
基于多层感知器神经网络的学生校内消费评估研究
2018-08-01 07:13:08马晓娜
中国教育信息化 2018年14期
武 斌 ,马晓娜
(1.安徽理工大学 现代教育技术中心,安徽 淮南 232001;2.安徽理工大学 测绘学院,安徽 淮南 232001)
一、引言
随着我国教育事业的不断发展,越来越多的公民实现了高等教育,招生人数的增加给学校管理与决策带来了挑战。如何快速、科学、可靠地了解学生的相关情况显得尤为重要。学生的校内消费数据中隐含了大量信息,通过对它的分析评估,可以获取学生多个方面的信息,为后续的诸如贫困生认定、学校资源配置优化等提供参考。数据分析评估可以有多个方向,本文以贫困生认定为例。
贫困生的认定指标体系中有家庭、个人、学校、社会等几个方面,其中学生校内消费是家庭与个人方面的重要体现。因此,我们可以通过分析评估学生的校内消费数据挖掘出隐藏的信息,为认定工作提供数据支持。有部分高校尝试大数据统计分析方法,如决策树算法[2]、关联规则算法[3]、层次分析算法[4]、数据挖掘算法[5]、聚类分析算法[6]等。这些算法虽然可以获取信息,但是他们的底层核心算法还是基于传统的单个评估指标的排列组合与逻辑判断。而这些单个评估指标如何确定、准确与否同样是需要解决的问题。为此笔者提出了采用机器学习中的多层感知器神经网络算法,通过学习已给定学生的校内消费数据,建立多层感知器神经网络模型,最后用建立完成的模型去评估并输出结果。
二、神经网络
神经网络是一种模拟人脑的神经网络系统,以期能够实现类人工智能的机器学习技术。
1.神经元基本结构
神经元模型是一个包含输入、输出与计算功能的模型。输入可以类比为神经元的树突,而输出可以类比为神经元的轴突,计算则可以类比为细胞核。一个典型的神经元模型如图1所示。

图1 神经元基本结构
图 1中,SUM为求和,SGN为非线性函数g,I为输入,w为权重,则神经元的输出为:

当大量的神经元叠加、具有多个层次的时候,就构成了神经元网络。
2.多层感知器
将前一个神经元的输出作为后一个神经元的输入,得到的输出再作为后一个神经元的输入,不断叠加,就构成了多层感知器(Multilayer Perceptron),如图2所示。
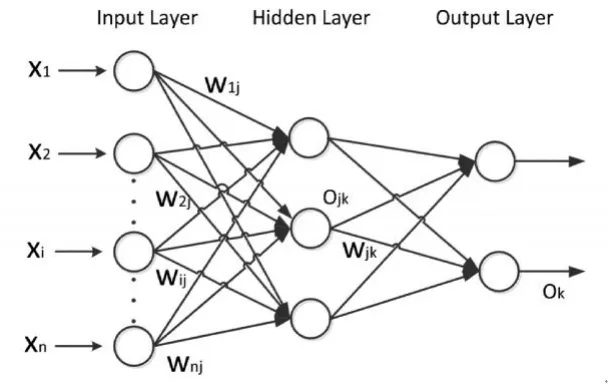
图2 多层感知器(Multi-layer Perceptron)示意图
多层感知器是一种前向的神经网络,它的输入是一组向量,输出为另一组向量。多层感知器由输入层(Input Layer)、 隐藏层 (Hidden Layer) 和输出层(Output Layer)构成。其中,隐藏层又可以包含多层。每层由多个节点构成,每层又可以传递给下一层,直到输出层。除去输入节点,每个节点都是一个带有非线性激活函数的神经元(或称处理单元)。它的输出为:

公式2中,wnj为节点权重,bjk为偏差。
3.求解器
由神经网络的输出表达式公式2可以看出,求解权重和偏差是建立神经网络模型的关键。求解器即是神经网络模型在学习时通过算法求解出权重与偏差的值。这里使用Adam算法求解。
Adam算法来源于自适应矩估计 (Adaptive Moment Estimation),是梯度下降算法的优化,根据损失函数对每个参数的梯度的一阶矩估计和二阶矩估计动态调整针对于每个参数的学习速率,使参数比较平稳。算法如下:
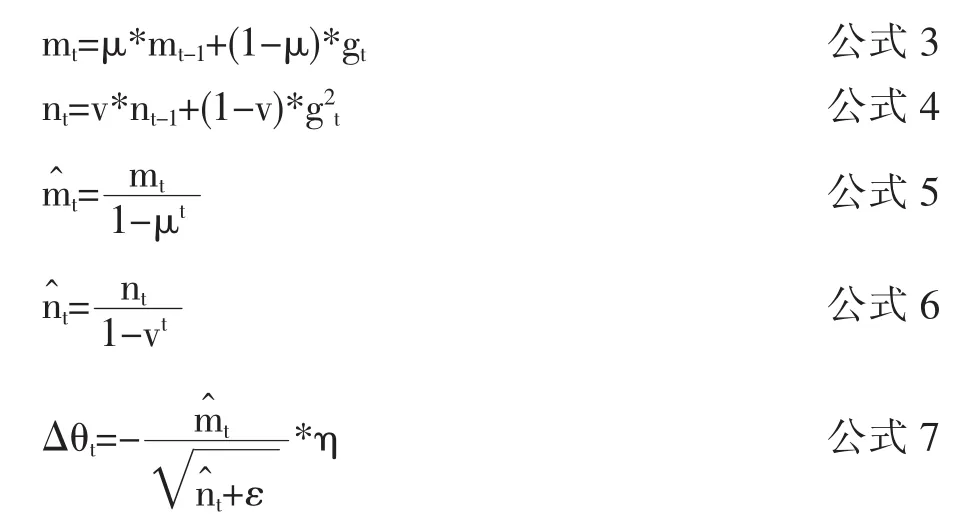
算法中 η 是学习率,gt是梯度函数,mt、nt分别是对梯度的一阶矩估计和二阶矩估计,可以看作对期望E|gt|、,的估计;是对、mt、nt的校正,这样可以近似认为是期望的无偏估计。同时,学习率η也有了限制。
三、Python编程实现
1.Python简介
Python是一种面向对象的解释型计算机程序设计语言,其语法简洁清晰,具有丰富和强大的库。由于其简洁性、易读性以及可扩展性,现今用Python做科学计算的研究机构日益增多,并且众多开源的科学计算软件包都提供了Python的调用接口,例如NumPy、SciPy和matplotlib都分别为Python提供了快速数组处理、数值运算以及绘图功能。这里使用Python编程实现多层感知器神经网络模型,并用于评估。
2.消费数据预处理
学生的校内消费数据主要来自于校园一卡通系统。这里采用校内食堂、超市消费数据。食堂消费每天有早中晚三餐,每餐有消费次数与金额,学生每学年度在校时间九个月,这样每位学生每学年的消费数据就有3×2×30×9=1620条目,作为输入向量数据量过大。为此,采用以月份为单位,统计出每月早中晚消费次数与金额,这样每位学生的年度数据只有72条目,便于输入多层感知器神经网络模型。
在统计学生消费数据时,会存在没有早饭等数据缺失的情况,查询数据库会返回空值。我们需要将空值替换为0,才能输入多层感知器神经网络使用。
为了使多层感知器神经网络模型更好地适应计算,输入的数据必须进行归一化处理。归一化处理在sklearn库中有标准的方法,即sklearn.preprocessing.scale()方法。但该方法需要计算数据总量的均值,当数据量较大,分批次输入数据时,会存在标准不统一的问题,同时数据不服从高斯正态分布也会出现数据失真问题,为此,通过观察输入数据,发现只需同时除以某固定值即可解决这个问题。这里取消费次数除100,消费金额除400。
3.导出校内消费数据
由于需要统计的学生校内消费数据较多,且直接查询一卡通数据库不仅耗时较大,而且占用资源。这里采用统计一次、数据存储、多次使用的方式,将初步统计的数据存储在另一套数据库中,供多层感知器神经网络模型使用。
新建一台虚拟主机,操作系统使用CentOS 7.1 x64版本,数据库使用MySQL 5.7.18版本,建立用户信息表(T_CUSTOMER)、月度消费信息表(T_BLSMONTH)、年度消费总和表(T_SUM),分别存储学生基本信息、学生月度消费数据、年度消费总和等数据。
我校一卡通数据库使用Oracle数据库,可以使用Python中的cx_Oracle库连接,从而实现Python与Oracle数据库的通信,以执行SQL语句。新建的存储数据库使用pymysql库来连接。这样,将一卡通数据库中的数据统计出来,并做预处理,最后存储在MySQL数据库中待使用。
4.导出学习数据
有了学生的校内消费数据,接下来就是分析使用。首先,需要导出多层感知器神经网络模型学习的数据。这里采用先统计出年度消费总和,再降序排列,并结合学生管理部门人工核实,选取出适当数量的具有代表性的学生,导出消费数据。
为了提高模型的准确度,还需要模型学习一些非代表性学生的消费数据。采用MySQL数据库的avg()函数计算出所有学生消费的平均值,在此基础上适当添加偏移量bias,具体值可以根据每个学院的情况具体问题具体分析确定。
5.多层感知器神经网络模型的创建、学习与持久化
根据多层感知器神经网络的原理,使用代码编程构建一个多层感知器神经网络模型。使用Python第三方sklearn机器学习库中的neural_network模块导入MLPClassifier类,通过实例化的方式构建多层感知器神经网络。MLPClassifier类中的主要方法如表1所示。
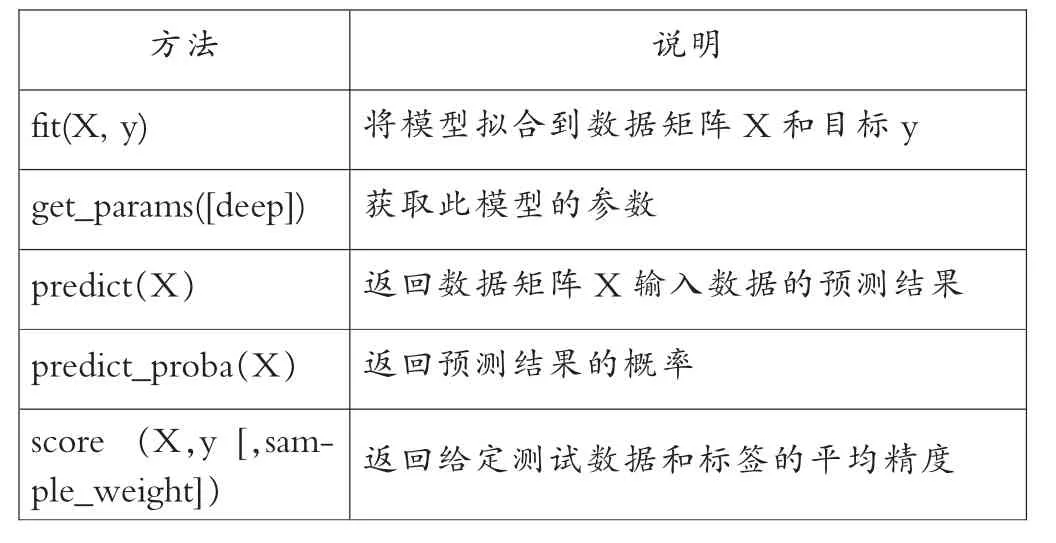
表1 MLPClassifier类中主要方法
通过调用MLPClassifier类中的方法,可以方便快速地构建和使用多层感知器神经网络。Python构建多层感知器神经网络核心功能代码如下:

输入的原始数据inputx列表中包含了所有需要学习的学生数据,其中每位学生是一个经过预处理并归一化后的72维向量;inputy则是学习时每位学生对应的已知结果,这里取贫困生值为1,非贫困生值为0。选取2016年9月份至2017年6月份之间除去寒假2017年2月份共9个月份的校内消费数据。其中某学生的月度消费数据如图3所示。
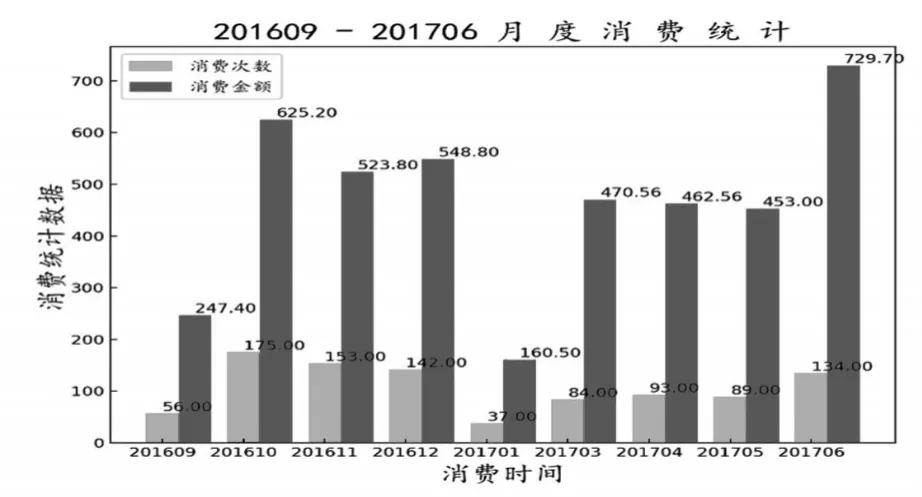
图3 某位学生月度消费数据
由于程序不可能一直处在运行状态,还需要将学习完成后的模型保存在磁盘上,供下次使用,这个过程即是模型的持久化。这里使用sklearn.externals库中的joblib类的dump()方法实现。
6.多层感知器神经网络模型学习的参数调优
多层感知器神经网络MLPClassifier模型具有很多参数可以设置,主要参数如表2所示。
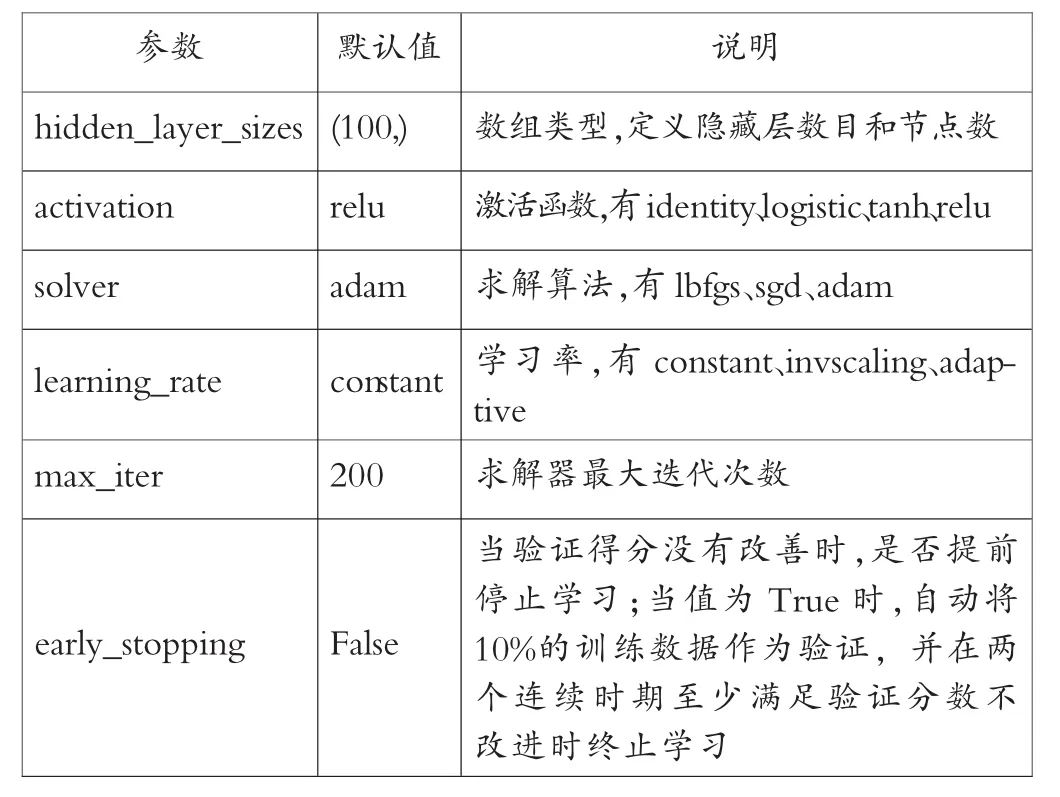
表2 MLPClassifier模型主要参数
针对表2中的MLPClassifier神经网络模型参数,这里主要优化隐藏层、激活函数和最大迭代次数参数,即hidden_layer_sizes、activation、max_iter参数。
隐藏层参数hidden_layer_sizes的值是一维数组,数组长度代表隐藏层个数,每个值表示当前层的神经元节点数。取不同的隐藏层参数,其余均为默认值,使用另外一组测试数据实验。
实验结果表明,当隐藏层层数固定,每层神经元数量呈梯度递减趋势时,对不同学生的区分度逐渐明显;当每层神经元数目固定,隐藏层层数不断增加时,对不同学生的区分度逐渐明显,但是超过一定层数后,会出现过拟合,反而使区分度下降。这里结合本研究实例,取隐藏层参数hidden_layer_sizes=(36,24,12),此时,不同家庭条件学生有明显的分层,且更加逼近该层次相对应的评估值,能够较好地区分出不同学生。
激活函数参数activation的值为一个非线性函数名,代表神经网络模型使用的激活函数。这里通过实验对比了 identity、logistic、tanh、relu 四种激活函数的学习结果。由实验结果可见,只有logistic激活函数学习效果较差,其它三个非线性激活函数均可以达到较好的学习效果,这里采用默认值relu。
求解器最大迭代次数max_iter参数设置了求解器运算的最大计算次数。它的值过小会造成神经网络无法收敛,过大则会出现过拟合问题且求解时间过长。不同值的学习结果如图4。
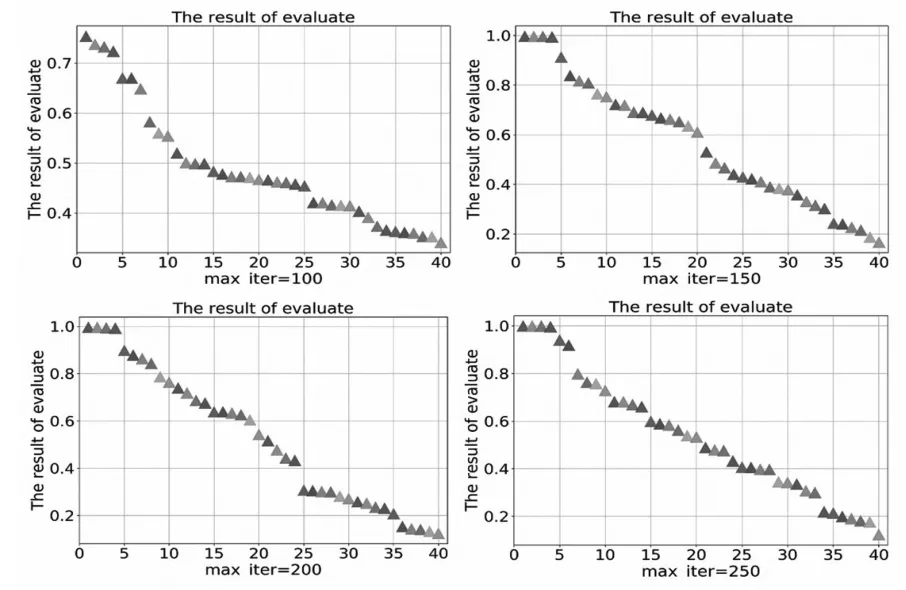
图4 不同求解器最大迭代次数参数学习结果
已知前18名为贫困生,中间15名为一般家庭条件学生,后7名为非贫困生。由图4可见,随着迭代次数的增加,多层感知器神经网络逐渐收敛,不同学生区分度明显,但是当迭代次数过大时,出现过拟合,无法区分不同学生。此处,多层感知器神经网络在迭代200次左右即收敛,这里取max_iter参数为200。
7.导出待评估学生的数据
待评估的学生数据与用于学习的学生数据在数据预处理时进行相同的操作,这样,只需要根据学院提供的学生名单,重复上述步骤即可导出消费数据。
8.实现评估
首先,通过sklearn.externals库中joblib类的load()方法导入学习完毕的多层感知器神经网络模型。然后,将待评估的学生消费数据矩阵变换为多层感知器神经网络输入格式并输入模型,再通过模型的计算,得到评估结果。该结果为一个0-1之间的置信值。随机取校内5个院系评估,并将评估结果反馈至相关院系,比对后得到结果如表3。
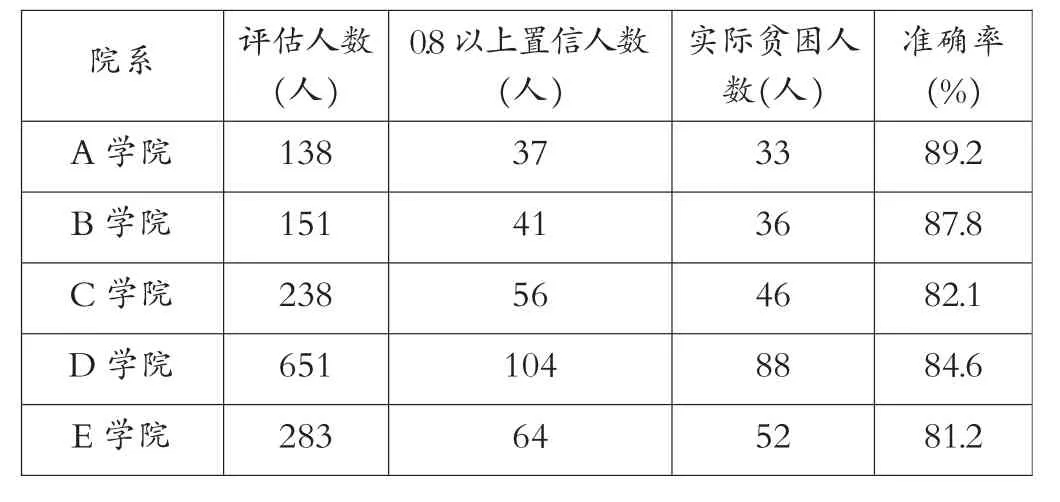
表3 多层感知器神经网络模型评估结果
四、结束语
通过上述实验方法,处理了学生的校内消费数据,建立多层感知器神经网络模型并学习已认定贫困生的消费数据,最后使用学习完毕的模型用于评估,得到了评估结果。在此过程中,全程使用计算机编程自动处理,平均处理每位学生时间约为10秒,相比人工分析几周时间,极大地缩短了时间、减轻了人力投入;同时避免了选取特定评估指标标准以及人为主观因素对结果的影响,为学校决策者和职能部门提供了有力的数据支持。
将神经网络模型评估的结果反馈至相关学院,对比可见,模型筛选出0.8以上置信值的学生占真实人数的比例在80%以上,具有较强的可信度与准确度。将此结果再结合成绩、勤工助学、奖学金等维度信息则可以更加准确与全面地了解学生。
我们还可以将此方法泛化在其他方面。比如将具有某一特性的学生信息输入模型进行训练,则可用此模型评估目标在该特性方面的结果,具有较大的使用价值。
猜你喜欢
自然杂志(2021年6期)2021-12-23 08:24:46
传感器与微系统(2021年7期)2021-07-15 12:08:44
中国矿业(2019年7期)2019-07-26 05:37:30
环球时报(2019-04-26)2019-04-26 06:17:15
发明与创新·中学生(2019年2期)2019-02-26 12:39:22
现代装饰(2018年5期)2018-05-26 09:09:01
电源技术(2015年5期)2015-08-22 11:18:38
弹箭与制导学报(2015年1期)2015-03-11 15:32:06
中国火炬(2014年9期)2014-07-25 10:23:07
中国火炬(2012年5期)2012-07-25 10:44:08
