
数据集的语义关联发现方法研究
2018-08-15 08:15:22范冰冰
计算机应用与软件 2018年8期
龚 振 范冰冰
(华南师范大学计算机学院 广东 广州 510631)
0 引 言
在大数据时代,数据成为了最具有价值的资产,数据的开放和跨界融合是大数据产业得以壮大的关键。而传统开放数据组织管理方式,数据集间相互孤立、缺乏关联、杂乱无章,无法发掘其真正价值。同传统的数据管理技术相比,关联技术更容易实现多源数据的组合,它的自描述特性利于大范围的数据共享。关联数据也成为开放数据的最佳实践之一[1]。
关联数据是W3C推荐的一种规范,用来发布和连接各类数据、信息和知识。通过对Web中各种数据资源及其相互之间关系映射进行机器可读的描述,可以在更大范围内,准确、高效、可靠地查找、分享、利用这些相互关联的信息和知识。目前,RDF是最适合程序自动处理的文档之一,且能富含语义,已成为关联数据的“标配”,也是关联数据的基础数据模型。RDF是领域无关的,适用于Web的简单而抽象的数据模型。其采用三元组的形式表达两个资源间的二元关系或一个资源的属性。RDF三元组是在网络上发布关联数据最简单便捷的形式[2]。
自关联数据提出以来,它的研究和应用一直是个热点,涵盖生命科学、地理信息、科学出版物、电影、音乐等众多领域。在欧美国家,关联数据已经开始应用于政府数据的开放,如美国的data.gov、英国的data.gov.uk已经采用RDF格式发布数据集并提供SPARQL方式查询。国内第一个关联开放数据项目——zhishi.me,把维基百科中国、百度百科、互动百科整合链接成一个知识库,尝试构建中文通用知识图谱[3]。文献[4]借鉴国外图书馆MARC21转换成RDF的成功做法,构建CNMARC到RDF的映射实现进行了关联数据在图书馆学的实践尝试[4]。文献[5-8]对实现关联数据需要解决的关键问题包括描述、数据管理、语义互操作等进行了探讨。
从国内外研究来看,现阶段,数据集之间的关联主要表现为各个数据集与 DBpedia、GeoNames 等少数核心资源集(HUB 资源)的链接,其他非 HUB 资源集之间的关联相对比较少,数据集内部实体间的关联更加缺乏。其主要原因就是缺乏统一的关联数据集描述规范和有效的数据集自动关联方法。针对此,本文参考国内外研究,从数据集外部基本信息、内部属性特征、关联关系映射三方面设计关联数据集描述模型,并采用语义相似度计算方法,综合数据项特征,发现数据集语义关联,构建具有映射关系的RDF数据,实现的数据集的统一描述和内外部链接。最后以“广州市政府数据统一开放平台”为例进行实验,实现数据集的描述并建立链接关系。也为关联数据技术在开放数据方面的实践应用提供借鉴价值。
1 关联数据集描述模型
构建关联数据的关键步骤就是对数据集进行描述。本文将数据集的描述分为外部描述(粗粒度描述)和内部描述(细粒度描述)。描述模型除了包含数据集的数据特征信息之外,还需有描述数据集间的链接信息。数据集描述模型是应用于关联数据的开放与共享,采用RDF的标准数据格式及RDF/XML 描述语言,提供统一的数据描述,并根据的描述特征自动发现和映射有关系的其他数据集。
为了便于关联数据在Web中共享和传播,数据集描述模型的设计还要遵循一下三个原则:
(1) 尽可能地复用已有的词汇表和术语(如DCAT、DC、FOAF、Geo等),减少词汇异构。
(2) 模型各部分描述能够很好表述数据集信息特征。
(3) 必须符合SPARQL的查询方式。
外部描述是用户识别了解数据集内容最为直接的方式。本文将外部描述分为数据集标识信息、数据集限制信息、数据集维护信息三类。数据集标识信息包括数据集标题、分类、摘要等基本信息;数据集限制信息包括许可说明、权限等访问与使用有关的限制信息;数据集维护信息包括更新日期、更新频率、维护方等信息。基于复用已有的词汇表原则,本文将借鉴都柏林核心词汇并结合其他相关词汇,选用部分适用于关联数据集的外部描述词汇,如表1所示。
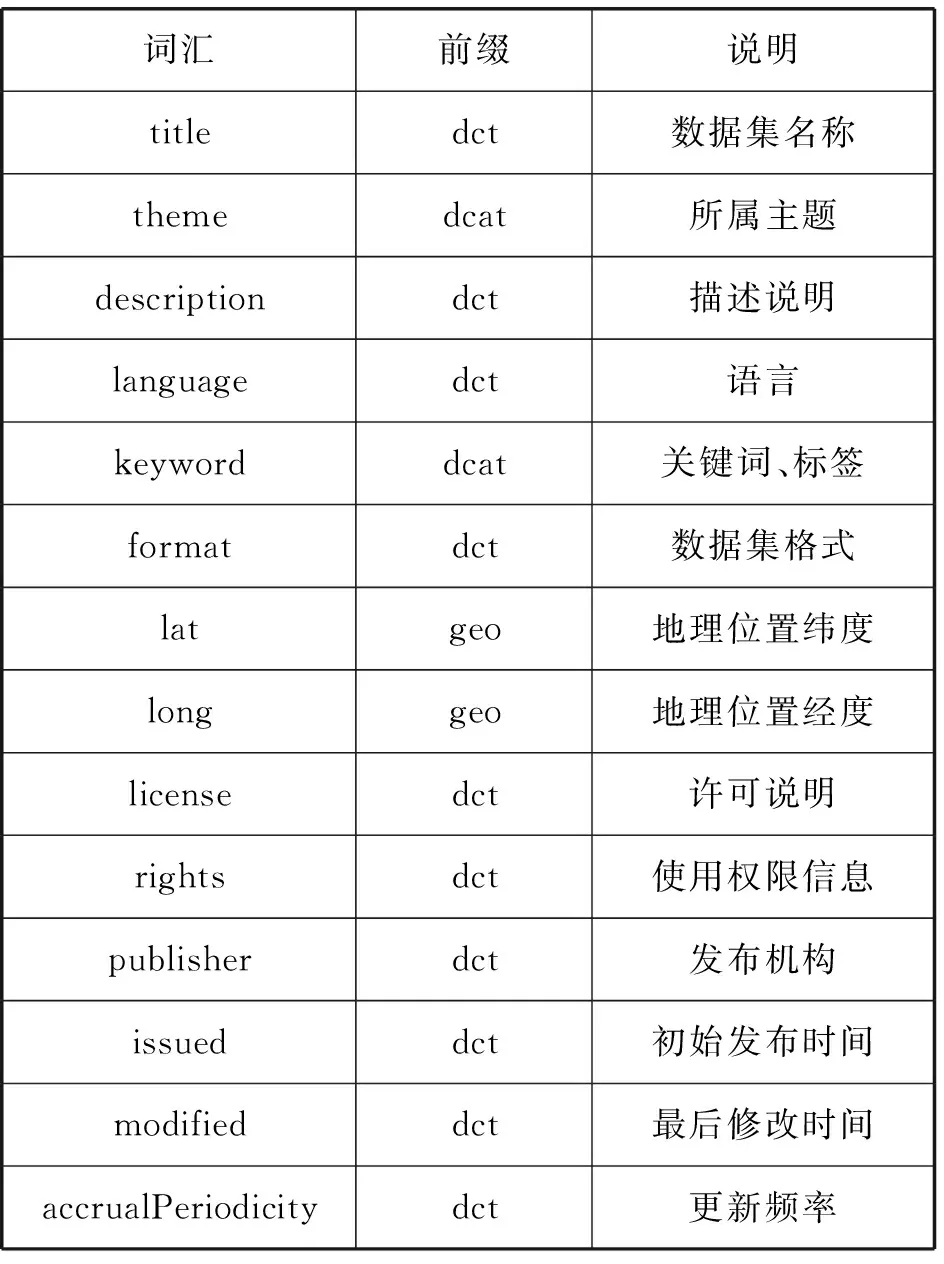
表1 关联数据集外部描述选用的基本词汇
内部描述是描述数据集内部数据属性信息,目的在于用户可以通过数据集描述信息直接了解到数据内部结构,而且通过对数据集内部描述,可以标记内部实体属性特征,便于辨别某些属性间是否可能存在关联。由于数据集内部数据的描述尚未有可借鉴词汇,本文来自定义新的词汇DI(data item),用以描述数据集内部属性特征。例如:di:isLink作为数据集间关联映射时对此字段是否要进行关联匹配。比如:对于数量这类无概念数值就不用计算和其他本体的关联;对于学校、公司等名词这类有实际意义的属性需要进行关联映射;对于身份证号、车牌号这类具有唯一标识的属性,以di:isUnique为标记,来做更精准的关系判断,以及一些来描述属性信息的词汇。表2为本文设计的数据集内部描述词汇。
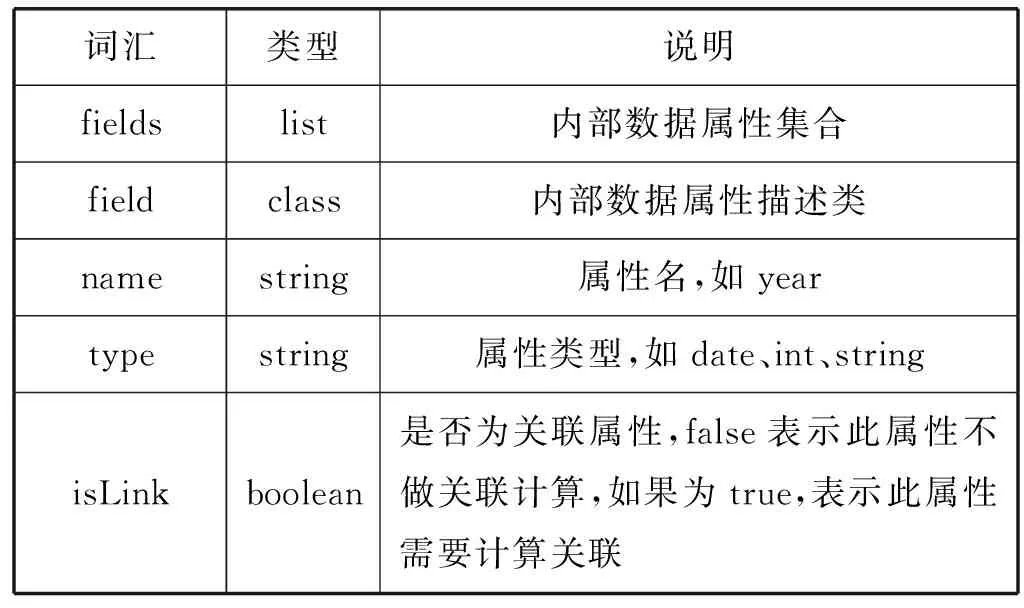
表2 自定义数据集内部描述词汇
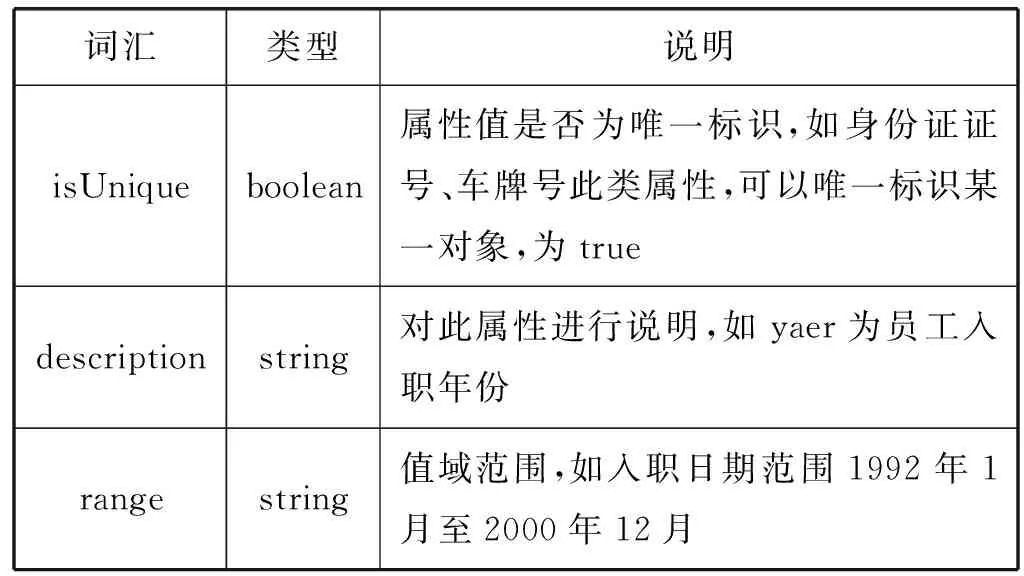
续表2
除了描述数据集信息的外部描述和内部描述外,关联数据集还需要关联描述,目的在于描述数据集之间的关联信息。鉴于关联数据通常采用RDF数据形式,本文将数据集的关联关系通过RDF三元组的来表示:主体为某一数据集资源或者内部某一实体属性值,谓词用SKOS、OWL、VoID等表示关系的词汇,宾语为另一数据集或者同数据集实体属性值,以此来表述关联关系。有些链接关系没有明确指向,如owl:sameAs表示等同关系,主语和宾语可以互换,有些链接关系是不对称的,如void: subjectsTarget用来说明主语链接指向。
完整的关联数据集描述模型的设计要包括以上三个方面的描述,分别用来表示不同的数据集信息以及数据间的关系。
2 数据集的语义关联
关联发现是实现构建关联数据的关键步骤,本文借鉴文献[9]中关联层次分类,把数据集关联分为外部关联和内部关联。两个数据集外部描述如标题、摘要、关键字等存在关联关系即成为数据集外部关联。数据集内部数据存在实体关联称为数据集内部关联。数据集外部关联和内部关联由于链接对象层次不同,不存在必然的联系,却更加丰富了数据集的联系。大量的外部关联和内部关联可以将众多数据信息相互链接, 构成关联开放数据云LoD cloud(Linked open Data cloud)[10],进而形成数据网 (Web of Data)[11]。
分析关联数据相关技术,语义相似度计算是目前计算资源间关联度的比较常用的方法。所以本文基于设计的语义描述模型,综合数据集的描述特征,采用语义相似度的计算方法,根据其语义相似度结果来判定数据集或内部属性间是否存在关联。语义相似度的大小应该是在区间 [0,1],相似度值越大,说明关联程度越高,相似度为1可视为等同关系。
2.1 外部关联
数据集标题、摘要、关键字、主题分类是表述一个数据集所述内容的基本信息项。标题、摘要属于长文本类型,对此类型数据项,首先进行分词,转为词集。使用向量空间模型方法计算相似度。其语义相似度计算公式如下:
词集1表示为D1,词集2表示为D2,其中:
D1={w11,w12,…,w1n}
D2={w21,w22,…,w2n}
D1和D2的相似度:
(1)
这里把标题和摘要的相似度值分别记为Simt和Simd。
主题、关键字数据项属于概念性词汇,概念间的语义计算一般基于第三方语料库或者领域本体计算相似关系。本文采用基于百度百科的词语相似度计算方法进行此方面计算。此方法通过对百科名片、词条正文、开放分类和相关词条部分的相似度计算方法,对其再加权就得到整体的相似度结果,这里给出总体相似度计算公式[12]:
(2)
把主题和关键字的相似度值分别记为Simc和Simk。
外部描述的总体相似度值即为这四项加权:
Simout=θtSimt+θdSimd+θcSimc+θkSimk
(3)
由于标题和摘要是描述数据集内容主要数据项,其中θt和θd权重相对大一些,θc和θc权重相对小一些。θt+θd+θc+θk总和为1,具体权重赋值根据实验结果调整优化。
2.2 内部关联
对于结构化和半结构化数据集,还需进行内部数据描述,数据集的内部关联也是建立在内部描述的基础上的。对于同一数据集或者不同数据集间内部记录的某些属性实体值可能是表述同一对象,这里就要建立数据集的内部关联。
在内部数据描述中,di:isLink表示此属性是否需要实现关联,当为true时,要计算此属性实体和其他属性实体关联度;为false时,可以不用计算此属性的关联。当di:isUnique为true时,表示此属性为身份证、车牌号等唯一标识属性,可以直接采用文本值比较的方法,判断两个实体是否一致,其相似度取值为只能为0或1。
当di:isUnique为false时,标识此属性非唯一标识,需综合此属性的描述特征以及具体属性值,判断实体间是否相关。在内部描述中有对此属性信息的描述:name、type、description,这三项描述了此属性的名称(如产品名称)、类型(如string)、说明(如本数据集的产品名称是农作物品种的学名)。
计算di:type的相似度,由于di:type为固定范围取值,这里采用文本值比较计算方法,记为Sim1。属性说明di:description部分,采用式(1)计算,记作Sim2。属性名称di:name采用式(1)计算,记作Sim3。对于属性值,先进行词性分析,对于词性为长文本的属性值采用式(1)计算相似度,对于概念性属性值采用式(2)计算相似度,此部分记为Sim4。内部关联综合相似度为:
Siminner=θ1Sim1+θ2Sim2+θ3Sim3+θ4Sim4
(4)
式中:θ1+θ2+θ3+θ4总和为1,属性值作为整个属性的关键特征,θ4应该具有更高的权重,其他权重赋值根据实验结果进行优化调整。
3 实验结果
本实验数据来源于广州市政府数据统一开放平台,爬取了其中574个数据集,此数据量已经占此平台总数据集量的95%以上,实验数据相对比较可靠。为了实现数据集的关联,并验证本研究方法的有效性和科学性,本文设计了以下实验流程:
(1) 搭建基于Java的Jena[13]框架,便于把读取到的数据集转换成RDF数据。
(2) 根据关联数据集描述模型引入所需词汇并创建自定义的DI词汇。
(3) 读取数据集及元数据,参照描述模型,生成RDF数据。
(4) 根据内外描述,利用上文关联计算方法计算对应项相似度,对于相似度值大于设定阈值的数据集或实体属性建立关联映射。
(5) 输出关联数据集的RDF/XML格式文件。
数据集的关联发现流程如图1所示。
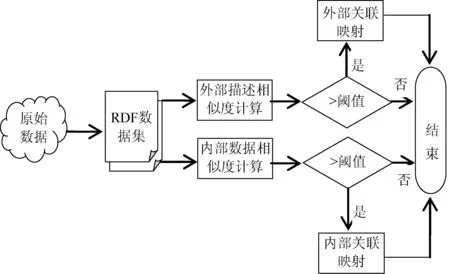
图1 数据集描述和关联发现流程
考虑计算时数据项描述特征,数据集标题和内部属性值对语义相似度影响较大,所以权重应该较大。又经过多组权重实验结果对比分析,式(3)中权重系数设为了θt∶θd∶θc∶θk=0.6∶0.2∶0.1∶0.1,式(4)权重系数设为θ1∶θ2∶θ3∶θ4=0.1∶0.1∶0.1∶0.7,其结果相对较好。当然,具体的赋值也可以根据实际实验调整,进行优化。表3是“广州市高新技术企业名单”这一数据集与其他数据集外部关联相似度计算结果。
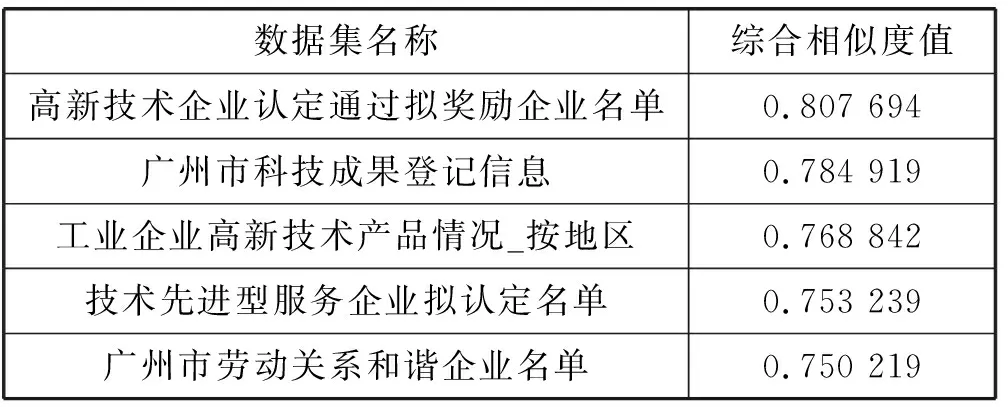
表3 “广州市高新技术企业名单”数据集
广州市政府数据统一开放平台未涉及到数据集内部关联,并且未实现对内部数据的检索查询。本实验以数据集“广州市农药使用品种推荐名录”中“产品名称”属性和“广州市地理标志产品一览表”中的“作物”属性计算两数据集内部具有关联的实体的语义相似度,其结果如表4所示。

表4 数据集内部数据的实体相似度计算结果
从实验结果可以看出,对角线上的数值均在0.8以上,其产品也为对应的作物的某一品种,两个实体本身存在关联关系。如“钱岗糯米糍”是“荔枝”的一个种类,根据本文方法计算的相似度为0.810 307,它们之间关联程度比其他非对应的作物产品相似度相对较高,可以验证本方法实体间相似度计算的相对较为可靠。
4 结 语
以关联数据形式发布数据是开放数据的未来发展趋势。本文结合数据集外部描述、内部描述和链接信息设计关联数据集描述模型,并根据描述模型,提出基于语义相似度的数据集关联发现方法,实现关联数据的程序化创建转换。相比其他研究,本文设计的描述模型为关联数据集的开放共享提供了可借鉴的描述模型。其关联方法不仅实现了数据集之间的基本描述层面的关联,还实现了数据集内部数据属性之间的关联,大大提高了数据信息的关联程度。本文的研究虽然完成了一定的工作,但还有一些问题需要改进:其一数据集关联由于要综合多个数据项,随着数据集的增多,计算量会暴涨,需要一个有效的计算框架。此外,各数据项相似度值的权重系数和综合相似度阈值还需进行优化,以提高关联质量。
猜你喜欢
开放教育研究(2020年2期)2020-03-31 01:54:14
中国外汇(2019年18期)2019-11-25 01:41:54
当代陕西(2019年15期)2019-09-02 01:52:00
学苑创造·A版(2018年11期)2018-02-01 06:29:20
哲学评论(2017年1期)2017-07-31 18:04:00
领导决策信息(2017年9期)2017-05-04 04:04:49
领导决策信息(2017年9期)2017-05-04 04:04:49
读者(2017年5期)2017-02-15 18:04:18
现代语文(2016年21期)2016-05-25 13:13:44
大连民族大学学报(2015年2期)2015-02-27 08:28:11
