
基于最长公共视觉词串的图像检索方法
2018-08-01 07:46段立娟许少武
计算机工程与应用 2018年15期
苗 军,崔 嵩,段立娟,张 璇,许少武
1.北京信息科技大学 计算机学院 网络文化与数字传播北京市重点实验室,北京 100101
2.北京工业大学 信息学部,北京 100124
1 引言
基于内容的图像检索(Content-Based Image Retrieval,CBIR)是与人类检索图像过程更为接近的图像检索方式。理想的基于内容的图像检索可以跨越语义鸿沟,让计算机理解图像的内容,从而根据对于图像的理解检索对应的图像。这个检索过程通常被建模为图像特征表达、相似性度量和后处理过程三个部分。其中图像的特征表达和相似性度量是跨越语意鸿沟,使计算机理解图像的关键,也是影响图像检索准确性的最主要问题。
“词袋”模型(Bag-of-Features,BoF model)借鉴自文本检索[1],并在图像检索中取得了较好的结果。“词袋”模型主要分为三个步骤。第一步,提取图像局部特征(如SIFT特征);第二步,聚类图像中的局部特征,构建视觉词码本;第三步,将图像特征映射到视觉词码本上,得到该图像中视觉词出现的频率直方图。这一映射可以看作特征量化的过程。特征量化提高了图像特征的鲁棒性,降低了特征的维度,但损失了视觉词之间潜在的空间关系,影响对于图像检索至关重要的距离的表达。
为进一步提高检索的性能,需要引入空间信息来减少“词袋”模型中视觉词带来的歧义。一些研究者对于空间信息的引入做了深入研究[1-7]。其中,许多图像检索模型在后处理过程中引入空间信息来对“词袋”模型的结果进行重排序,如RANSAC方法[2]和邻近特征一致性方法(neighboring feature consistency)[1]。这些方法表明加入空间信息对于检索质量有提高作用,但其计算复杂度通常较高。另一方面,Passalis等人在他们的工作中将熵优化策略引入词袋的构建中,提出了熵优化词袋模型(Entropy Optimized BoW,Eo-BoW)[8]。此外,Mohedano等人尝试将BoF与CNN结合以提高检索速度,尽管在实验数据集上取得了一定成效,但却存在对干扰图像敏感的问题[9]。
由于二维图像是三维场景在一个二维平面上的投影。场景中的不同物体的位置关系在二维图像中得到了一定程度的保持。通常描述空间关系的方法有两种:基于目标的描述和基于关系的描述。基于目标的描述方法先提取图像中目标的坐标,然后通过对坐标进行空间位置划分来实现对图像的描述。常用的基于目标的描述方法有网格法、四叉树[10]、二叉树、k-d树等。基于关系的描述是通过分离空间关系和视觉信息,抽象化目标之间的空间位置关系,对抽象的目标关系进行建模分析。本文提出一种基于最长公共视觉词串的方法引入图像中目标间的空间位置关系,利用视觉词来构建视觉词串,并采用最大似然准则衡量词串间的相似度。并通过实验验证了提出方法对于图像检索的有效性。
2 基于最长公共视觉词串的图像检索
目标物体的位置关系是图像的重要特征之一。空间关系是一种较为模糊的概念,它很难用一个确定的概念来描述清楚,通常这种概念是在一组限定的条件中进行描述的[11]。空间关系通常包括朝向关系和拓扑关系。朝向关系指目标的各部分之间或整体间的朝向。可以使用目标之间的距离或者目标与参照点之间的夹角来衡量。拓扑关系是目标在参照点的平移、旋转以及尺度变换下不发生变化的关系,强调目标间相对位置关系。为表示图像中目标的朝向关系和拓扑关系需要获得图像的2-D串表达。
2.1 目标位置关系的2-D串表达
图像中目标间的位置关系可以利用目标物体在两个正交方向上的投影转化为两个1-D的排序表达,这样的表达可以表示目标间的拓扑关系和朝向关系。借鉴符号图的2-D串表达[12],一幅自然图像也可以表示为视觉词的2-D串。首先,将图像中的物体表示为视觉词,将每个视觉词看作一个符号向x方向与y方向进行投影。其中,“词袋”模型提取的局部特征即是视觉词的一种表示。为表示视觉词在两个方向上的排序,利用如下符号表示规则:“x:”或“y:”表示在X或Y轴上投影得到的视觉词串,其中在X轴投影得到的串叫x串,在Y轴投影得到的串叫y串。“<”表示排序关系,代表视觉词的投影沿X轴从左向右排序,沿Y轴从下向上排序。“=”表示重叠关系,代表两个视觉词的投影并列排序。则可利用上述规则构建图像目标位置关系的2-D串。
以一幅图像包含不同位置的4个不同目标为例,如图1所示。其在X轴的投影顺序为A、B、C、D,在Y 轴的投影顺序为D、B、C、A。应用上述规则可以得到图像目标位置关系的2-D串表达:
x:A<B<C<D
y:D<B=C<A
并简化为:
x:A<B<C<D
y:D<BC<A

图1 (a) 原始图
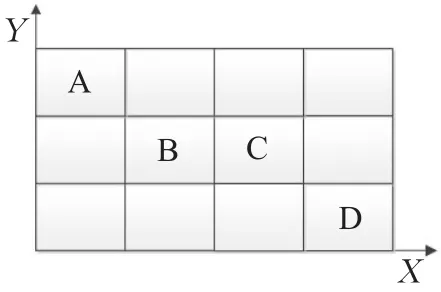
图1 (b) 符号图
这样图像的相似度问题可以转化为字符串的相似度问题。在得到图像的2-D串的表达后,还需要使用一些策略来计算串与串的相似度。本文采用最大似然准则求解两个字符串的最长公共子串,并以此衡量图像间的相似度。
2.2 构建最长公共视觉词串
为提高检索的效果,本文在“词袋”模型中引入表达图像中物体间空间信息的最长公共视觉词串(Longest Common Visual Substring,LCVS)。2-D串是图像中目标物体间的位置关系的一种表达,且需要确定物体的位置及种类。“词袋”模型将图像用训练好的字典进行表达,这样一幅图像就可以表示为字典中视觉词的组合。如图2所示,通过视觉词在X轴与Y轴上的投影将图像表示为视觉词串,视觉词串反映了视觉词之间的拓扑结构,包含很多空间语义信息。在查询阶段,计算待查询图像与数据库中图像的最长公共视觉词串。最长公共视觉词串反映了两幅图像的相似程度,公共视觉词串越长两幅图像越相似。构建视觉词串的流程图如图3所示。
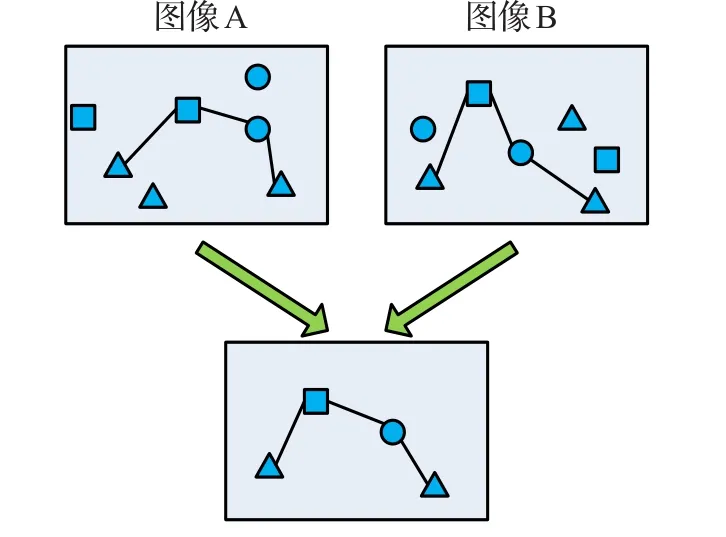
图2 图像A与图像B构成的最长公共视觉词串示意图
具体检索过程如下:
步骤1提取查询图像特征并进行量化投影,得到查询图像中视觉词串。对于查询图像imagequery,提取其SIFT特征F=[f1,f2,…,fl],并将SIFT特征量化得到视觉词集合W={w1,w2,…,wm},其中m为字典中视觉词的数量。之后,将视觉词分别向X轴和Y轴投影,得到查询图像的视觉词串xquery和yquery。
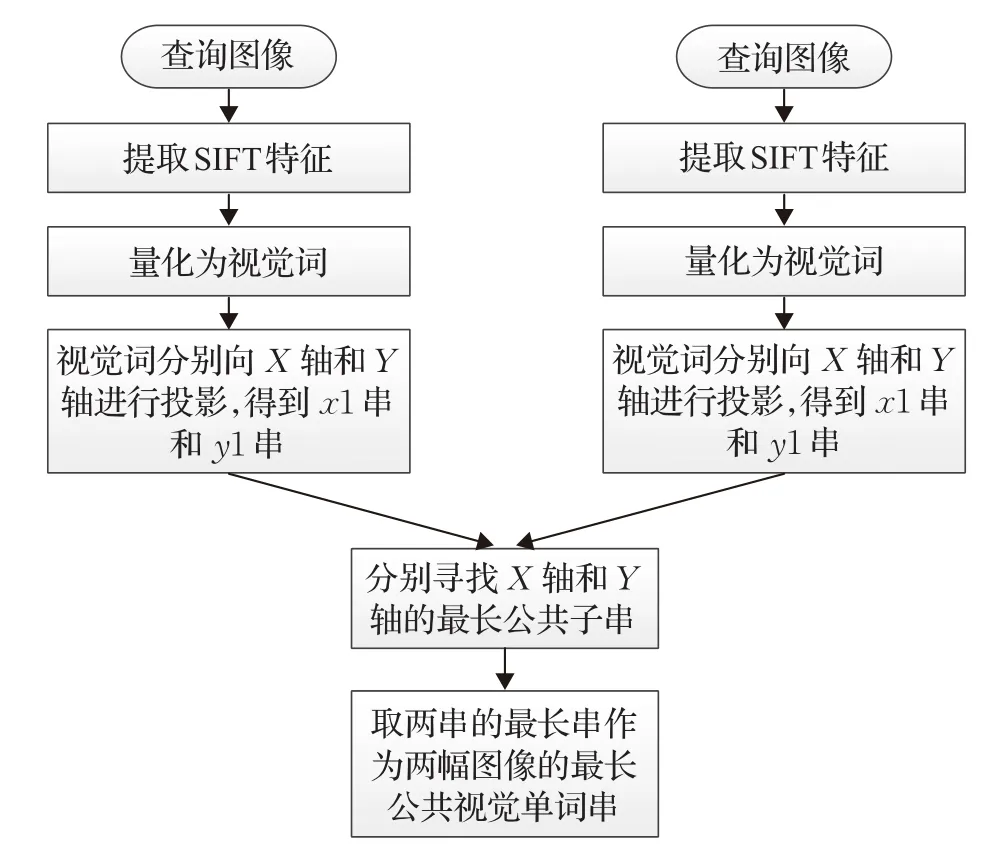
图3 构建视觉词串流程图
步骤2提取数据库中图像特征并进行量化投影,得到数据库中图像的视觉词串。给定数据库中图像imagei,提取其SIFT特征并进行特征量化得到视觉词串与。
步骤3计算查询图像与数据库中图像的最长公共视觉词串。
按如下规则计算最长公共视觉词串

其中Lcs(String1,String2)表示两个串的最长公共子串,LCVS_X(i)和LCVS_Y(i)分别是查询图像imagequery与数据库中图像imagei在X轴和Y轴上的最长公共视觉词串。Max_LCVS(i)是LCVS_X(i)和LCVS_Y(i)中较大的串作为图像imagequery与imagei的最长公共视觉词串。
步骤4根据最长公共视觉词串计算查询图像与数据库中图像的相似度得分。
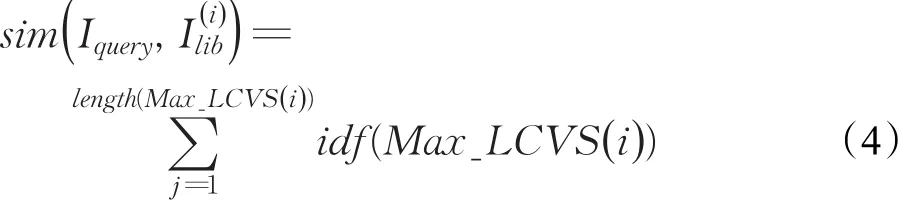
其中,idf(·)表示“词袋”模型中每个视觉词的权重,即逆向文件频率。根据相似度得分的高低对数据库中图像进行排序,得到图像检索结果。
2.3 最长公共视觉词串鲁棒性强化
最长公共视觉词串包含了两幅图像的公共隐含模式,但构造的视觉词串仍不具有旋转不变性。
如图4所示,图像I1和I2相似度较高,且两者相差90°旋转。假设两幅图像包含的视觉词构成符号图Is1和Is2,那么根据2.2节中的方法可以得到两幅图像的最长公共视觉词串为A其长度为1,从最长公共视觉词串看这两幅图像相似度并不高,检索失配。为了解决这种情况的失配问题,增加方法的旋转不变性,查询图像分别经过0°、90°、180°、270°旋转,再与数据库中图像匹配最长公共视觉词串,取最长公共视觉词串中最大的作为结果。这样的过程提高了最长公共视觉词串的鲁棒性,对噪声与仿射变换有一定程度的不变性。
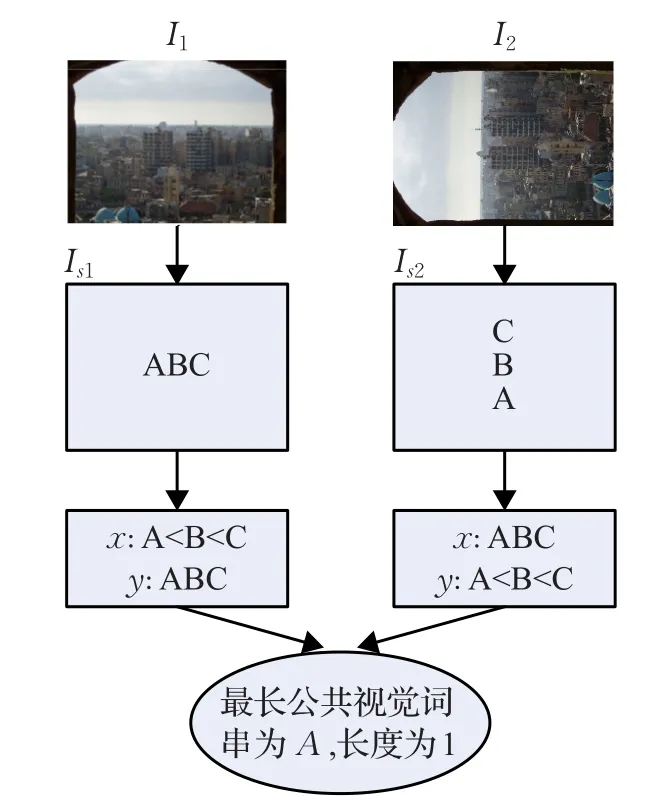
图4 失配情况示例
图5 展示了匹配对于噪声影响不敏感。如果有噪声出现在两幅相似的图像的其中一幅中,单词串的构造仍然不会受到干扰。这种朴素的构造方式是简单的,易于理解的,在后面的测试中也展现了良好的效果。

图5 抵抗噪声示意图
具体检索过程如下:
步骤1提取查询图像特征并进行量化投影,得到查询图像中视觉词串。对于查询图像imagequery,提取其SIFT特征F=[f1,f2,…,fl],并将SIFT特征量化得到视觉词集合W={w1,w2,…,wm},其中m为字典中视觉词的数量。之后,将视觉词分别向X轴和Y轴投影,得到查询图像的视觉词串xquery0和yquery0。旋转查询图像重复上述操作得到旋转不同角度查询图像的视觉词串
步骤2提取数据库中图像特征并进行量化投影,得到数据库中图像的视觉词串。给定数据库中图像imagei,提取其SIFT特征并进行特征量化得到视觉词串与。
步骤3计算查询图像与数据库中图像的最长公共视觉词串。
按如下规则计算最长公共视觉词串
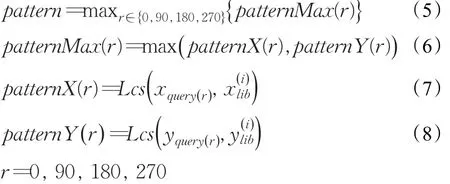
其中Lcs(String1,String2)表示两个串的最长公共子串,patternX(r)和 patternY(r)分别是旋转r°后的查询图像imagequery(r)与数据库中图像imagei在X轴和Y轴上的最长公共视觉词串。 patternMax(r)是 patternX(r)和patternY(r)中较大的串,作为旋转r°图像imagequery(r)与imagei的最长公共视觉词串。 pattern取不同角度旋转下最大的串,作为最终查询图像的最长公共视觉词串。
步骤4根据最长公共视觉词串计算查询图像与数据库中图像的相似度得分。

其中,idf(·)表示“词袋”模型中每个视觉词的权重,即逆向文件频率。根据相似度得分的高低对数据库中图像进行排序,得到图像检索结果。
3 实验结果
3.1 实验数据集
实验在Holiday数据集上运行,该数据集是法国INRIA机构在2008年发布的。该数据集共有500类图像,每类图像有2~6幅不等,共计1 491幅。数据集中图像的尺寸不一,大部分图像的分辨率为2 048×1 536,在实验中统一调整为1 024×768。Holiday数据集中的图像都是对同一目标或场景进行的不同角度的拍摄。INRIA提供了数据集每幅图像的SIFT特征和训练好的字典[13]。字典的维度从100维到200 000维。下面在与“词袋”模型对比的实验中均采用200 000维的字典[14]。按照数据集的说明,每一类的第一幅图像作为查询图像,在查询图库的过程中要排除自身,在剩余图像中计算排名,使用Average Precision(AP)作为衡量系统的指标。在500类图像进行500次查询,然后求其平均值mAP(mean Average Precision),以此作为衡量系统的评价指标。
3.2 参数选择
在实验中,并不使用每幅图像的全部SIFT特征,而是选取显著度最大的t个作为该图像的特征。显著度是由特征点的Hessian矩阵的行列式值和该矩阵的迹共同求得。下面“词袋”模型缩写为BoF,本文提出方法缩写为LCVS。BoF、Eo-BoW与LCVS在参数t的选择上的最优有一定区别,因此,实验参数t由500到4 000间隔500进行调整计算在Holiday数据集上的mAP值。
实验结果如表1与图6所示。LCVS方法在不同的参数t下的mAP均高于BoF与Eo-BoW。BoF与Eo-BoW模型在t=2 500时最高,前者mAP为0.572 0,后者仅为0.490 0。相比LCVS方法在t=3 000处取得最高的mAP=0.603 6,高于前两种模型的结果。其中,BoF模型与LCVS模型的SIFT特征数量从2 000后,mAP值的增长放缓,这说明当描述图像所需的特征达到一定数量之后,过多的特征引入对系统起到的作用有限,反而影响特征的鲁棒性,出现震荡或者下降。
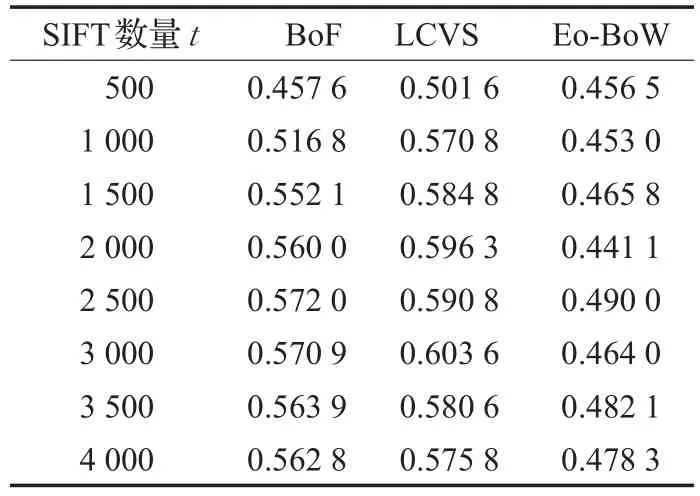
表1 SIFT数量对的mAP值的影响

图6 在Holiday图库上不同SIFT特征数目的mAP曲线比较
3.3 方法比较与分析
如上节所述,LCVS在各不同参数下的准确率均高于BoF和Eo-Bow方法,为了进一步分析LCVS方法在哪类图像中更有优势,选取BoF与LCVS的mAP结果最高的参数t,在Holiday数据集上进行了查询实验。
选出了LCVS提高了检索结果的6类典型检索图像及结果进行了展示。如图7所示,第一列图像为查询图像,第二列为同类的待查图像,第三列为待查图像用BoF、Eo-Bow和LCVS三种方法检索的排名。这6类图像中每类有1~3张同类图像。其中,LCVS方法对于待检图像均成功检出,BoF方法只有413类的桥正确检出。

图7 部分查询结果对比
通过对于更多图像的观察与分析,相比于传统的BoF方法,LCVS对于明暗变化不敏感;对于旋转、缩放、平移LCVS方法检索结果较好;对于细节丰富的场景有不错的检索结果。对于细节丰富的场景,LCVS可以充分利用关键特征点间的空间位置关系,从而提高了图像检索的效果。从实验对比中发现,LCVS方法在许多BoF和Eo-BoW检索效果一般的图像上有了较大的提高,成功检索出待检图像。LCVS检索结果变差的典型结果如图8所示,其中,第11类和174类两种方法均未能正确检索出同类图像而LCVS将正确的图像排在了较后的位置。总结发现主要包括两类图像,图像中缺少有效的细节信息,如大片的沙滩海洋、蓝天白云、森林;图像中细节丰富,且待查图像有很多新的细节加入,如车等物体遮挡了待检索的建筑。这样的结果也较大地受到了SIFT提取到的关键点的影响,当提取的关键点很少,或缺少待检索物体的关键信息时,LCVS方法将达不到理想的效果。

图8 部分查询结果对比
4 结论
(1)提出了一种基于最长公共视觉词串的图像检索方法,应用于自然图像的检索中。自然图像的特征间的距离可以利用最长公共视觉词串进行表达,这样的表达引入了图像中目标间的空间位置关系,提高了图像检索的结果。
(2)设计方法提高了检索的鲁棒性,对噪声与仿射变换有一定程度的不变性,并采用最大似然准则衡量词串间的相似度。
(3)与传统BoF方法和近年提出的改进方法Eo-BoW方法进行了对比实验,验证了基于最长公共视觉词串的方法对于图像检索的有效性。实验结果表明基于最长公共视觉词串的距离表达方式较直接计算特征距离的表达方式更能表达图像中目标间的位置关系,具有更好的检索效果。
猜你喜欢
数学物理学报(2021年1期)2021-03-29
新疆大学学报(自然科学版)(中英文)(2020年2期)2020-07-25
新世纪智能(教师)(2019年2期)2019-09-11
学生天地·小学低年级版(2019年5期)2019-06-05
学生天地(2019年15期)2019-05-05
新闻传播(2018年15期)2018-09-18
专利代理(2016年1期)2016-05-17
当代外语研究(2010年9期)2010-12-07
中文信息学报(2010年1期)2010-06-05
质量与标准化(2010年5期)2010-05-03
