
移动社交网络幂律分布特征及亲属关系判别
2018-07-18 02:36:08张树森魏玉党梁天新
中文信息学报 2018年6期
张树森 ,魏玉党,,梁 循,窦 勇,许 媛,梁天新
(1. 中国人民大学 信息学院,北京 100872;2. 国防科学技术大学 计算机学院 并行与分布处理国防科技重点实验室,湖南 长沙 410073)
0 引言
在社会生活中,通信网络能够反映出人们现实生活中的社交关系,由此产生一种包含丰富信息的网络,即移动社交网络。移动社交网络通常指的是结合移动终端设备,并能通过移动终端设备的位置信息而产生的一种社交网络。与当前移动社交网络概念不同,本文将通信网络中的通讯录网络、通话网络和短信网络作为移动社交网络进行研究。当前,社交网络[1]受到众多学科的广泛关注,成为了研究者关注的热点。移动社交网络具有稳定、可靠特性,能够反映人们社交活动的真实情况。因此,从社会网络研究和社交关系分析的角度来讲,移动社交网络具有一定的研究价值和意义。此外,移动社交网络的研究还对通信网络的监控和管理以及商业应用等具有重要的现实意义。
近年来,由于我国网络通信技术的快速发展,移动社交网络得到普及和应用。如图1所示,截至2016年12月,我国国内网民达到7.31亿,手机网民达6.95亿,即时通信用户达6.66亿,比2015年年底增长4 219万。随着社交网络的不断发展,为我们研究现实世界人与人之间的社交网络和社交关系提供了广阔的空间和研究条件。

图1 2011—2016年国内即时通信用户规模
当前,针对社交网络的研究很多,如针对在线社交网络Facebook、Twitter、微博等进行的研究,并且许多研究结论已经应用到现实生活中的多个领域。然而,针对移动社交网络的研究则相对较少。本文探讨的移动社交网络研究内容,主要包括移动社交网络中的幂律分布特征和用户亲属关系的判别。社交网络特征分析是研究和分析社交网络的重要途径,以往研究中的样本规模往往不够大,所得结论常常并不准确[1]。在社交网络中,人与人之间关系的研究一直是社会网络的重要课题。研究人员通过收集和分析相关社交数据,利用用户与其联系人属性和行为上的相关性,实现对用户关系的判别和研究。然而,由于网络的开放性,不可避免的丢失部分用户之间固有的连接关系。同时,由于用户在社交网络中的亲属关系一般都是隐式表现的,而本文的亲属关系判别将有助于恢复网络中的用户亲属关系。此外,研究亲属关系不仅能够分析出亲属关系网络的构成模式,而且有助于推进社会结构的进一步优化。
本文针对移动社交网络特征中的幂律分布特征以及用户亲属关系进行研究。在研究过程中,我们首先对移动社交网络中的幂律分布特征进行分析,并对得到的结论和规律进行说明。然后,通过用户社交行为对用户之间是否存在亲属关系进行判别,提出用户亲属关系判别模型。同时,将该模型与不同算法进行对比,检验该模型的有效性,其判别精确率达到81.01%。
1 相关工作
1.1 相关研究
在社交网络中,用户社交关系[2]的判别或预测,一直是社交网络分析中的重要研究方向。其中,针对用户关系的判别主要是从结构和社会学角度加以研究。例如,Liben-Nowell等人[3]根据网络共同点和网络路径两种网络结构方面的相似度,通过计算其特征及特征之间的相互作用,对用户之间的关系进行了分析和预测。Adamic等人[4]基于统计共同好友的情况,提出了Adamic Adar算法。
在用户关系的研究中,一些研究者还通过聚类分析以及图分割分析的方法分析用户间的关系。例如,Zhang Y[5]等人通过计算用户间的相似性,利用K-means聚类算法识别微博用户群体关系。Gao Q[6]等人将用户关系作为边,利用MSCC(maximal strongly connected components)方法对用户进行划分,并对不同用户群体关系进行了挖掘。还有一些研究者通过用户动态分析判断用户间的关系,如袁毅[7]等通过跟踪用户对某一话题的交流数据,发现用户所形成的关注、评论、转发和引用四种关系。此外,Christopher C[8]等人通过同质性原理提出一种时间分析方法来识别社交媒体中用户的隐含关系。Noor F[9]等人通过分析不同社会网络系统的模式和相关性,识别出不同社会网络中群体中的朋友等用户关系。在亲属关系的判别研究中,一些研究人员通过机器学习的方法实现对用户亲属关系进行认证或判别。如根据用户面部图像,通过深度卷积神经网络提取亲属验证的特征[10]以及基于SIFT流的遗传Fisher矢量特征[11]实现对用户亲属关系的判别等。
本文主要研究移动社交网络中的幂律分布特征和用户间亲属关系判别的问题。此外,与以往分析用户关系的方法不同,本文的亲属关系判别研究没有从网络的结构和用户属性出发,而是将用户通话行为作为研究对象并进行分析。
1.2 实验数据
本文实验数据采集时间为2016年2月至2017年2月,由三个数据集构成,包括手机通信录(mobile phone contacts,MPC)数据、通话记录(Call Data Records,CDRs)数据和短信服务(Short Messaging Service,SMS)数据,如表1所示。

表1 实验数据集
由于本文数据中涉及用户的隐私以及保护信息安全的需要,本文中所采用的所有数据均是经过匿名替换处理的脱敏数据。同时,在实际分析过程中,还需要对数据集进行预处理,将其中无效、异常的数据去除。实际上,本文采用的实验数据较为丰富且涵盖国内大部分省市,能真实地反映国内移动社交网络用户社交行为,具有广泛的代表意义。
2 网络幂律分布特征分析
1999年,Barabási[12]揭示了网络中普遍存在的幂率分布,即网络中大部分节点只有较少的连接,而网络中具有较多连接的节点在网络中占较小的比例,从而改变了传统网络中认为的泊松分布特征,并将这种服从幂律度分布的网络称为无标度网络(scale-free network),如图2所示。
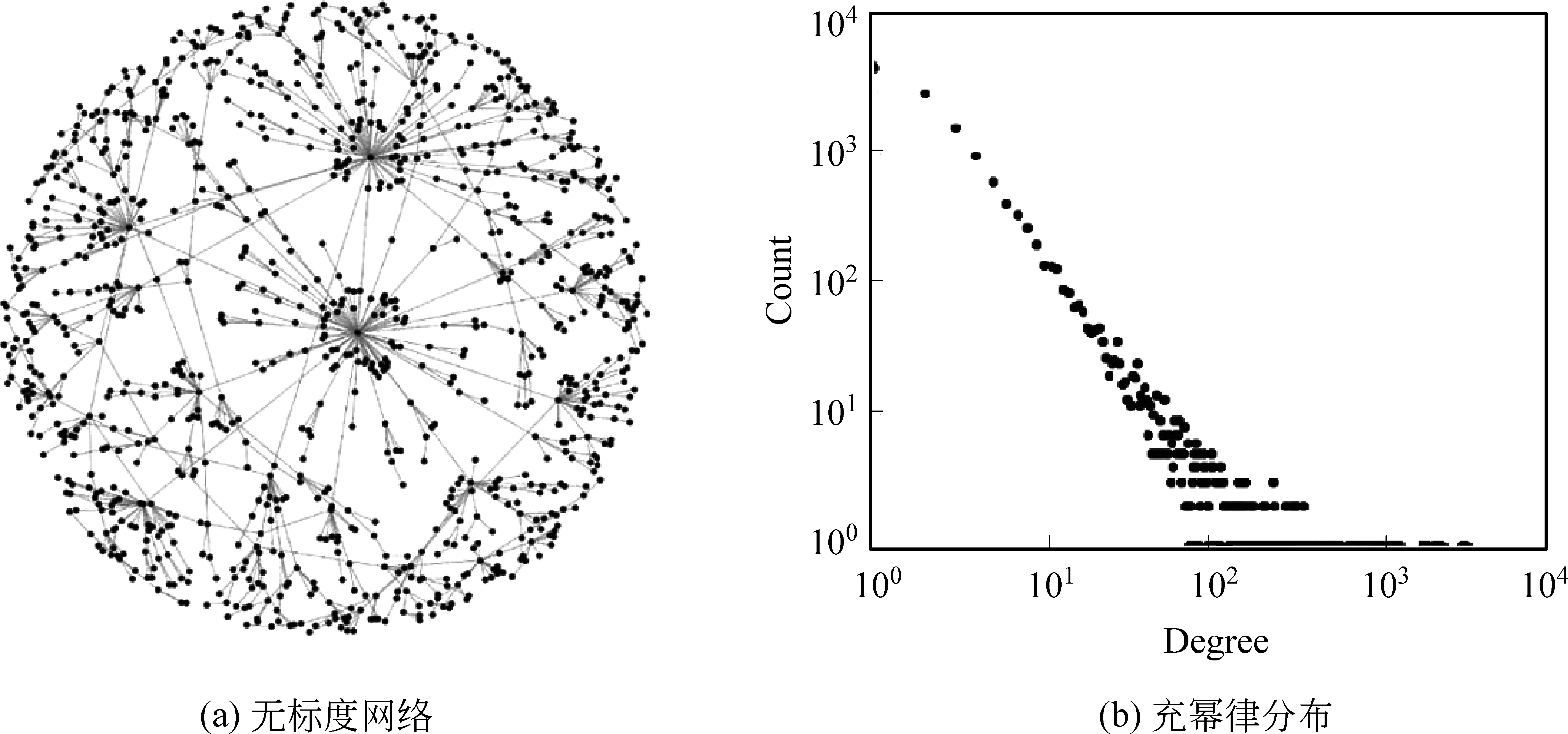
图2 无标度网络与度的幂律分布
2.1 度的幂律分布
在社交网络中,节点的度能直观反映用户在社交网络中的地位和影响力。度越大表示节点在网络中越重要。在社交网络中,度分布可定义为网络中度为k的概率分布。如图3所示,在考虑到方向性,从度(无向)、入度、出度三个方面对网络进行分析。我们发现,本文移动社交网络度分布均服从幂率分布且存在长尾,其分布指数γ分别为3.19、3.26、1.75。这种“长尾”分布表明,在社交网络中绝大多数用户的联系广度(范围)是一定的。同时,存在极少数用户联系广度较高。
由图3可知,在本文移动社交网络中,短信网络幂律指数最小,而幂律指数反映网络无标度特性的程度,值越大无标度特性越明显。由此说明,相比短信网络,通话网络与通信录网络的无标度特性更加明显。
为了进一步对本文移动社交网络节点度进行研究分析,我们计算网络中节点的平均度,并与其他社交网络(在线社交网络)对比。不同社交网络平均度(Ad) 具体信息,如表2所示。

表2 社交网络平均度
本文中的度可以表征为用户受欢迎程度、影响力、活跃度等。入度大说明该用户受欢迎程度较高,出度较大则说明该用户活跃性较高。

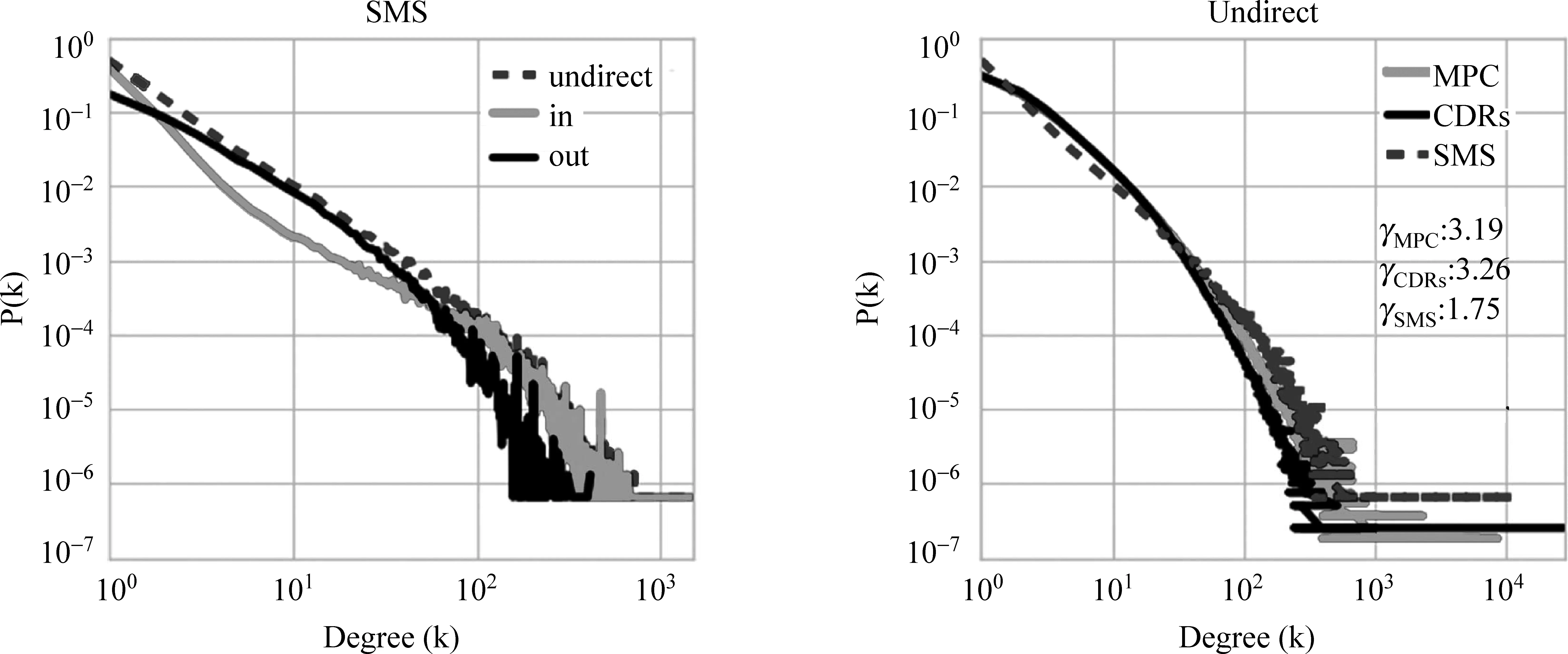
图3 网络(度)幂律分布
由表2可知,通话网络平均度是短信网络两倍多,说明在现实生活中相比短信通信,人们更倾向于通过电话进行沟通。本文社交网络的平均度在2~7之间,与国外相应社交网络平均度相近,如文献[13]中短信网络平均度为4.3。与在线社交网络相比,本文移动社交网络平均度明显低于在线社交网络,如Facebook[14]、Twitter[15-16]等。
我们分析产生这种差异的原因: 本文移动社交网络以用户真实关系为基础,社交广度会受到一定的限制。而在线社交网络则由于其开放性、虚拟性等特点,用户范围不会受到较大的限制,故在线社交网络的平均度要高于本文社交网络。同时,我们将平均度看作是用户活跃程度,进而表明人们在虚拟网络中表现出更高的积极性,社交活动更加活跃。
2.2 连通子图规模幂律分布
根据图论原理,如果无向图的节点之间存在路径,则称两节点是连通的。如果图中任意两节点都是连通的,该图称为连通图,否则为非连通图。在本文移动社交网络中,我们分别对强连通子图和弱连通子图规模(连通子图节点数)及连通子图数目进行分析,同样发现幂律分布规律。我们以连通子图节点数为横轴,以相同节点数的连通子图数为纵轴,得到如图4所示结果。
由图4可以发现,社交网络的强连通子图和弱连通子图的规模同样服从幂律分布,并且具有较为明显的肥尾特征,都存在一个较大的连通子图。
我们继续对本文移动社交网络中的最大连通图进行分析。在社交网络中,最大连通子图的节点数占整个网络的节点总数的比例,能够反映该网络的整体连通特性。通过分析,我们发现通信录网络、通话网络以及短信网络中最大连通图比例都较高。通信录网络、通话网络的最大连通图比例分别为96.8%、97.8%,其中通话网络与国外通话网络的84.1%[15]相比,其值更高。由此我们可以得出“本文移动社交网络具有较高的最大连通比例”的结论。此外,在线社交网络中,Twitter在2008年为97.6%[17],Facebook在2011年为99.91%,新浪微博、腾讯微博最大连通比例同样高达99.99%[17]。从而说明本文社交网络与在线社交网络均具有较强的连通性。

图4 连通子图幂律分布
此外,本文短信网络的最大连通图占比为66.3%,与2012年的91%、85%、97.92%[18]相比,明显偏低。这主要是因为在线社交网络的快速发展对短信造成较大的影响,如微信、Twitter、Facebook等,在线社交网络逐渐替代以文本信息为主要载体的短信服务,短信网络中连接数量不断降低,从而导致短信连通图比例下降。
2.3 用户联系人数量幂律分布
本文在对移动社交网络中用户联系人数量进行分析过程中,也发现了幂律分布特征。在分析过程中,我们将网络中的叶子节点也包含在内,分析用户联系人的实际规模(联系人数量)。如图5所示,我们以联系人数量为横轴,以联系人规模相同的用户数量为纵轴,左图为联系人数量的累计概率密度分布图。
由图5可知,通信录与通话网络联系人数量在一定规模内保持均衡,而超过一定规模则表现出幂律分布特征,而短信网络整体上服从幂律分布。通讯录中联系人数在128人以内的用户数量保持稳定,说明128人的社交关系总量能够满足用户在社交网络中基本的社交需求。通话联系人则反映出用户存在实际交互行为,其数量在55以内保持恒定,说明保持联系较为紧密的团体规模在55人以内,即一定规模的人群构成用户的核心网络成员。正如Marsden核心网络[19]理论一样,社交关系总量增长的不是核心网络成员数量,而是人们被动偶然联系的人数。
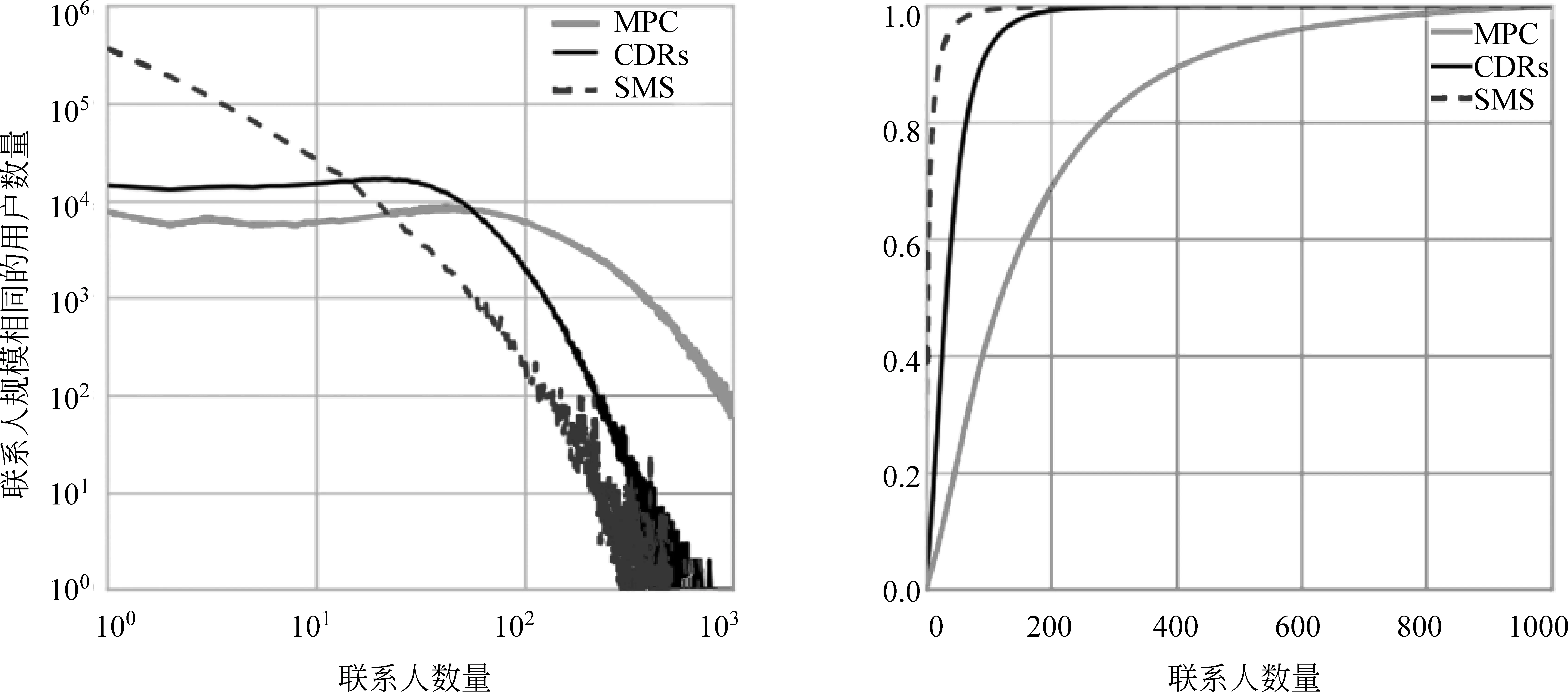
图5 用户联系人规模幂律分布
相对于通话网络与通信录网络,短信网络用户联系人分布表现出整体上服从幂律分布,并没有前期的稳定阶段。其原因在于随着即时通信工具的不断发展,如微信、QQ、Facebook等,以短信方式进行沟通的用户及短信的使用频率越来越少。由图5可知,通话网络与短信网络的联系人数量要明显小于通信录网络。通信录网络建立在社会关系存在的基础上,用户之间互相存在连接只能说明其社会关系存在,即路径可达。通话网络和短信网络则是建立在至少发生一次交互行为的基础上,是发生实际交互行为而产生的社会关系。由此,通话网络与短信网络的联系人数量要明显小于通信录网络。
移动社交网络中手机通信录(MPC)网络、通话(CDRs)网络和短信服务(short messaging service,SMS)网络都是手机用户在通信交流过程中形成的社交网络,都能够反映用户在实际生活中的社交状况。其中,通信录(MPC)网络是由用户通信录中用户之间形成的社交网络,可以说是用户认识的人之间的社交网络。而通话网络和短信网络中用户没有这种限制,用户之间可能是不认识的,尤其是通话网络。相对短信使用更加频繁,更能反映出用户现实中的社交情形。
实际上,幂律分布规律是社交网络中广泛在的规律。本文在研究过程中找出移动社交网络中存在的三个幂律分布规律,并与其他社交网络相对比。同时,对移动社交网络平均度低于在线社交网络,短信网络的最大连通图占比更低等规律和结论进行分析,进而优化验证了相关研究结论,对移动社交网络的结构及其用户社交行为有了更深入的认识,从而实现对移动社交网络的深入了解和分析。
3 用户亲属关系判别模型
3.1 亲属关系研究问题
在社会网络中,亲属关系是与用户联系最为密切的社交关系。在以往亲属关系研究中,研究人员由于研究条件的限制,往往通过调查问卷的形式采集数据进行研究,采集的样本规模也不够大。因此,研究中往往存在数据规模小、样本少的问题。当前,由于计算机及信息技术的快速发展,使大规模社会关系数据的获取和分析成为可能,为我们研究和分析亲属关系提供了条件。本文所采用的移动社交网络数据,具有数据量多、范围广的特点。因此,与小规模样本数量的研究相比,更具实际意义。
本文亲属关系研究的问题,主要是基于用户通话行为特征判别用户间是否存在亲属关系。我们通过提取用户通话行为的显著特征,采用GBDT(gradient boost decision tree)与LR(logistic regression)融合方法,建立一个亲属关系判别模型,并使用用户数据和提取的特征数据训练该模型。由此,通过该模型我们在具有通话交互行为的用户之间,判别他们是否存在亲属关系。
在本文亲属关系判别模型训练过程中,需要具有亲属关系的用户数据来训练模型。本文将具有亲属关系的用户数据,看成由八类关系用户数据组成,即夫妻关系、父子关系、兄妹关系、祖孙关系、堂表关系、伯舅关系、嫂夫关系及其他(如外祖、姨等)。在提取亲属用户数据中,用户之间具有这八类关系中的一种,本文即认为用户之间具有亲属关系。其中,在基于短信文本内容提取亲属关系用户数据过程中,祖孙关系、伯舅关系这两种亲属关系用户的准确率和数量相比其他亲属关系用户明显偏低。因此,在实际提取亲属关系数据及判别实验中不再考虑这两种关系的用户数据。本文结合机器学习和关系逻辑推理的方法,从短信数据中提取亲属关系用户数据。
3.2 数据特征选择
本文通过分析用户之间的通话行为特征,将亲属关系判别问题转换成数据挖掘中的分类问题。由于原始数据只有用户之间的通话时长、通话时间、及通话类型这三种属性特征,不能够有效对亲属关系进行判别,需要我们对用户通话行为特征进行提取。用户通话行为特征提取过程是以用户的通话时长与类型为基本属性,在通话次数、时间等维度上进行扩展。根据用户间通话的基本信息以人工的方式在不同指标和维度上进行扩展,如用户在通话时长上可扩展出通话总时长、平均通话时长、白天通话时长、夜间通话时长、日均通话时长、月均通话时长、工作日通话时长、周末通话时长等特征。
通话数据的采集时间跨度和时间点均与短信数据相同,但数据总量和用户量比短信数据要大得多。通过聚合通话数据与短信数据,求取其共有用户,并通过短信数据中用户亲属名称、称谓等提取亲属关系用户数据。在清理后得到的用户中,具有亲属关系的用户数为147.4万,不存在亲属关系的用户数为1 124.6万。由此,我们分别得到亲属关系用户数据集和不存在亲属关系用户数据集。同时,根据提取的特征分别得到两种数据集中的特征数据。
3.3 亲属关系判别模型选择
3.3.1相关算法
(1) 逻辑回归(LR)是当前比较常用的机器学习方法,通常用于估计某种事物的可能性,是一种广义线性模型。由于LR决策边界是线性的,当面对复杂的学习任务时,其效果并不理想。只能通过人工的特征工程制造出有效的变量和变量组合,间接的增加其非线性学习的能力。如何实现自动的特征发现、组合,以弥补人工经验的不足,从而缩短特征工程周期,成为当前LR分析中所面临的问题。
(2) 梯度提升决策树 (GBDT)是一种基于boosting思想的集成学习算法。GBDT中每一棵提升树都可以看作构造特征的一种方法,且有监督式产生的特征具有一定区分性。
3.3.2判别模型选择
本文将提升树叶子节点作为LR的特征变量,由此大大减少了人工寻找特征及特征组合的时间,由此我们得到GBDT与LR融合方法。将GBDT与LR融合前需要人工寻找有区分性的特征(raw feature)、特征组合(cross feature),融合后直接通过GBDT进行特征、特征组合的自动发现。
本文选择GBDT与LR融合方法进行亲属关系判别,主要是为了综合考虑亲属关系判别中的运行速度和准确率,以及运行大规模数据的可行性。采用LR模型前加GBDT模型,是因为要解决LR的非线性判别能力问题,GBDT模型后接LR是解决算法速度或者应用于大规模数据性能问题,两者结合是能够在性能和速度上都有所提高。
GBDT与LR融合方法处理流程,如图6所示。GBDT模型通过学习得出两棵决策树Tree1、Tree2,输入样本x经过对两个决策树遍历后,分别在两个提升树的叶子节点上形成值。如果x分别落在Tree1、Tree2的第二个叶子节点和第一个叶子节点,则相应的特征则为[0,1,0,1,0]。决策树是简单的预测模型,其代表着样本数据与目标变量之间的一种映射关系。决策树中的每个节点表示某个对象,而每个路径则代表某种可能的属性值。叶子节点则对应从根节点到所历经的路径所表示的对象值。每条路径都是通过损失函数最小化等方法得到的具有区分性的路径。通过该路径处理的特征,是经过决策树判断整合后的特征。通过这种方式得到的特征或者特征组合,其模型效果理论上不低于人工处理的方式。GBDT模型的特点,非常适合用来挖掘有效的特征及特征组合。

图6 融合算法流程
3.3.3亲属关系判别模型
本文中,我们将GBDT与LR的融合方法应用到亲属关系的判别。由此,得到本文亲属关系判别模型。本文亲属关系判别过程为:
输入: 训练数据T={(x1,y1),(x2,y2),...,(xN,yN)},xi∈x⊆Rn,yi∈y⊆R。
输出: 提升树fM(x),KI值,亲属关系模型
(1) 初始提升树f0(x)=0
(2) 对m=1,2,...,M
+T(xi;Qm))
其中,Qm为决策树参数
残差γmi=yi-fm-1(xi),i=1,2,...,N
(b) 拟合残差γm i学习一个回归树,得到
T(x;Qm)
(c) 更新fm(x) =fm-1(x) +T(x;Qm)
(3) 得到回归问题提升树。
(1)
(4) 每个样本点再映射到每个树上的相应节点,则有M个特征。
(5) 将得到的M个特征作为LR的输入,进行训练。
(6) 通过LR得到关系预测值R,R≥0.5时,我们认为用户之间具有亲属关系,否则没有亲属关系。
本文用户亲属关系的判别研究是以用户间通话的记录和短信数据进行分析。通过短信数据中具有的亲属关系定义中的称谓、身份等信息确定用户间是否具有亲属关系,进而得到实验数据集(具有亲属关系的数据集和不具有亲属关系的数据集)。通过提取用户通话行为特征,使用实验数据集对分类算法模型进行训练,得到亲属关系的分类模型,然后进行验证分析。在实验数据中,我们得出的仅仅是两类数据,并没有对具体亲属关系类型进行分类和处理。对于其他用户关系,如朋友、同事等,在本文数据中难以确认用户之间是否是朋友或同事等关系。因此,本文研究过程中通过用户间的通话行为进行分析,只对是否存在亲属关系进行判别,没有对其亲属类别进行详细判别。
3.4 实验过程
在实验过程中,我们将本文亲属关系判别模型的实验结果与其他机器学习算法实验结果进行比较,验证本文亲属关系判别模型的有效性。
3.4.1评价指标
在实验结果评价中,我们通过K折交叉验证评估方法验证本文亲属判别方法的有效性。该方法将数据集分割成K个等份,其中K-1份作为训练,1份作为测试,实践中一般取K=10,本文中我们将K取值为10。同时,本文在交叉验证的基础上,采用多种评价指标对亲属关系判别模型及对比算法实验结果进行评价,包括: 精确率、召回率、F1值及AUC。本文实验中的混淆矩阵如表3所示。
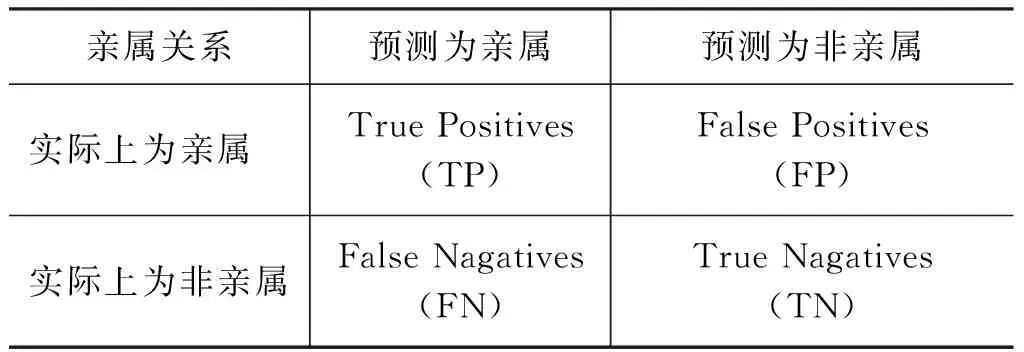
表3 混淆矩阵
本文结合表3所示的混淆矩阵,分别介绍这几种判别指标的计算方法。
(1) 精确率(Precision)是模型预测为亲属关系而占实际亲属关系的比例,即查准率。
(2)
(2) 召回率(Recall)是模型预测为亲属关系样本中实际上也是亲属的比例,即查全率。
(3)
(3)F1-Score是精准率和召回率的调和均值,是对模型的一种中和评价。
(4)
(4) AUC是ROC(receiver operating characteristic)曲线下的面积,是对模型敏感性和特异性的综合评价指标。AUC处于[0,1]之间,AUC值越大表示决策的准确率越高。AUC的基准值为0.5,即随机猜测。
3.4.2实验及结果分析
实验中对移动社交网络用户间是否存在亲属关系进行判别,验证亲属关系判别模型的有效性。同时,本文通过多种机器学习算法作为对比算法,验证判别模型的有效性。其中,对比算法包括决策树(decision tree,DT)、支持向量机(support vector machine,SVM)、Logistic回归(logistic regression,LR)、梯度提升决策树 (gradient boost decision tree,GBDT)。
在实验过程中,我们通过预处理的用户通话记录数据集,对本文亲属关系判别模型和对比算法模型进行训练和测试。首先,我们根据用户间的通话记录数据得到通话用户数据特征值,进而得到实验用的数据集。然后,将实验数据集分成10个子集,其中九个作为训练集,一个作为测试集。最后,我们将DT、SVM、LR、GBDT算法以及本文亲属关系判别模型分别在训练集和测试集上进行训练和测试,计算实验中不同评价指标值。
由此,我们得到不同方法实验结果评价指标,实验结果比较如表4所示。

表4 实验结果评价指标比较
同时,根据上述指标结果,我们对各指标以AUC值的大小进行排序,其结果如图7所示。

图7 亲属关系判别模型算法比较
由图7可知,本文提出的GBDT与LR融合模型能够取得良好的实验效果。实验中GBDT+LR融合模型的精确率为81.01%,召回率为76.24%,准确率为79.18%。与其他对比算法相比,实验效果更好。
4 结论
本文针对人们生活中联系较为紧密的移动社交网络进行分析和研究,主要工作包括以下两部分。
(1) 对移动社交网络中存在的幂律分布特征进行了分析,对其中的规律和结论进行解释和说明,并与其他社交网络相关结论进行对比。实现对本文移动社交网络幂律分布特征的分析和研究,优化了相关研究结论。
(2) 通过提取用户通话行为显著特征,采用GBDT与LR融合方法建立亲属关系判别模型。在实验中,将该判别模型与多种算法进行对比实验。通过该模型,我们能够在移动社交网络中具有交互行为的用户之间,较好地判别用户间是否存在亲属关系,其判别精确率达到81.01%。
在今后的工作中,我们将继续对移动社交网络中的网络特征及用户关系进行研究。例如,本文用户亲属关系研究中,用户间的亲属关系判别是基于通话网络中用户的行为信息,并没有充分地考虑用户之间的结构特征及短信网络中用户结构和行为特征。因此,我们可以结合不同网络中用户的结构和行为对用户之间的亲属关系进行判别分析。本文只对用户间是否存在亲属关系进行判别,下一步可以将用户亲属关系分成更加具体的类别,并对其他用户关系进行提取和分析,进而通过本文判别方法及其他分类算法的训练学习,判别出用户具体的关系类别。
猜你喜欢
当代工人(2019年4期)2019-04-22 12:04:26
中华诗词(2018年5期)2018-11-22 06:46:08
当代工人(2018年21期)2018-03-06 12:41:08
高原山地气象研究(2016年1期)2016-11-10 06:05:57
发明与创新(2016年30期)2016-08-22 11:35:24
浙江大学学报(工学版)(2016年9期)2016-06-05 09:20:57
意林原创版(2015年10期)2015-05-30 10:48:04
电信科学(2014年1期)2014-09-29 04:48:34
电信科学(2013年5期)2013-02-19 07:28:36
断块油气田(2012年6期)2012-03-25 09:53:59
