
基于ELK的日志分析系统研究及应用
2018-07-19 12:54马玉鹏徐春香
计算机工程与设计 2018年7期
姚 攀,马玉鹏,徐春香
(1.中国科学院 新疆理化技术研究所,新疆 乌鲁木齐 830011;2.新疆民族语音语言信息处理实验室,新疆 乌鲁木齐 830011;3.中国科学院大学,北京 100049)
0 引 言
日志是系统运维、故障诊断、性能分析的重要来源,对于任何系统而言都是极其重要的组成部分。随着大数据时代的来临,系统日志量也呈指数级增加。伴随着日志格式复杂度的增加、日志规模的扩大以及应用节点的增多,传统的日志分析手段耗时耗力、效率低下、无法胜任复杂事件处理[1,2]等缺点逐渐暴露出来。传统的日志分析方法已经不能满足实时化的需求,实时化已经成为当今大数据技术的发展趋势之一[3]。
随着硬件成本的降低以及实时分析技术的发展成熟,在日志处理领域出现了以ELK(日志采集工具Logstash、分布式搜索引擎Elasticsearch、数据可视化分析平台Kibana)为代表的实时日志分析平台,使运维人员从浩如烟海的日志信息中轻松准确地监控及维护所需关注的信息及实现日志统计分析成为了可能[4]。本文基于ELK技术栈,实现了能对海量日志进行实时采集和检索的分析监控系统。
1 相关工作
国内外很多大学和研究机构都做了日志领域的相关研究,如加拿大麦吉尔大学信息学院、国防科学技术大学、中国科学院计算机网络中心、浙江大学CAD&CG重点实验室等。
文献[3]研究了大数据环境下分布式数据流处理系统的各个子系统,包括数据收集子系统、消息队列管理子系统、流式数据处理子系统和数据存储子系统,对4类子系统涉及的关键技术做了详细介绍并从应用角度做了比较。
文献[5]系统地综述了日志研究的进展,从日志特征分析、日志故障诊断、日志分析3个大的方面对日志的研究领域、研究方法、研究方向和未来的挑战做了总结,具有很强的指导意义。
文献[6]介绍了LARGE系统中采用类MapReduce机制对大规模系统日志的日志模式提炼算法的优化方法,指出了近年来对Elastic公司开发的ELK组合的研究和使用呈现显著增长的趋势,ELK作为实时数据分析框架对日志流处理有一定优势,对特定系统或环境的分析需求仍需其它辅助分析程序[6]。
文献[7]使用Flume收集日志,使用插件为Hbase提供日志事件,使用Elasticsearch做日志搜索,提出了实时大数据日志搜索集成方案,有一定借鉴意义,但是日志的传输和存储过于复杂。
ELK技术在大数据系统[1]、电子商务平台[4]、天文系统[8]、电力系统[9]都有相关应用,在系统监控和数据分析方面有着良好的效果。本文在此基础之上,在日志收集方面使用Beats取代Logstash,进一步探索与总结Elasticsearch集群的优化方法。
2 基于ELK的日志分析平台
2.1 日志分析系统整体架构
一个完整的日志分析系统主要包括日志采集系统、日志解析系统、日志存储系统和可视化分析系统4部分。典型的ELK架构中,Logstash作为日志收集器分布于多台机器,把非结构化日志按照规则解析然后输出至Elasticsearch;Elasticsearch可以当作一个具有全文检索功能的NoSQL数据库来使用,在日志处理这个业务场景中Elasticsearch作为存储日志的中央系统;Kibana是数据分析与可视化分析组件,可以对Elasticsearch中的日志进行高效的搜索、统计分析与可视化操作。由于Logstash既作为日志搜集器又作为解析器,会消耗较多的CPU和内存资源,如果服务器计算资源不够丰富,容易造成服务器性能下降甚至无法工作。为了解决了Logstash占用系统资源较高的问题,Elastic公司推出了轻量级的日志采集器Beats,在数据收集方面取代Logstash,引入Beats后的系统架构如图1所示。
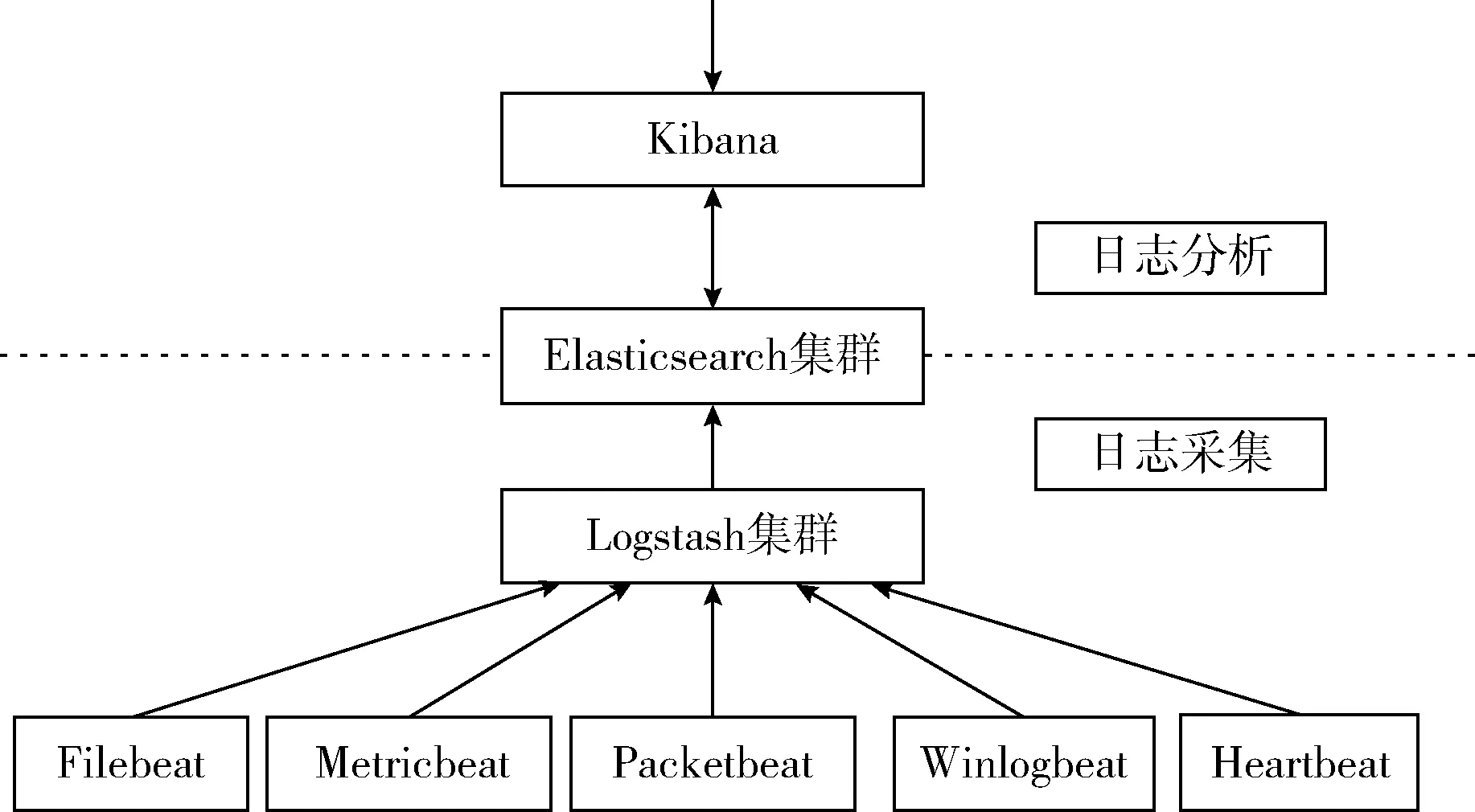
图1 ELK+Beats架构
Beats是一系列采集器的总称,对于不同的日志源和日志格式可以使用不同的Beats,目前Beats家族包括以下5个成员:
(1)Filebeat:轻量级的日志采集器,可用于收集文件数据。
(2)Metricbeat:5.0版本之前名为Topbeat,搜集系统、进程和文件系统级别的CPU和内存使用情况等数据。
(3)Packetbeat:收集网络流数据,可以实时监控系统应用和服务,可以将延迟时间、错误、响应时间、SLA性能等信息发送到Logstash或Elasticsearch。
(4)Winlogbeat:搜集Windows事件日志数据。
(5)Heartbeat:监控服务器运行状态。
相比Logstash,Beats所占系统的CPU和内存几乎可以忽略不计。另外,Beats和Logstash之间支持SSL/TLS加密传输,客户端和服务器双向认证,保证了通信安全。
2.2 日志实时收集系统
日志收集是日志分析处理的前提与基础,很多应用系统的日志都分布在不同的服务器上,把分散的日志汇总之后才能做后续的处理分析。现阶段的日志都是文件格式,使用Filebeat和Logstash构建日志收集系统。
Filebeat是GO语言开发的轻量级日志采集器,在应用服务器上以代理的形式安装。当Filebeat启动时,它会启动一个或者多个prospector监控日志路径或日志文件,每个日志文件会有一个对应的harvester,harvester按行读取日志内容并转发至后台程序。Filebeat维护了一个记录文件读取信息的注册文件,记录每个harvester最后读取位置的偏移量。
Logstash是分布式数据收集引擎,在日志处理中担任搬运工的角色,它支持动态的从各种数据源搜集数据,并对数据进行过滤、分析、统一格式等操作,然后输出到用户指定的位置。事件流通过Logstash中的Input、Filter和Output插件处理和转换,Input用于配置日志的输入源,Filter用来解析日志,Output指定日志的输出去向[10]。
Grok是Logstash的一个正则解析插件,它能对日志流进行解析,内置了120多种的正则表达式库,对日志解析时需要针对日志格式定义相应的正则表达式。结合Grok提供的便利,总结出按行读取文件格式日志的解析步骤:
(1)首先对日志进行分析,明确每一个字段的含义,确定日志的切分规则,也就是一条日志切分成哪几个字段,这些字段是以后做日志分析的关键,对原始日志的解读和分析是非常关键的一步。
(2)根据步骤(1)的切分原则确定提取每一个字段的正则表达式,如果Grok中的正则库满足需求直接使用即可,否则采用自定义模式,两者可以组合使用。
(3)在Grok Debugger调试工具中调试、验证解析日志的正则表达式是否正确。
以下是应用系统中的一条半结构化日志:
2017-03-16 00:00:01, 570 133382978[HandleConsu-mer.java:445:INFO]车辆号牌为空
对应的Grok表达式如下:
%{TIMESTAMP_IS08601:time}s*%{NUMBER:bytes}[s*%{JAVAFILE:class}:%{NUMBER:lineNumber}s*:%{LOGLEVEL:level}s*]s*(?
格式化后的日志如下:
{
"time":"2017-03-16 00:00:01,570",
"bytes":"133382978",
"class":"HandleConsumer.java",
"lineNumber":"445",
"level":"INFO",
"info":"车辆号牌为空。"
}
2.3 日志存储与搜索系统
Elasticsearch是一个建立在Lucene基础之上的分布式搜索引擎,基于RESTful web接口,可用于全文搜索、结构化搜索以及聚合分析,有着分布式、零配置、高可用、集群自动发现、索引自动分片、模式自由、近实时搜索等优点。表1对比了Elasticsearch和关系型数据库中的一些重要术语。
Elasticsearch集群中的节点一般有3种角色,在搭建完全分布式集群以前需要在配置文件中指定节点的角色,简介如下:
Master节点:master节点主要负载元数据的处理,比如索引的新增、删除、分片分配等,每当元数据有更新,master节点负责同步到其它节点之上。
Data节点:data节点上保存了数据分片。它负责数据相关操作,比如分片的增删改查以及搜索和整合操作。
Client节点:client节点起到路由请求的作用,实际上可以看作负载均衡器,适用于高并发访问的业务场景。

表1 Elasticsearch和RDMS概念对比
综合考虑现阶段的日志量和服务器硬件配置,使用3台CentOS服务器搭建了Elasticsearch集群,集群拓扑图如图2所示。

图2 Elasticsearch集群拓扑结构
2.4 日志可视化分析
孟小峰教授明确指出:“可视化技术是数据分析与信息获取的重要手段[11]。”数据可视化是大数据的最后一公里,通过可视化可以将抽象的数据转化为直观的图表,能够有效的将要点信息展示给人们。
Kibana是一个开源日志分析及可视化平台,使用它可以对存储在Elasticsearch索引中的数据进行高效的搜索、可视化、分析等各种操作。Kibana的愿景是让海量数据更容易理解,通过浏览器的用户界面可以创建各种高级图表进行数据分析和展示,它的仪表盘功能可以汇总多个单操作图表,并且可以实时显示查询动态。
3 Elasticsearch集群优化
Elasticsearch作为存储和搜索日志的中央系统,向下对接日志采集系统,向上配合Kibana做可视化分析,优化集群配置可以使其获得更优的性能。
3.1 硬件层面优化配置
(1)合理选择服务器。Elasticsearch的运行对JDK版本、Linux内核、最小内存等都有一定的要求,在安装部署集群之前需要选择和Elasticsearch版本匹配的服务器配置,同时也要根据业务量做集群规划。
(2)提高Linux系统应用程序最大打开文件数。在启动Elasticsearch集群以前,增大机器的最大文件数,可以避免数据导入高峰时期打开文件过多异常的发生。
(3)增大虚拟映射内存。Elasticsearch写入文档时最终要使用Lucene构建倒排索引,增大虚拟映射内存可以加快索引速度。
3.2 数据导入性能优化
(1)关闭_all字段。_all字段是把一个文档的所有字段合并在一起的超级字段,在搜索字段不明确的情况下可以对_all进行搜索,默认是开启的。如果没有模糊搜索的需要,关闭_all字段可以缩小索引大小,提高导入性能。
(2)设置副本为0。如果副本不为0,Master节点需要把文档复制到副本分片上,复制过程需要消耗系统资源,因此可以在数据导入阶段设置副本为0,等数据导入完成以后再提高副本数。
(3)对不必要的字段不索引。Elasticsearch可以通过参数设置字段是否建索引,建索引需要分词、解析、建倒排记录表等一系列过程,可以根据业务需求对不必要的字段(比如需要精确匹配的地名)不索引。
(4)使用批量导入。文档一条一条的导入会导致频繁的磁盘读写,使用批量导入可以降低I/O消耗。
(5)适当增大刷新间隔。索引数据过程中为了使数据尽快可搜索,Elasticsearch会不断刷新创建新的段并打开它,默认1s刷新1次,在数据导入期间可适当增大刷新间隔,待数据导入完成以后再恢复至默认设置。
3.3 查询优化
(1)使用路由。路由机制即是通过哈希算法,将具有相同哈希值的文档放置到同一个主分片中,合理使用路由机制可以提高查询性能。
(2)正确使用Query和Filter。Query和Filter都有查询的功能,但是Query使用的是搜索机制,需要通过评分模型计算相关度,而Filter是过滤机制,只需要根据条件进行过滤,无需计算相关度,因此Filter响应时间更快。
(3)使用Optimize API合并段。Elasticsearch中每个分片有多个段,每个段都是一个完整的倒排索引,在查询时Elasticsearch会把所有段的查询结果汇总作为最终的查询结果。当索引的文档不断增多时段也会增多,查询性能就会下降。Optimize API可以强制分片进行段合并,把多个小的段合并成大的段(通常合并成一个段),通过减少段的数量达到提高搜索性能的目的。在日志处理场景中,日志的存储一般按天、周、月存入索引,而且日志一旦索引就不会再修改,索引只是可读的,这种情况下把索引段设为1是非常有效的。
4 性能评估与可视化分析
4.1 实验数据
本实验使用服务器上2500万条日志数据来完成,实验中把2500万条日志分成500万条、1000万条、1500万条、2000万条、2500万条5组。
4.2 实验环境
按照2.3小节中设计的Elasticsearch集群拓扑结构,使用3台CentOS服务器安装部署了3节点集群。服务器的配置如下:操作系统为CentOS 6.5,六核2.10 GHz CPU,磁盘为非SSD普通磁盘,Elasticsearch运行内存为16 G。实验使用的软件版本信息如下:Elasticsearch版本为2.3.3,Logstash版本为2.4.0,Kibana版本为4.4.0,Filebeat版本为1.3.1,压力测试工具为Apache JMeter 3.2。
4.3 实验结果
为了测试集群的日志搜索响应时间和集群优化效果,设计了2组实验:
TEST1:测试不同量级不同查询条件下日志搜索的响应时间。
TEST2:测试段合并前后索引内存的优化效果。
TEST1中设置以下3个查询条件进行日志搜索和聚合分析测试:
Q1:match查询统计文件的上传数量
Q2:filter聚合统计日志级别为ERROR的日志数量
Q3:terms分桶统计各服务器的日志导入量
在Apache Jmeter中使用10组200个线程,模拟200个用户同时并发访问,循环测试10次之后取平均值,查询响应时间的统计结果见表2,折线图如图3所示。

表2 查询响应时间/ms
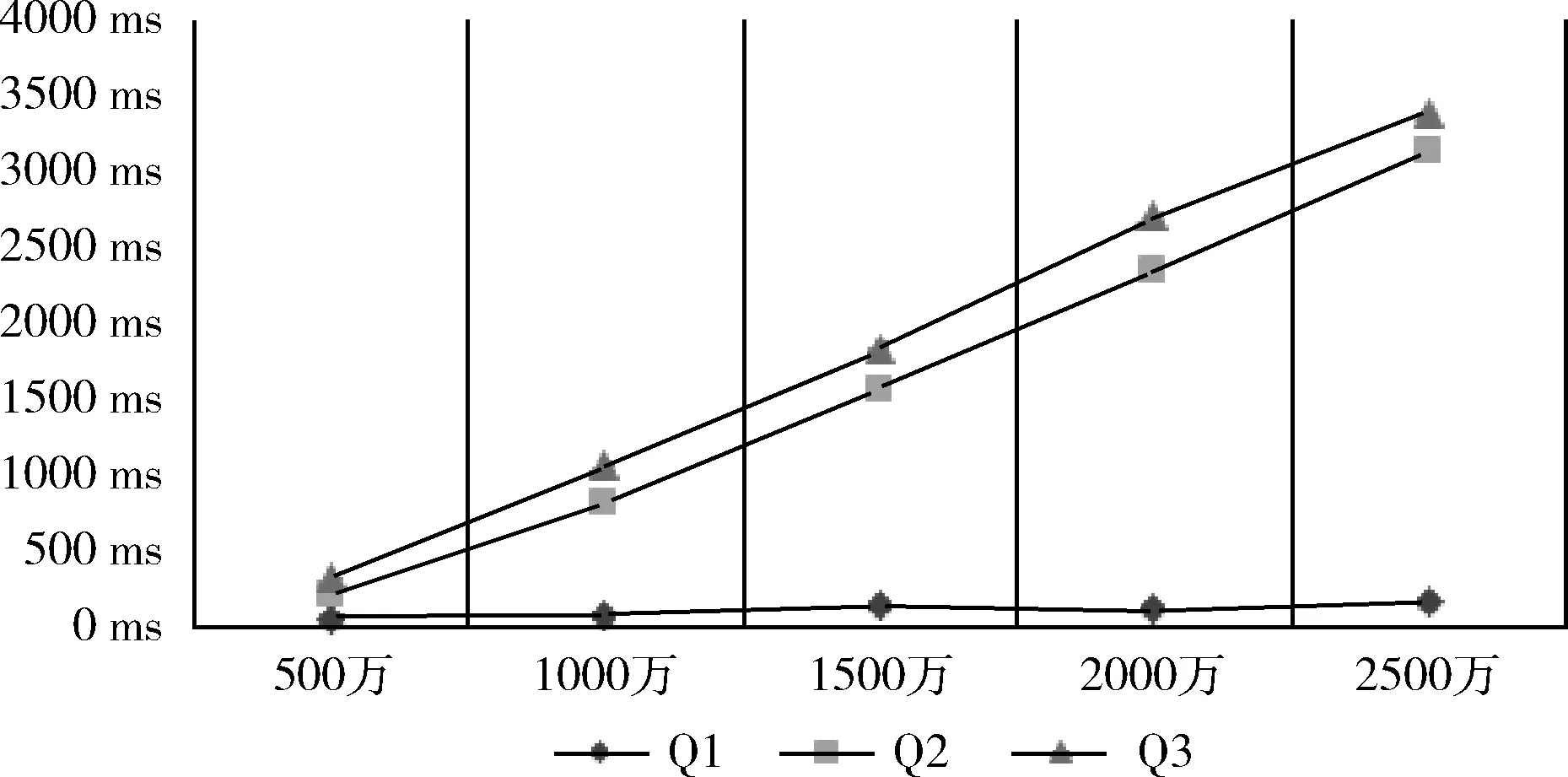
图3 不同条件下查询响应时间
从表2中可以看出,Q1的响应时间均在0.15 s以内,响应时间并没有随着日志数量的加倍而倍增,Q2和Q3的响应时间明显高于Q1。从图3中可以看出,Q1的响应时间增长率接近水平,Q2和Q3的响应时间随着日志量的增加呈现线性增长的趋势。究其原因,Q1使用的是match查询,查询的是倒排索引,根据查询关键词找到倒排记录表中的文档ID集合,因此文档数量的成倍增加并不会导致查询时间的成倍增加。相比match查询,聚合分析的步骤更为复杂,流程如下:
(1)为需要聚合的字段构造Global Ordinals,耗时取决于索引段的多少以及字段的不同唯一值的数量。
(2)根据match查询结果得到文档ID集合,借助统计字段的doc values值得到统计字段的值集合。
(3)将统计字段映射到Global Ordinal构造的分桶里并统计各分桶中值的个数。
(4)根据聚合设置的返回文档数返回Top size的分桶数据。
由以上分析可得结论:单索引千万条日志量级下,集群对match查询的响应时间极快,而聚合分析的过程更为复杂,耗时更长。
TEST2中分别统计段合并前后日志占用的内存大小,段合并的命令如下:
curl XPOST "10.90.1.64:9200/test_500/_optimize?max_num_segments=1"
统计索引所占内存的命令如下:
curl-s"http://10.90.1.64:9200/_cat/segments/test_500?v&h=shard,segment,size,size.memory"|awk‘{sum+=$NF} END {print sum}’
段合并前后各索引所占的内存情况、内存优化量和优化百分比见表3,对比如图4所示。从图表中可以看出,内存优化百分比从6.7%到15.9%不等,段合并优化效果十分明显。
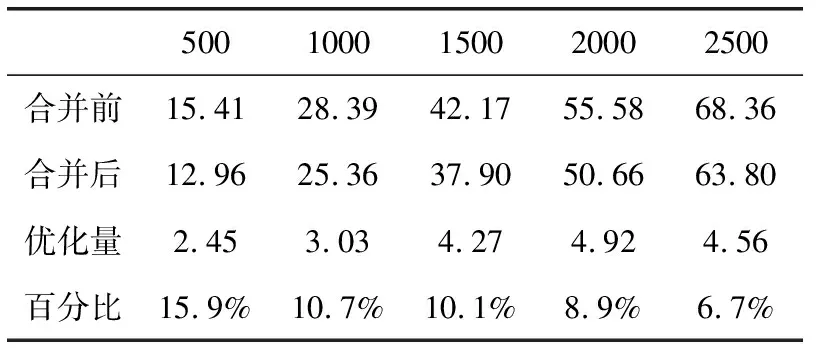
表3 段合并内存统计/Mb

图4 段合并前后索引内存对比
4.4 日志可视化分析
在Kibana中可以生成多种图表,如图5所示,左到右由上而下依次为:HTTP状态码对应的页面比例图、日志导入量时段图、日志总条数、系统的UV统计(由于使用了代理UV数量较少)、客户端浏览器代理比例图、访问页面Top 10、各主机日志导入比例图。
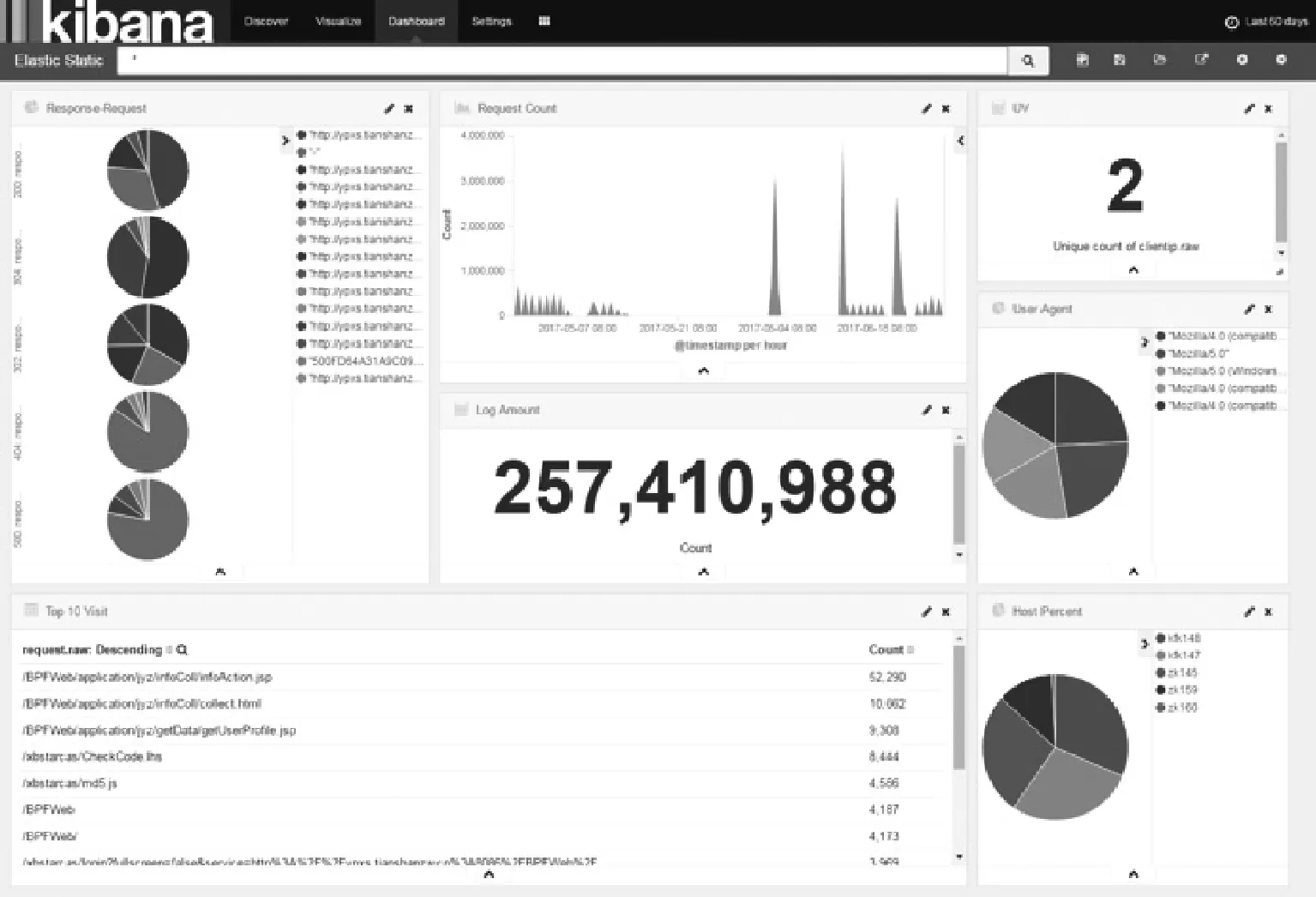
图5 Kibana仪表盘
5 结束语
本文对ELK日志分析平台进行了研究及应用,在各个应用服务器上部署Beats家族中的Filebeat完成日志采集工作,探索了Logstash解析日志的规则与技巧,总结了优化Elasticsearch分布式集群相关经验,最后在Kibana中对日志做了聚合和可视化的分析。解决了日志采集、日志解析、日志存储、日志检索、日志可视化的问题,为系统维护和日志分析提供了有效的方法。
猜你喜欢
江苏科技信息(2022年16期)2022-07-17
华人时刊(2021年13期)2021-11-27
高技术通讯(2021年5期)2021-07-16
心声歌刊(2020年4期)2020-09-07
当代陕西(2019年13期)2019-08-20
小学生(看图说画)(2017年6期)2017-11-06
图书馆建设(2015年10期)2015-02-13
新世纪图书馆(2014年7期)2014-09-19
电子设计工程(2014年19期)2014-02-27
测绘科学与工程(2014年5期)2014-02-27
