
基于ARIMA模型的安徽省就业发展趋势分析①
2018-08-03 05:22雅文
佳木斯大学学报(自然科学版) 2018年4期
, 雅文,
(安徽财经大学a.统计与应用数学学院b.经济学院,安徽 蚌埠 233030)
0 引 言
经济增长、物价稳定、充分就业、国际收支平衡是各国政府管理经济的四大目标。目前,我国的就业形式越来越严峻,受到社会各界的广泛关注,成为各级政府亟待解决的重要难题。因此,收集相关就业信息和就业数据,建立有效且准确的预测模型,预测未来某一地区就业人口发展趋势,从而为政府制定就业政策提供科学依据,具有极为重要的现实意义。时间序列预测法是依据历史数据揭示系统动态结构和规律性的定量预测法,一方面考虑到事物发展偶然因素造成的影响,另一方面又承认事物发展的延续性[1]。为了消除随机因素产生的影响,利用历史数据进行时间序列预测分析,运用差分等方法对历史数据加以适当处理,进行趋势预测。传统的趋势外推预测方法是利用某种典型趋势现象特征进行预测,然而在实际现象中,许多时间序列资料往往并不具有这种典型趋势特征,采用此种趋势外推法建立的模型产生的随机误差项并不一定是随机的,从而影响预测效果[2]。ARIMA模型是一种预测精度较高的时间序列短期预测方法,适用于各类时间序列数据,是目前为止最通用的时间序列预测方法。基于以上研究,选取安徽省1978-2016年的就业人数为样本数据,运用Eviews 9建立ARIMA模型,并借助建立的模型预测安徽省未来六年的就业发展趋势,以期为制定就业政策提供科学依据。
1 模型的选取
1.1 ARIMA模型的基本原理
自回归求和移动平均模型(ARIMA)是指先将非平稳时间序列转化为平稳时间序列,然后将因变量对其滞后值以及随机误差项的现值和滞后值进行回归所建立的模型[3]。ARIMA模型根据对时间序列特征的预先研究,可以指定3个参数来分析时间序列,即自回归阶数(p)、差分次数(d)和移动平均阶数(q),记为{Xt}ARIMA(p,d,q)。ARIMA模型的基本结构如下:
式中:Φ(B)=1-φ1B-…-φpBp为平稳可逆ARMA(p,q)模型的自回归系数多项式;Θ(B)=1-θ1B--θqBq为平稳可逆ARMA(p,q)模型的移动平滑系数多项式;{εt}为零均值白噪声序列。只要通过适当的差分运算,任何非平稳的时间序列都可以实现平稳,进而进行ARMA模型的拟合。
1.2 ARIMA模型的建模步骤
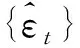
2 模型的建立
以安徽省1978-2016年就业人数为研究样本,运用Eviews 9软件进行数据分析,对1978年至2016年安徽省就业人数序列建立时间序列模型,预留出2012-2016年就业人数{Xt}进行预测,用于检验模型的效果,并对安徽省未来6年的就业人数进行预测。
2.1 数据来源及处理
主要研究安徽省1978-2016年的就业人数,数据来源于《安徽统计年鉴》。根据所收集的1978-2016年的数据,作出安徽省就业人数时间序列趋势图,如图1所示。观察1978年至2016年安徽省就业人数时序图(图1)可知,就业人数有一定上升趋势,表现为非平稳序列。为了进一步确定就业人数{Xt}序列的平稳性,运用ADF单位根检验进行判断,结果见表1。
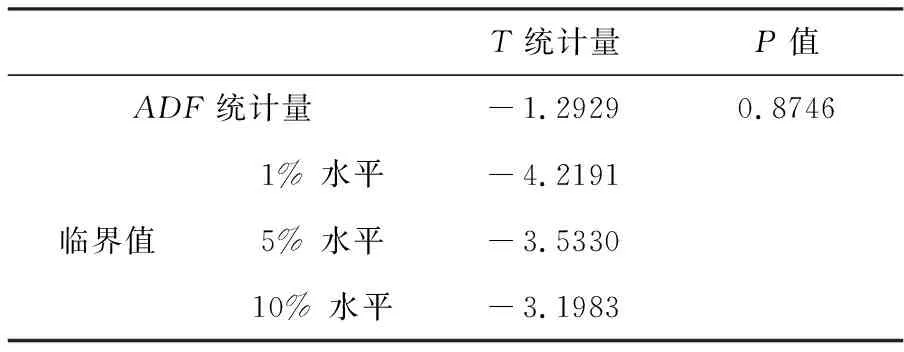
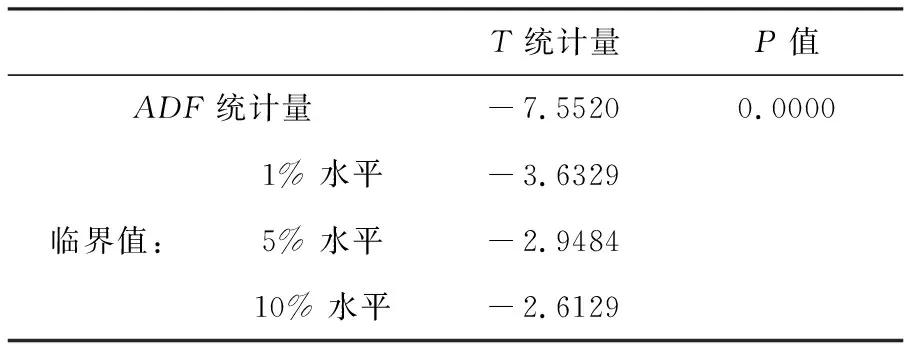
表1 序列的ADF单位根检验
由表1的ADF单位根检验结果可知,P值为0.8746,不能拒绝原假设,说明序列存在单位根,即原始序列为非平稳序列。为了使序列平稳化,对原始序列进行二阶差分化处理,将原始序列处理为平稳的时间序列,记为{Yt},该序列时序图如图2所示,并对其进行ADF单位根检验,检验结果见表2。由表2单位根检验结果可知,ADF统计量的值为-7.5520,小于在1%,5%和10%的置信水平下所对应的临界值,此外,值接近于零,应拒绝原假设,即新序列{Yt}不存在单位根,二阶差分处理过后的新序列{Yt}为平稳时间序列,这与时序图(图2)的直观观察是一致,符合ARIMA模型建立的基本要求。原始序列经过二阶差分得到新序列{Yt},作出新序列的自相关和偏相关图,如图3所示。
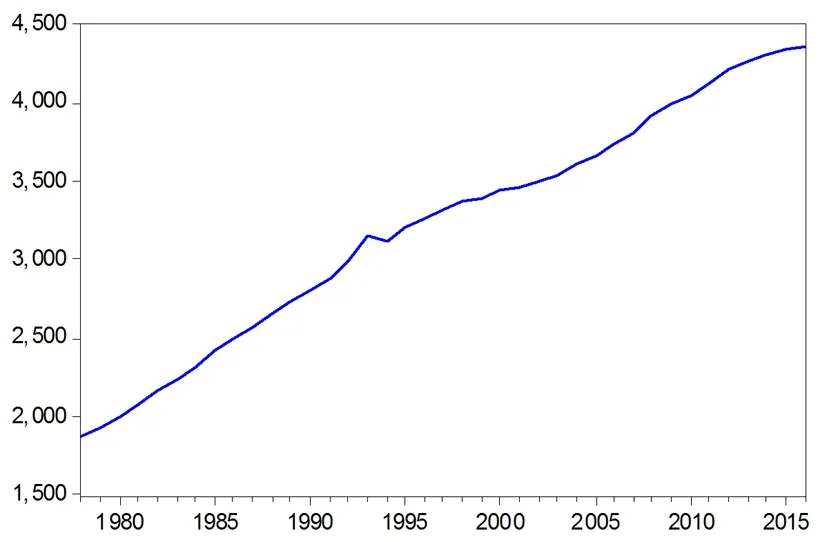
图1 1978-2016年安徽省就业人数的时间序列图
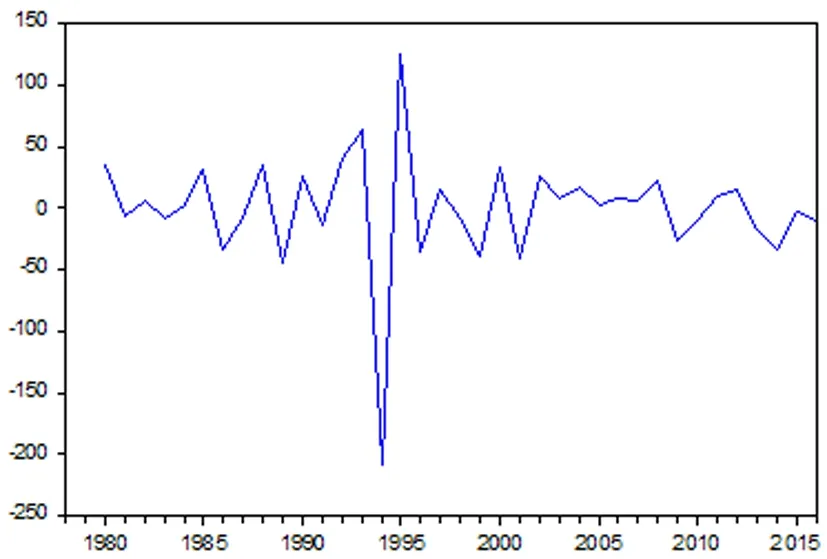
图2 1978-2016年安徽省就业人数二阶差分的时间序列图

图3 序列的自相关和偏相关图
T统计量 P值 ADF统计量 -7.5520 0.0000 1%水平 -3.6329临界值: 5%水平 -2.9484 10%水平 -2.6129
2.2 模型识别及参数估计
经过二阶差分处理后,新序列{Yt}已经化为平稳可逆的时间序列,符合ARIMA模型建立的基本要求。ARIMA模型的构建主要是对模型的阶数进行识别和对参数进行估计[5]。若自相关函数(ACF)在q阶截尾和偏自相关系数(PACF)在p阶截尾,则可初步判定模型为ARIMA(p,2,q)。通过观察偏自相关函数可以看出,p可以取值为1,也可以取值为2;通过观察自相关函数可以看出,q可以取值为1。根据以上结论,初步设定的模型为ARIMA(0,2,1)、ARIMA(1,2,0)、ARIMA(1,2,1)、ARIMA(2,2,0)、ARIMA(2,2,1)。通过自相关和偏相关系数法确定的ARIMA模型的阶数有一定的主观误差,可以使用AIC准则法和SC准则法综合确定模型参数[6]。根据AIC准则、SC准则确定模型参数时,一般认为,使得AIC和SC准则函数值较小的模型阶数往往比较接近真实模型的阶数。利用Eviews 9软件,经逐次尝试,得到各个ARIMA(p,2,q)模型信息的对比表,结果见表3。
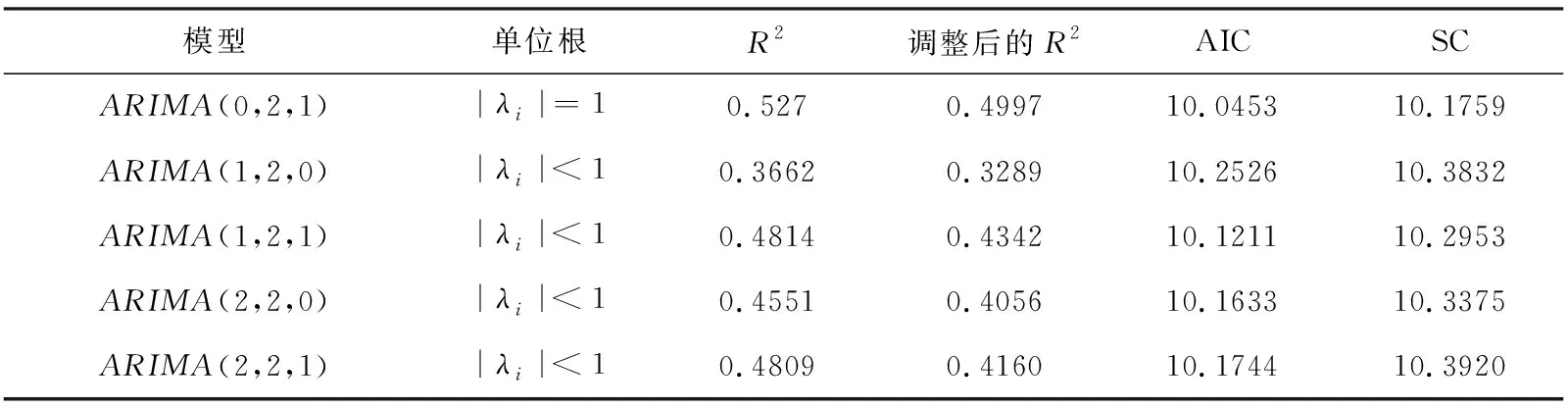
表3 备选模型对比表
根据AIC准则和单位根小于1的原则,选取ARIMA(1,2,1)作为最优模型,模型的参数估计结果见表4。由表4,可以得到{Yt}序列的ARIMA(1,2,1)的拟合结果为:
Yt=-0.8800-0.2512Yt-1+εt-0.6779εt-1
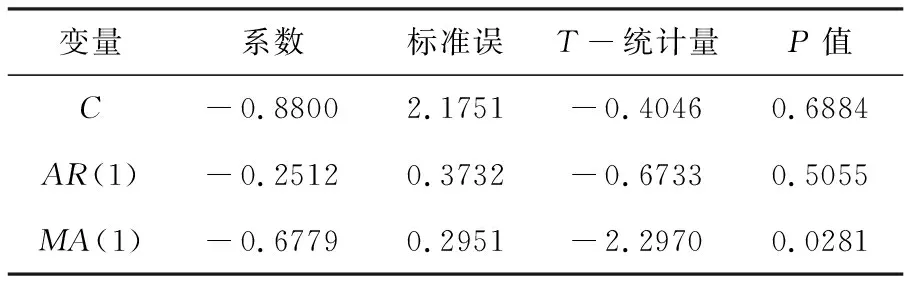
表4 序列的参数估计表
2.3 模型检验
在对ARIMA(1,2,1)模型进行参数估计后,还应对拟合模型的适应性进行检验,实质是对模型残差序列是否是白噪声序列即纯随机性序列进行的统计检验。若残差序列不是白噪声序列,说明模型中的一些重要信息还没被提取出来,应对模型的阶数进行重新设定[7]。拟合模型的适应性检验通常有两种方法,一种为对残差进行纯随机性检验,另一种为对残差χ2的检验。运用Eviews 9对残差进行χ2检验,检验结果如图4所示,ACF和PACF与0都没有显著差异,Q统计量的p值远远大于0.05。检验结果表明,残差序列是纯随机的,为白噪声序列。模型已经提取了大部分有规律的信息,模型拟合效果较好。
3 模型的预测
经过模型识别、参数估计、模型检验,得到一个准确且有效的预测模型,适用于安徽省就业发展趋势的短期预测。为了检验ARIMA(1,2,1)模型的预测精度,选取平均绝对百分误差(MAPE)和希尔不等系数(TIC)[8]这两个指标对于模型的拟合效果进行检验,MAPE和TIC的计算公式如下:
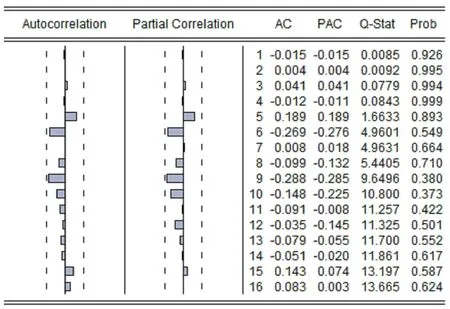
图4 ARIMA(1,2,1)模型残差序列的自相关-偏自相关分析结果
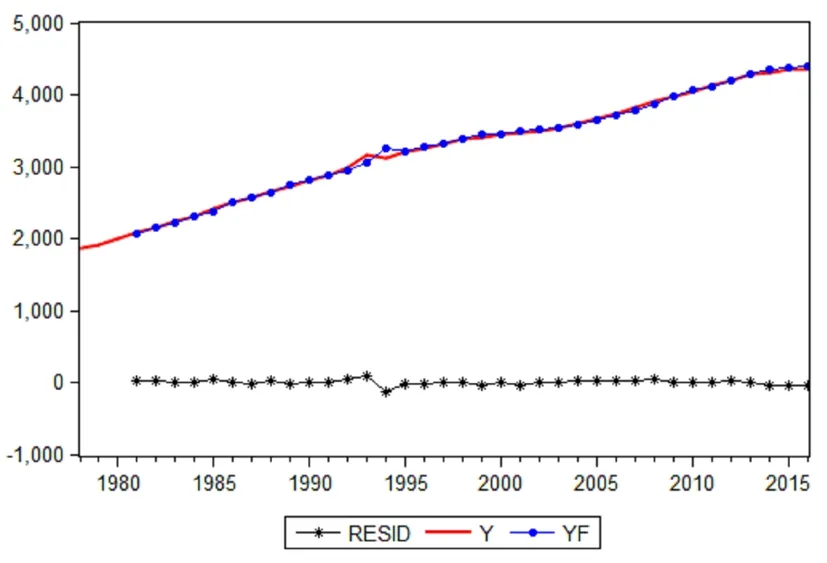
图5 模型的预测拟合图
其中:MAPE<10,认为预测精度较高;TIC介于0-1之间,数值越小,表明拟合值与真实值间的差异越小,预测精度越高。
通过分析1978-2016年安徽省就业人数,得到的ARIMA最优预测模型ARIMA(1,2,1),利用ARIMA(1,2,1)模型,得出1978-2016年的就业人数并与真实值比较,结果如图5所示。观察图5,预测序列数据(YF)的趋势与原始序列数据(Y)的趋势大体保持一致,残差曲线(RESID)几乎是一条为零的曲线。运用Eviews 9对所选取的两个检验模型预测精度的指标进行计算,得到MAPE=0.7003,TIC=0.0050,可以认为运用ARIMA(1,2,1)进行预测,预测精度高,模型合适。
用ARIMA(1,2,1)模型预测2012-2016年的安徽省就业人数,并将预测值与真实值进行比较,结果见表5。观察表5可知,模型样本数据预测的相对误差均小于1%,平均相对误差约为0.6%,预测值与真实值差距非常小,ARIMA(1,2,1)模型预测精度极高。利用1978-2016年的数据建立的ARIMA(1,2,1)模型来预测安徽省2017-2022年的就业人数(见表6)
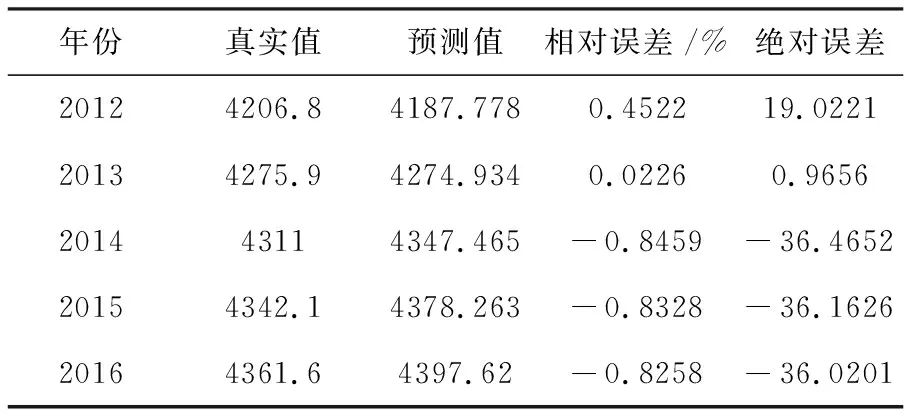
表5 真实值与预测值的比较

表6 模型对2017-2022年安徽省就业总人数的预测
4 结 语
从《安徽省统计年鉴》中,选取了1978-2016年安徽省就业人数实际值为样本数据,运用时间序列分析方法对安徽省就业人数进行预测分析。主要结论如下:
(1)建立的安徽省就业发展的ARIMA(1,2,1)模型,模型的残差序列为白噪声序列,表明模型的拟合效果较好,相关信息提取充分。ARIMA(1,2,1)模型的平均绝对百分误差MAPE值与希尔不等系数TIC值分别为0.7003,0.0050,模型预测精度高。因此,建立的ARIMA(1,2,1)模型不仅可以用于安徽省就业人数的预测,还可以应用到其他省份和国家的就业人数的预测。
(2)运用建立的ARIMA(1,2,1)模型,对安徽省2017-2022年就业人数进行预测并将其与历史数据进行对比发现,在接下来的6年里,安徽省就业人数总体趋势还在逐年增加,年均增长率维持在0.87%左右,增长幅度较之前略有下降,表明在未来一段时间内安徽省就业问题仍然很严峻。
针对模型预测的安徽省就业人数变化趋势,结合安徽省就业发展的实际情况,提出以下建议: 政府及相关部门应深入分析安徽省就业人数增长的原因,针对不同原因提出不同的应对措施,为安徽省就业发展规划提供理论依据;政府及相关部门应该积极落实就业的各项政策,通过政策扶持促进就业;重视和大力实施全民创业工程,让创业带动就业;从各方面加强职业培训,把更多的人培养成技能型人才,以技能促进就业。
猜你喜欢
华东师范大学学报(自然科学版)(2021年3期)2021-06-03
中国市场(2018年32期)2018-12-18
教育教学论坛(2018年39期)2018-09-25
教育教学论坛(2017年38期)2017-09-14
投资北京(2017年2期)2017-03-15
湖南大学学报·自然科学版(2015年1期)2015-04-20
统计与决策(2015年11期)2015-02-18
舰船电子工程(2010年2期)2010-08-11
