
基于Go 实现的分布式主键系统研究
2022-11-03 03:19:00河南理工大学计算机学院河南焦作454000
无线互联科技 2022年15期
(河南理工大学 计算机学院,河南 焦作 454000)
秦攀科,李有卿*
0 引言
单机时代,一个数据库就可以满足业务的需要,数据库的主键选择很简单,直接借助数据库的自增主键就可以实现,其他类型复杂的主键,在单进程服务中也可以很简单地实现。 但是,随着系统规模的扩大,越来越多的公司开始使用微服务架构,这时就面临着数据库主键一致性的问题。 传统来说,UUID 是可以解决分布式主键问题的[1-2],但是大多数公司都采用MySQL数据库[3],而UUID 的无序和跳跃会导致数据库的性能急剧下降,并且UUID 长度很长,因此采用UUID 是不可取的。 雪花算法在时间范围内基本有序,同时也可以保障多进程下不会出现主键重复,但是也有可能生成重复的主键,而且生成的主键长度也较长,在前端展示的时候会精度丢失,需要后端额外转化为字符串。越来越多的系统需要定制有一定特殊格式和规则的主键,开发人员需要去实现特定要求的主键,这会让业务参与到分布式主键的开发,造成人力资源浪费。 所有的这一系统问题都急需解决,因此,分布式主键系统应运而生,可以支持多种分布式主键生成规则,通过Grpc方式的远程过程调用提供多种语言的SDK 支持[4-5],不仅方便,而且RPC 可以让系统性能得到提升[6]。 内部通过Namespace 做系统空间隔离,不同种类的主键通过主键类型做区分。 此系统上线后,所有业务系统都可以直接调用该系统提供的SDK,集成分布式主键。
1 分布式主键介绍
1.1 雪花算法
目前,最主流的分布式主键生成算法是基于雪花算法的,其结构如图1 所示。
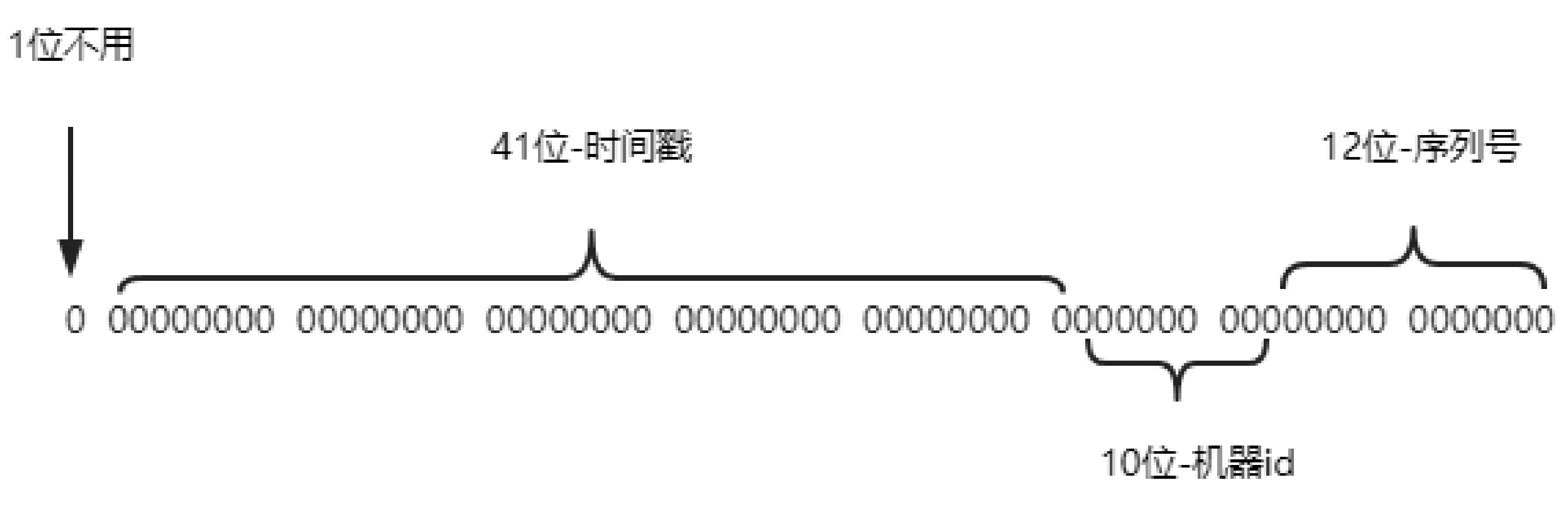
图1 雪花算法的结构
可以看到,雪花算法是由64 个二进制数组成。 其中,第一位是符号位,其值永远为0;接着是41 个二进制位表示时间,精确到毫秒值;然后是10 个二进制位表示机器标识;最后是12 个二进制位标识某一毫秒能产生的唯一主键个数,即2 的12 次方,4 096 个数字。基于雪花算法的结构,可以保证:(1)所有生成的id 按时间趋势递增;(2)因为机器标识的隔离,整个分布式系统不会产生重复的id。
雪花算法存在的问题:(1)机器标识只有10 个二进制位,也即最多只支持1 024 个服务使用,现在的大型系统服务节点可能远远不止1 024 个。 (2)要保证1 024 个节点分配到的机器标识都是唯一的。 (3)时钟回拨问题。 当时钟回拨,会产生重复的主键,这是难以接受的。 (4)雪花算法的机器id 的分配问题。 当机器多起来,需要仔细考虑保证每台机器能分到唯一的机器标识。
1.2 基于Redis 的分布式主键
有一种分布式主键的实现方式是基于Redis 的[7],Redis 的自增命令可以很好地提供自增主键,但特别依赖Redis,也不是完美的实现方式。 若Redis 宕机,又没有开启持久化,会导致主键出现重复,对Redis 的性能造成影响,同时,易于他人通过主键推测系统规模。 所以,没有特殊需求定制全局自增的主键,不建议使用这种方式。但在某些特殊场景中,Redis 自增主键有着很大效果。 此外,通过Redis 的过期机制,也可以很好地模拟出定期自增主键,这种类型的主键在很多场景都有着广泛的应用。Redis 在缓存和分布式协调方面也有着广泛的应用[8],已经成为开发领域内不可或缺的基础组件。
1.3 基于MySQL 的号段模式主键
有一种分布式主键的生成方式是通过MySQL 数据库的号段模式[9],向数据库申请取得一段范围数据的使用权,其他节点将不再使用这段范围数据,以此保证数据的唯一[10]。 分配号段时,需要分布式锁保证分配范围不会出现多分配的问题。 号段模式的问题在于如何决定号段范围的大小,分配太大,服务重启会导致范围失效,浪费一定数量的范围;太少,容易频繁触发分布式锁,并频繁触发数据库操作,影响性能。 当然,号段的优点也很明显,主键可以从0 开始,生成的主键比较短[11],对于前端展示比较友好,也可以弥补雪花算法主键长的缺点。
1.4 Go 语言介绍
Go 语言可以直接编译成机器码[12],不依赖其他库,部署方便,属于静态语言。 在语言层面就支持并发,是Go 最大的特色,可以充分利用多核的优势。 Go内置Runtime,支持垃圾回收,而且简单易学,只有25个关键字,但是表达能力非常强大,几乎支持了大多数面向对象语言的特性:继承、重载、对象等[13]。 基于Go强大的能力,其广泛应用于区块链开发、物联网开发以及云原生基础服务支撑,K8s,Docker,Etcd 等都是基于Go 语言开发的,可见Go 语言的发展前景极好。 考虑到Go 语言兼顾高性能和开发效率,贴近K8s,可以很方便地使用K8s 进行部署,因此使用Go 语言开发一个分布式主键系统[14]。
2 搭建分布式主键系统
2.1 分布式主键系统总体设计
搭建分布式主键系统可以解决以下问题:(1)统一分布式主键服务[15],通过Rpc 的方式去使用分布式主键,方便业务端的开发。 (2)优化雪花算法的缺点,包括时间回拨、机器id 分配以及上限问题。 (3)可以同时满足多种分布式主键的实现,方便地扩展业务端的需求,只需直接调用即可。
分布式主键系统核心整体调用如图2 所示,分布式主键系统可以让业务系统直接接入,然后,就可以直接使用各种类型的分布式主键。 非常显著地减轻了业务端的压力。 同时,业务端调用分布式主键系统通过Grpc 的方式,这就保证了调用的实时性。 业务端调用分布式主键系统如图3 所示,通过Ingress 的方式路由到分布式主键服务集群。
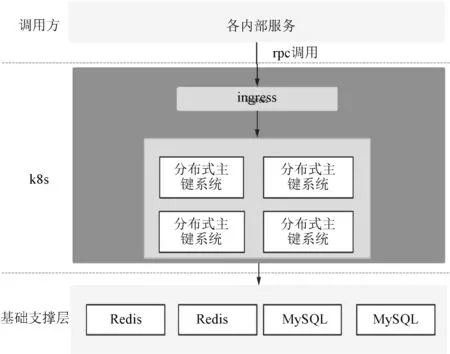
图2 分布式主键系统
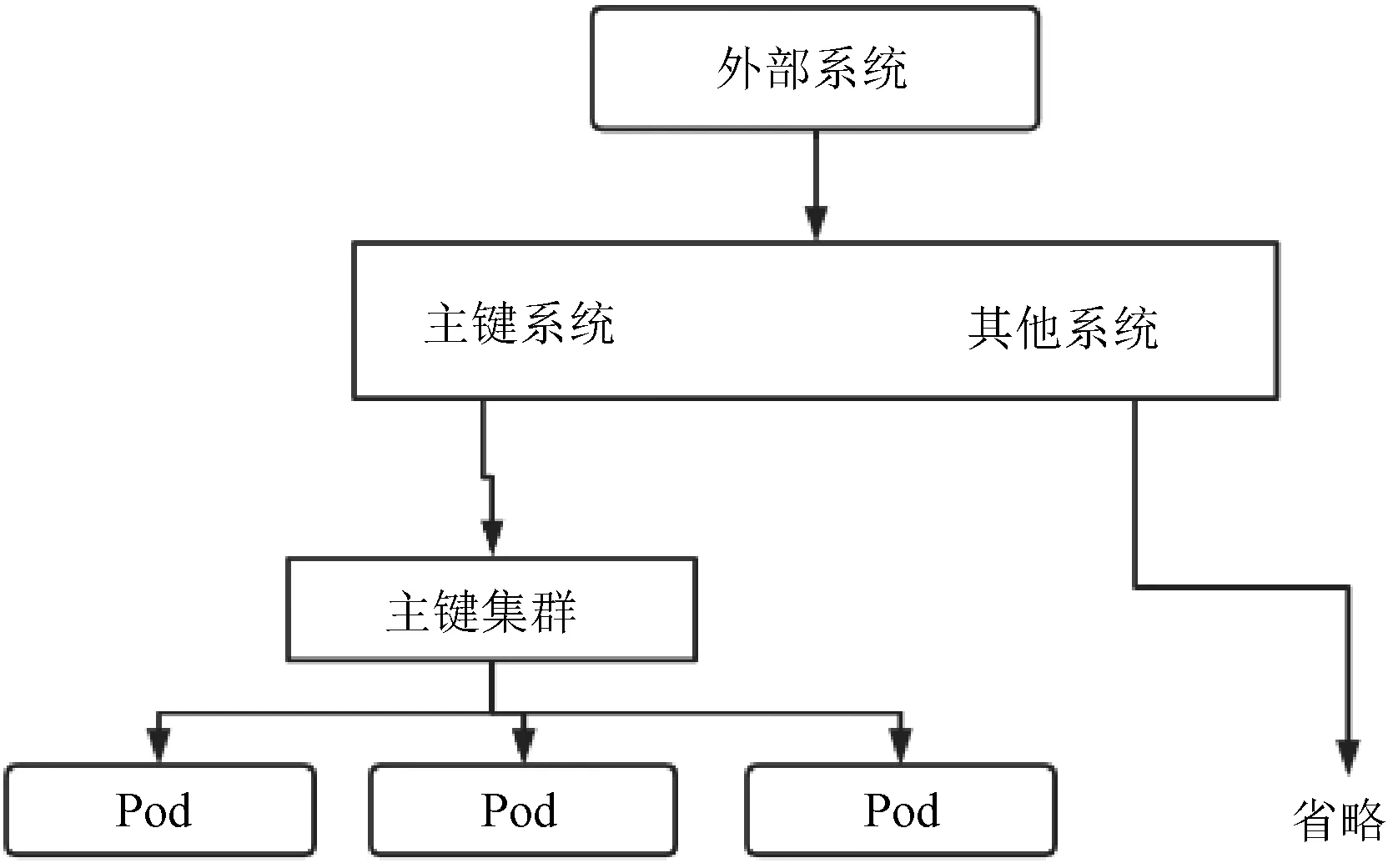
图3 业务端调用分布式主键系统
2.2 Grpc 协议字段设计
该分布式主键系统采用Go 语言开发,使用Grpc远程过程调用,Grpc 是一个高性能开源的统一的RPC调用框架。 RPC 即远程过程调用,使得应用程序之间可以进行通信,而且也遵从Server/Client 模型。 使用的时候客户端调用Server 提供的接口就像调用本地的函数一样。 Grpc 最大的好处就是快和体积小,Grpc 可以通过Protobuf 定义接口,Protobuf 可以将数据序列化为二进制编码,这可以大幅减少数据量,从而提升传输 性能。 Grpc 的通信字段定义如图4 所示。

图4 Grpc 的通信字段定义
该Proto 文件提供了接口的请求结构和返回结构,并定义了一个服务,对外提供了获取主键的方法。 该分布式唯一主键系统目前对外提供3 种类型的分布式主键:(1)基于MySQL 数据库号段的;(2)基于Redis自增的;(3)基于雪花算法的。
2.3 实现基于MySQL 的号段模式的主键
基于MySQL 号段模式实现分布式主键是以前许多公司经常采用的方法。 号段可以理解为批量获取。 比如,开发人员会经常批量获取多个数据缓存在本地,提升系统效率。 当需要分布式主键时,就向数据库获取一个号段,如[1,10 000],于是,当需要主键时,就可以在这个范围自增,等用到了10 000,再使用则超过了范围,此时需要再次向数据库申请号段。 数据库的表设计如图5 所示。

图5 数据库的表设计
这个数据表是用来记录自增步长以及当前自增id的最大值,对于自增逻辑的判断则是在系统实现中做的。 这种方案不会强依赖数据库,即使数据库宕机,系统缓存的号段也可以再使用一段时间。 不过,该分布式主键系统是一个集群,集群多个服务会发生同时申请号段的情况。 在这种情况下,就会发生数据一致性的问题,解决办法有:(1)使用数据库的乐观锁,加一个Version 字段,在修改的时候只有跟以前的Version 一样才会成功;(2)使用分布式锁。 本文采用第二种方式。
2.4 实现基于Redis 的自增模式主键
这个方式的实现很简单,通过Redis 的Incr 命令实现。 由于Redis 的单线程特性,天生就支持并发。 但是,这种方式也有着缺点:(1)过于依赖Redis,如果Redis 出了问题,就无法生成主键;(2)Redis 需要开启持久化,要不然Redis 重启就会导致主键重复;(3)性能比较依赖Redis。 所以,基于Redis 的主键有着特殊的使用场景。
2.5 实现并优化雪花算法
针对时间回拨问题,改进的思路是:启动时间采用的是“历史时间”,每次请求只增加序列值,序列值满了,然后才把“历史时间”增加1。 具体做法是,在进程启动后,把当前时间(实际处理采用了延迟20 ms 启动)作为这个机器进程的时间戳中的起始时间字段。每次有数据请求时,序列号自增1,当序列号到达最大值,时间戳字段自增1,也就是时间增加1 ms,然后序列号从0 开始计算。 当特别巨大的请求过来时,进程中的时间戳达到真实的当前时间戳,这个时候如果出现时间回拨,就采用业界常用的方式,首次等待,然后等待一会儿回拨时间,时间超过一定量就抛出异常。
针对机器id 分配和回收问题,机器id 一共占了10个二进制位, 也就是最多1 024 个。 其中5 个Workerid,5 个Dataid。 id 的分配通过Redis 实现,核心代码如图6 所示。

图6 核心代码
其逻辑就是,Redis 存了Workerid 和Dataid,各进程通过分布式锁的方式去取1 个Workid 和Dataid 联合唯一的id。
3 结语
通过Go 语言结合Grpc 的方式开发了分布式主键系统,支持3 种分布式主键,对外提供RPC 远程调用。这个分布式主键服务可以极大地提高开发效率,让分布式主键跟业务开发解耦。 同时也解决了雪花算法存在的几个缺点,让雪花算法生成主键更加可靠。
猜你喜欢
商品与质量(2019年34期)2019-11-29 03:25:51
教育界·中旬(2019年7期)2019-11-24 05:53:39
计算机与网络(2019年3期)2019-09-10 07:22:44
测控技术(2018年5期)2018-12-09 09:04:46
发明与创新·大科技(2017年8期)2017-08-17 21:09:52
信息安全研究(2016年4期)2016-12-01 06:07:05
无线互联科技(2015年18期)2016-03-07 00:55:40
中国信息化·学术版(2013年1期)2013-05-28 05:53:24
无线互联科技(2013年7期)2013-04-29 03:43:54
电脑迷(2012年9期)2012-04-29 03:54:14
