
基于中文年报管理层讨论与分析文本特征的上市公司财务困境预测研究
2018-08-11 02:31陈艺云贺建风覃福东
预测 2018年4期
陈艺云, 贺建风, 覃福东
(华南理工大学 经济与贸易学院,广东 广州 510006)
1 引言
自2014年“11超日债”违约以来,我国公司债券市场违约事件频发,信用风险问题引起了监管层、投资者和学术界的普遍关注。在经济呈现新常态、增长速度趋缓、公司企业经营业绩下滑的情况下,准确评价公司企业的信用风险从而准确预测其财务困境对于强化信用风险管理,防范信用危机和债务危机有着重要的理论与现实意义。
以往对公司企业财务困境预测的研究都是以财务数据、市场交易数据等定量数据为基础的,很少考虑公司公告、新闻报道、在线评论等公开的定性信息,实际上标准普尔早在2003年就指出,“定性信息中包含着区分信用风险的重要信息”[1]。大数据时代的到来使得以定性文本信息为主的非结构化数据在金融市场预测中将发挥更为重要的作用,也为有效分析文本信息提供了新的技术和方法。本文通过对中文年报管理层讨论与分析部分特征词的抽取与文本内容的量化分析,为公司企业的财务困境预测和信用风险管理提供新的思路和方法,拓展了对公司信息披露文本内容的挖掘分析,对于更有效地分析新闻报道、在线评论等其他文本内容,从而准确预测财务困境和管理信用风险都有重要的借鉴和参考价值。
2 文献回顾与理论分析
公司企业财务困境的预测是理论和实务界关注的热点问题之一,但以往的研究大多是以财务数据、市场交易数据等定量数据为基础的,如Altman[2]基于财务比率的 Z 评分模型,Merton[3]基于股票市场交易数据的结构模型,Shumway[4]结合财务比率和市场交易数据提出的风险模型等,这些研究存在着低估违约概率、难以实时预测违约的问题。一些学者将此归因于公开信息的不完全,认为应以不完全信息假设为基础来进行最优估计[5],这种方法更接近现实,但忽略了传统理论和方法的最大缺陷,即只注重对财务数据、市场交易数据等定量数据的分析,而没有考虑公司公告、新闻报道、在线评论等公开的定性信息。
从上市公司信息披露的内容来看,财务数据只是其中的一个组成部分,可以很直观地反映公司的经营和财务状况,但信息披露报告更多还是以描述性文本内容为主,这是公司和经理人具体说明并分析公司现状、发展前景,从而与潜在的投资者进行沟通的重要机会。通过这些描述性的文本内容,经理人可以达到吸引投资者,促使其购买更多股票或将更多资金放贷给公司,并抑制其出售公司证券冲动的目的[6]。当公司经营和财务状况开始恶化时,经理人的这种激励会更为强烈,信息披露的文本内容就会随之出现变化,这样以来,公司信息披露的文本内容就有可能为判断经理人与公司的违约倾向提供重要线索。
然而,由于投资者对信息的分析和处理存在着收益与成本的均衡[7],公司可以通过提高负面信息的分析成本来弱化市场的反应[8]。对于正面信息,经理人倾向于以更直接更清晰的方式进行陈述,使好消息等到更充分更及时的反映;对于负面信息,经理人则倾向于以复杂模糊的方式来表达,如使用更多的生僻词、更冗长的句子来进行描述,可能会以更多中性或含义模糊、而不是悲观和负面的词语来表达对未来前景的负面信息[9],这样以来,公司信息披露文本的措辞和风格就可能会反映出其真实的经营状况以及经理人对未来的预期,从而为评价其信用风险、预测财务困境提供新的信息。
尽管Tennyson等[6]在1990年就通过对公司年报管理层讨论与分析和董事长致辞部分描述性内容的主题分析指出了文本信息对于公司破产预测的重要作用,但在信用风险评价和财务困境预测中考虑定性文本信息的研究还很少见,而且大多局限于对新闻报道和网络舆情的分析[10~13]。从信息获取渠道来看,公司的信息披露比外部的新闻报道、社交媒体信息更为可靠,许多对股票市场的研究都表明公司年报的文本内容,如管理层讨论与分析(Management Discussion& Analysis,MD&A)部分的文本内容确实可以为预测公司未来经营业绩提供增量信息[14~16],而 Cecchini等[17]基于本体分析的研究也证实英文年报MD&A的措辞特征确实可以提高破产预测的准确性。
国内对中文年报管理层讨论与分析的研究大多以人工阅读或打分方法为主[15,16],难以适用于对大样本的分析,一些学者的自动文本分析侧重于对其言语的有效性或文本内容相似性的分析[18,19],很少从用词的角度来进行分析。谢德仁和林乐[20]在对上市公司业绩说明会文本内容的分析中引入了国外学者基于英文年报用词构建的词典来分析管理层语调,但这种方法对于中文用词的特殊性考虑不足。由于对财务困境公司和正常公司的区分是一个典型的分类问题,两类公司年报的用词可能会存在着一些显著的差异,那么通过对文本特征词的提取和分析就可以实现对文本内容的量化并用以预测财务困境,为此,本文引入文本分类中文本特征的提取方法对两类公司管理层讨论与分析部分的文本内容进行对比,从中抽取能区分两类公司的特征词,由此构建文本内容的量化指标,将其加入到财务困境预测的建模中,并采用不同预测方法来检验该文本量化指标能否提高预测的准确性。
3 研究设计
3.1 实证方法的选择
在财务困境预测的研究中,国内外学者采用了多种方法和技术,主要分为两大类:一是基于统计模型的判别分类方法,如线性判别分析、Logistic回归、Probit回归等;二是人工智能方法,如决策树、人工神经网络、支持向量机、进化计算等。为检验本文构建的文本量化指标在财务困境预测中的作用,确保研究结论的稳健性,本文选择了上述两类方法中应用最广泛、代表性最强的Logistic回归和支持向量机来进行实证分析。
3.1.1 Logistic 回归模型
在信用风险预警的传统统计方法中,Logistic回归是对二分类因变量进行建模时最常用的多元统计方法,可以解决非线性分类的问题,对变量的分布没有具体要求,判断的准确率较高,其一般形式如下

其中pi表示事件发生的概率,Xi表示解释变量。
3.1.2 支持向量机
支持向量机是一种基于统计学习理论的分类方法,在解决小样本、非线性及高维模式识别中有许多优势,其目的在于构建一个超平面,使得高维特征空间内两个类的边缘间隔最大化,其优势在于利用核函数来提供准确率高的分类模型,并借助正则项避免模型的过度适应,同时避免局部最优和多种共线性的影响。支持向量机求解的最优化问题如下所示
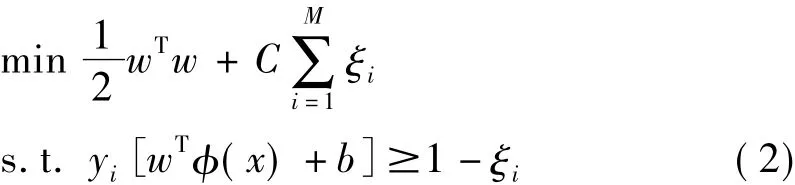
其中 i=1,2,…,M,ξi≥0 表示惩罚因子 C 决定的误差界限,yi表示训练集中的类别,Φ(x)表示从输入层到特征层的非线性转换,w和b分别代表权重和阈值。支持向量机通过二次规划,以核函数K(x)=K(xi,xj)代替最优分类平面的点积Φ(xi)T·Φ(xj)来求解上述最优化问题,而核函数的形式有多种,如线性核函数、多项核函数、高斯核函数等,本文在这里选取了高斯核函数来进行建模。
3.2 财务比率的选择
财务比率是上市公司财务困境预测的基础变量,在结合已有文献的基础上[21~23],考虑数据的可得性,本文从偿债能力、营运能力、盈利能力、发展能力、每股指标、风险水平等角度选取了32个财务比率,包括固定资产比率(FIX)、流动比率(CURRENT)、速动比率(ACID)、营运资金(WC)、利息保障倍数(INTEREST)、经营活动产生的现金流净额/流动负债(CASH)、现金流利息保障倍数(CINTEREST)、资产负债率(LEV)、有形资产负债率(TLEV)、权益乘数(EM)、产权比率(EQUITY)、权益/负债(ED)、总资产增长率(AGROWTH)、权益增长率(EGROWTH)、财务杠杆(FL)、经营杠杆(OL)、综合杠杆(CL)、营业周期(OC)、总资产周转率(TAT)、每股收益(EPS)、每股营业收入(OIPS)、每股营业利润(OPPS)、每股净资产(BPS)、每股留存收益(REPS)、每股经营活动产生的现金流净额(CPS)、每股现金净流量(NCPS)、投入资本回报率(RIA)、资产报酬率(ROA)、资产净利率(JROA)、净资产收益率(ROE)、营业利润率(OPM)和总营业成本率(OCR)。
3.3 文本内容的量化分析
3.3.1 特征词的提取方法
由于公司经营和财务状况会对其信息披露文本内容的措辞和风格产生影响,本文采用R语言开源中文分词工具JiebaR来进行中文分词,然后利用卡方检验的方法来选取可以区分财务困境公司和正常公司的特征词。按照Yang和Pedersen[24]的研究,以N表示训练语料中文档的总数,以A表示属于Cj类且包含特征词ti的文档频数,以B表示不属于Cj类但包含特征词ti的文档频数,以C表示属于Cj类但不包含特征词ti的文档频数,以D表示不属于Cj类且不包含特征词ti的文档频数,则特征词ti的卡方值为

根据卡方分布一个自由度的临界值就可以确定特征词ti是否能显著区分财务困境公司和正常公司,由此可以构建财务困境公司和正常公司的特征词表。
3.3.2 特征词的权重设置
本文采用与 Cecchini等[17]相似的方法,考虑特征词在分类中的相对重要性,通过对词频-逆向文档频率 (TF-IDF,Term Frequency-Inverse Document Frequency)的扩展来设置权重。特征词ti的权重wi可以表示为

其中j表示文档,k和l表示类别,tfijk表示特征词i在k类j文档的词频,N表示文档总数,n表示包含特征词i的k类文档总数。
3.3.3 基于文本分析的违约倾向指标的构建
通过选取特征词并设置其权重,就可以对每个信息披露文本中包含的特征词进行统计,由此可以构建基于文本分析的公司违约倾向指标(TTD,Tendency toward Default):
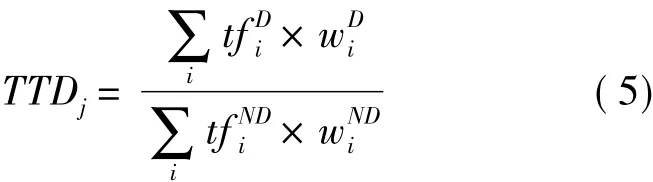
其中TTDj表示公司j的违约倾向指标表示财务困境公司特征词ti在公司j信息披露文本中的词频表示特征词ti对财务困境公司的权重,表示正常公司特征词ti在公司j信息披露文本中的词频表示特征词ti对正常公司的权重。TTD值越大,文本内容中就使用了相对更多负面意义的词语。
3.4 样本和数据
3.4.1 样本
参照国内在预测上市公司财务困境时的通常做法,本文以因财务状况异常而被特别处理(ST)作为上市公司出现财务困境的标志,在选取样本的时候采用配比原则来选择非ST公司作为配对样本。为了确保实证结果的稳健性,本文按照行业相同,资产规模相近的原则来选择非ST公司作为配对样本,在配比的比例上分别按1∶1和1∶2来选择。由于上市公司的年报是在年度终了4个月内编制发布的,因而t-1年年报的发布与其在t年是否被特别处理这两个时间是同时发生的,为此本文参照石晓军等[25]的做法,采用了上市公司t-2年的数据建立模型来预测其是否会在t年出现信用风险。基于上述条件,本文选取了2011年~2017年期间199家被ST的上市公司作为财务困境公司样本,按行业相近、规模相近的原则选择了398家非ST公司作为配对的正常公司样本,对应的数据期间为2009年~2015年。
考虑到特征词的选取应考虑足够多的样本,因而不管实证分析时财务困境公司和正常公司的比例是1∶1还是1∶2,本文以全部样本为基础来选取特征词。通过预处理和中文分词后,在选取特征词时,由于卡方检验难以排除一些并不能区分财务困境公司与正常公司的词语,如“现金流量”、“经营活动”、“投资者”、“管理办法”、“供应商”、“子公司”等会计或行业常用词,因而本文对通过卡方检验的词语进行了筛选,最后选定了93个财务困境公司的特征词以及98个正常公司的特征词,然后计算各个特征词的权重。
3.4.2 数据
本文的财务数据都来自于国泰安数据库,中文年报来自于巨潮资讯网,从中截取了管理层讨论与分析的文本内容。对于违约倾向指标(TTD)和财务比率能否反映财务困境公司和正常公司之间的显著差异,对所有变量进行了非参数 Mann-Whitney检验,结果显示除了财务比率变量中营业周期(OC)和每股现金净流量(NCPS)不显著以外,包括违约倾向指标(TTD)在内的其他全部变量都存在显著性差异,可以用来区分财务困境公司和正常公司。对于违约倾向指标(TTD),正常公司的平均值为 0.08898,财务困境公司的平均值为0.23461,非参数检验的 Z 值为 -10.621,显著性水平为1%,表明财务困境公司在其年报的文本内容中确实使用了更多与财务困境相关的、有负面意义的特征词。
4 实证结果与分析
对于违约倾向指标在财务困境预测中的作用,本文采用Logistic回归和支持向量机两种方法来进行实证检验,同时进行样本内检验和样本外预测。首先不区分训练集和测试集,以全部样本(分1∶1和1∶2两种比例)进行样本内检验,分别按加入违约倾向指标(TTD)前后两种情况建模;然后再选取2011年~2015年的139家ST公司和配对样本作为训练集,分别采用两种方法进行建模,以2016年~2017年的60家ST公司和配对正常公司样本作为测试集对模型预测财务困境的准确性进行比较分析。判断标准主要有三个:一是TTD的加入能否提高分类的整体准确率(Accuracy);二是TTD的加入能否降低第一类错误(TypeⅠ error,将ST公司识别为正常公司)和第二类错误(TypeⅡerror,将正常公司识别为 ST公司)的概率;三是TTD的加入能否提高受试者工作特征曲线(ROC,Receiver Operating Characteristic Curve)的曲线下面积AUC(Area Under Curve),AUC是根据建模结果预测样本被ST的概率来计算的,取值范围为0.5~1,值越大表明样本内模型的拟合效果或样本外预测的准确性越好。
4.1 基于Logistic回归的分析
本文在采用Logistic回归分析时应用逐步回归的方法来剔除不显著的变量,首先不考虑违约倾向指标(TTD),然后再加入该指标,对模型的拟合程度和预测能力进行比较分析,同时根据违约倾向指标(TTD)是否会在逐步回归的过程中被剔除来判断其对财务困境模型构建的作用。
4.1.1 样本内检验
表1给出了1∶1和1∶2两种样本比例下Logistic逐步回归样本内检验的结果。由表1可见,样本比例不同,逐步回归选取的财务变量有所区别,是否加入违约倾向指标(TTD)也会导致财务变量选取的不同,但不管配比比例如何,加入违约倾向指标(TTD)后逐步回归都无法剔除且违约倾向指标(TTD)显著为正,即文本内容反映的违约倾向越强,公司出现财务困境的可能性越大。

表1 Logistic回归的样本内检验结果
然后从加入违约倾向指标(TTD)后模型的拟合情况来看,对数似然比(Log Likelihood)明显降低,而Cox&Snell R2和Nagelkerke R2都显著提高,AUC也有一定幅度的提高,可见违约倾向指标(TTD)确实提高了财务困境预测模型的拟合度;再从样本内预测能力来看,不管比例如何,违约倾向指标(TTD)的加入减少了第一类错误,在1∶2比例下也减少了第二类错误,整体准确率都有一定幅度的提高,可见违约倾向指标(TTD)确实提高了财务困境预测模型的预测能力,且主要体现在第一类错误的降低上,即减少了将财务困境公司误判为正常公司的概率,这对于信用风险管理有着非常重要的价值。
4.1.2 样本外预测
表2给出了Logistic逐步回归样本外预测的结果。由表2可见,在ST公司与正常公司的比例为1∶1时,违约倾向指标(TTD)的加入使得AUC和整体准确率都有一定幅度的提高,第一类错误和第二类错误都有所降低,其中第一类错误的降低更为明显;在提高配对比例,增加正常公司数量后,违约倾向指标(TTD)加入对预测效果的改进幅度有所下降,但同样可以提高整体准确率和AUC,降低第一类错误和第二类错误,同样对第一类错误的降低更为明显。由此可见,在采用Logistic回归方法时,文本内容反映的违约倾向指标(TTD)确实可以提高财务困境预测模型样本外预测准确性,而且与样本内检验一致,这主要还是体现在降低第一类错误,即将财务困境公司误判为正常公司的概率上。

表2 Logistic回归的样本外预测结果
4.2 基于支持向量机的分析
在采用支持向量机建模分析时,为了判断违约倾向指标(TTD)以及财务比率变量对财务困境预测建模的相对重要性,本文引入Cortez和Embrechts[26]提出的敏感性分析方法来计算违约倾向指标(TTD)加入前后各变量的相对重要性并进行样本内检验,然后再对加入违约倾向指标(TTD)前后支持向量机的样本外预测能力进行比较分析。
4.2.1 样本内检验
表3给出了支持向量机样本内检验的结果。由表3可见,样本比例较小时支持向量机的总体准确率更高一些,主要是因为第一类错误的概率相对要低很多,而样本比例扩大后,第一类错误的概率有显著提升;加入违约倾向指标(TTD)后,不管比例如何,第一类错误和第二类错误的概率都有所降低,同样对第一类错误的减少相对会更显著一些,同时整体准确率和AUC也都有一定幅度的提高。从敏感性分析的结果来看,配比比例的变化对财务比率变量在采用支持向量机建模时的相对重要性影响不大,而违约倾向指标(TTD)在两种比例下都进入了前十大重要变量,而且在比例为1∶2时在所有指标中排在第四位,重要性显著提高。由此可见,在采用支持向量机构建财务困境预测模型时,违约倾向指标(TTD)都发挥了重要的作用。

表3 支持向量机的样本内检验结果
4.2.2 样本外预测
表4给出了支持向量机样本外预测的结果。由表4可见,同样是在样本比例较小时支持向量机的总体准确率更高,而样本比例扩大后,两类错误的概率都有显著提升;从违约倾向指标(TTD)加入的影响来看,在比例为1∶1时,显著降低了第二类错误的概率,AUC也有显著的提高,整体准确率都有大幅度的提高,但在比例扩大以后,其影响有所降低,对于第二类错误的影响较小,只是降低了第一类错误的概率。从总体来看,在采用支持向量机方法的情况下,加入文本信息反映的违约倾向指标(TTD)同样可以提高财务困境预测模型的准确度。

表4 支持向量机的样本外预测结果
5 结论与启示
管理层讨论与分析部分的描述性文本内容是上市公司信息披露的重要组成部分,对这些文本信息的分析有助于了解公司的真实状况以及经理人对未来的预期,从而更准确地预测财务困境。本文以财务困境公司和正常公司年报管理层讨论与分析部分的文本内容为研究对象,采用卡方检验方法来提取反映财务困境和正常公司的特征词,通过对TF-IDF的扩展来设置特征词的权重,从而构建公司经理人违约倾向指标,并将该指标与财务比率变量相结合,采用Logistic回归和支持向量机的方法对违约倾向指标能否提供财务困境预测的增量信息进行了分析,结果表明不管财务困境公司与正常公司的配比比例是1∶1还是1∶2,在这两种财务困境预测模型的建模方法下,违约倾向指标的加入都可以提高财务困境预测模型的拟合度以及预测的准确性,降低出现误判的第一类错误率和第二类错误率。由此可见,上市公司年报文本内容的特征在一定程度上反映了公司的真实现状以及经理人对未来前景的预期,可以为财务困境预测和信用风险评价提供新的信息,而且这些信息可以通过自动文本分析的方法进行挖掘和获取,这对于信用风险管理机构,乃至于市场投资者分析上市公司的风险信息都有重要的借鉴价值。不过本文的研究局限于上市公司,难以适用于非上市的公司企业,但对于这些公司企业,可以通过对新闻报道、社交媒体等其他渠道文本内容的挖掘分析来实现,当然由于这些渠道的文本信息来自于企业外部,在具体方法和技术的选择上还需要进一步的研究。
猜你喜欢
词学(2022年1期)2022-10-27
计算机技术与发展(2022年8期)2022-08-23
计算机系统应用(2021年9期)2021-10-11
中学生数理化(高中版.高一使用)(2021年2期)2021-03-19
时代英语·高一(2020年1期)2020-05-15
文苑(2020年12期)2020-04-13
现代信息科技(2020年18期)2020-02-22
领导决策信息(2018年16期)2018-09-27
数学学习与研究(2017年3期)2017-03-09
人生十六七(2015年2期)2015-02-28
