
面向作文自动评分的优美句识别
2018-07-18 02:35付瑞吉王士进胡国平
中文信息学报 2018年6期
付瑞吉,王 栋,王士进,胡国平,刘 挺
(1. 科大讯飞股份有限公司研究院,安徽 合肥518057;2. 科大讯飞股份有限公司 哈工大讯飞联合实验室,北京100094;3. 哈尔滨工业大学 计算机科学与技术学院 社会计算与信息检索研究中心,黑龙江 哈尔滨150001)
0 引言
现行高考语文作文考纲的发展等级要求词语生动、句式灵活,善于运用修辞手法,文句有意蕴[1]。这是在语言通顺基础上提出的高一层次的语言标准,或是语言生动,或是句式灵活,或是善于运用修辞手法,或是文句有意蕴,这些都是有文采的表现[2]。考生在运用语言方面,只要有某一处闪光耀眼的地方,都应该加以肯定和鼓励,以保证他们在通顺的基础上所展示的各种语言风采能够得到应有的评价。
一个句子有文采与否,看似是一件主观的事情,实则也有一定的规律。本文参考了高考语文作文中关于优美表达的判别标准: 有文采的句子通常在语言生动、活用句式、运用修辞、巧借引用、巧用文言词语等某一方面或几方面有突出之处[3]。我们同时请高考评分专家对数据标注过程进行了指导和数据质量保障。并在此基础上,提出了面向作文自动评分的优美句识别任务。
优美句识别可以看作一个文本分类问题。文本分类的主要任务是在预先给定类别集合的前提下,计算机通过分析文本内容判别其类别。传统的文本分类通常有文本领域的区分,如新闻可分为政治、体育、财经等;还有基于文本特定维度的分类,如情感分类、垃圾邮件过滤等。传统的基于统计机器学习的方法[4-9]通常需要人工设定特征模板,从文本中抽取出来,作为分类模型计算的依据。而优美句识别是一种句子级的二元分类问题,与传统文本分类相比,优美的文采更难以把握,很难人为制定优美的特征。
而神经网络方法的一个优势恰好在于无需人工特征,即可从数据中学习得到模型参数。因此,本文提出一种基于卷积神经网络(CNN)和双向长短时记忆(BiLSTM)网络的混合深度神经网络的优美句自动识别方法,并对比了该方法和CNN、BiLSTM网络等在此任务上的效果。实验证明,混合神经网络获得了最好的准确率,以及和BiLSTM网络相当的最好的F1值。
最后,判别作文句子优美与否,也是作文自动评分任务中的关键之一。本文对于整篇作文句子的优美程度及分布进行分析,并可组合相关特征对作文进行自动评分提供帮助,提高作文评阅精度。
综上,本文的主要贡献包括: ①首次提出了句子优美自动识别的任务; ②采用混合深度神经网络进行分类预测取得了较好的效果; ③优美句子识别结果作为特征,可改善作文自动评分。
1 相关研究
1.1 传统文本分类技术
文本分类一直是自然语言处理领域的研究热点和关键技术之一,在Web内容管理、搜索引擎、邮件过滤等许多实际应用中都扮演着至关重要的角色,是组织和管理数据的重要方法。
从20世纪90年代起,基于统计机器学习的文本分类逐渐兴起,常用的文本分类方法如 K 近邻法(K nearest neighbor,KNN)[4]、最大熵(maximum entropy,ME)[5-6]、朴素贝叶斯(Naïve Bayes,NB)[7]、决策树(Decision Tree,DT)[8]、支持向量机(support vector machine,SVM)[9]等。尤其是SVM,很长一段时间内在效果和稳定性上占据优势[10-11]。然而这些机器学习方法大都采用浅层结构,为了使其有较好的性能,系统必须融入大量的人工特征。这些特征集合一般具有高维度、稀疏、特征间相关性大的特点。因此,在传统的基于机器学习的文本分类任务中选择和提取特征成为一个重要的任务。
1.2 基于深度神经网络的文本分类技术
近年来深度神经网络技术快速发展,在自然语言处理的许多任务上都取得了很好的效果。深度学习模型的一个显著优势在于特征的自动选取和组合,能够提取出较好反映文本信息的特征。 基于 Hinton 对概念进行分布表示(distributed representation)的思想[12],词嵌入(word embedding)或称为词向量将词用一种低维实数向量表示,使得语义相似的词在距离上更接近,成为衡量词语语义远近的一个有效方法。词向量可由大量生语料训练得到,无需人工标注,且它的引入有效降低了网络的深度,使得深度学习成为文本分类的一种高效方法。
常用的深度神经网络包括卷积神经网络(convolutional neural network,CNN)[13]和循环神经网络(recurrent neural network,RNN)[14]。深度学习算法在图像处理和语音识别领域取得了令人瞩目的成果[13-15]。其中,CNN是近年发展起来并引起广泛重视的一种高效学习方法,是目前应用最为广泛的一种深度学习结构,通过卷积层(convolutional layer)和池化层(pooling layer)来具体实现。CNN可以很好地利用文本中的局部特征,如相邻词汇间的关联关系等。Kim将CNN用于文本分类任务,仅用一层卷积层就达到了很好的分类效果[16]。Zhang等人采用基于字符层面的卷积神经网络进行文本分类,他们设计了一个9层的CNN,包括6层卷积层和3层全连接层,该CNN在多个文本分类任务上取得了最好的效果[17]。
RNN的结构更适用于时序特征的利用,并支持变长输入。然而传统的RNN在使用后向传播进行训练的时候会出现梯度消失和梯度爆炸的问题,这些问题导致传统的RNN捕获不到远距离的依赖,而只能捕获当前位置近距离的信息。Hochreiter和Schmidhuber提出了长短时记忆(long short-term memory,LSTM)网络[18],在神经元上添加输入门、遗忘门和输出门的方式更好地控制神经元中信息的传递,由于每个神经元上的门打开的时刻可以不同,所以LSTM可以捕获远距离的特征和近距离的信息,同时可以更有效地过滤掉不重要的信息,起到去噪的作用。原始的LSTM是沿着序列的一个方向扫描,为了更好地捕获序列的模式信息,常用的一种方式是采用双向LSTM。目前LSTM广泛应用于机器翻译、信息检索、文本分类等任务中[19-22]。Liu等人提出了基于多任务学习的RNN,在文本分类中取得了很好的效果[21]。Tai等人提出了树LSTM,用于语义关联学习和情感分类任务[22]。Lee等人在RNN和CNN中加入了时序化信息,提升了多轮对话中短文本分类的效果[23]。
1.3 作文自动评分
作文自动评分(automated essay scoring, AES)是使用计算机对作文进行评估和打分的技术,其中最著名的是E-rater系统,它是由Educational Testing Service(ETS)的Burstein 等人在20世纪90 年代末开发的作文评分系统[24-27]。目前ETS正利用该系统对GMAT中Analytical Writing Assessment(AWA)部分进行评分,并于2005年开始应用于托福考试的作文评分[28]。
近十几年来,国内外自然语言处理研究者在作文自动评分领域开展了不少研究工作,以英文作文评分居多。按照研究侧重点的不同,相关工作大致可以分成内容和表达两个方面。
内容方面,Burstein等基于句子位置、论点高频词以及RST篇章关系特征,通过贝叶斯分类方法实现对英文熟练度测试(English proficiency test, EPT)中答案中心句子的识别[29]。Burstein等通过改进Barzilay和Lapata的实体连贯性算法[30],引入其他表征作文质量的特征,对作文连贯性进行二元分类,取得了较好的效果[31]。Persing和Ng对作文主题的清晰度进行了评价,他们将导致作文主题不清晰的原因分成五类,针对每种类型的错误训练二元分类模型,从而实现导致主题不清晰错误的识别,同时基于上述针对错误识别的特征,运用回归方法实现对作文主题清晰度的评分[32]。Klebanov等通过互信息统计词汇之间的关联度,将词对分成高、中、低三种关联,通过对文章的分析发现: 作文的质量越高,其高和低两种类型关联度所占的比例较大,而词对关联度处于中等水平所占的比例较小。引入词对关联度分布情况作为特征,可以提升作文评分的效果[33]。
表达方面,由于EFL(English as first language)句子不符合语法规则,采用传统的依存句法分析十分困难,Lonsdale采用链接语法对句子进行分析,同时引入一些作文相关的句法规则,从而提升句法分析的鲁棒性[34]。Chang基于对词性和词汇不同水平文章的分布分析实现修辞手法连接词(如“变成”“好像”)的识别,然后通过定义一些规则,从而实现对包含修辞手法的句子的识别,最终通过ID3决策树将作文分成高和低两种等级[35]。
最近几年,随着深度学习的广泛应用,一些研究者也尝试了基于神经网络深度学习的作文评分。 Alikaniotis等人采用LSTM来表示作文,同时在训练时引入分数信息对词汇的表示进行调整,得到面向评分任务的词向量表示(score-specific word embeddings),从而提高了评分的准确率[36]。Dong 和Zhang采用的是双层卷积神经网络CNN,第一层是句子级的表示,第二层是篇章级的表示,同样要调整词向量表示,使其更适合评分任务[37]。Nguyen和Dery对比了多种神经网络,包括CNN、RNN和LSTM等,结果显示LSTM在作文自动评分上表现最好[38]。
2 优美句子识别方法及其应用
优美句子识别可以看作是一个文本分类的问题,输入为句子文本s=x1x2…xn,输出为二元分类结果:y∈Y,Y={优美,不优美}。传统的文本分类是根据文本中的内容,如词汇分布等,预测文本是否属于某一领域,如政治、财经、体育等。但与传统的文本分类不同的是,优美句子识别任务是根据句子内容、表达方式等对于句子优美程度做出判别。
本节提出三种基于深度神经网络的优美句子识别方法,并介绍优美句子特征在作文评分中的应用。
2.1 基于深度神经网络的优美句子识别方法
本节分别介绍三种基于深度神经网络的优美句子识别方法: 循环神经网络、卷积神经网络,及循环和卷积混合的神经网络。
2.1.1基于卷积神经网络的优美句子识别
我们首先训练词向量(word embedding),然后将一句话中的词向量输入到卷积神经网络中,经过卷积层、池化层后(这里我们只采用了一层卷积和池化)。然后在上层接入全连接层进行分类,结构如图1所示。

图1 基于CNN的优美句子识别
卷积层第j个卷积核的输出cj按照式(1)计算,其中xi为相邻a个词向量组成的二维矩阵中第i个向量,a为卷积核窗口大小,kij为卷积核中第i个向量,bj为偏置。最后通过一个激活函数f得到隐层特征值。池化层采用最大值池化(max-pooling)选择隐层向量中的最大值,如式(1)所示。
(1)
训练时,训练数据以句子为单位,均标有“优美”或“不优美”的标记,我们采用反向传播算法训练模型参数。
2.1.2基于循环神经网络的优美句子识别
我们首先训练词向量,然后将一句话中词向量依次输入到双向循环神经网络中,然后再接入一个全连接层进行分类。本文中的循环神经网络,我们使用的是常用的双向LSTM,其特点是可以捕捉到长距离的相关特征,结构如图2所示。

图2 基于双向LSTM的优美句子识别

其中,w1×m为全连接层网络参数,b为偏置。
2.1.3基于混合神经网络的优美句子识别
由于优美句子的识别不仅需要考虑句子的内容,比如用词是否生动、是否引用诗词等,而且要考虑句子的组织形式,比如句式组织是否工整,读起来是否朗朗上口,这就要求模型能够捕捉句子的局部信息和全局信息。因此,本文尝试使用CNN对于局部短距离特征进行建模,而在此基础上利用Bi-LSTM对这些局部特征进行串联来刻画全局特征。
首先将词向量输入到CNN网络中,在卷积层得到一系列特征向量后,再将各维向量补充空值为等长向量后对齐,组成纵向向量,按照时序作为双向LSTM的输入,最后再接入全连接层中计算分类概率进行类别的判别,如图3所示。结合式(1)~式(5),得到我们混合神经网络的分类概率计算如式(6)、式(7)所示。

图3 基于混合神经网络的优美句子识别
这样做的好处在于可以将局部多个窗口内的信息综合起来,再通过BiLSTM获取长距离的依赖,便于利用局部和全局信息的综合判断,但也增加了参数数量,需要更多的训练语料来训练。
2.2 优美句子特征在作文自动评分中的应用
在优美句识别的基础上,我们尝试将优美句特征应用于作文自动评分任务。实验使用科大讯飞研发的语文作文自动评分系统,该系统参考高考作文评分标准,基础特征包括词汇丰富性、句子通顺度、立意高低、篇章结构等多个方面,采用支持向量回归(support vector regression,SVR)、梯度提升决策树(gradient boost decision tree,GBDT)、岭回归(ridge regression)等多种回归模型融合,对作文进行自动评分。
按照高考作文评分标准的指导,在不离题的情况下,语言表达越优美,作文分数越高;文采越好,作文发展等级得分越高,使得作文最终得分越高。基于本文提出的优美句识别结果,我们设计了一系列特征(表1),加入到基础特征中,考察其对于自动评分的作用。

表1 面向作文自动评分的优美句子特征
3 实验和结果
3.1 实验设置
3.1.1优美句子识别数据
实验部分,我们从一个公开的学生作文练习批改网站*http://www.leleketang.com/zuowen/上收集优美句子训练语料,示例如图4所示,我们抽取划线句子为优美句子的候选。采用这种方式,并经过人工标注确认,我们共得到3万句优美表达,然后随机从未划线句子中选取约6万句作文反例,构成训练数据(正反例比例为1∶2)。

图4 优美句子训练集获取示例
为了测试,我们从真实的中学生考试作文中随机选取21 053个句子,人工标注优美与否,作为测试语料,其中被标注为优美的句子共3 990句(占比18.95%)。我们请两个标注人员背靠背标注,Kappa值为0.87。
此外,我们还从互联网爬取中学生作文,共计约139万篇,用于训练词向量。我们采用skip-gram的方法[39]进行训练。
3.1.2作文评分数据
为了评价优美句子特征对于作文自动评分的影响,本文选取了三次中学生语文考试的作文来测试,数据包括原始试卷图片以及对应的人工评分。我们首先采用手写汉字识别技术将试卷图片中的作文内容识别出来,转换为文本,然后再基于文本内容进行自动评分。三次考试评分数据的基本情况如表2所示。

表2 作文自动评分数据情况
3.2 评价方法
我们采用准确率、召回率和F1值作为优美句子识别的评价指标。
对于作文评分,我们采取如下指标:
(1) 一致率: 计算机评分和现场评分(这里将评分现场的人工评分简称为“现场评分”)之间的分差在一定范围内视为评分一致(按照语文作文的评分惯例,一般取满分的10%作为阈值),在双评阅卷中不一致的作文须第三人复评,以保证评分的准确性。一致率的比例也可反映出将来实施人机双评后复评率的高低。
(2) 平均分差: 计算机评分和现场评分之间的分差的平均值,反映评分之间分差大小。
(3) 相关度: 计算机评分与现场评分之间的皮尔逊相关系数(式8),其中X和Y表示计算机评分和现场评分两个序列,cov(X,Y)表示X和Y的协方差,σX表示X的标准差,σY表示Y的标准差。
(8)
(4) 仲裁胜率: 对于计算机评分和现场评分不一致的作文,我们随机抽取部分由专家精评,以专家评分为标准来评判现场评分和计算机评分的准确性。当计算机评分和仲裁分一致,并且现场评分和仲裁分不一致时,则计算机评分更接近于仲裁分,视为计算机评分胜,反之则现场评分胜,如表3所示。

表3 仲裁评分定义表
3.3 实验结果及分析
我们首先对不同的优美句子识别方法进行了对比分析,然后将优美句子特征用于作文自动评分任务,分析其作用。
3.3.1优美句子识别结果对比
在优美句子识别任务中,我们比较了经典的基于特征工程的分类方法与深度神经网络方法,经典分类方法包括逻辑回归(logistic)、最大熵、支持向量机,神经网络方法包括前面介绍的CNN、Bi-LSTM以及本文提出的混合神经网络方法。基于特征工程的方法所使用的特征为句子中所有词向量(embedding)的平均值。
由表4可见,在优美句子识别任务上,神经网络的表现均比传统统计分类方法好。其中,BiLSTM的召回率和F1值最好,混合神经网络(CNN+Bi-LSTM)的准确率最高,F1值与BiLSTM相当。表4最后一行为多人人工标注结果的平均指标。

表4 优美句子识别对比结果
混合神经网络的召回率不如BiLSTM,可能的原因是参数更多,所需的训练数据更多,本文中的训练数据量可能不足以支持其充分训练。后续工作中可尝试标注更多的训练数据验证。然而,在某些准确率要求较高的场景,比如作文自动批改场景中,模拟老师划出文中最亮点的句子,而并不要求全部划出,混合神经网络的结果更符合实用要求。
3.3.2优美句子识别结果分析
我们期望分析优美句子识别模型到底捕捉到了什么样的特征,使其具备区分句子是否优美的能力。但神经网络模型的中间结果难以被直观解释,于是我们采用间接分析的方法,通过修改句子观察模型输出结果的变化,来推测神经网络模型起作用的模型。
如表5所示,我们尝试将优美句子中的一些内容替换掉或删除,或者将句式改变,观察模型预测概率的变化。当我们将生动的描述性词汇(或成语、短句)替换为普通词汇(或短句),模型输出的优美概率明显下降;当我们将诗词引用替换为意思相同但大白话版的表达,优美概率也大幅下降;当我们将工整的句式修改为普通的句式,优美概率同样会显著下降。由此可以间接说明,我们的模型能够捕捉到作文句子中生动的语言、工整的句式以及古诗词引用等信息,从而据此判断句子优美与否,这符合高考作文优美表达的评判标准。
此外,我们还在表6中展示了部分基于混合神经网络识别正确和识别错误的例子。可见我们的方法对于用词优美考究的句子识别较好,而对于语言普通但蕴含哲理的句子识别较差。

表5 优美句判别结果修改分析示例

表6 基于混合神经网络的优美句子识别结果示例
究其原因,一方面是由于前一种类型优美句容易被中学生学习和运用,但要写出蕴含哲理的句子,需要深厚的文化素养和深刻的思考,要做到比较难,这导致训练语料中前一种类型的句子较多;另一方面,前一种体现在用浅层词汇上的优美特征较容易获取和学习,相较于含蓄的富有哲理的句子,优美词汇和搭配或者明显的修辞手法,如排比、比喻等,比较容易被神经网络学习掌握。
3.3.3优美句子特征对于作文评分的影响
在3.1.2节介绍的中学生作文评分数据上,我们基于1.3节介绍的特征进行评分实验,分别加入优美句子相关的特征,观察评分效果是否有所提高,实验结果如表7所示。
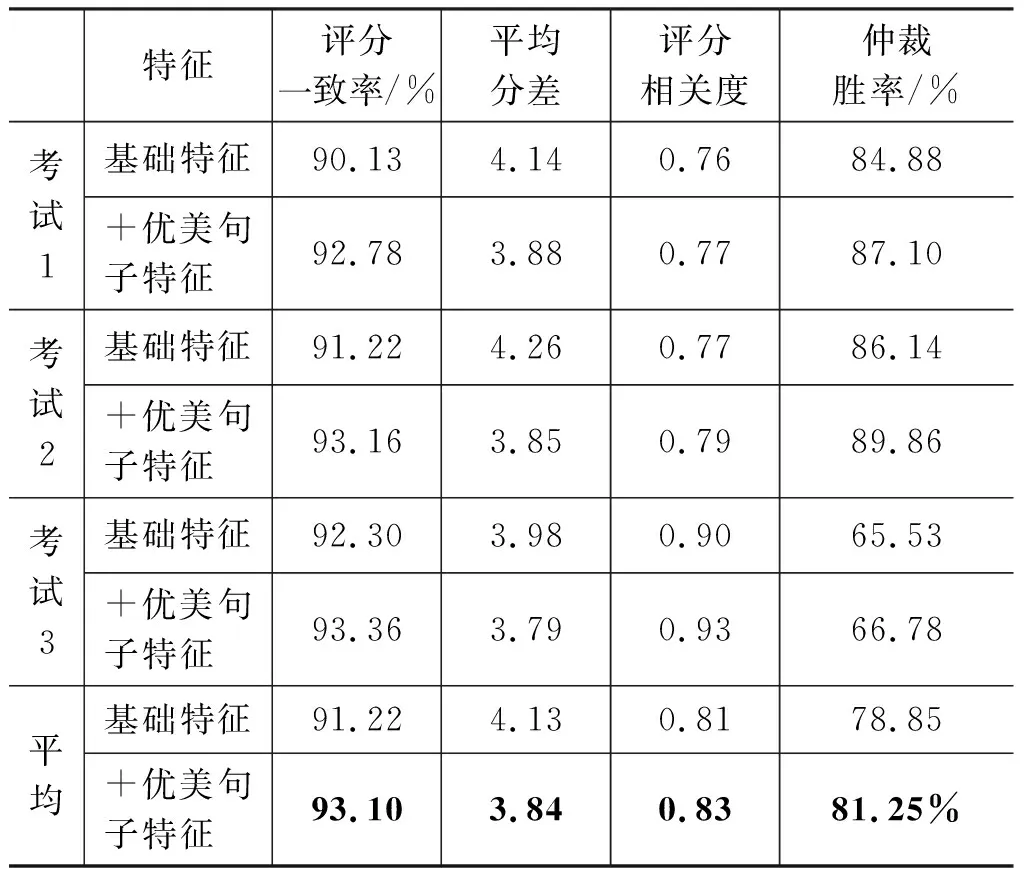
表7 优美句子特征对于作文自动评分结果的影响
如表7中结果所示,在基础特征基础上增加优美句子特征,可以稳定地改善作文评分的的一致率、平均分差、相关度和仲裁胜率。其中,平均评分一致率提高1.88%,即大分差的比例由8.78%降低到了6.90%,下降21.41%;平均分差缩小0.29分;相关度提高0.02;仲裁胜率提高2.4%。
此外,本文还对2.2节中提出的优美句特征进行了更加详细的实验分析。如图5所示,可见作文中句子优美概率的最大值Fmax和最小值Fmin特征并不有效,可见偶尔的好句子或差句子并不影响评分;其余的特征可以代表整篇作文的语言表达水平,实验证明这些特征均是有效的。

图5 优美句子特征详细对比结果
3.3.4优美句子识别在作文自动批改中的应用
我们还将优美句子识别技术应用于讯飞智学网(http://www.zhixue.com)的作文自动批改系统中,模拟老师划出文中亮点句子(图6)。该系统已在北京、安徽等地的部分中学试点应用。

图6 优美句子在作文自动批改中应用示例
4 结论
本文提出了面向中学生作文自动评分的优美句识别任务,并对比了CNN、BiLSTM和混合神经网络等方法。实验证明,BiLSTM获得了最佳的F1值75.45%,卷积和循环混合神经网络的准确率最高,达到89.23%,F1值与BiLSTM相当,达到75.39%。通过间接分析发现,本文提出的模型可以捕捉到作文句子中生动的语言、工整的句式及古诗词引用等信息,从而据此判断句子优美与否。另外,本文将优美句子特征用于作文自动评分任务,实验结果显示,反映整篇作文语言水平的优美句子特征可以有效提高作文自动评分的各项指标。在未来工作中,我们将继续探索新方法,进一步提高优美句子识别的效果,并探索更多评估中学生语言表达能力的方法,提高作文自动评分的精度,可以使计算机评分和人工评分的大分差比例下降21.41%。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
北京航空航天大学学报(2021年9期)2021-11-02
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
电子制作(2019年13期)2020-01-14
电子制作(2019年19期)2019-11-23
电子制作(2019年11期)2019-07-04
电子制作(2019年24期)2019-02-23
北京航空航天大学学报(2018年1期)2018-04-20
高中生学习·高三版(2016年9期)2016-05-14
重型机械(2016年1期)2016-03-01
