了验证IPTV视频评估模型的有效性,实验选取200 MB训练数据,首先在训练过程中采用交叉检验的方式来验证评估模型的稳定性,训练完成后得到IPTV视频评估模型,然后用100条新的视频数据作为预测数据集,用新评估模型和原有的评估模型分别对其进行预测,通过对比来验证评估模型的有效性。
评估模型训练的过程中,采用K折交叉检验的方式来验证评估模型的稳定性,这里K=10。在每次的迭代训练过程中计算交叉检验产生的均方误差。从图5可知,经过30次的迭代训练,交叉检验产生的误差值整体呈现明显的下降趋势并逐渐趋于稳定,这就说明基于BP神经网络建立的视频评估模型较为稳定。
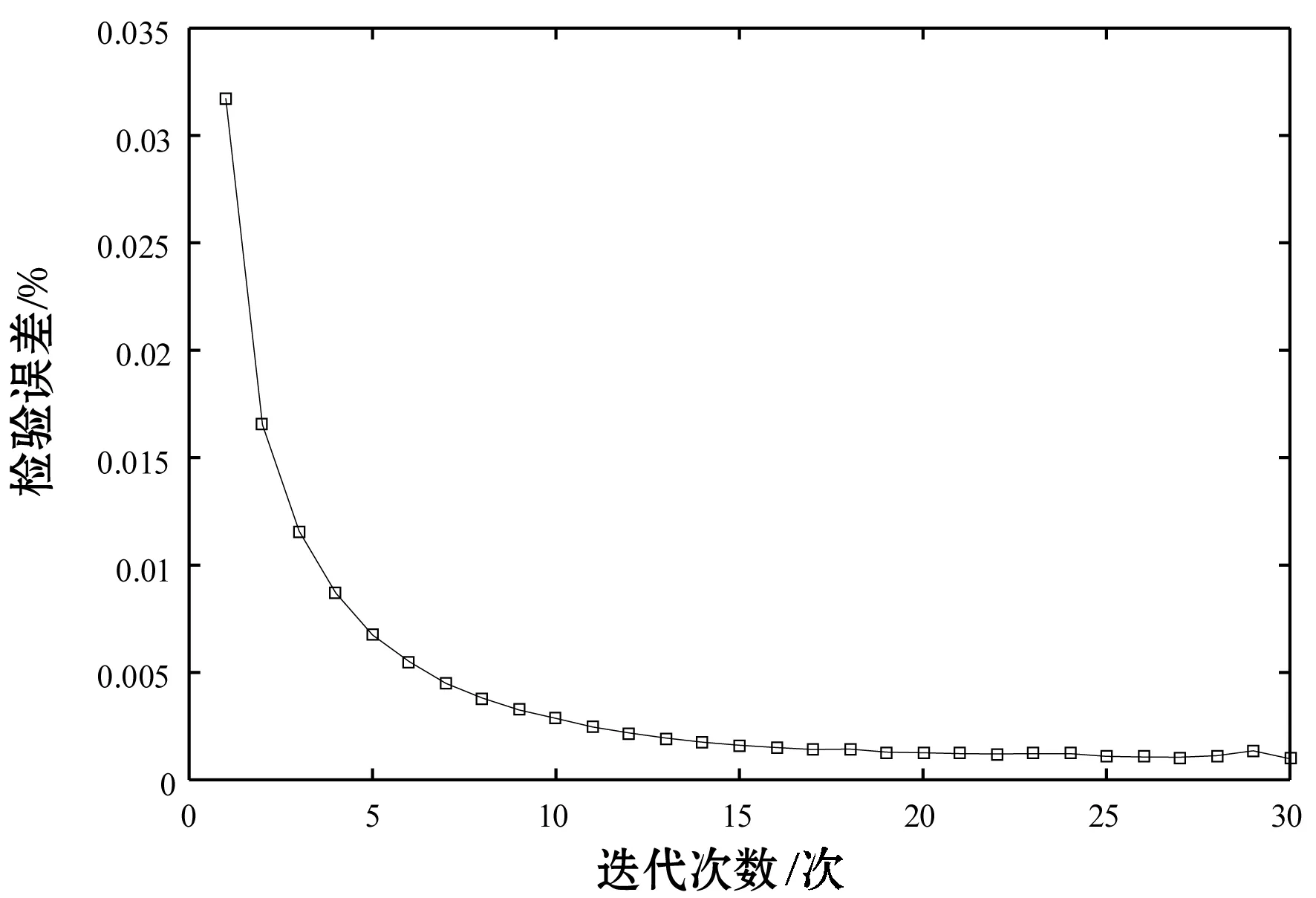
图5 交叉检验误差图
训练结束后选取100条新的数据对评估模型的有效性进行验证。用ebp表示基于BP神经网络建立的IPTV视频评估模型预测得出的实验输出与隐式评分的差值的绝对值,eold表示根据原评估模型预测得出的实验输出与隐式评分之间差值的绝对值。图6为ebp与eold之间的对比图,其中实线表示ebp,虚线表示eold。
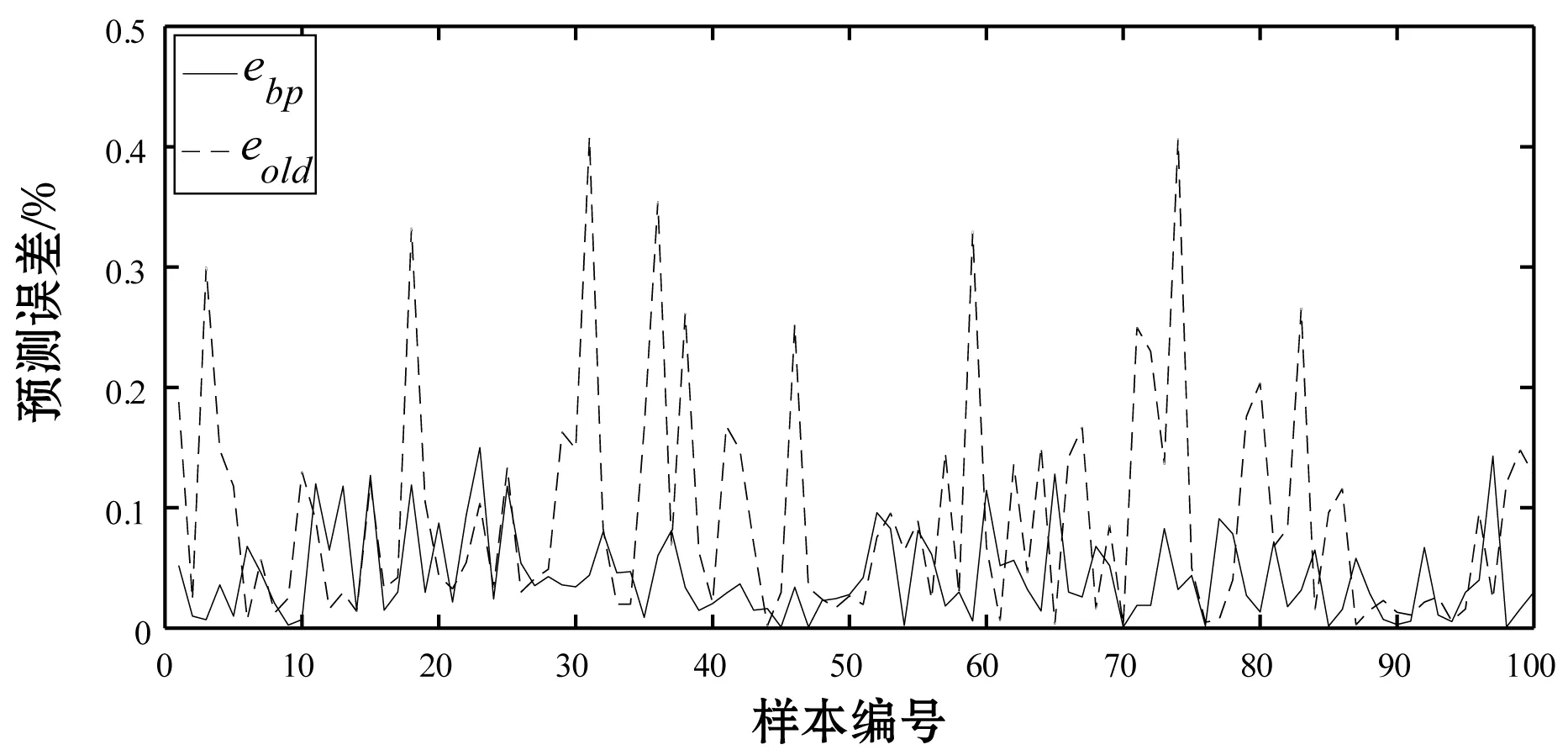
图6 差值对比图
从图中可以明显地看出,ebp的值从整体上要明显小于eold,并且计算均方误差得到MSEbp=0.003 143,MSEold=0.017 56,这就进一步说明了基于BP神经网络建立的视频评估模型更为准确。
4.2 并行化构建视频评估模型的有效性验证
实验采用了基于内存的分布式并行框架Spark进行实现,实验环境介绍如下:集群环境共包含6个节点,其中5个为Worker节点,每个节点的配置相同,且处在同一个局域网内,操作系统为CentOs6.5,CPU为E5-2620 v4,核心频率2.10 GHZ,节点内存32 GB,使用了Scala编程语言,分布式平台为Spark2.0.0。
通过改变训练数据集的大小,分析Spark平台在不同节点数目下构建评估模型所需的时间,计算加速比来验证算法的并行性。实验将训练数据集分成200、400、600和800 MB,来计算不同大小训练数据集产生的加速比,加速比的公式如下:
(9)
式中:Sp代表加速比,Tp为使用1个节点时任务执行的时间,Tp为使用 个节点时任务执行的时间。
实验结果如图7所示,在4种不同大小的训练数据集下,加速比与节点数目的增加近似成正比的关系。并且随着训练数据量的增加,产生的加速比逐渐趋于理想的状态。由此可见,基于Spark的BP神经网络在处理大规模训练数据集的情况下构建视频评估模型有较好的并行性。
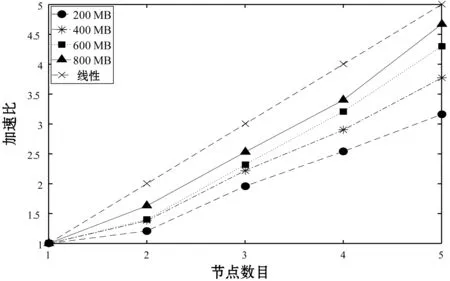
图7 BP神经网络并行化后加速比
5 结 语
针对目前IPTV视频评估模型所面临的准确性问题,本文首先从视频的收视度、视频的影响度和视频内容三个方面完善了视频评估体系;然后引入视频的隐式评分来反映视频的受欢迎程度,对IPTV上已上线视频的各项信息进行采集和量化后得到视频的各项评估指标数据,再通过收集这些视频的历史收视情况得出视频的隐式评分,将其分别作为神经网络的输入数据和输出数据来训练评估模型;最后针对大数据的海量性,在Spark平台上使用BP神经网络实现了数据的并行化训练,建立了基于大数据的视频评估模型。实验结果表明,本文提出的基于大数据的IPTV视频评估模型提高了视频评估的准确度,并且在Spark平台上建立评估模型具有良好的时间性能。
猜你喜欢
机械工业标准化与质量(2022年6期)2022-08-12 02:07:42
国际眼科杂志(2021年9期)2021-09-15 03:24:42
装备制造技术(2020年2期)2020-12-14 03:09:16
电子制作(2019年19期)2019-11-23 08:42:00
重型机械(2016年1期)2016-03-01 03:42:04
大连工业大学学报(2015年4期)2015-12-11 04:06:52
中国卫生(2015年12期)2015-11-10 05:13:34
质量与标准化(2015年9期)2015-07-10 15:12:07
海军航空大学学报(2015年4期)2015-02-27 13:45:47
浙江人大(2014年5期)2014-03-20 16:20:25
